python 数据分析day4 Pandas 之 DataFrame
DataFrame
-
- 一. 创建DataFrame
-
- 1. 二维数组创建
- 2. 字典创建
- 3. JSON创建
- 4. 读取Excel或CSV文件创建
- 5. 读数据库(MySQL)创建
- 二. 常用属性
- 三. 基本方法
-
- 3.1汇总方法
- 3.2处理索引
-
- et_index() / reset_index()方法:设置索引/重置索引,两个相当于是逆操作。
- 四. 获取数据
-
- 1.索引和切片
- 2.数据筛选
-
- 布尔索引
- query()方法
- filter()方法
- 补充:添加一列/行
- 随机抽样
- 练习:科比投篮数据分析
- 重塑数据
-
-
- 1.merge函数
- 练习1:查询学生的姓名、课程的名称和考试成绩。
- 练习2:查询每个学生的姓名和选课的数量。(连接时需要外连接,需要使用pd.groupby())
- 2.concat函数
-
- 五. 处理数据
-
- 1.数据清洗
-
- 缺失值处理 ---> dropna() / fillna()
- 重复值处理 ---> duplicated() / drop_duplicates()
-
- 练习:找主管不包括老板(先获取mgr的索引(无重复),然后根据索引找到主管)
- 异常值处理(用指定的值替换掉原来的值 replace())
-
- 练习:
- 2.数据删除
-
- 删除行
- 删除列
- 3.数据转换
-
- apply() / transform() / applymap()方法
- 字符串向量
- 补充:UUID方式产生数据ID的字段
-
- 练习:读取拉勾网上招聘数据,找出数据分析岗位的平均工资是多少?
- 时间日期向量
- python datetime模块的datetime库
- 六. 数据分析
-
- 1.获取描述性统计信息
- 练习1:计算每个城市的数据分析岗位平均薪资
-
- 知识点:groupby()方法
- 练习2:
-
- 知识点:分组聚合操作(# SAC ---> Split - Aggregate - Combine)
- 使用agg()方法一次性执行多个聚合函数
- 2.排序和Top-N
-
- 透视表和交叉表
- 数据分箱(离散化)
- 练习:
一. 创建DataFrame
1. 二维数组创建
scores=np.random.randint(60,101,(5,3))
courses=['语文','数学','英语']
ids=[1001,1002,1003,1004,1005]
df=pd.DataFrame(data=scores,columns=courses,index=ids)
df
"""
语文 数学 英语
1001 87 100 92
1002 97 75 96
1003 67 69 78
1004 87 70 72
1005 72 69 97
"""
2. 字典创建
ids=[1001,1002,1003,1004,1005]
data={
'语文':[62,72,93,88,93],
'数学':[95,65,86,66,87],
'英语':[66,75,82,69,82]
}
df=pd.DataFrame(data=data,index=ids)
df
"""
语文 数学 英语
1001 62 95 66
1002 72 65 75
1003 93 86 82
1004 88 66 69
1005 93 87 82
"""
3. JSON创建
json_string='''
{
"语文":[62,72,93,88,93],
"数学":[95,65,86,66,87],
"英语":[66,75,82,69,82]
}
'''
pd.read_json(json_string)
df.index=ids
df
"""
语文 数学 英语
1001 62 95 66
1002 72 65 75
1003 93 86 82
1004 88 66 69
1005 93 87 82
"""
4. 读取Excel或CSV文件创建
读取CSV文件
df=pd.read_csv('2018年北京积分落户数据.csv',
delimiter=',',
index_col='id',
usecols=['id','name','score'],
skiprows=range(1,6),
nrows=5
)
df
"""
name score
id
6 罗恒 117.34
7 刘春静 116.17
8 李玉俊 116.13
9 穆立 115.95
10 李加昌 115.91
"""
读取Excel文件
import random
df=pd.read_excel('某视频网站运营数据.xlsx',
skiprows=lambda x:x>0 and random.random()>0.05
)
df

5. 读数据库(MySQL)创建
import pymysql
conn=pymysql.connect(host='47.104.xx.xxx',
port=3306,
user='xxxxxx',
password='xxxxxx',
database='xxxxxx',
charset='utf8mb4'
)
conn
#二. 常用属性
形状
df.shape # (14,7)
维度
df.ndim # 2
行索引(标签)
df.index # RangeIndex(start=0, stop=14, step=1)
列索引(标签)
df.columns # Index(['eno', 'ename', 'job', 'mgr', 'sal', 'comm', 'dno'], dtype='object')
所有的值—> 二维数组
df.values
"""
array([[1359, ' 胡 一刀 ', '销售员', 3344.0, 1800, 200.0, 30],
[2056, '乔 峰', '分析师', 7800.0, 5000, 1500.0, 20],
[3088, '李莫愁', '设计师', 2056.0, 3500, 800.0, 20],
[3211, '张无忌', '程序员', 2056.0, 3200, nan, 20],
[3233, '丘 处机', '程序员', 2056.0, 3400, nan, 20],
[3244, '欧阳锋', '程序员', 3088.0, 3200, nan, 20],
[3251, '张翠山', '程序员', 2056.0, 4000, nan, 20],
[3344, '黄蓉', '销售主管', 7800.0, 3000, 800.0, 30],
[3577, '杨过', '会计', 5566.0, 2200, nan, 10],
[3588, '朱九真', '会计', 5566.0, 2500, nan, 10],
[4466, '苗人凤', '销售员', 3344.0, 2500, nan, 30],
[5234, '郭靖', '出纳', 5566.0, 2000, nan, 10],
[5566, '宋远桥', '会计师', 7800.0, 4000, 1000.0, 10],
[7800, '张三丰', '总裁', nan, 9000, 1200.0, 20]], dtype=object)
"""
元素的个数
df.size # 98
三. 基本方法
3.1汇总方法
info()方法
df.info()
"""
RangeIndex: 14 entries, 0 to 13
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 eno 14 non-null int64
1 ename 14 non-null object
2 job 14 non-null object
3 mgr 13 non-null float64
4 sal 14 non-null int64
5 comm 6 non-null float64
6 dno 14 non-null int64
dtypes: float64(2), int64(3), object(2)
memory usage: 912.0+ bytes
"""
head() / tail()方法
df.head(3)
"""
eno ename job mgr sal comm dno
0 1359 胡 一刀 销售员 3344.0 1800 200.0 30
1 2056 乔 峰 分析师 7800.0 5000 1500.0 20
2 3088 李莫愁 设计师 2056.0 3500 800.0 20
"""
df.tail(10)
"""
eno ename job mgr sal comm dno
12 5566 宋远桥 会计师 7800.0 4000 1000.0 10
13 7800 张三丰 总裁 NaN 9000 1200.0 20
"""
describe()方法
df.describe()
"""
eno mgr sal comm dno
count 14.000000 13.000000 14.000000 6.000000 14.000000
mean 3786.928571 4469.076923 3521.428571 916.666667 19.285714
std 1586.112639 2320.660770 1803.065156 440.075751 7.300459
min 1359.000000 2056.000000 1800.000000 200.000000 10.000000
25% 3216.500000 2056.000000 2500.000000 800.000000 12.500000
50% 3297.500000 3344.000000 3200.000000 900.000000 20.000000
75% 4246.500000 5566.000000 3875.000000 1150.000000 20.000000
max 7800.000000 7800.000000 9000.000000 1500.000000 30.000000
"""
3.2处理索引
et_index() / reset_index()方法:设置索引/重置索引,两个相当于是逆操作。
设置索引(用指定的列充当索引)
df.set_index('eno')

多级索引
df.set_index(['job', 'eno'])

重置索引
# 重置索引(相当于是set_index方法的逆操作)
df.reset_index(inplace=True)

reindex()方法:调整索引的顺序。
调整列索引
temp = ['eno', 'dno', 'ename', 'job', 'mgr', 'sal', 'comm', 'level']
# 调整列索引
df.reindex(columns=temp, fill_value=5)
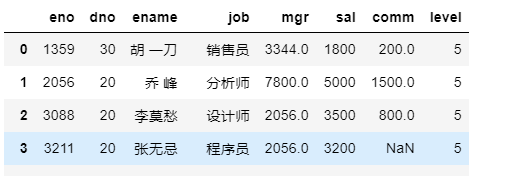
调整行索引
new_index = np.arange(0, 14)
# 用shuffle函数对数组随机乱序
np.random.shuffle(new_index)
# 调整行索引
df.reindex(new_index)

rename()方法:修改索引的名字。
给列索引(标签)改名字
df.rename(columns={
'eno': '编号', 'ename': '姓名'})
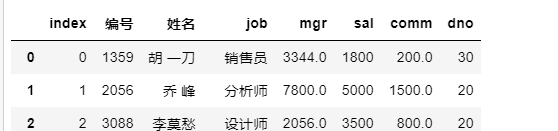
给行索(标签)引改名字
df.rename({
0: 'A', 1: 'B', 2: 'C'})
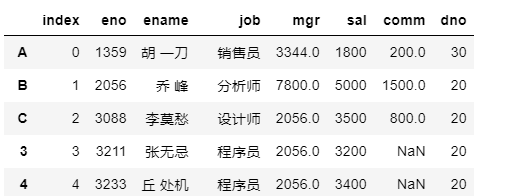
四. 获取数据
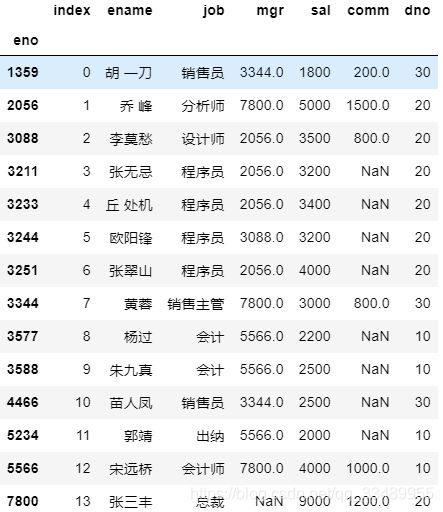
1.索引和切片
获取指定的列
df.ename
或者
ser=df['ename']
eno
1359 胡 一刀
2056 乔 峰
3088 李莫愁
3211 张无忌
3233 丘 处机
3244 欧阳锋
3251 张翠山
3344 黄蓉
3577 杨过
3588 朱九真
4466 苗人凤
5234 郭靖
5566 宋远桥
7800 张三丰
Name: ename, dtype: object
获取多个列(通过花式索引)
temp=df[['ename','sal']]
temp

获取行
通过索引器属性+行索引获取一行
df.loc[1359]
通过整数下标索引获取一行
df.iloc[0]
df.iloc[-14]
"""
index 0
ename 胡 一刀
job 销售员
mgr 3344
sal 1800
comm 200
dno 30
Name: 1359, dtype: object
"""
获取多个行(通过花式索引)
df.iloc[[0,1,-1]]
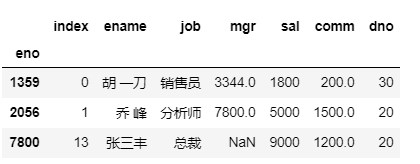
切片操作
df.iloc[0:10:2]

df.loc[1359:7800:3]
获取指定单元格的值
# 先通过列索引取一列再索引获取对应的值
df['job'][3588] # 会计
# 先通过索引器获取一行再索引获取对应的值
df.loc[3588]['job'] # 会计
# 使用at属性指定行和列的索引获取对应的值
df.at[3588,'job'] # 会计
# 只能先行后列,否则会报错
# df.at['job',3588]
修改单元格的值
# 使用iat属性通过整数的行列索引获取对应的值
df.iat[0,1]='大师'
df.iat[0,1] # '大师'
df.at[1359,'ename']='二师'
df.at[1359,'ename'] # '二师'
df['ename'][1359]='三师'
df['ename'][1359] #'三师'
df.loc[1359]['ename']='四师'
df.loc[1359]['ename'] # '三师' 经测试值不会改变
df.iloc[0][1]='四师'
df.iloc[0][1] # '三师' 经测试值不会改变
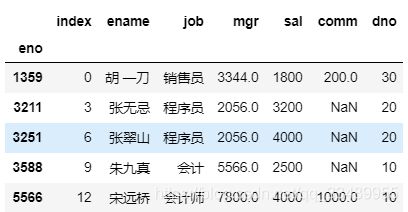
2.数据筛选
布尔索引
数据集:
index ename job mgr sal comm dno
eno
1359 0 大师 销售员 3344.0 1800 200.0 30
2056 1 乔 峰 分析师 7800.0 5000 1500.0 20
3088 2 李莫愁 设计师 2056.0 3500 800.0 20
3211 3 张无忌 程序员 2056.0 3200 NaN 20
3233 4 丘 处机 程序员 2056.0 3400 NaN 20
3244 5 欧阳锋 程序员 3088.0 3200 NaN 20
3251 6 张翠山 程序员 2056.0 4000 NaN 20
3344 7 黄蓉 销售主管 7800.0 3000 800.0 30
3577 8 杨过 会计 5566.0 2200 NaN 10
3588 9 朱九真 会计 5566.0 2500 NaN 10
4466 10 苗人凤 销售员 3344.0 2500 NaN 30
5234 11 郭靖 出纳 5566.0 2000 NaN 10
5566 12 宋远桥 会计师 7800.0 4000 1000.0 10
7800 13 张三丰 总裁 NaN 9000 1200.0 20
# 布尔索引
df[df.sal >= 3500]
"""
index ename job mgr sal comm dno
eno
2056 1 乔 峰 分析师 7800.0 5000 1500.0 20
3088 2 李莫愁 设计师 2056.0 3500 800.0 20
3251 6 张翠山 程序员 2056.0 4000 NaN 20
5566 12 宋远桥 会计师 7800.0 4000 1000.0 10
7800 13 张三丰 总裁 NaN 9000 1200.0 20
"""
& - 与 - 而且
-
| - 或 - 或者
-
- 非 - 变反
df[(df.sal >= 3500) & (df.comm >= 1000)]
"""
index ename job mgr sal comm dno
eno
2056 1 乔 峰 分析师 7800.0 5000 1500.0 20
5566 12 宋远桥 会计师 7800.0 4000 1000.0 10
7800 13 张三丰 总裁 NaN 9000 1200.0 20
"""
query()方法
使用query方法通过指定的表达式筛选数据
df.query('sal>=3500 and comm >=1000')
"""
index ename job mgr sal comm dno
eno
2056 1 乔 峰 分析师 7800.0 5000 1500.0 20
5566 12 宋远桥 会计师 7800.0 4000 1000.0 10
7800 13 张三丰 总裁 NaN 9000 1200.0 20
"""
filter()方法
数据准备
df2 = pd.DataFrame(np.array(([1, 2, 3], [4, 5, 6])),
index=['mouse', 'rabbit'],
columns=['one', 'two', 'three'])
df2
"""
one two three
mouse 1 2 3
rabbit 4 5 6
"""
筛选指定的列,类似于花式索引
df2.filter(items=['one','three'])
"""
one three
mouse 1 3
rabbit 4 6
"""
筛选以字母e结尾的列
df2.filter(regex='e$', axis=1)
"""
one three
mouse 1 3
rabbit 4 6
"""
筛选以字母e结尾的行
df2.filter(regex='e$',axis=0)
"""
one two three
mouse 1 2 3
"""
筛选行索引中有bbi的行
df2.filter(like='bbi',axis=0)
"""
one two three
rabbit 4 5 6
"""
补充:添加一列/行
添加列
df['正式员工'] = ['是', '是', '是', '是', '是', '是', '否', '是', '是', '否', '是', '是', '是', '是']
df
"""
index ename job mgr sal comm dno 正式员工
eno
1359 0 大师 销售员 3344.0 1800 200.0 30 是
2056 1 乔 峰 分析师 7800.0 5000 1500.0 20 是
3088 2 李莫愁 设计师 2056.0 3500 800.0 20 是
3211 3 张无忌 程序员 2056.0 3200 NaN 20 是
3233 4 丘 处机 程序员 2056.0 3400 NaN 20 是
3244 5 欧阳锋 程序员 3088.0 3200 NaN 20 是
3251 6 张翠山 程序员 2056.0 4000 NaN 20 否
3344 7 黄蓉 销售主管 7800.0 3000 800.0 30 是
3577 8 杨过 会计 5566.0 2200 NaN 10 是
3588 9 朱九真 会计 5566.0 2500 NaN 10 否
4466 10 苗人凤 销售员 3344.0 2500 NaN 30 是
5234 11 郭靖 出纳 5566.0 2000 NaN 10 是
5566 12 宋远桥 会计师 7800.0 4000 1000.0 10 是
7800 13 张三丰 总裁 NaN 9000 1200.0 20 是
"""
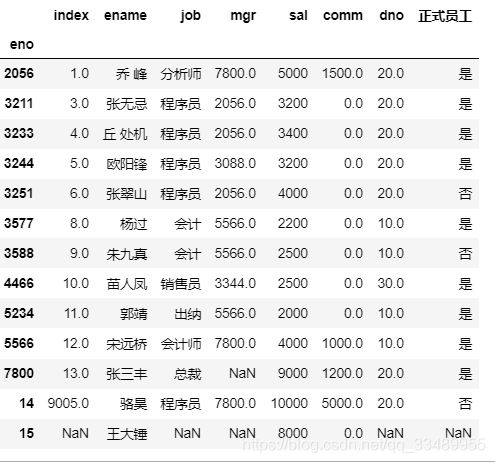
添加一行:两种方式(列表,字典)
df.loc[14] = [9005, '骆昊', '程序员', 7800, 10000, 5000, 20, '否']
df.loc[15] = {
'eno': 9006, 'ename': '王大锤', 'sal': 8000}
df
"""
index ename job mgr sal comm dno 正式员工
eno
1359 0.0 大师 销售员 3344.0 1800 200.0 30.0 是
2056 1.0 乔 峰 分析师 7800.0 5000 1500.0 20.0 是
3088 2.0 李莫愁 设计师 2056.0 3500 800.0 20.0 是
3211 3.0 张无忌 程序员 2056.0 3200 NaN 20.0 是
3233 4.0 丘 处机 程序员 2056.0 3400 NaN 20.0 是
3244 5.0 欧阳锋 程序员 3088.0 3200 NaN 20.0 是
3251 6.0 张翠山 程序员 2056.0 4000 NaN 20.0 否
3344 7.0 黄蓉 销售主管 7800.0 3000 800.0 30.0 是
3577 8.0 杨过 会计 5566.0 2200 NaN 10.0 是
3588 9.0 朱九真 会计 5566.0 2500 NaN 10.0 否
4466 10.0 苗人凤 销售员 3344.0 2500 NaN 30.0 是
5234 11.0 郭靖 出纳 5566.0 2000 NaN 10.0 是
5566 12.0 宋远桥 会计师 7800.0 4000 1000.0 10.0 是
7800 13.0 张三丰 总裁 NaN 9000 1200.0 20.0 是
14 9005.0 骆昊 程序员 7800.0 10000 5000.0 20.0 否
15 NaN 王大锤 NaN NaN 8000 NaN NaN NaN
"""
随机抽样
随机抽样(指定样本数量)
df.sample(n=5)
"""
index ename job mgr sal comm dno 正式员工
eno
3244 5.0 欧阳锋 程序员 3088.0 3200 NaN 20.0 是
2056 1.0 乔 峰 分析师 7800.0 5000 1500.0 20.0 是
3251 6.0 张翠山 程序员 2056.0 4000 NaN 20.0 否
4466 10.0 苗人凤 销售员 3344.0 2500 NaN 30.0 是
1359 0.0 大师 销售员 3344.0 1800 200.0 30.0 是
"""
随机抽样(指定样本的比例)
df.sample(frac=0.5)
"""
index ename job mgr sal comm dno 正式员工
eno
1359 0.0 三师 销售员 3344.0 1800 200.0 30.0 是
5566 12.0 宋远桥 会计师 7800.0 4000 1000.0 10.0 是
7800 13.0 张三丰 总裁 NaN 9000 1200.0 20.0 是
5234 11.0 郭靖 出纳 5566.0 2000 NaN 10.0 是
4466 10.0 苗人凤 销售员 3344.0 2500 NaN 30.0 是
3244 5.0 欧阳锋 程序员 3088.0 3200 NaN 20.0 是
3588 9.0 朱九真 会计 5566.0 2500 NaN 10.0 否
3251 6.0 张翠山 程序员 2056.0 4000 NaN 20.0 否
"""
练习:科比投篮数据分析
数据准备
kobe_df = pd.read_csv('Kobe_data.csv', index_col='shot_id')
kobe_df.info()
# 设置显示所有的列
pd.set_option('max_columns', None)
kobe_df.head(20)
科比使用得最多的投篮动作(action_type + combined_shot_type)是什么?
ser = kobe_df.action_type + '-' + kobe_df.combined_shot_type
ser.value_counts().index[0] #'Jump Shot-Jump Shot'
科比职业生涯交手最多的队伍是哪支球队?
ser = kobe_df.drop_duplicates('game_id').opponent
ser.value_counts().index[0] #'SAS'
科比职业生涯总得分(不包括罚篮)是多少?
# temp = kobe_df.query('shot_made_flag == 1')['shot_type'] # 法一
temp = kobe_df[kobe_df.shot_made_flag == 1]['shot_type'] # 法二
np.sum(temp.apply(lambda x: int(x[0]))) ## 24712
# 法三
# 获取Series对象对应的字符串向量
# 通过extract方法用正则表达式从字符串中抽取指定内容
temp.str.extract('(\d+)').applymap(int).sum()[0] # 24712
重塑数据
1.merge函数
merge函数的参数
left - 左表
right - 右表
how - 连接方式(inner / outer / left / right)
on - 连表字段(left_on / right_on)
获取数据:
conn = pymysql.connect(
host='47.104.xx.xxx', port=3306, user='guest',
password='xxxxxx', database='school', charset='utf8mb4'
)
conn # 将学生表和学院表合并:
student_df=pd.read_sql('select * from tb_student',conn)
student_df
"""
stuid stuname stusex stubirth stuaddr collid
0 1001 杨过 1 1990-03-04 湖南长沙 1
1 1002 任我行 1 1992-02-02 湖南长沙 1
2 1033 王语嫣 0 1989-12-03 四川成都 1
3 1378 纪嫣然 0 1995-08-12 四川绵阳 1
4 1572 岳不嫣 1 1993-07-19 陕西咸阳 1
5 1954 林平之 1 1994-09-20 福建莆田 1
6 2035 东方不败 1 1988-06-30 四川成都 2
7 3011 林震南 1 1985-12-12 福建莆田 3
8 3755 项少龙 1 1993-01-25 四川绵阳 3
9 3923 杨不悔 0 1985-04-17 四川成都 3
"""
college_df = pd.read_sql('select collid, collname from tb_college', conn)
college_df
"""
collid collname
0 2 外国语学院
1 3 经济管理学院
2 1 计算机学院
"""
temp_df=pd.merge(left=student_df,right=college_df,on='collid',how='inner')
temp_df
"""
stuid stuname stusex stubirth stuaddr collid collname
0 1001 杨过 1 1990-03-04 湖南长沙 1 计算机学院
1 1002 任我行 1 1992-02-02 湖南长沙 1 计算机学院
2 1033 王语嫣 0 1989-12-03 四川成都 1 计算机学院
3 1378 纪嫣然 0 1995-08-12 四川绵阳 1 计算机学院
4 1572 岳不嫣 1 1993-07-19 陕西咸阳 1 计算机学院
5 1954 林平之 1 1994-09-20 福建莆田 1 计算机学院
6 2035 东方不败 1 1988-06-30 四川成都 2 外国语学院
7 3011 林震南 1 1985-12-12 福建莆田 3 经济管理学院
8 3755 项少龙 1 1993-01-25 四川绵阳 3 经济管理学院
9 3923 杨不悔 0 1985-04-17 四川成都 3 经济管理学院
"""
练习1:查询学生的姓名、课程的名称和考试成绩。
查询学生表
student_df = pd.read_sql('select stuid, stuname from tb_student', conn)
student_df
"""
stuid stuname
0 1001 杨过
1 1002 任我行
2 1033 王语嫣
3 1378 纪嫣然
4 1572 岳不嫣
5 1954 林平之
6 2035 东方不败
7 3011 林震南
8 3755 项少龙
9 3923 杨不悔
"""
查询记录表
record_df = pd.read_sql(
'select sid, cid, score from tb_record where score is not null', conn,
)
record_df
"""
sid cid score
0 1001 1111 95.0
1 1001 2222 87.5
2 1001 3333 100.0
3 1001 6666 100.0
4 1002 1111 65.0
5 1002 5555 42.0
6 1033 1111 92.5
7 1033 4444 78.0
8 1033 5555 82.5
9 1572 1111 78.0
10 1378 1111 82.0
11 1378 7777 65.5
12 2035 7777 88.0
13 2035 9999 78.0
14 3755 9999 92.0
15 1002 9999 75.0
16 1572 9999 83.0
"""
查询课程表
course_df = pd.read_sql('select couid, couname from tb_course', conn)
course_df
couid couname
0 1111 Python程序设计
1 2222 Web前端开发
2 3333 操作系统
3 4444 计算机网络
4 5555 编译原理
5 6666 算法和数据结构
6 7777 经贸法语
7 8888 成本会计
8 9999 审计学
合表:
选课记录表和学生表合并成临时表
temp_df=pd.merge(student_df,record_df,left_on='stuid',right_on='sid',how='inner')
temp_df
"""
stuid stuname sid cid score
0 1001 杨过 1001 1111 95.0
1 1001 杨过 1001 2222 87.5
2 1001 杨过 1001 3333 100.0
3 1001 杨过 1001 6666 100.0
4 1002 任我行 1002 1111 65.0
5 1002 任我行 1002 5555 42.0
6 1002 任我行 1002 9999 75.0
7 1033 王语嫣 1033 1111 92.5
8 1033 王语嫣 1033 4444 78.0
9 1033 王语嫣 1033 5555 82.5
10 1378 纪嫣然 1378 1111 82.0
11 1378 纪嫣然 1378 7777 65.5
12 1572 岳不嫣 1572 1111 78.0
13 1572 岳不嫣 1572 9999 83.0
14 2035 东方不败 2035 7777 88.0
15 2035 东方不败 2035 9999 78.0
16 3755 项少龙 3755 9999 92.0
"""
临时表和课程表合并
temp_df=pd.merge(temp_df,course_df,left_on='cid',right_on='couid')
temp_df
"""
stuid stuname sid cid score couid couname
0 1001 杨过 1001 1111 95.0 1111 Python程序设计
1 1002 任我行 1002 1111 65.0 1111 Python程序设计
2 1033 王语嫣 1033 1111 92.5 1111 Python程序设计
3 1378 纪嫣然 1378 1111 82.0 1111 Python程序设计
4 1572 岳不嫣 1572 1111 78.0 1111 Python程序设计
5 1001 杨过 1001 2222 87.5 2222 Web前端开发
6 1001 杨过 1001 3333 100.0 3333 操作系统
7 1001 杨过 1001 6666 100.0 6666 算法和数据结构
8 1002 任我行 1002 5555 42.0 5555 编译原理
9 1033 王语嫣 1033 5555 82.5 5555 编译原理
10 1002 任我行 1002 9999 75.0 9999 审计学
11 1572 岳不嫣 1572 9999 83.0 9999 审计学
12 2035 东方不败 2035 9999 78.0 9999 审计学
13 3755 项少龙 3755 9999 92.0 9999 审计学
14 1033 王语嫣 1033 4444 78.0 4444 计算机网络
15 1378 纪嫣然 1378 7777 65.5 7777 经贸法语
16 2035 东方不败 2035 7777 88.0 7777 经贸法语
"""
提取结果:
方法一:花式索引直接提取
temp_df[['stuname','couname','score']]
方法二:通过reindex调整索引获得需要的列
temp_df.reindex(columns=['stuname','couname','score'])
output:
stuname couname score
0 杨过 Python程序设计 95.0
1 任我行 Python程序设计 65.0
2 王语嫣 Python程序设计 92.5
3 纪嫣然 Python程序设计 82.0
4 岳不嫣 Python程序设计 78.0
5 杨过 Web前端开发 87.5
6 杨过 操作系统 100.0
7 杨过 算法和数据结构 100.0
8 任我行 编译原理 42.0
9 王语嫣 编译原理 82.5
10 任我行 审计学 75.0
11 岳不嫣 审计学 83.0
12 东方不败 审计学 78.0
13 项少龙 审计学 92.0
14 王语嫣 计算机网络 78.0
15 纪嫣然 经贸法语 65.5
16 东方不败 经贸法语 88.0
练习2:查询每个学生的姓名和选课的数量。(连接时需要外连接,需要使用pd.groupby())
先合表(student_df,record_df)外连接(因为有人没选课,使用内连接会导致改数据缺失),空值用0 填充 (否则计算课程数量时会导致数据缺失)
temp_df=pd.merge(student_df,record_df,left_on='stuid',right_on='sid',how='outer').fillna(0)
temp_df
"""
stuid stuname sid cid score
0 1001 杨过 1001.0 1111.0 95.0
1 1001 杨过 1001.0 2222.0 87.5
2 1001 杨过 1001.0 3333.0 100.0
3 1001 杨过 1001.0 6666.0 100.0
4 1002 任我行 1002.0 1111.0 65.0
5 1002 任我行 1002.0 5555.0 42.0
6 1002 任我行 1002.0 9999.0 75.0
7 1033 王语嫣 1033.0 1111.0 92.5
8 1033 王语嫣 1033.0 4444.0 78.0
9 1033 王语嫣 1033.0 5555.0 82.5
10 1378 纪嫣然 1378.0 1111.0 82.0
11 1378 纪嫣然 1378.0 7777.0 65.5
12 1572 岳不嫣 1572.0 1111.0 78.0
13 1572 岳不嫣 1572.0 9999.0 83.0
14 1954 林平之 0.0 0.0 0.0
15 2035 东方不败 2035.0 7777.0 88.0
16 2035 东方不败 2035.0 9999.0 78.0
17 3011 林震南 0.0 0.0 0.0
18 3755 项少龙 3755.0 9999.0 92.0
19 3923 杨不悔 0.0 0.0 0.0
"""
分组求课程数量和
ser=temp_df.groupby(['stuid','stuname']).cid.count()
ser
"""
stuid stuname
1001 杨过 4
1002 任我行 3
1033 王语嫣 3
1378 纪嫣然 2
1572 岳不嫣 2
1954 林平之 1
2035 东方不败 2
3011 林震南 1
3755 项少龙 1
3923 杨不悔 1
Name: cid, dtype: int64
"""
2.concat函数
用concat函数拼接多个DataFrame的数据
ignore_index=True表示忽略原来的索引
axis参数的默认值是0,表示在0轴上进行拼接
数据准备:三个表
小宝剑大药房(高新店)2018年销售数据
| 表格 1 | ||||||
| 购药时间 | 社保卡号 | 商品编码 | 商品名称 | 销售数量 | 应收金额 | 实收金额 |
| 2018-03-05 星期六 | 0010077400828 | 236701 | 清热解毒口服液 | 1 | 28 | 24.64 |
| 2018-03-07 星期一 | 0010077400828 | 236701 | 清热解毒口服液 | 5 | 140 | 112 |
| 2018-03-09 星期三 | 0010079843728 | 236701 | 清热解毒口服液 | 6 | 168 | 140 |
| 2018-03-15 星期二 | 0010031328528 | 236701 | 清热解毒口服液 | 2 | 56 | 49.28 |
| 2018-03-15 星期二 | 00100703428 | 236701 | 清热解毒口服液 | 2 | 56 | 49.28 |
| 2018-03-15 星期二 | 0010712328 | 236701 | 清热解毒口服液 | 5 | 140 | 112 |
| 2018-03-20 星期日 | 0011668828 | 236701 | 清热解毒口服液 | 6 | 168 | 140 |
| 2018-03-22 星期二 | 0010066351928 | 236701 | 清热解毒口服液 | 1 | 28 | 28 |
| 表格 1 | ||||||
| 购药时间 | 社保卡号 | 商品编码 | 商品名称 | 销售数量 | 应收金额 | 实收金额 |
| 2018-04-07 星期四 | 0011652628 | 236701 | 清热解毒口服液 | 6 | 168 | 140 |
| 2018-04-13 星期三 | 0011005128 | 236701 | 清热解毒口服液 | 2 | 56 | 56 |
| 2018-04-22 星期五 | 0010344628 | 236701 | 清热解毒口服液 | 6 | 168 | 140 |
| 2018-05-01 星期日 | 0010070313828 | 236701 | 清热解毒口服液 | 6 | 168 | 140 |
| 2018-05-05 星期四 | 0010031328528 | 236701 | 清热解毒口服液 | 5 | 140 | 112 |
| 2018-05-05 星期四 | 0010070343428 | 236701 | 清热解毒口服液 | 2 | 56 | 49.28 |
| 2018-05-05 星期四 | 0010073660228 | 236701 | 清热解毒口服液 | 1 | 28 | 24.64 |
| 表格 1 | ||||||
| 购药时间 | 社保卡号 | 商品编码 | 商品名称 | 销售数量 | 应收金额 | 实收金额 |
| 2018-01-01 星期五 | 001616528 | 236701 | 强力VC银翘片 | 6 | 82.8 | 69 |
| 2018-01-02 星期六 | 001616528 | 236701 | 清热解毒口服液 | 1 | 28 | 24.64 |
| 2018-01-06 星期三 | 0012602828 | 236701 | 感康 | 2 | 16.8 | 15 |
| 2018-01-11 星期一 | 0010070343428 | 236701 | 三九感冒灵 | 1 | 28 | 28 |
| 2018-01-15 星期五 | 00101554328 | 236701 | 三九感冒灵 | 8 | 224 | 208 |
| 2018-01-20 星期三 | 0013389528 | 236701 | 三九感冒灵 | 1 | 28 | 28 |
| 2018-01-31 星期日 | 00101464928 | 236701 | 三九感冒灵 | 2 | 56 | 56 |
| 2018-02-17 星期三 | 0011177328 | 236701 | 三九感冒灵 | 5 | 149 | 131.12 |
| 2018-02-22 星期一 | 0010065687828 | 236701 | 三九感冒灵 | 1 | 29.8 | 26.22 |
names = ['高新', '犀浦', '新津']
dfs=[pd.read_excel(f'小宝剑大药房({name}店)2018年销售数据.xlsx',header=1) for name in names]
dfs
"""
[ 购药时间 社保卡号 商品编码 商品名称 销售数量 应收金额 实收金额
0 2018-03-05 星期六 10077400828 236701 清热解毒口服液 1 28 24.64
1 2018-03-07 星期一 10077400828 236701 清热解毒口服液 5 140 112.00
2 2018-03-09 星期三 10079843728 236701 清热解毒口服液 6 168 140.00
3 2018-03-15 星期二 10031328528 236701 清热解毒口服液 2 56 49.28
4 2018-03-15 星期二 100703428 236701 清热解毒口服液 2 56 49.28
5 2018-03-15 星期二 10712328 236701 清热解毒口服液 5 140 112.00
6 2018-03-20 星期日 11668828 236701 清热解毒口服液 6 168 140.00
7 2018-03-22 星期二 10066351928 236701 清热解毒口服液 1 28 28.00,
购药时间 社保卡号 商品编码 商品名称 销售数量 应收金额 实收金额
0 2018-04-07 星期四 11652628 236701 清热解毒口服液 6 168 140.00
1 2018-04-13 星期三 11005128 236701 清热解毒口服液 2 56 56.00
2 2018-04-22 星期五 10344628 236701 清热解毒口服液 6 168 140.00
3 2018-05-01 星期日 10070313828 236701 清热解毒口服液 6 168 140.00
4 2018-05-05 星期四 10031328528 236701 清热解毒口服液 5 140 112.00
5 2018-05-05 星期四 10070343428 236701 清热解毒口服液 2 56 49.28
6 2018-05-05 星期四 10073660228 236701 清热解毒口服液 1 28 24.64,
购药时间 社保卡号 商品编码 商品名称 销售数量 应收金额 实收金额
0 2018-01-01 星期五 1616528 236701 强力VC银翘片 6 82.8 69.00
1 2018-01-02 星期六 1616528 236701 清热解毒口服液 1 28.0 24.64
2 2018-01-06 星期三 12602828 236701 感康 2 16.8 15.00
3 2018-01-11 星期一 10070343428 236701 三九感冒灵 1 28.0 28.00
4 2018-01-15 星期五 101554328 236701 三九感冒灵 8 224.0 208.00
5 2018-01-20 星期三 13389528 236701 三九感冒灵 1 28.0 28.00
6 2018-01-31 星期日 101464928 236701 三九感冒灵 2 56.0 56.00
7 2018-02-17 星期三 11177328 236701 三九感冒灵 5 149.0 131.12
8 2018-02-22 星期一 10065687828 236701 三九感冒灵 1 29.8 26.22]
"""
使用concat 将三个表的数据汇总为一个表
new_df=pd.concat(dfs,ignore_index=True)
new_df.to_excel('汇总数据.xlsx')
new_df
| 购药时间 | 社保卡号 | 商品编码 | 商品名称 | 销售数量 | 应收金额 | 实收金额 | |
| 0 | 2018-03-05 星期六 | 10077400828 | 236701 | 清热解毒口服液 | 1 | 28.0 | 24.64 |
| 1 | 2018-03-07 星期一 | 10077400828 | 236701 | 清热解毒口服液 | 5 | 140.0 | 112.00 |
| 2 | 2018-03-09 星期三 | 10079843728 | 236701 | 清热解毒口服液 | 6 | 168.0 | 140.00 |
| 3 | 2018-03-15 星期二 | 10031328528 | 236701 | 清热解毒口服液 | 2 | 56.0 | 49.28 |
| 4 | 2018-03-15 星期二 | 100703428 | 236701 | 清热解毒口服液 | 2 | 56.0 | 49.28 |
| 5 | 2018-03-15 星期二 | 10712328 | 236701 | 清热解毒口服液 | 5 | 140.0 | 112.00 |
| 6 | 2018-03-20 星期日 | 11668828 | 236701 | 清热解毒口服液 | 6 | 168.0 | 140.00 |
| 7 | 2018-03-22 星期二 | 10066351928 | 236701 | 清热解毒口服液 | 1 | 28.0 | 28.00 |
| 8 | 2018-04-07 星期四 | 11652628 | 236701 | 清热解毒口服液 | 6 | 168.0 | 140.00 |
| 9 | 2018-04-13 星期三 | 11005128 | 236701 | 清热解毒口服液 | 2 | 56.0 | 56.00 |
| 10 | 2018-04-22 星期五 | 10344628 | 236701 | 清热解毒口服液 | 6 | 168.0 | 140.00 |
| 11 | 2018-05-01 星期日 | 10070313828 | 236701 | 清热解毒口服液 | 6 | 168.0 | 140.00 |
| 12 | 2018-05-05 星期四 | 10031328528 | 236701 | 清热解毒口服液 | 5 | 140.0 | 112.00 |
| 13 | 2018-05-05 星期四 | 10070343428 | 236701 | 清热解毒口服液 | 2 | 56.0 | 49.28 |
| 14 | 2018-05-05 星期四 | 10073660228 | 236701 | 清热解毒口服液 | 1 | 28.0 | 24.64 |
| 15 | 2018-01-01 星期五 | 1616528 | 236701 | 强力VC银翘片 | 6 | 82.8 | 69.00 |
| 16 | 2018-01-02 星期六 | 1616528 | 236701 | 清热解毒口服液 | 1 | 28.0 | 24.64 |
| 17 | 2018-01-06 星期三 | 12602828 | 236701 | 感康 | 2 | 16.8 | 15.00 |
| 18 | 2018-01-11 星期一 | 10070343428 | 236701 | 三九感冒灵 | 1 | 28.0 | 28.00 |
| 19 | 2018-01-15 星期五 | 101554328 | 236701 | 三九感冒灵 | 8 | 224.0 | 208.00 |
| 20 | 2018-01-20 星期三 | 13389528 | 236701 | 三九感冒灵 | 1 | 28.0 | 28.00 |
| 21 | 2018-01-31 星期日 | 101464928 | 236701 | 三九感冒灵 | 2 | 56.0 | 56.00 |
| 22 | 2018-02-17 星期三 | 11177328 | 236701 | 三九感冒灵 | 5 | 149.0 | 131.12 |
| 23 | 2018-02-22 星期一 | 10065687828 | 236701 | 三九感冒灵 | 1 | 29.8 | 26.22 |
五. 处理数据
1.数据清洗
数据准备
df
index ename job mgr sal comm dno 正式员工
eno
1359 0.0 大师 销售员 3344.0 1800 200.0 30.0 是
2056 1.0 乔 峰 分析师 7800.0 5000 1500.0 20.0 是
3088 2.0 李莫愁 设计师 2056.0 3500 800.0 20.0 是
3211 3.0 张无忌 程序员 2056.0 3200 NaN 20.0 是
3233 4.0 丘 处机 程序员 2056.0 3400 NaN 20.0 是
3244 5.0 欧阳锋 程序员 3088.0 3200 NaN 20.0 是
3251 6.0 张翠山 程序员 2056.0 4000 NaN 20.0 否
3344 7.0 黄蓉 销售主管 7800.0 3000 800.0 30.0 是
3577 8.0 杨过 会计 5566.0 2200 NaN 10.0 是
3588 9.0 朱九真 会计 5566.0 2500 NaN 10.0 否
4466 10.0 苗人凤 销售员 3344.0 2500 NaN 30.0 是
5234 11.0 郭靖 出纳 5566.0 2000 NaN 10.0 是
5566 12.0 宋远桥 会计师 7800.0 4000 1000.0 10.0 是
7800 13.0 张三丰 总裁 NaN 9000 1200.0 20.0 是
14 9005.0 骆昊 程序员 7800.0 10000 5000.0 20.0 否
15 NaN 王大锤 NaN NaN 8000 NaN NaN NaN
缺失值处理 —> dropna() / fillna()
dropna() : 删除有缺失值的数据
axis=0 —> 默认 —> 遇到空值就删除对应的行
axis=1 —> 遇到空值就删除对应的列
df.dropna(axis=1)
"""
ename sal
eno
1359 大师 1800
2056 乔 峰 5000
3088 李莫愁 3500
3211 张无忌 3200
3233 丘 处机 3400
3244 欧阳锋 3200
3251 张翠山 4000
3344 黄蓉 3000
3577 杨过 2200
3588 朱九真 2500
4466 苗人凤 2500
5234 郭靖 2000
5566 宋远桥 4000
7800 张三丰 9000
14 骆昊 10000
15 王大锤 8000
"""
把DataFrame中所有的空值都处理成0
df.fillna(0)
"""
index ename job mgr sal comm dno 正式员工
eno
1359 0.0 大师 销售员 3344.0 1800 200.0 30.0 是
2056 1.0 乔 峰 分析师 7800.0 5000 1500.0 20.0 是
3088 2.0 李莫愁 设计师 2056.0 3500 800.0 20.0 是
3211 3.0 张无忌 程序员 2056.0 3200 0.0 20.0 是
3233 4.0 丘 处机 程序员 2056.0 3400 0.0 20.0 是
3244 5.0 欧阳锋 程序员 3088.0 3200 0.0 20.0 是
3251 6.0 张翠山 程序员 2056.0 4000 0.0 20.0 否
3344 7.0 黄蓉 销售主管 7800.0 3000 800.0 30.0 是
3577 8.0 杨过 会计 5566.0 2200 0.0 10.0 是
3588 9.0 朱九真 会计 5566.0 2500 0.0 10.0 否
4466 10.0 苗人凤 销售员 3344.0 2500 0.0 30.0 是
5234 11.0 郭靖 出纳 5566.0 2000 0.0 10.0 是
5566 12.0 宋远桥 会计师 7800.0 4000 1000.0 10.0 是
7800 13.0 张三丰 总裁 0.0 9000 1200.0 20.0 是
14 9005.0 骆昊 程序员 7800.0 10000 5000.0 20.0 否
15 0.0 王大锤 0 0.0 8000 0.0 0.0 0
"""
只处理某一列的空值
df.comm=df.comm.fillna(0)
df
"""
index ename job mgr sal comm dno 正式员工
eno
1359 0.0 大师 销售员 3344.0 1800 200.0 30.0 是
2056 1.0 乔 峰 分析师 7800.0 5000 1500.0 20.0 是
3088 2.0 李莫愁 设计师 2056.0 3500 800.0 20.0 是
3211 3.0 张无忌 程序员 2056.0 3200 0.0 20.0 是
3233 4.0 丘 处机 程序员 2056.0 3400 0.0 20.0 是
3244 5.0 欧阳锋 程序员 3088.0 3200 0.0 20.0 是
3251 6.0 张翠山 程序员 2056.0 4000 0.0 20.0 否
3344 7.0 黄蓉 销售主管 7800.0 3000 800.0 30.0 是
3577 8.0 杨过 会计 5566.0 2200 0.0 10.0 是
3588 9.0 朱九真 会计 5566.0 2500 0.0 10.0 否
4466 10.0 苗人凤 销售员 3344.0 2500 0.0 30.0 是
5234 11.0 郭靖 出纳 5566.0 2000 0.0 10.0 是
5566 12.0 宋远桥 会计师 7800.0 4000 1000.0 10.0 是
7800 13.0 张三丰 总裁 NaN 9000 1200.0 20.0 是
14 9005.0 骆昊 程序员 7800.0 10000 5000.0 20.0 否
15 NaN 王大锤 NaN NaN 8000 0.0 NaN NaN
"""
重复值处理 —> duplicated() / drop_duplicates()
duplicated()方法会返回一系列的布尔值表示是否重复,True:无重复;False:有重复
df.mgr.duplicated()
"""
eno
1359 False
2056 False
3088 False
3211 True
3233 True
3244 False
3251 True
3344 True
3577 False
3588 True
4466 True
5234 True
5566 True
7800 False
14 True
15 True
Name: mgr, dtype: bool
"""
drop_duplicates可以删除重复值,默认保留第一项
练习:找主管不包括老板(先获取mgr的索引(无重复),然后根据索引找到主管)
1.获取mgr的索引
方法一:unique()方法 先去掉空值,转成int类型,再去重
df.mgr.dropna().astype(int).unique() # array([3344, 7800, 2056, 3088, 5566])
方法二:drop_duplicates() 方法 先取mgr字段的值,再去重
使用’keep’参数,重复值的选择行为
可以改变。值’first’保留每一个的第一次出现
重复条目的集合。keep的默认值是’first’
mgr_nos=df.mgr.drop_duplicates(keep='first').dropna().astype(int)
"""
eno
1359 3344
2056 7800
3088 2056
3244 3088
3577 5566
"""
mgr_index=mgr_nos.values # array([3344, 7800, 2056, 3088, 5566])
方法三:先根据mgr字段对DataFrame做去重,然后再获取mgr字段的值
mgr_index=df.drop_duplicates('mgr').mgr.dropna().astype(int).values
mgr_index # array([3344, 7800, 2056, 3088, 5566])
方法四:(方法三的分解动作)
先找到重复的元素,获取它们的索引
temp_index = df[df.duplicated('mgr')].index
temp_index #Int64Index([3211, 3233, 3251, 3344, 3588, 4466, 5234, 5566, 14, 15], dtype='int64', name='eno')
根据重复元素的索引删除这些行,再获取不重复的数据
df.drop(temp_index).mgr.dropna().astype(int).values #array([3344, 7800, 2056, 3088, 5566])
2.用花式索引的方式找出主管
df.loc[mgr_index]
"""
index ename job mgr sal comm dno 正式员工
eno
3344 7.0 黄蓉 销售主管 7800.0 3000 800.0 30.0 是
7800 13.0 张三丰 总裁 NaN 9000 1200.0 20.0 是
2056 1.0 乔 峰 分析师 7800.0 5000 1500.0 20.0 是
3088 2.0 李莫愁 设计师 2056.0 3500 800.0 20.0 是
5566 12.0 宋远桥 会计师 7800.0 4000 1000.0 10.0 是
"""
异常值处理(用指定的值替换掉原来的值 replace())
df.replace({
'是': True, '否': False})
"""
index ename job mgr sal comm dno 正式员工
eno
1359 0.0 大师 销售员 3344.0 1800 200.0 30.0 True
2056 1.0 乔 峰 分析师 7800.0 5000 1500.0 20.0 True
3088 2.0 李莫愁 设计师 2056.0 3500 800.0 20.0 True
3211 3.0 张无忌 程序员 2056.0 3200 0.0 20.0 True
3233 4.0 丘 处机 程序员 2056.0 3400 0.0 20.0 True
3244 5.0 欧阳锋 程序员 3088.0 3200 0.0 20.0 True
3251 6.0 张翠山 程序员 2056.0 4000 0.0 20.0 False
3344 7.0 黄蓉 销售主管 7800.0 3000 800.0 30.0 True
3577 8.0 杨过 会计 5566.0 2200 0.0 10.0 True
3588 9.0 朱九真 会计 5566.0 2500 0.0 10.0 False
4466 10.0 苗人凤 销售员 3344.0 2500 0.0 30.0 True
5234 11.0 郭靖 出纳 5566.0 2000 0.0 10.0 True
5566 12.0 宋远桥 会计师 7800.0 4000 1000.0 10.0 True
7800 13.0 张三丰 总裁 NaN 9000 1200.0 20.0 True
14 9005.0 骆昊 程序员 7800.0 10000 5000.0 20.0 False
15 NaN 王大锤 NaN NaN 8000 0.0 NaN NaN
"""
练习:
读取2018年北京积分落户数据
luohu_df = pd.read_csv('2018年北京积分落户数据.csv', index_col='id')
luohu_df
"""
name birthday company score
id
1 杨效丰 1972-12 北京利德华福电气技术有限公司 122.59
2 纪丰伟 1974-12 北京航天数据股份有限公司 121.25
3 王永 1974-05 品牌联盟(北京)咨询股份公司 118.96
4 杨静 1975-07 中科专利商标代理有限责任公司 118.21
5 张凯江 1974-11 北京阿里巴巴云计算技术有限公司 117.79
... ... ... ... ...
6015 孙宏波 1978-08 华为海洋网络有限公司北京科技分公司 90.75
6016 刘丽香 1976-11 福斯(上海)流体设备有限公司北京分公司 90.75
6017 周崧 1977-10 赢创德固赛(中国)投资有限公司 90.75
6018 赵妍 1979-07 澳科利耳医疗器械(北京)有限公司 90.75
6019 贺锐 1981-06 北京宝洁技术有限公司 90.75
6019 rows × 4 columns
"""
查看公司名字有“华为”的公司
luohu_df[luohu_df.company.str.contains('华为')]
"""
name birthday company score
id
130 常新苗 1981-01 北京华为数字技术有限公司 107.25
139 侯乃莹 1973-12 北京华为数字技术有限公司 107.05
144 陈国义 1975-09 北京华为数字技术有限公司 106.96
149 刘艳军 1977-02 北京华为数字技术有限公司 106.91
153 谢美伦 1975-08 北京华为数字技术有限公司 106.84
... ... ... ... ...
5942 高久亮 1982-04 北京华为数字技术有限公司 90.83
5948 毛道娟 1980-05 北京华为数字技术有限公司 90.80
5983 魏建雄 1975-04 北京华为数字技术有限公司 90.79
5987 高晓光 1978-05 北京华为数字技术有限公司 90.79
6015 孙宏波 1978-08 华为海洋网络有限公司北京科技分公司 90.75
165 rows × 4 columns
"""
通过replace方法指定正则表达式将“北京华为技术研究所”和“华为技术北京研究所”统一替换为“华为”
luohu_df.replace(regex='(北京华为.*)|(华为技术.*)', value='华为', inplace=True)
luohu_df[luohu_df.company.str.contains('华为')]
"""
name birthday company score
id
130 常新苗 1981-01 华为 107.25
139 侯乃莹 1973-12 华为 107.05
144 陈国义 1975-09 华为 106.96
149 刘艳军 1977-02 华为 106.91
153 谢美伦 1975-08 华为 106.84
... ... ... ... ...
5942 高久亮 1982-04 华为 90.83
5948 毛道娟 1980-05 华为 90.80
5983 魏建雄 1975-04 华为 90.79
5987 高晓光 1978-05 华为 90.79
6015 孙宏波 1978-08 华为海洋网络有限公司北京科技分公司 90.75
165 rows × 4 columns
"""
2.数据删除
使用drop方法删除指定的行或列
index指定行索引,columns指定列索引
删除行
数据:
index ename job mgr sal comm dno 正式员工
eno
1359 0.0 大师 销售员 3344.0 1800 200.0 30.0 是
2056 1.0 乔 峰 分析师 7800.0 5000 1500.0 20.0 是
3088 2.0 李莫愁 设计师 2056.0 3500 800.0 20.0 是
3211 3.0 张无忌 程序员 2056.0 3200 0.0 20.0 是
3233 4.0 丘 处机 程序员 2056.0 3400 0.0 20.0 是
3244 5.0 欧阳锋 程序员 3088.0 3200 0.0 20.0 是
3251 6.0 张翠山 程序员 2056.0 4000 0.0 20.0 否
3344 7.0 黄蓉 销售主管 7800.0 3000 800.0 30.0 是
3577 8.0 杨过 会计 5566.0 2200 0.0 10.0 是
3588 9.0 朱九真 会计 5566.0 2500 0.0 10.0 否
4466 10.0 苗人凤 销售员 3344.0 2500 0.0 30.0 是
5234 11.0 郭靖 出纳 5566.0 2000 0.0 10.0 是
5566 12.0 宋远桥 会计师 7800.0 4000 1000.0 10.0 是
7800 13.0 张三丰 总裁 NaN 9000 1200.0 20.0 是
14 9005.0 骆昊 程序员 7800.0 10000 5000.0 20.0 否
15 NaN 王大锤 NaN NaN 8000 0.0 NaN NaN
方法一:根据index这一索引列来删除行(注意drop()中的inde是参数列索引 )
df.set_index('index').drop(index=[0, 2, 7])
"""
ename job mgr sal comm dno 正式员工
index
1.0 乔 峰 分析师 7800.0 5000 1500.0 20.0 是
3.0 张无忌 程序员 2056.0 3200 0.0 20.0 是
4.0 丘 处机 程序员 2056.0 3400 0.0 20.0 是
5.0 欧阳锋 程序员 3088.0 3200 0.0 20.0 是
6.0 张翠山 程序员 2056.0 4000 0.0 20.0 否
8.0 杨过 会计 5566.0 2200 0.0 10.0 是
9.0 朱九真 会计 5566.0 2500 0.0 10.0 否
10.0 苗人凤 销售员 3344.0 2500 0.0 30.0 是
11.0 郭靖 出纳 5566.0 2000 0.0 10.0 是
12.0 宋远桥 会计师 7800.0 4000 1000.0 10.0 是
13.0 张三丰 总裁 NaN 9000 1200.0 20.0 是
9005.0 骆昊 程序员 7800.0 10000 5000.0 20.0 否
NaN 王大锤 NaN NaN 8000 0.0 NaN NaN
"""
方法二:根据eno删除列
df.drop(index=[1359,3088,3344])
"""
index ename job mgr sal comm dno 正式员工
eno
2056 1.0 乔 峰 分析师 7800.0 5000 1500.0 20.0 是
3211 3.0 张无忌 程序员 2056.0 3200 0.0 20.0 是
3233 4.0 丘 处机 程序员 2056.0 3400 0.0 20.0 是
3244 5.0 欧阳锋 程序员 3088.0 3200 0.0 20.0 是
3251 6.0 张翠山 程序员 2056.0 4000 0.0 20.0 否
3577 8.0 杨过 会计 5566.0 2200 0.0 10.0 是
3588 9.0 朱九真 会计 5566.0 2500 0.0 10.0 否
4466 10.0 苗人凤 销售员 3344.0 2500 0.0 30.0 是
5234 11.0 郭靖 出纳 5566.0 2000 0.0 10.0 是
5566 12.0 宋远桥 会计师 7800.0 4000 1000.0 10.0 是
7800 13.0 张三丰 总裁 NaN 9000 1200.0 20.0 是
14 9005.0 骆昊 程序员 7800.0 10000 5000.0 20.0 否
15 NaN 王大锤 NaN NaN 8000 0.0 NaN NaN
"""
删除列
用Python中删除字典键值对的方式删除列(注意删除后就真的删除了)
del df['index']
df
或者:pop() 能达到同样的效果(注意删除后就真的删除了)
df.pop('index')
或者:使用drop方法删除指定的行或列(注意删除后就真的删除了)
df.drop(columns='index', inplace=True)
output:
误删除后想要恢复index列
reset_index()恢复列
df.reset_index(inplace=True)
df=df.set_index('eno') # 这一步是为了恢复至和原来一样的索引
或者:直接添加一列,再通过reindex()调整列的顺序
#df.columns #['ename', 'job', 'mgr', 'sal', 'comm', 'dno', '正式员工','index']
# 添加一列
new_index = np.arange(0, 16)
df['index']=new_index
# 调整行索引
df.reindex(columns=['index','ename', 'job', 'mgr', 'sal', 'comm', 'dno', '正式员工'])

3.数据转换
apply() / transform() / applymap()方法
关于apply()和applymap()方法的区别请看这里
每个员工的工资增加1000元:(使用apply())
df.sal = df.sal.apply(lambda x: x + 1000)
df
"""
eno ename job mgr sal comm dno
0 1359 胡 一刀 销售员 3344.0 4800 200.0 30
1 2056 乔 峰 分析师 7800.0 8000 1500.0 20
2 3088 李莫愁 设计师 2056.0 6500 800.0 20
3 3211 张无忌 程序员 2056.0 6200 NaN 20
4 3233 丘 处机 程序员 2056.0 6400 NaN 20
5 3244 欧阳锋 程序员 3088.0 6200 NaN 20
6 3251 张翠山 程序员 2056.0 7000 NaN 20
7 3344 黄蓉 销售主管 7800.0 6000 800.0 30
8 3577 杨过 会计 5566.0 5200 NaN 10
9 3588 朱九真 会计 5566.0 5500 NaN 10
10 4466 苗人凤 销售员 3344.0 5500 NaN 30
11 5234 郭靖 出纳 5566.0 5000 NaN 10
12 5566 宋远桥 会计师 7800.0 7000 1000.0 10
13 7800 张三丰 总裁 NaN 12000 1200.0 20
"""
数据准备:
scores=np.random.randint(30,80,(5,3))
scores
"""
array([[66, 39, 66],
[75, 48, 76],
[33, 33, 48],
[55, 47, 72],
[56, 74, 50]])
"""
score_df=pd.DataFrame(
data=scores,
index=np.arange(1001,1006),
columns=['语文','数学','英语']
)
score_df
"""
语文 数学 英语
1001 66 39 66
1002 75 48 76
1003 33 33 48
1004 55 47 72
1005 56 74 50
"""
用开方乘以10的方法处理考试成绩:使用applymap()
score_df.applymap(lambda x:round(x**0.5*10,1))
"""
语文 数学 英语
1001 81.2 62.4 81.2
1002 86.6 69.3 87.2
1003 57.4 57.4 69.3
1004 74.2 68.6 84.9
1005 74.8 86.0 70.7
"""
使用transform方法将多个函数作用到数据上
def calc1(x):
return round(x ** 0.5 * 10, 1)
def calc2(x):
return x + 20
ser = score_df.语文
ser.transform([calc1,calc2])
"""
calc1 calc2
1001 81.2 86
1002 86.6 95
1003 57.4 53
1004 74.2 75
1005 74.8 76
"""
字符串向量
核心操作:拆分 / 合并 / 匹配 / 替换 / 抽取
方法:大小写 / 转类型 / 格式化
数据准备
ser = pd.Series(['apple', 'pitaya', 'litche', 'durian', 'waxberry', 'blueberry'])
将数据序列中的字符串变成大写:
通常方法:apply()
ser.apply(lambda x:x.upper())
字符串向量法:用字符串向量,再用字符串的相关方法解决
ser.str.upper()
output:
0 APPLE
1 PITAYA
2 LITCHE
3 DURIAN
4 WAXBERRY
5 BLUEBERRY
dtype: object
其他练习:
ser.str.capitalize()
"""
0 Apple
1 Pitaya
2 Litche
3 Durian
4 Waxberry
5 Blueberry
dtype: object
"""
ser.str.find('a')
"""
0 0
1 3
2 -1
3 4
4 1
5 -1
dtype: int64
"""
ser.str.split('a')
"""
0 [, pple]
1 [pit, y, ]
2 [litche]
3 [duri, n]
4 [w, xberry]
5 [blueberry]
dtype: object
"""
ser.str.rjust(20)
"""
0 apple
1 pitaya
2 litche
3 durian
4 waxberry
5 blueberry
dtype: object
"""
补充:UUID方式产生数据ID的字段
在很多商业项目中,数据库表的主键不能够使用自增长编号,因为在有并发insert操作时,自增长编号的方式会影响性能。所以,很多产品中会选择使用UUID(Universal Unique IDentifier)的方式来产生数据的ID字段。
生成分布式环境(多机环境)下全局唯一标识符的算法比较多,现在的项目中用的比较多的Snowflake算法(雪花算法那)。
import uuid
for _ in range(10):
print(uuid.uuid1().hex)
1e3acb76b16711ebafcf68f728dcf2e9
1e3bb5c6b16711eba83368f728dcf2e9
1e3bca44b16711eba04468f728dcf2e9
1e3bca45b16711eba9db68f728dcf2e9
1e3bf0d1b16711ebb75c68f728dcf2e9
1e3bf0d2b16711eb876168f728dcf2e9
1e3c17e0b16711ebb1a368f728dcf2e9
1e3c17e1b16711eb8a3768f728dcf2e9
1e3c17e2b16711ebaf1668f728dcf2e9
1e3c17e3b16711eb8d4268f728dcf2e9
练习:读取拉勾网上招聘数据,找出数据分析岗位的平均工资是多少?
获取数据及查看信息:
# ANSI ---> GB2312 ---> GBK ---> GB18030
lagou_df = pd.read_csv(
'lagou.csv',
usecols=['_id', 'companyShortName', 'companySize','city', 'positionName', 'salary'],
# encoding='gbk'
)
lagou_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3140 entries, 0 to 3139
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 _id 3140 non-null object
1 city 3140 non-null object
2 companyShortName 3140 non-null object
3 companySize 3140 non-null object
4 positionName 3140 non-null object
5 salary 3140 non-null object
dtypes: object(6)
memory usage: 147.3+ KB
取前三个数据用来观察
lagou_df.head(3)
"""
_id city companyShortName companySize positionName salary
0 5de5e75734e608e63026c1bc 北京 达达-京东到家 2000人以上 数据分析岗 15k-30k
1 5de5e75734e608e63026c1bd 北京 音娱时光 50-150人 数据分析 10k-18k
2 5de5e75734e608e63026c1be 北京 千喜鹤 2000人以上 数据分析 20k-30k
"""
判断下_id列有无重复
方法一,获取不重复的数据,再获取数据量的大小
lagou_df.index.unique().size #3140
方法二:直接获取不重复的数据的数量
lagou_df.index.nunique() #3140
第一列没有用,设置’_id’为索引
lagou_df.set_index('_id',inplace=True)
"""
city companyShortName companySize positionName salary
_id
5de5e75734e608e63026c1bc 北京 达达-京东到家 2000人以上 数据分析岗 15k-30k
5de5e75734e608e63026c1bd 北京 音娱时光 50-150人 数据分析 10k-18k
...
...
3140 rows × 5 columns
"""
筛选出数据分析的岗位:
temp_df=lagou_df[lagou_df.positionName.str.contains('数据分析')]
temp_df
从工资中抽取出工资的下限值和上限值
result_df=temp_df.salary.str.extract(r'(\d+)[kK]?-(\d+)[kK]?')
result_df
"""
0 1
_id
5de5e75734e608e63026c1bc 15 30
5de5e75734e608e63026c1bd 10 18
5de5e75734e608e63026c1be 20 30
5de5e75734e608e63026c1bf 33 50
5de5e75734e608e63026c1c0 10 15
... ... ...
5de5ea0734e608e63026cdb5 8 10
5de5ea0734e608e63026cdb9 6 10
5de5ea0734e608e63026cdba 2 4
5de5ea0734e608e63026cdbb 6 12
5de5ea0a34e608e63026cdcc 8 12
1515 rows × 2 columns
"""
转成整数后,取上限值和下限值的平均值(axis=0),之后再取平均(axis=1)
ser=result_df.applymap(int).mean(axis=1)
ser
round(ser.mean(),2)
"""
_id
5de5e75734e608e63026c1bc 22.5
5de5e75734e608e63026c1bd 14.0
5de5e75734e608e63026c1be 25.0
5de5e75734e608e63026c1bf 41.5
5de5e75734e608e63026c1c0 12.5
...
5de5ea0734e608e63026cdb5 9.0
5de5ea0734e608e63026cdb9 8.0
5de5ea0734e608e63026cdba 3.0
5de5ea0734e608e63026cdbb 9.0
5de5ea0a34e608e63026cdcc 10.0
Length: 1515, dtype: float64
"""
# 18.93
时间日期向量
- date, time, year, month, day, hour, minute, second, microsecond, nanosecond, dayofweek, dayofyear, weekofyear, daysinmonth, quarter
- is_xxx
- round() / ceil() / floor()
数据准备:
luohu_df = pd.read_csv('2018年北京积分落户数据.csv', index_col='id')
luohu_df.info()
"""
Int64Index: 6019 entries, 1 to 6019
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 name 6019 non-null object
1 birthday 6019 non-null object
2 company 6019 non-null object
3 score 6019 non-null float64
dtypes: float64(1), object(3)
memory usage: 235.1+ KB
"""
luohu_df.head(3)
"""
name birthday company score
id
1 杨效丰 1972-12 北京利德华福电气技术有限公司 122.59
2 纪丰伟 1974-12 北京航天数据股份有限公司 121.25
3 王永 1974-05 品牌联盟(北京)咨询股份公司 118.96
"""
使用to_datetime()函数将字符串处理成时间日期
ser=pd.to_datetime(luohu_df.birthday)
"""
id
1 1972-12
2 1974-12
3 1974-05
4 1975-07
5 1974-11
...
6018 1979-07
6019 1981-06
Name: birthday, Length: 6019, dtype: object
"""
通过时间日期向量获取年份和月份
0 - 星期一, 1 - 星期二,……,6 - 星期日
luohu_df['year'] = ser.dt.year
luohu_df['month'] = ser.dt.month
luohu_df['weekday'] = ser.dt.dayofweek
luohu_df['quarter'] = ser.dt.quarter
luohu_df
"""
name birthday company score year month weekday quarter
id
1 杨效丰 1972-12 北京利德华福电气技术有限公司 122.59 1972 12 4 4
2 纪丰伟 1974-12 北京航天数据股份有限公司 121.25 1974 12 6 4
3 王永 1974-05 品牌联盟(北京)咨询股份公司 118.96 1974 5 2 2
"""
python datetime模块的datetime库
from datetime import datetime
d1 = datetime(2008, 10, 1)
print(d1)
d2 = datetime.now()
print(d2)
delta = d2 - d1
print(delta.days, delta.seconds)
"""
2008-10-01 00:00:00
2021-05-10 21:10:36.904474
4604 76236
"""
将生日换算成年龄
base_date=datetime(2018,7,1)
ages=(base_date-pd.to_datetime(luohu_df.birthday)).dt.days//365
luohu_df['age']=ages
luohu_df
"""
name birthday company score year month weekday quarter age
id
1 杨效丰 1972-12 北京利德华福电气技术有限公司 122.59 1972 12 4 4 45
2 纪丰伟 1974-12 北京航天数据股份有限公司 121.25 1974 12 6 4 43
"""
六. 数据分析
1.获取描述性统计信息
lagou_df = pd.read_csv(
'lagou.csv',
usecols=['_id', 'companyShortName', 'city', 'positionName', 'salary'],
# encoding='gbk' # windows系统在修改了文件内容后出现编码问题用得到
)
lagou_df.info()
"""
RangeIndex: 3140 entries, 0 to 3139
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 _id 3140 non-null object
1 city 3140 non-null object
2 companyShortName 3140 non-null object
3 positionName 3140 non-null object
4 salary 3140 non-null object
dtypes: object(5)
memory usage: 122.8+ KB
"""
练习1:计算每个城市的数据分析岗位平均薪资
知识点:groupby()方法
找到岗位名称的字符串向量中的包含‘数据分析’项的表
temp_df = lagou_df[lagou_df.positionName.str.contains('数据分析')]
temp_df

处理salary列,利用salary的str向量中的extract方法,通过正则表达式提取工资范围,求取均值作为新的salary列
salary = temp_df.salary.str.extract(r'(\d+)[kK]?-(\d+)[kK]?').applymap(int).mean(axis=1)
temp_df['salary'] = salary
temp_df

根据城市分组,获取工资求均值
ser = np.round(temp_df.groupby('city').salary.mean(), 1)
ser
"""
city
上海 20.2
北京 21.0
南京 14.7
厦门 12.7
天津 7.8
广州 14.8
成都 10.8
杭州 20.1
武汉 14.3
深圳 19.5
苏州 15.2
西安 8.1
长沙 11.4
Name: salary, dtype: float64
"""
画图:
ser.plot(figsize=(8, 4), kind='bar')
plt.xticks(np.arange(ser.size), labels=ser.index, rotation=0)
plt.yticks(np.arange(0, 26, 5))
plt.xlabel('城市')
plt.ylabel('平均薪资(k)')
for i in range(ser.size):
plt.text(i, ser[i], ser[i], ha='center')
plt.show()

plt.text() 常用参数说明:
常用参数说明:
x,y:显示内容的坐标位置
s:显示内容
fontdict:一个定义s格式的dict
fontsize:字体大小
color:str or tuple, 设置字体颜色 ,单个字符候选项{
‘b’, ‘g’, ‘r’, ‘c’, ‘m’, ‘y’, ‘k’, ‘w’},也可以’black’,'red’等,tuple时用[0,1]之间的浮点型数据,RGB或者RGBA, 如: (0.1, 0.2, 0.5)、(0.1, 0.2, 0.5, 0.3)等
backgroundcolor:字体背景颜色
horizontalalignment(ha):设置垂直对齐方式,可选参数:left,right,center
verticalalignment(va):设置水平对齐方式 ,可选参数 : ‘center’ , ‘top’ , ‘bottom’ ,‘baseline’
rotation(旋转角度):可选参数为:vertical,horizontal 也可以为数字
alpha:透明度,参数值0至1之间
练习2:
知识点:分组聚合操作(# SAC —> Split - Aggregate - Combine)
数据准备:
import pymysql
conn = pymysql.connect(
host='47.104.xx.xxx', port=3306, user='guest',
password='xxxxxx', database='school', charset='utf8mb4'
)
conn
# student_df = pd.read_sql('select * from tb_student', conn, index_col='stuid')
student_df

- 数据替换(*处理数据常用方法,重要):
student_df.replace({
'stusex': {
0: '女', 1: '男'}}, inplace=True)
- 统计男女学生的人数(用性别分组再使用count聚合)
student_df.groupby('stusex').stuname.count()
"""
stusex
女 3
男 7
Name: stuname, dtype: int64
"""
- 统计每个学院男女学生的人数(多级索引)
ser=student_df.groupby(['collid','stusex']).stuname.count()
ser
"""
collid stusex
1 女 2
男 4
2 男 1
3 女 1
男 2
Name: stusex, dtype: int64
"""
此时该数据序列的索引为:
ser.index
"""
MultiIndex([(1, '女'),
(1, '男'),
(2, '男'),
(3, '女'),
(3, '男')],
names=['collid', 'stusex'])
"""
使用agg()方法一次性执行多个聚合函数
数据准备:
import pymysql
conn = pymysql.connect(
host='47.104.xx.xxx', port=3306, user='guest',
password='xxxxxx', database='hrs', charset='utf8mb4'
)
conn
df = pd.read_sql('select * from tb_emp', conn)
df['comm'].fillna(0,inplace=True)
df
| eno | ename | job | mgr | sal | comm | dno | |
|---|---|---|---|---|---|---|---|
| 0 | 1359 | 胡 一刀 | 销售员 | 3344.0 | 1800 | 200.0 | 30 |
| 1 | 2056 | 乔 峰 | 分析师 | 7800.0 | 5000 | 1500.0 | 20 |
| 2 | 3088 | 李莫愁 | 设计师 | 2056.0 | 3500 | 800.0 | 20 |
| 3 | 3211 | 张无忌 | 程序员 | 2056.0 | 3200 | 0.0 | 20 |
| 4 | 3233 | 丘 处机 | 程序员 | 2056.0 | 3400 | 0.0 | 20 |
| 5 | 3244 | 欧阳锋 | 程序员 | 3088.0 | 3200 | 0.0 | 20 |
| 6 | 3251 | 张翠山 | 程序员 | 2056.0 | 4000 | 0.0 | 20 |
| 7 | 3344 | 黄蓉 | 销售主管 | 7800.0 | 3000 | 800.0 | 30 |
| 8 | 3577 | 杨过 | 会计 | 5566.0 | 2200 | 0.0 | 10 |
| 9 | 3588 | 朱九真 | 会计 | 5566.0 | 2500 | 0.0 | 10 |
| 10 | 4466 | 苗人凤 | 销售员 | 3344.0 | 2500 | 0.0 | 30 |
| 11 | 5234 | 郭靖 | 出纳 | 5566.0 | 2000 | 0.0 | 10 |
| 12 | 5566 | 宋远桥 | 会计师 | 7800.0 | 4000 | 1000.0 | 10 |
| 13 | 7800 | 张三丰 | 总裁 | NaN | 9000 | 1200.0 | 20 |
def ptp(x):
return x.max()-x.min()
# 使用agg()方法一次性执行多个聚合函数
df.groupby('dno').sal.agg(['max','min','mean',ptp])
| max | min | mean | ptp | |
|---|---|---|---|---|
| dno | ||||
| 10 | 4000 | 2000 | 2675.000000 | 2000 |
| 20 | 9000 | 3200 | 4471.428571 | 5800 |
| 30 | 3000 | 1800 | 2433.333333 | 1200 |
2.排序和Top-N
待补充
在这里插入代码片