你该知道的浏览器请求与Header
从url到页面展示过程中发生了什么
让我们从一道“经典前端面试题” —— 从url到页面展示过程中发生了什么说起:
- url解析,根据dns系统进行ip查找;
① 网络标准规定了 url 只能是数字和字母,还有一小些特殊符号。url 可以携带参数。如果不对 url 转义可能会出现歧义。比如
?key=value中可能key本身就包括=符号;
url 编码是以 utf-8 为标准,但不是所有浏览器对所有情况都是这样。像JS的话就有encodeURIComponent和encodeURI来保证以 utf-8 编码。
② dns解析流程是 hosts(映射ip) -> 本地dns解析器(缓存) -> 计算机上配置的dns服务器 -> 全球根dns服务器
前端的dns优化就是在 head 里添加:和
- 查找到 ip 之后,进行 TCP 三次握手发送http请求;
- 建立完链接,请求HTML文件/资源,如果在缓存中有就直接拿,否则向后端要;
浏览器首次加载资源成功时,服务器返回200,此时浏览器不仅把资源下载了,而且把 response 的 header 一并缓存;
下一次加载资源时,首先会经过强缓存处理,cache-control优先级最高,比如cache-control:no-cache就直接进入协商缓存步骤;如果是max-age=xxx,就会先比较当前时间和上一次返回200时的时间差(比较date属性),如果没超过max-age,命中强缓存,不发请求直接从本地缓存中读取该文件(这里注意:如果无cache-control字段,会去比较expires),过期的话就进入下一阶段:协商缓存;
协商缓存阶段会比较两个字段:If-Modified-Since和If-None-Match,他们会在 header 中跟随请求到达服务端。首先会比较If-None-Match-Etag,如果相同则命中协商缓存,返回304;如果不一致返回新资源 & 200.然后是If-Modified-Since-last-modified(跟服务端获取的文件最近改动的时间比较),如果一致命中协商缓存,返回304;否则返回新的 last-modified 值和文件以及200;
- 服务器处理完会返回HTML;
- TCP 四次挥手结束请求;
- 浏览器解析HTML,有“构建 DOM 树”->“构建 CSSOM 树”->“执行JS”->“根据 DOM 和 CSSOM 合并生成 render 树”->“渲染”->“布局”->“绘制”
一次完整的请求正式结束。其实这和 img 的 src、script 的 src 一样,都是一次get请求!
请求与响应中的Header
上面缓存那里提到了一些头字段,我们来看一下:

可以看到,一次请求包括“请求”和“响应”两个部分。他们具体是:
- 请求行
- 请求头
- 请求体
- 状态行(响应)
- 响应头(响应)
- 响应正文(响应)
响应头
其中“请求头”和“响应头”使我们比较关注的。先来看响应头 —— 他们都是由服务端控制的,用来实现不同的功能。比较常见的有:
- etag:资源唯一标识
- last-modified:请求资源的最后修改时间
- cache-control
- expires
- Date
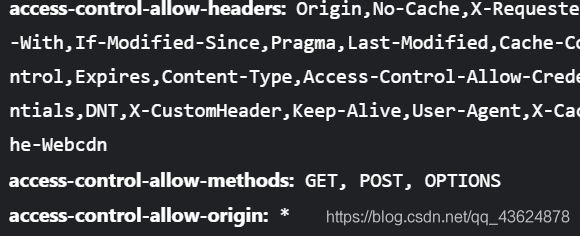
- Access-Control-Allow系
- Set-Cookie: 服务端设置管理状态所用的cookie信息(这里面也有expires指令,它仅控制cookie的存活时间,如果不指定则默认到浏览器关闭)(在里面还可以通过 Secure 和 HttpOnly 来进行web安全防御)
先说 Access-Control-Allow系,他们是用来跨域和设置服务端允许接收什么形式的请求;
然后是 Date:服务端消息发出的时间。它的值应该是上一次请求为200时的时间,用来在下一次请求强缓存阶段和 max-age 属性做比较,它是一个 GMT 时间;
然后是 expires:它是一个绝对时间,规定了缓存在什么时间后过期。因为绝对时间对应用场景的限制,才出现了 max-age :相对时间(相对资源上一次被请求的时间);
最重要的便是这个 cache-control 了。它包含几个值:
- public:表明响应可以被任何对象缓存;
- private:响应只能被客户端缓存;
- no-store:表示当前请求资源不准被缓存;
- no-cache:资源有缓存,但必须向服务端发一次请求(跳过强缓存,直接进入协商缓存,比较 Etag 和 last-modified)
- max-age
- s-maxage
- …
几个经典问题
1、这里 no-store 和 no-cache 引起了我的注意:他们有什么用呢?真的如定义所说么?
经过验证,对于 no-store 来说,正如它定义的那样,资源不会被以任何形式的缓存,在下一次请求时依然会被服务器认为是“第一次请求”;而对于 no-cache来说,它更偏重比较两次资源有没有变化,它和 max-age=0 表现一致,在下一次请求时,虽然浏览器缓存中有,但仍然向服务端发一次请求确认(会携带Etag),如果资源没有变化,返回304(只返回)表示资源还可以继续使用,浏览器才会从缓存中拿到资源;否则按照新的请求返回并重新缓存。
2、为什么 no-cache 优先级比 no-store 高?
这个问题笔者翻遍资料也没找到,但是根据上面的描述我可以猜测:是因为确保文件的时效性的同时兼顾性能。如果请求发现文件并没有改动,这时候实际上也并不需要重新传输资源并拿到页面上,直接从缓存中取的话更快一些。
3、为什么cache-control(有指定 max-age 时)的优先级比expires高?
原因在于Expires控制缓存的原理是使用客户端的时间与服务端返回的时间做对比,那么如果客户端与服务端的时间因为某些原因(例如时区不同;客户端和服务端有一方的时间不准确)发生误差,那么强制缓存则会直接失效,这样的话强制缓存的存在则毫无意义;而且前面说了,expires控制的绝对时间,也就是说你指定的是哪一年几月几日几时几分几秒,大多数场景下这样非常不方便。
哦对了,上面不断提到了协商缓存阶段用到的几个头字段 Etag 和 If-None-Match、last-modified 和 If-Modified-Since,前面说会首先比较Etag,那为什么 Etag 优先级要更高一些呢?
- 首先,If-Modified-Since 只能检查秒级别的时间(或者说 Unix 记录 MTIME 只能精确到秒),对于文件修改非常频繁的情况,它就无能为力了。
- 其次,last-modified 日期并不可靠。有时开发人员会在修复某些内容后将所有文件上传到服务器,即使内容仅在子集上修改,也会重置所有文件的 last-modified 日期。
- 而 Etag 不一样,它是由开发者生成的对应资源在服务端的唯一标识,它本质上是使用像 SHA256 这样的散列函数生成的一段 hash值。
请求头
http请求中的“请求头”同样优秀,这里列举一些常见的:
- Accept系:客户端可接受的一些编码、内容类型等方面的设置
- Cache-Control:本资源的缓存机制
- Connection:是否需要长久连接(http1.1默认开启)
- cookie:发送请求时,会把保存在该请求域名下的所有cookie一起发送过去
- content系:请求的信息
- Date:发送请求的日期
- Origin:发送请求的资源的“协议名+域名”
- referer(referrer):发送请求的资源的地址
- Upgrade:传输协议(学过websocket的应该不怎么陌生)
- User-agent:用户信息
- If-None-Match:值为服务器先前响应的Etag,用来比较判断是否资源发生了改变
- If-Modified-Since:请求资源是否在指定时间后才被修改
- …
这里发现:请求头中有 cache-control 字段,而响应头中也有这个字段!他们是怎么发挥作用的?
事实上,它们之间的关系是:响应头(后端设置的)中控制缓存的开启,而请求头(前端ajax设置)可控制不缓存。 我们用 node做服务器来看一下:
// 前端代码
const ajax=new XMLHttpRequest();
ajax.open('get','http://localhost:8083/assets');
// ajax.setRequestHeader('cache-control','max-age=0');
ajax.onreadystatechange=function(){
if(ajax.readyState==4 && ajax.status==200){
console.log(ajax.responseText);
}
}
ajax.send()
这段代码中有一行注释,打开则表示前端设置不进行缓存,如果打开,则请求时的请求头与响应头是这样的(此时每次请求都不会再走强缓存,而是直接向服务端发送请求):
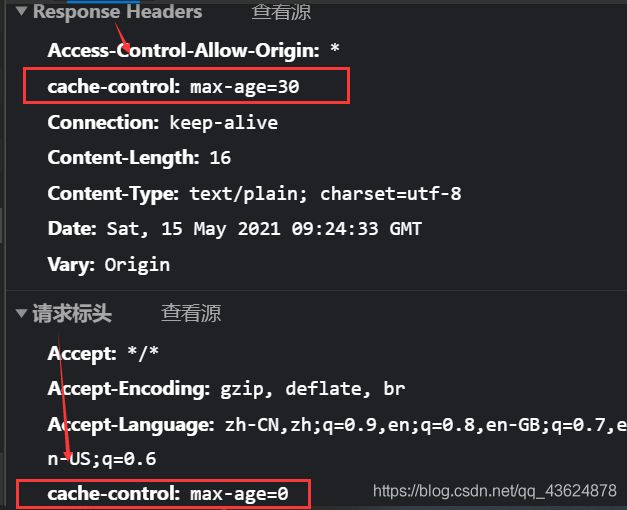
但若关闭注释,表示一切以后端设置的为主。(这种情况 Request Header 里面是没有 cache-control 这个字段的)
// koa代码
const Koa=require("koa");
const Router=require("koa-router");
const cors=require('koa2-cors');
//引入静态服务模块
const staticFiles = require('koa-static');
const router=new Router();
const app=new Koa();
app.use(cors({
origin:'*',
credentials:true // koa中控制允许接收cookie的方式
}))
app.use(staticFiles(__dirname + '/试验的HTML页面都在这'))
app.use(async(ctx,next)=>{
console.log('这是全局测试',Date.now())
await next()
})
router.get('/assets',async (ctx,next)=>{
console.log(ctx);
ctx.set('cache-control', 'max-age=30');
ctx.body='这是一次test'
})
app.use(router.routes())
app.use(router.allowedMethods())
app.listen(8083);
我们可以看下这时候的效果:
请求头中还有两个字段是需要重点提到的:
首先是cookie —— 可能前端都听过“cookie会被自动携带到 header 中发送到服务端”。有时候我们也会配合后端使用token(JWT)。这里涉及到“简单请求”和“非简单请求”的概念:
- 简单请求:请求方法是GET、POST、HEAD之一,且HTTP头信息只有/少于“
Accept”、“Accept-Language”、“Content-Language”、“Last-Event-ID”、“Content-Type”,并且Cnotent-Type的值仅限于“application/x-www-form-urlencoded”、“multipart/form-data”、“text/plain”; - 非简单请求:对服务器有特殊要求,比如请求方式是PUT、DELETE,或者
Content-Type字段类型是application/json,或者HTTP头信息中加了自定义header(比如token);
他们通常发生在“跨域请求”中的 cors 场景中(这属于Ajax请求的范畴,也是浏览器请求的一种,故而放到本文)。
其次是 origin ——它也和跨域密切相关,我们一起聊聊。
跨域的解决
说起跨域,简单来说就是浏览器对两个不同源的资源之间资源共享的限制。前端js对跨域的解决方法有很多,这里说下最主要的两种:cors和jsonp。
cors原理
对于简单请求,浏览器直接发出CORS请求。具体来说,就是在请求头信息中增加一个 origin 字段(这是浏览器自动添加的)。如果 origin 指定的源不在许可范围内,服务端会返回一个正常的HTTP响应。浏览器发现响应头信息中没有包含 Access-Control-Allow-Origin字段,就知道出错了,从而抛出一个错误,这个错误被XMLHttpRequest的 onerror 回调捕获。
注意:这种情况下无法通过状态码识别,因为HTTP回应的状态码有可能也是200。
怎么判断origin指定的源在不在许可范围内?这就是cors解决跨域的方法:后端配置一些响应头,在里面指定域名、请求方法等信息:
// springMVC 代码
@Configuration
public class CrosConfig implements WebMvcConfigurer {
@Override
public void addCorsMappings(CorsRegistry registry) {
registry.addMapping("/**")
.allowedOrigins("*")
.allowedMethods("*")
.allowedHeaders("*");
}
}
简单请求中要让浏览器携带cookie必须手动在ajax中设置:
xhr.withCredentials=true;
同时要让服务端同意(接受),通过指定 Access-Control-Expose-Credentials 字段。
对于非简单请求的跨域cors,浏览器会首先发出类型为 OPTIONS 的“预检请求”,请求地址相同,浏览器询问服务端当前网页所在域名是否在服务端的许可名单中,服务端对“预检请求”处理,并对 Response Header 添加验证字段,客户端接收到预检请求的返回值进行一次请求预判断,验证通过后主请求发起。这种情况浏览器只有在第一次请求后得到肯定答复时才发出主请求,否则会直接报错!
非简单请求在服务端的配置和简单请求差不多,唯一不同的是:Allow-Origin字段必须是确定的(不能是“ * ”)!
关于这点,有的说可以有的说不行。笔者在项目中测试时不行的,也可能和项目的其他某些配置有关。
jsonp
jsonp的原理是利用了像script、img这类标签的src属性并不被同源策略约束的特性。它是动态生成script标签的方式。jsonp只允许get请求!
jsonp的实现模式是callback。也就是说,我们必须要接收一个回调函数去拿到返回值:
<html lang="en">
<head>
<meta charset="utf-8">
head>
<body>
<script type='text/javascript'>
// 后端返回直接执行的方法,相当于执行这个方法,由于后端把返回的数据放在方法的参数里,所以这里能拿到res。
window.showLocation = function (res) {
console.log(res)
//执行ajax回调
}
script>
<script src='http://127.0.0.1:8080?callback=showLocation' type='text/javascript'>script>
body>
html>
和这段代码表述的意思相同,jsonp的原理就是:创建一个回调函数,然后在远程服务上调用这个函数并且将JSON数据作为参数传递,完成回调(它的本质是在服务端以结果为参数调用传递过去的函数名,并且将这一切返回给前端,这样就相当于在js中直接执行了函数)。
// node.js服务端代码
const http = require("http");
const server = http.createServer();
server.on("request", (req, res) => {
res.setHeader("Content-Type", "text/html;charset=utf-8");
res.end("showLocation('我是返回值')");
});
server.listen(8080, () => {
console.log("请访问 http://127.0.0.1:8080");
});
为什么jsonp要以这种方式?
一般情况下,我们希望这个script标签能够动态调用,而不是固定在HTML中所以没等页面显示完就执行了,很不灵活。我们可以通过js动态创建script标签,然后以回调函数名作为参数传递,回调函数的参数又是服务端调用这个参数后传递进去的结果。这样就可以灵活调用远程服务了。