代码def append_GAN Compression 2:代码解读

请务必先看原paper,可参考上篇解析:
科技猛兽:GAN Compression原理分析zhuanlan.zhihu.com
原作者的github项目链接:
https://github.com/mit-han-lab/gan-compressiongithub.com代码解读:
简要画了一下代码的调用关系:
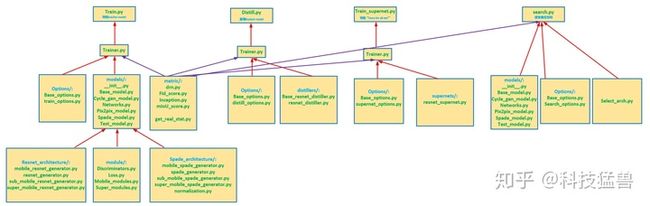
观察目录应该和上篇分析的GauGAN结构相似,多出了NAS和蒸馏的部分。我们首先看代码结构:
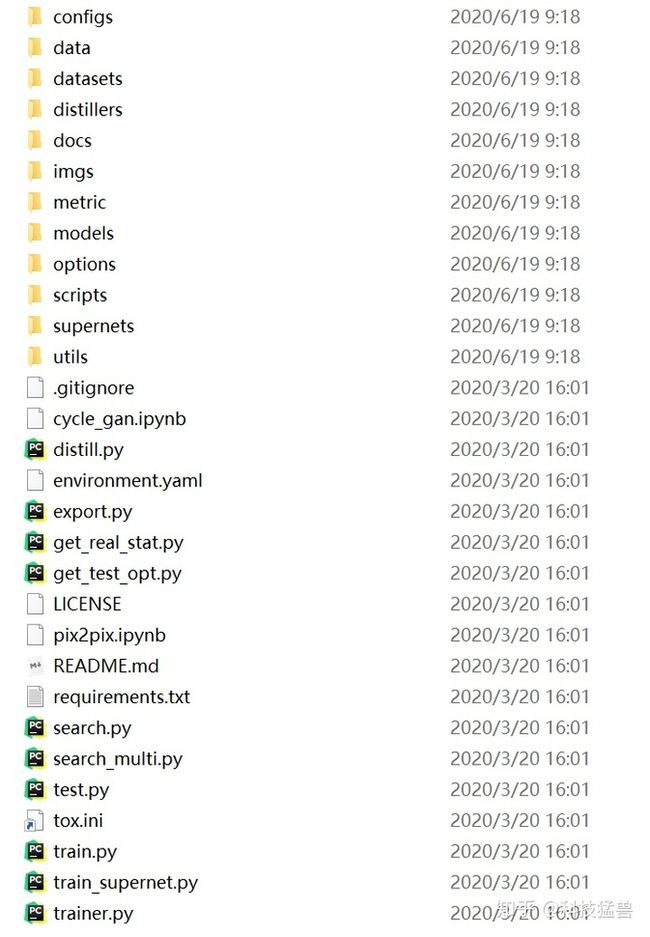
在这里简要说明每个package和module的功能以及实现方式:
configs/:

resnet_configs.py:
import random
class ResnetConfigs:
def __init__(self, n_channels):
self.attributes = ['n_channels']
self.n_channels = n_channels
def sample(self):
ret = {}
ret['channels'] = []
for n_channel in self.n_channels:
ret['channels'].append(random.choice(n_channel))
return ret
def largest(self):
ret = {}
ret['channels'] = []
for n_channel in self.n_channels:
ret['channels'].append(max(n_channel))
return ret
def smallest(self):
ret = {}
ret['channels'] = []
for n_channel in self.n_channels:
ret['channels'].append(min(n_channel))
return ret
def all_configs(self):
def yield_channels(i):
if i == len(self.n_channels):
yield []
return
for n in self.n_channels[i]:
for after_channels in yield_channels(i + 1):
yield [n] + after_channels
for channels in yield_channels(0):
yield {
'channels': channels}
def __call__(self, name):
assert name in ('largest', 'smallest')
if name == 'largest':
return self.largest()
elif name == 'smallest':
return self.smallest()
else:
raise NotImplementedError
def __str__(self):
ret = ''
for attr in self.attributes:
ret += 'attr: %sn' % str(getattr(self, attr))
return ret
def __len__(self):
ret = 1
for n_channel in self.n_channels:
ret *= len(n_channel)
def get_configs(config_name):
if config_name == 'channels-48':
return ResnetConfigs(n_channels=[[48, 32], [48, 32], [48, 40, 32],
[48, 40, 32], [48, 40, 32], [48, 40, 32],
[48, 32, 24, 16], [48, 32, 24, 16]])
elif config_name == 'channels-32':
return ResnetConfigs(n_channels=[[32, 24, 16], [32, 24, 16], [32, 24, 16],
[32, 24, 16], [32, 24, 16], [32, 24, 16],
[32, 24, 16], [32, 24, 16]])
elif config_name == 'test':
return ResnetConfigs(n_channels=[[8], [6, 8], [6, 8],
[8], [8], [8],
[8], [8]])
else:
raise NotImplementedError('Unknown configuration [%s]!!!' % config_name)配置了一些层的channel数,largest,smallest等函数应该是选择这一层channel数的大小。
data/:

这个文件夹下的代码定义的是dataset类,只不过分了好多种:
base_dataset.py:
BaseDataset继承PyTorch的data.Dataset类,overwrite了__init__(),__len__(),__getitem__()函数,modify_commandline_options写得和GauGan里面的极其相似,这里推荐阅读这篇文章:
学习python的正确姿势:Python 各种下划线都是啥意思_、_xx、xx_、__xx、__xx__、_classname_zhuanlan.zhihu.com
__scale_width()为调整图片的宽和高,保持相同的比例。__crop()裁剪图片的尺寸。__flip()为翻转图片,get_transform()利用以上函数定义预处理操作,返回值为transforms.Compose(transform_list)。其他dataset.py文件都继承了BaseDataset(), get_transform()函数。
定义dataset类的一般方法是:
Step 1: get a random image path: e.g., path = self.image_paths[index] Step 2: load your data from the disk: e.g., image = Image.open(path).convert('RGB'). Step 3: convert your data to a PyTorch tensor. You can use helpder functions such as self.transform. e.g., data = self.transform(image) Step 4: return a data point as a dictionary.
single_dataset.py:继承BaseDataset类定义最简单的dataset类。
class SingleDataset(BaseDataset):
"""This dataset class can load a set of images specified by the path --dataroot /path/to/data.
It can be used for generating CycleGAN results only for one side with the model option '-model test'.
"""
def __init__(self, opt):
"""Initialize this dataset class.
Parameters:
opt (Option class) -- stores all the experiment flags; needs to be a subclass of BaseOptions
"""
BaseDataset.__init__(self, opt)
self.A_paths = sorted(make_dataset(opt.dataroot, opt.max_dataset_size))
input_nc = self.opt.output_nc if self.opt.direction == 'BtoA' else self.opt.input_nc
self.transform = get_transform(opt, grayscale=(input_nc == 1))
def __getitem__(self, index):
"""Return a data point and its metadata information.
Parameters:
index - - a random integer for data indexing
Returns a dictionary that contains A and A_paths
A(tensor) - - an image in one domain
A_paths(str) - - the path of the image
"""
A_path = self.A_paths[index]
A_img = Image.open(A_path).convert('RGB')
A = self.transform(A_img)
return {
'A': A, 'A_paths': A_path}
def __len__(self):
"""Return the total number of images in the dataset."""
if self.opt.max_dataset_size == -1:
return len(self.A_paths)
else:
return self.opt.max_dataset_sizemetrics/:
定义评价指标。
models/:

base_model.py:
最基本的model类,被其他model类继承。它定义了一些helper functions:保存/加载模型,更新优化器,计算当前损失等等。
cycle_gan_model.py:
定义CycleGANModel类,继承BaseModel。
class CycleGANModel(BaseModel):
"""
This class implements the CycleGAN model, for learning image-to-image translation without paired data.
The model training requires '--dataset_mode unaligned' dataset.
By default, it uses a '--netG resnet_9blocks' ResNet generator,
a '--netD basic' discriminator (PatchGAN introduced by pix2pix),
and a least-square GANs objective ('--gan_mode lsgan').
CycleGAN paper: https://arxiv.org/pdf/1703.10593.pdf
"""
@staticmethod
def modify_commandline_options(parser, is_train=True):
"""Add new dataset-specific options, and rewrite default values for existing options.
Parameters:
parser -- original option parser
is_train (bool) -- whether training phase or test phase. You can use this flag to add training-specific or test-specific options.
Returns:
the modified parser.
For CycleGAN, in addition to GAN losses, we introduce lambda_A, lambda_B, and lambda_identity for the following losses.
A (source domain), B (target domain).
Generators: G_A: A -> B; G_B: B -> A.
Discriminators: D_A: G_A(A) vs. B; D_B: G_B(B) vs. A.
Forward cycle loss: lambda_A * ||G_B(G_A(A)) - A|| (Eqn. (2) in the paper)
Backward cycle loss: lambda_B * ||G_A(G_B(B)) - B|| (Eqn. (2) in the paper)
Identity loss (optional): lambda_identity * (||G_A(B) - B|| * lambda_B + ||G_B(A) - A|| * lambda_A) (Sec 5.2 "Photo generation from paintings" in the paper)
Dropout is not used in the original CycleGAN paper.
"""
assert is_train
parser = super(CycleGANModel, CycleGANModel).modify_commandline_options(parser, is_train)
parser.add_argument('--restore_G_A_path', type=str, default=None,
help='the path to restore the generator G_A')
parser.add_argument('--restore_D_A_path', type=str, default=None,
help='the path to restore the discriminator D_A')
parser.add_argument('--restore_G_B_path', type=str, default=None,
help='the path to restore the generator G_B')
parser.add_argument('--restore_D_B_path', type=str, default=None,
help='the path to restore the discriminator D_B')
parser.add_argument('--lambda_A', type=float, default=10.0,
help='weight for cycle loss (A -> B -> A)')
parser.add_argument('--lambda_B', type=float, default=10.0,
help='weight for cycle loss (B -> A -> B)')
parser.add_argument('--lambda_identity', type=float, default=0.5,
help='use identity mapping. '
'Setting lambda_identity other than 0 has an effect of scaling the weight of the identity mapping loss. '
'For example, if the weight of the identity loss should be 10 times smaller than the weight of the reconstruction loss, please set lambda_identity = 0.1')
parser.add_argument('--real_stat_A_path', type=str, required=True,
help='the path to load the ground-truth A images information to compute FID.')
parser.add_argument('--real_stat_B_path', type=str, required=True,
help='the path to load the ground-truth B images information to compute FID.')
parser.set_defaults(norm='instance', dataset_mode='unaligned',
batch_size=1, ndf=64, gan_mode='lsgan',
nepochs=100, nepochs_decay=100, save_epoch_freq=20)
return parser
def __init__(self, opt):
"""Initialize the CycleGAN class.
Parameters:
opt (Option class)-- stores all the experiment flags; needs to be a subclass of BaseOptions
"""
assert opt.isTrain
assert opt.direction == 'AtoB'
assert opt.dataset_mode == 'unaligned'
BaseModel.__init__(self, opt)
# specify the training losses you want to print out. The training/test scripts will call
self.loss_names = ['D_A', 'G_A', 'G_cycle_A', 'G_idt_A',
'D_B', 'G_B', 'G_cycle_B', 'G_idt_B']
# specify the images you want to save/display. The training/test scripts will call
visual_names_A = ['real_A', 'fake_B', 'rec_A']
visual_names_B = ['real_B', 'fake_A', 'rec_B']
if self.opt.lambda_identity > 0.0: # if identity loss is used, we also visualize idt_B=G_A(B) ad idt_A=G_A(B)
visual_names_A.append('idt_B')
visual_names_B.append('idt_A')
self.visual_names = visual_names_A + visual_names_B # combine visualizations for A and B
# specify the models you want to save to the disk. The training/test scripts will call and .
self.model_names = ['G_A', 'G_B', 'D_A', 'D_B']
# define networks (both Generators and discriminators)
# The naming is different from those used in the paper.
# Code (vs. paper): G_A (G), G_B (F), D_A (D_Y), D_B (D_X)
self.netG_A = networks.define_G(opt.input_nc, opt.output_nc, opt.ngf, opt.netG, opt.norm,
opt.dropout_rate, opt.init_type, opt.init_gain, self.gpu_ids)
self.netG_B = networks.define_G(opt.output_nc, opt.input_nc, opt.ngf, opt.netG, opt.norm,
opt.dropout_rate, opt.init_type, opt.init_gain, self.gpu_ids)
self.netD_A = networks.define_D(opt.output_nc, opt.ndf, opt.netD,
opt.n_layers_D, opt.norm, opt.init_type, opt.init_gain, self.gpu_ids)
self.netD_B = networks.define_D(opt.input_nc, opt.ndf, opt.netD,
opt.n_layers_D, opt.norm, opt.init_type, opt.init_gain, self.gpu_ids)
if opt.lambda_identity > 0.0: # only works when input and output images have the same number of channels
assert (opt.input_nc == opt.output_nc)
self.fake_A_pool = ImagePool(opt.pool_size) # create image buffer to store previously generated images
self.fake_B_pool = ImagePool(opt.pool_size) # create image buffer to store previously generated images
# define loss functions
self.criterionGAN = models.modules.loss.GANLoss(opt.gan_mode).to(self.device) # define GAN loss.
self.criterionCycle = torch.nn.L1Loss()
self.criterionIdt = torch.nn.L1Loss()
# initialize optimizers; schedulers will be automatically created by function .
self.optimizer_G = torch.optim.Adam(itertools.chain(self.netG_A.parameters(), self.netG_B.parameters()),
lr=opt.lr, betas=(opt.beta1, 0.999))
self.optimizer_D = torch.optim.Adam(itertools.chain(self.netD_A.parameters(), self.netD_B.parameters()),
lr=opt.lr, betas=(opt.beta1, 0.999))
self.optimizers = []
self.optimizers.append(self.optimizer_G)
self.optimizers.append(self.optimizer_D)
self.eval_dataloader_AtoB = create_eval_dataloader(self.opt, direction='AtoB')
self.eval_dataloader_BtoA = create_eval_dataloader(self.opt, direction='BtoA')
block_idx = InceptionV3.BLOCK_INDEX_BY_DIM[2048]
self.inception_model = InceptionV3([block_idx])
self.inception_model.to(self.device)
self.inception_model.eval()
if 'cityscapes' in opt.dataroot:
self.drn_model = DRNSeg('drn_d_105', 19, pretrained=False)
util.load_network(self.drn_model, opt.drn_path, verbose=False)
if len(opt.gpu_ids) > 0:
self.drn_model = nn.DataParallel(self.drn_model, opt.gpu_ids)
self.drn_model.eval()
self.best_fid_A, self.best_fid_B = 1e9, 1e9
self.best_mAP = -1e9
self.fids_A, self.fids_B = [], []
self.mAPs = []
self.is_best = False
self.npz_A = np.load(opt.real_stat_A_path)
self.npz_B = np.load(opt.real_stat_B_path)
def set_input(self, input):
"""Unpack input data from the dataloader and perform necessary pre-processing steps.
Parameters:
input (dict): include the data itself and its metadata information.
The option 'direction' can be used to swap domain A and domain B.
"""
# Since it is a cycle.
self.real_A = input['A'].to(self.device)
self.real_B = input['B'].to(self.device)
def set_single_input(self, input):
self.real_A = input['A'].to(self.device)
self.image_paths = input['A_paths']
def forward(self):
"""Run forward pass; called by both functions and ."""
self.fake_B = self.netG_A(self.real_A) # G_A(A)
self.rec_A = self.netG_B(self.fake_B) # G_B(G_A(A))
self.fake_A = self.netG_B(self.real_B) # G_B(B)
self.rec_B = self.netG_A(self.fake_A) # G_A(G_B(B))
def backward_D_basic(self, netD, real, fake):
"""Calculate GAN loss for the discriminator
Parameters:
netD (network) -- the discriminator D
real (tensor array) -- real images
fake (tensor array) -- images generated by a generator
Return the discriminator loss.
We also call loss_D.backward() to calculate the gradients.
"""
# Real
pred_real = netD(real)
loss_D_real = self.criterionGAN(pred_real, True)
# Fake
pred_fake = netD(fake.detach())
loss_D_fake = self.criterionGAN(pred_fake, False)
# Combined loss and calculate gradients
loss_D = (loss_D_real + loss_D_fake) * 0.5
loss_D.backward()
return loss_D
def backward_D_A(self):
"""Calculate GAN loss for discriminator D_A"""
fake_B = self.fake_B_pool.query(self.fake_B)
self.loss_D_A = self.backward_D_basic(self.netD_A, self.real_B, fake_B)
def backward_D_B(self):
"""Calculate GAN loss for discriminator D_B"""
fake_A = self.fake_A_pool.query(self.fake_A)
self.loss_D_B = self.backward_D_basic(self.netD_B, self.real_A, fake_A)
def backward_G(self):
"""Calculate the loss for generators G_A and G_B"""
lambda_idt = self.opt.lambda_identity
lambda_A = self.opt.lambda_A
lambda_B = self.opt.lambda_B
# Identity loss
if lambda_idt > 0:
# G_A should be identity if real_B is fed: ||G_A(B) - B||
self.idt_A = self.netG_A(self.real_B)
self.loss_G_idt_A = self.criterionIdt(self.idt_A, self.real_B) * lambda_B * lambda_idt
# G_B should be identity if real_A is fed: ||G_B(A) - A||
self.idt_B = self.netG_B(self.real_A)
self.loss_G_idt_B = self.criterionIdt(self.idt_B, self.real_A) * lambda_A * lambda_idt
else:
self.loss_G_idt_A = 0
self.loss_G_idt_B = 0
# GAN loss D_A(G_A(A))
self.loss_G_A = self.criterionGAN(self.netD_A(self.fake_B), True)
# GAN loss D_B(G_B(B))
self.loss_G_B = self.criterionGAN(self.netD_B(self.fake_A), True)
# Forward cycle loss || G_B(G_A(A)) - A||
self.loss_G_cycle_A = self.criterionCycle(self.rec_A, self.real_A) * lambda_A
# Backward cycle loss || G_A(G_B(B)) - B||
self.loss_G_cycle_B = self.criterionCycle(self.rec_B, self.real_B) * lambda_B
# combined loss and calculate gradients
self.loss_G = self.loss_G_A + self.loss_G_B + self.loss_G_cycle_A + self.loss_G_cycle_B + self.loss_G_idt_A + self.loss_G_idt_B
self.loss_G.backward() forward函数生成假图。
backward_D_basic函数为D的反向传播。backward_D_A,backward_D_B为cyclegan的2个判别器的反向传播。backward_G为生成器的反向传播。
optimize_parameters函数为参数的更新。
pix2pix_model.py:
定义Pix2PixModel类,继承BaseModel,首先添加命令行参数,
class Pix2PixModel(BaseModel):
@staticmethod
def modify_commandline_options(parser, is_train=True):
assert is_train
parser = super(Pix2PixModel, Pix2PixModel).modify_commandline_options(parser, is_train)
parser.add_argument('--restore_G_path', type=str, default=None,
help='the path to restore the generator')
parser.add_argument('--restore_D_path', type=str, default=None,
help='the path to restore the discriminator')
parser.add_argument('--recon_loss_type', type=str, default='l1',
choices=['l1', 'l2', 'smooth_l1'],
help='the type of the reconstruction loss')
parser.add_argument('--lambda_recon', type=float, default=100,
help='weight for reconstruction loss')
parser.add_argument('--lambda_gan', type=float, default=1,
help='weight for gan loss')
parser.add_argument('--real_stat_path', type=str, required=True,
help='the path to load the groud-truth images information to compute FID.')
parser.set_defaults(norm='instance', netG='mobile_resnet_9blocks', batch_size=4,
dataset_mode='aligned', log_dir='logs/train/pix2pix',
pool_size=0, gan_mode='hinge')
return parser
def __init__(self, opt):
"""Initialize the pix2pix class.
Parameters:
opt (Option class)-- stores all the experiment flags; needs to be a subclass of BaseOptions
"""
assert opt.isTrain
BaseModel.__init__(self, opt)
# specify the training losses you want to print out. The training/test scripts will call
self.loss_names = ['G_gan', 'G_recon', 'D_real', 'D_fake']
# specify the images you want to save/display. The training/test scripts will call
self.visual_names = ['real_A', 'fake_B', 'real_B']
# specify the models you want to save to the disk. The training/test scripts will call and
self.model_names = ['G', 'D']
# define networks (both generator and discriminator)
self.netG = networks.define_G(opt.input_nc, opt.output_nc, opt.ngf, opt.netG,
opt.norm, opt.dropout_rate, opt.init_type,
opt.init_gain, self.gpu_ids, opt=opt)
self.netD = networks.define_D(opt.input_nc + opt.output_nc, opt.ndf, opt.netD,
opt.n_layers_D, opt.norm, opt.init_type, opt.init_gain, self.gpu_ids)
# define loss functions
self.criterionGAN = models.modules.loss.GANLoss(opt.gan_mode).to(self.device)
if opt.recon_loss_type == 'l1':
self.criterionRecon = torch.nn.L1Loss()
elif opt.recon_loss_type == 'l2':
self.criterionRecon = torch.nn.MSELoss()
elif opt.recon_loss_type == 'smooth_l1':
self.criterionRecon = torch.nn.SmoothL1Loss()
else:
raise NotImplementedError('Unknown reconstruction loss type [%s]!' % opt.loss_type)
# initialize optimizers; schedulers will be automatically created by function .
self.optimizer_G = torch.optim.Adam(self.netG.parameters(), lr=opt.lr, betas=(opt.beta1, 0.999))
self.optimizer_D = torch.optim.Adam(self.netD.parameters(), lr=opt.lr, betas=(opt.beta1, 0.999))
self.optimizers = []
self.optimizers.append(self.optimizer_G)
self.optimizers.append(self.optimizer_D)
self.eval_dataloader = create_eval_dataloader(self.opt)
block_idx = InceptionV3.BLOCK_INDEX_BY_DIM[2048]
self.inception_model = InceptionV3([block_idx])
self.inception_model.to(self.device)
self.inception_model.eval()
if 'cityscapes' in opt.dataroot:
self.drn_model = DRNSeg('drn_d_105', 19, pretrained=False)
util.load_network(self.drn_model, opt.drn_path, verbose=False)
if len(opt.gpu_ids) > 0:
self.drn_model = nn.DataParallel(self.drn_model, opt.gpu_ids)
self.drn_model.eval()
self.best_fid = 1e9
self.best_mAP = -1e9
self.fids, self.mAPs = [], []
self.is_best = False
self.Tacts, self.Sacts = {}, {}
self.npz = np.load(opt.real_stat_path)
def set_input(self, input):
"""Unpack input data from the dataloader and perform necessary pre-processing steps.
Parameters:
input (dict): include the data itself and its metadata information.
The option 'direction' can be used to swap images in domain A and domain B.
"""
AtoB = self.opt.direction == 'AtoB'
self.real_A = input['A' if AtoB else 'B'].to(self.device)
self.real_B = input['B' if AtoB else 'A'].to(self.device)
self.image_paths = input['A_paths' if AtoB else 'B_paths']
def forward(self):
"""Run forward pass; called by both functions and ."""
self.fake_B = self.netG(self.real_A) # G(A)
def backward_D(self):
"""Calculate GAN loss for the discriminator"""
fake_AB = torch.cat((self.real_A, self.fake_B), 1).detach()
real_AB = torch.cat((self.real_A, self.real_B), 1).detach()
pred_fake = self.netD(fake_AB)
self.loss_D_fake = self.criterionGAN(pred_fake, False, for_discriminator=True)
pred_real = self.netD(real_AB)
self.loss_D_real = self.criterionGAN(pred_real, True, for_discriminator=True)
self.loss_D = (self.loss_D_fake + self.loss_D_real) * 0.5
self.loss_D.backward()
def backward_G(self):
"""Calculate GAN and L1 loss for the generator"""
# First, G(A) should fake the discriminator
fake_AB = torch.cat((self.real_A, self.fake_B), 1)
pred_fake = self.netD(fake_AB)
self.loss_G_gan = self.criterionGAN(pred_fake, True, for_discriminator=False) * self.opt.lambda_gan
# Second, G(A) = B
self.loss_G_recon = self.criterionRecon(self.fake_B, self.real_B) * self.opt.lambda_recon
# combine loss and calculate gradients
self.loss_G = self.loss_G_gan + self.loss_G_recon
self.loss_G.backward()
def optimize_parameters(self):
self.forward() # compute fake images: G(A)
# update D
self.set_requires_grad(self.netD, True) # enable backprop for D
self.optimizer_D.zero_grad() # set D's gradients to zero
self.backward_D() # calculate gradients for D
self.optimizer_D.step() # update D's weights
# update G
self.set_requires_grad(self.netD, False) # D requires no gradients when optimizing G
self.optimizer_G.zero_grad() # set G's gradients to zero
self.backward_G() # calculate graidents for G
self.optimizer_G.step() # udpate G's weights networks.py:
实现 normalization layers, initialization methods以及optimization scheduler等。define_G和define_D函数按要求返回一个G和D网络,要求在net_G和net_D中。
import functools
import torch
import torch.nn as nn
from torch.nn import init
from torch.optim import lr_scheduler
from configs import decode_config
from .modules.discriminators import NLayerDiscriminator, PixelDiscriminator
###############################################################################
# Helper Functions
###############################################################################
class Identity(nn.Module):
def forward(self, x):
return x
def get_norm_layer(norm_type='instance'):
"""Return a normalization layer
Parameters:
norm_type (str) -- the name of the normalization layer: batch | instance | none
For BatchNorm, we use learnable affine parameters and track running statistics (mean/stddev).
For InstanceNorm, we do not use learnable affine parameters. We do not track running statistics.
"""
if norm_type == 'batch':
norm_layer = functools.partial(nn.BatchNorm2d, affine=True, track_running_stats=True)
elif norm_type == 'instance':
norm_layer = functools.partial(nn.InstanceNorm2d, affine=False, track_running_stats=False)
elif norm_type == 'none':
def norm_layer(x):
return Identity()
else:
raise NotImplementedError('normalization layer [%s] is not found' % norm_type)
return norm_layer
def get_scheduler(optimizer, opt):
"""Return a learning rate scheduler
Parameters:
optimizer -- the optimizer of the network
opt (option class) -- stores all the experiment flags; needs to be a subclass of BaseOptions.
opt.lr_policy is the name of learning rate policy: linear | step | plateau | cosine
For 'linear', we keep the same learning rate for the first epochs
and linearly decay the rate to zero over the next epochs.
For other schedulers (step, plateau, and cosine), we use the default PyTorch schedulers.
See https://pytorch.org/docs/stable/optim.html for more details.
"""
if opt.lr_policy == 'linear':
def lambda_rule(epoch):
lr_l = 1.0 - max(0, epoch + 1 - opt.nepochs) / float(opt.nepochs_decay + 1)
return lr_l
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda_rule)
elif opt.lr_policy == 'step':
scheduler = lr_scheduler.StepLR(optimizer, step_size=opt.lr_decay_iters, gamma=0.1)
elif opt.lr_policy == 'plateau':
scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.2, threshold=0.01, patience=5)
elif opt.lr_policy == 'cosine':
scheduler = lr_scheduler.CosineAnnealingLR(optimizer, T_max=opt.niter, eta_min=0)
else:
return NotImplementedError('learning rate policy [%s] is not implemented', opt.lr_policy)
return scheduler
def init_weights(net, init_type='normal', init_gain=0.02):
"""Initialize network weights.
Parameters:
net (network) -- network to be initialized
init_type (str) -- the name of an initialization method: normal | xavier | kaiming | orthogonal
init_gain (float) -- scaling factor for normal, xavier and orthogonal.
We use 'normal' in the original pix2pix and CycleGAN paper. But xavier and kaiming might
work better for some applications. Feel free to try yourself.
"""
def init_func(m): # define the initialization function
classname = m.__class__.__name__
if hasattr(m, 'weight') and (classname.find('Conv') != -1 or classname.find('Linear') != -1)
and classname.find('SCC') == -1:
if init_type == 'normal':
init.normal_(m.weight.data, 0.0, init_gain)
elif init_type == 'xavier':
init.xavier_normal_(m.weight.data, gain=init_gain)
elif init_type == 'kaiming':
init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
elif init_type == 'orthogonal':
init.orthogonal_(m.weight.data, gain=init_gain)
else:
raise NotImplementedError('initialization method [%s] is not implemented' % init_type)
if hasattr(m, 'bias') and m.bias is not None:
init.constant_(m.bias.data, 0.0)
elif classname.find(
'BatchNorm2d') != -1: # BatchNorm Layer's weight is not a matrix; only normal distribution applies.
init.normal_(m.weight.data, 1.0, init_gain)
init.constant_(m.bias.data, 0.0)
print('initialize network with %s' % init_type)
net.apply(init_func) # apply the initialization function
def init_net(net, init_type='normal', init_gain=0.02, gpu_ids=[]):
"""Initialize a network: 1. register CPU/GPU device (with multi-GPU support); 2. initialize the network weights
Parameters:
net (network) -- the network to be initialized
init_type (str) -- the name of an initialization method: normal | xavier | kaiming | orthogonal
gain (float) -- scaling factor for normal, xavier and orthogonal.
gpu_ids (int list) -- which GPUs the network runs on: e.g., 0,1,2
Return an initialized network.
"""
if len(gpu_ids) > 0:
assert (torch.cuda.is_available())
net = torch.nn.DataParallel(net, gpu_ids) # multi-GPUs
init_weights(net, init_type, init_gain=init_gain)
return net
def define_G(input_nc, output_nc, ngf, netG, norm='batch', dropout_rate=0,
init_type='normal', init_gain=0.02, gpu_ids=[], opt=None):
norm_layer = get_norm_layer(norm_type=norm)
if netG == 'resnet_9blocks':
from models.modules.resnet_architecture.resnet_generator import ResnetGenerator
net = ResnetGenerator(input_nc, output_nc, ngf, norm_layer=norm_layer,
dropout_rate=dropout_rate, n_blocks=9)
elif netG == 'mobile_resnet_9blocks':
from models.modules.resnet_architecture.mobile_resnet_generator import MobileResnetGenerator
net = MobileResnetGenerator(input_nc, output_nc, ngf=ngf, norm_layer=norm_layer,
dropout_rate=dropout_rate, n_blocks=9)
elif netG == 'super_mobile_resnet_9blocks':
from models.modules.resnet_architecture.super_mobile_resnet_generator import SuperMobileResnetGenerator
net = SuperMobileResnetGenerator(input_nc, output_nc, ngf=ngf, norm_layer=norm_layer,
dropout_rate=dropout_rate, n_blocks=9)
elif netG == 'sub_mobile_resnet_9blocks':
from models.modules.resnet_architecture.sub_mobile_resnet_generator import SubMobileResnetGenerator
assert opt.config_str is not None
config = decode_config(opt.config_str)
net = SubMobileResnetGenerator(input_nc, output_nc, config, norm_layer=norm_layer,
dropout_rate=dropout_rate, n_blocks=9)
else:
raise NotImplementedError('Generator model name [%s] is not recognized' % netG)
return init_net(net, init_type, init_gain, gpu_ids)
def define_D(input_nc, ndf, netD, n_layers_D=3, norm='batch', init_type='normal', init_gain=0.02, gpu_ids=[], opt=None):
"""Create a discriminator
Parameters:
input_nc (int) -- the number of channels in input images
ndf (int) -- the number of filters in the first conv layer
netD (str) -- the architecture's name: basic | n_layers | pixel
n_layers_D (int) -- the number of conv layers in the discriminator; effective when netD=='n_layers'
norm (str) -- the type of normalization layers used in the network.
init_type (str) -- the name of the initialization method.
init_gain (float) -- scaling factor for normal, xavier and orthogonal.
gpu_ids (int list) -- which GPUs the network runs on: e.g., 0,1,2
Returns a discriminator
Our current implementation provides three types of discriminators:
[basic]: 'PatchGAN' classifier described in the original pix2pix paper.
It can classify whether 70×70 overlapping patches are real or fake.
Such a patch-level discriminator architecture has fewer parameters
than a full-image discriminator and can work on arbitrarily-sized images
in a fully convolutional fashion.
[n_layers]: With this mode, you cna specify the number of conv layers in the discriminator
with the parameter (default=3 as used in [basic] (PatchGAN).)
[pixel]: 1x1 PixelGAN discriminator can classify whether a pixel is real or not.
It encourages greater color diversity but has no effect on spatial statistics.
The discriminator has been initialized by . It uses Leakly RELU for non-linearity.
"""
net = None
norm_layer = get_norm_layer(norm_type=norm)
if netD == 'n_layers':
net = NLayerDiscriminator(input_nc, ndf, n_layers_D, norm_layer=norm_layer)
elif netD == 'pixel': # classify if each pixel is real or fake
net = PixelDiscriminator(input_nc, ndf, norm_layer=norm_layer)
else:
raise NotImplementedError('Discriminator model name [%s] is not recognized' % netD)
return init_net(net, init_type, init_gain, gpu_ids) discriminator.py:
定义network.py用到的PixelDiscriminator与NLayerDiscriminator类。
super_modules.py:
在最底层定义几种卷积:SuperConv2d,SuperConvTranspose2d,SuperSeparableConv2d。
resnet_generator.py:
先定义ResNet block的结构,之后再构建ResNetGenerator。
mobile_resnet_generator.py:
将ResNet block基本的模块变成了SeparableConv2d。
sub_mobile_resnet_generator.py:
super_mobile_resnet_generator.py:
这2个的区别是super_mobile_resnet_generator的channel数是以ngf为单位,sub_mobile_resnet_generator的channel数是以config['channels']为单位的。
distillers/:
base_resnet_distiller.py:
定义基类BaseResnetDistiller,这个类包含distiller所需的变量和函数,后续的distiller类都继承这个类。它包含的命令行参数有teacher_netG,student_netG,teacher_ngf,student_ngf,restore_teacher_G_path,restore_student_G_path,lambda_distill,lambda_recon,lambda_gan。这个类内部的变量loss_names 有5种:'G_gan', 'G_distill', 'G_recon', 'D_fake', 'D_real'。
这2行定义2个Generator:
self.netG_teacher = networks.define_G(opt.input_nc, opt.output_nc, opt.teacher_ngf,
opt.teacher_netG, opt.norm, opt.teacher_dropout_rate,
opt.init_type, opt.init_gain, self.gpu_ids, opt=opt)
self.netG_student = networks.define_G(opt.input_nc, opt.output_nc, opt.student_ngf,
opt.student_netG, opt.norm, opt.student_dropout_rate,
opt.init_type, opt.init_gain, self.gpu_ids, opt=opt)可以看到teacher和student Generator的区别是channel数不同。

这2行定义2个Discriminator:
if opt.dataset_mode == 'aligned':
self.netD = networks.define_D(opt.input_nc + opt.output_nc, opt.ndf, opt.netD,
opt.n_layers_D, opt.norm, opt.init_type, opt.init_gain, self.gpu_ids)
elif opt.dataset_mode == 'unaligned':
self.netD = networks.define_D(opt.output_nc, opt.ndf, opt.netD,
opt.n_layers_D, opt.norm, opt.init_type, opt.init_gain, self.gpu_ids)这里还想强调的是这个netA,它代表的是从student generator到teacher generator的映射网络。
def setup(self, opt, verbose=True):
self.schedulers = [networks.get_scheduler(optimizer, opt) for optimizer in self.optimizers]
self.load_networks(verbose)
if verbose:
self.print_networks()
if self.opt.lambda_distill > 0:
def get_activation(mem, name):
def get_output_hook(module, input, output):
mem[name] = output
return get_output_hook
def add_hook(net, mem, mapping_layers):
for n, m in net.named_modules():
if n in mapping_layers:
m.register_forward_hook(get_activation(mem, n))
add_hook(self.netG_teacher, self.Tacts, self.mapping_layers)
add_hook(self.netG_student, self.Sacts, self.mapping_layers)这个函数是为了给Tact和Sact赋值,get_activation(mem, n)返回一个钩子,叫get_output_hook,把他添加到m的前向传播里面,这里m是student和teacher的G的module,这些module要在mapping_layers里面。这样这些module前向传播时就会执行get_output_hook函数,把这个module输出的值存入Tact或者Sact里面,供以后使用。
效果是:
Tacts[module.model.9],Tacts[module.model.12],Tacts[module.model.15],Tacts[module.model.18]为对应的4个层的输出值。
看到这里你可能会好奇这个self.mapping_layers是什么玩意?
代码中是这么写的:
self.mapping_layers = ['module.model.%d' % i for i in range(9, 21, 3)]你一琢磨发现这个self.mapping_layers应该是:
可为什么是这样?我们看下原文:

这下你明白了,原来作者只是选择了4个中间层进行蒸馏,也就是每3层蒸馏一次。选出的4个中间层分别是:9,12,15,18。只保证这4个层的student Generator的输出尽量地接近teacher Generator。
最后,我们拿着3个损失:

def backward_G(self):
if self.opt.dataset_mode == 'aligned':
self.loss_G_recon = self.criterionRecon(self.Sfake_B, self.real_B) * self.opt.lambda_recon
fake = torch.cat((self.real_A, self.Sfake_B), 1)
else:
self.loss_G_recon = self.criterionRecon(self.Sfake_B, self.Tfake_B) * self.opt.lambda_recon
fake = self.Sfake_B
pred_fake = self.netD(fake)
self.loss_G_gan = self.criterionGAN(pred_fake, True, for_discriminator=False) * self.opt.lambda_gan
if self.opt.lambda_distill > 0:
self.loss_G_distill = self.calc_distill_loss() * self.opt.lambda_distill
else:
self.loss_G_distill = 0
self.loss_G = self.loss_G_gan + self.loss_G_recon + self.loss_G_distill
self.loss_G.backward()更新D的参数就简单了不少:
def backward_D(self):
if self.opt.dataset_mode == 'aligned':
fake = torch.cat((self.real_A, self.Sfake_B), 1).detach()
real = torch.cat((self.real_A, self.real_B), 1).detach()
else:
fake = self.Sfake_B.detach()
real = self.real_B.detach()
pred_fake = self.netD(fake)
self.loss_D_fake = self.criterionGAN(pred_fake, False, for_discriminator=True)
pred_real = self.netD(real)
self.loss_D_real = self.criterionGAN(pred_real, True, for_discriminator=True)
self.loss_D = (self.loss_D_fake + self.loss_D_real) * 0.5
self.loss_D.backward()蒸馏之后得到student Generator,再从蒸馏得到的student model训练出一个"once-for-all" network:
train distill和train supernet的整体代码结构是一样的,只是parser不同。
蒸馏student Generator时,先导入teacher Generator的参数。
训练"once-for-all" network时,先导入student Generator的参数。
resnet_distiller.py:
forward()函数:
def forward(self):
with torch.no_grad():
self.Tfake_B = self.netG_teacher(self.real_A)
self.Sfake_B = self.netG_student(self.real_A)计算teacher和student Generator的前向传播,其中teacher Generator不更新参数。
supernets/:
把上面的定义又写了一遍。
get_real_state.py:
is a auxiliary script to get the statistical information of the ground-truth images to compute FID. You need to specify the dataset with options `--dataroot`, `--dataset_model` and the direction you would like to train with `--direction`。
train.py:
从头训练模型,可选的命令行参数包括:--model:pix2pix,cyclegan等。--dataset_mode:unaligned,aligned等。
from trainer import Trainer
if __name__ == '__main__':
trainer = Trainer('train')
trainer.start()
print('Training finished!!!')distill.py:
蒸馏的代码,目前只支持ResNet的模型。You could specify the teacher model with options --teacher_netG and --teacher_ngf, and load the pretrained teacher weight with --restore_teacher_G_path. Similarly, You could specify the teacher model with options --student_netG and --student_ngf, and load the pretrained teacher weight with --restore_student_G_path。
from trainer import Trainer
if __name__ == '__main__':
trainer = Trainer('distill')
trainer.start()
print('Distillation finished!!!') train_supernet.py:
训练supernet以及finetuning的代码。目前只支持ResNet的模型。You could specify the teacher model with options `--teacher_netG` and `--teacher_ngf`, and load the pretrained teacher weight with `--restore_teacher_G_path`. Similarly, You could specify the teacher model with options `--student_netG` and `--student_ngf`, and load the pretrained teacher weight with `--restore_student_G_path`. Moreover, you need to specify the candidate subnet set with option `--config_set` when training a supernet. When we are fine-tuning a specific subnet, you need to specify the chosen subnet configuration with option `--config_str`。
from trainer import Trainer
if __name__ == '__main__':
trainer = Trainer('supernet')
trainer.start()
print('Supernet training finished!!!')trainer.py:
上面三个函数都最后调用了trainer.py,只不过传入的参数不同。
is a script the implements the training logic for [train.py](../train.py), [distill.py](../distill.py) and [train_supernet.py](../train_supernet.py)。
def __init__(self, task):
if task == 'train':
from options.train_options import TrainOptions as Options
from models import create_model as create_model
elif task == 'distill':
from options.distill_options import DistillOptions as Options
from distillers import create_distiller as create_model
elif task == 'supernet':
from options.supernet_options import SupernetOptions as Options
from supernets import create_supernet as create_model
else:
raise NotImplementedError('Unknown task [%s]!!!' % task)首先根据Trainer传入参数的不同import不同的Options,这里的Options是命令行参数。
再从不同的package里面import相应的create函数,实例化对应的类,比如说传入distill,就创建一个ResnetDistiller的对象返回。传入supernet,就创建一个ResnetSupernet的对象返回。这个对象之前已经讲过了,它们内部定义了前向传播,反向传播,求loss,优化等函数。
训练的代码是:
for epoch in range(start_epoch, end_epoch + 1):
epoch_start_time = time.time() # timer for entire epoch
for i, data_i in enumerate(dataset):
iter_start_time = time.time()
model.set_input(data_i)
model.optimize_parameters()
if total_iter % opt.print_freq == 0:
losses = model.get_current_losses()
logger.print_current_errors(epoch, total_iter, losses, time.time() - iter_start_time)
logger.plot(losses, total_iter)
if total_iter % opt.save_latest_freq == 0 or total_iter == opt.iter_base:
self.evaluate(epoch, total_iter,
'Saving the latest model (epoch %d, total_steps %d)' % (epoch, total_iter))
if model.is_best:
model.save_networks('iter%d' % total_iter)
total_iter += 1
logger.print_info(
'End of epoch %d / %d t Time Taken: %.2f sec' % (epoch, end_epoch, time.time() - epoch_start_time))
if epoch % opt.save_epoch_freq == 0 or epoch == end_epoch:
self.evaluate(epoch, total_iter,
'Saving the model at the end of epoch %d, iters %d' % (epoch, total_iter))
model.save_networks(epoch)
model.update_learning_rate(logger)这里的model就是前面ResnetDistiller,ResnetSupernet等返回的instance,它们都有optimize_parameters()函数,不断迭代更新G和D的参数,在更新过程中打印loss曲线和evaluate,并间歇性地保存结果,每个epoch更新1次学习率。
search.py:
is a script for evaluating all candidate subnets. Once you have get your supernet weight, you can use this script to evaluate the performance of candidate subnets. It will load a saved supernet model from --restore_G_path and save the evaluation results to --output_path。
可以看出,是得先有了supernet weight,然后使用这个文件评估candidate subnets的性能。
inception_model是除了CitySpace以外的其他数据集的评价指标所需的模型。
drn_model是CitySpace数据集的评价指标所需的模型。
result = {
'config_str': encode_config(config), 'macs': macs}
if not opt.no_fid:
fid = get_fid(fakes, inception_model, npz, device, opt.batch_size, use_tqdm=False)
result['fid'] = fid
if 'cityscapes' in opt.dataroot and opt.direction == 'BtoA':
mAP = get_mAP(fakes, names, drn_model, device,
data_dir=opt.cityscapes_path,
batch_size=opt.batch_size,
num_workers=opt.num_threads,
use_tqdm=False)
result['mAP'] = mAP
print(result, flush=True)
results.append(result)这几行把evaluate子模型的性能,结果保存在results里面。result是一个dict,关键字包括config_str(配置信息),macs(计算量),fid(评估性能)。
最后:
os.makedirs(os.path.dirname(opt.output_path), exist_ok=True)
with open(opt.output_path, 'wb') as f:
pickle.dump(results, f)把结果保存起来。
对于K=9个Blocks,选择每个Blocks输出的最合适的channels数,要决定8个变量。
search_multi.py:
is multi-gpu-evaluation supporting version of [search.py](../search.py). The usage is almost the same of [search.py](../search.py). All you need to do is specify the gpus you would like to use (with option `--gpu_ids`)。
select_arch.py:
选出最优的模型:
def takeMACs(item):
return item['macs']
def main(opt):
with open(opt.pkl_path, 'rb') as f:
results = pickle.load(f)
results.sort(key=takeMACs)
for item in results:
assert isinstance(item, dict)
qualified = True
if item['macs'] > opt.macs:
qualified = False
elif 'fid' in item and item['fid'] > opt.fid:
qualified = False
elif 'mIoU' in item and item['mIoU'] < opt.mIoU:
qualified = False
if qualified:
print(item)遍历results的所有元素,items,如果macs超过了规定就直接舍弃。
之后在所有macs满足要求的items里面选择fid最小或者mIoU最大的items,它的config_str参数就是最终选择出的模型。
export.py:
is a script to extract a specific subnet for a supernet and export it. You need specify the supernet model with `--ngf` and the model weight with `--input_path`. To extract the specific subnet, you need to provide the subnet configuration with `--config_str` and the exported model will be saved to `--output_path`。
test.py:
主要的测试文件。一旦有了模型的权重,可以使用它进行测试。命令行参数--restore_G_path代表从这里加载模型,--results_dir代表将结果保存在这里。
options/:

util/:

这2个文件夹分析的比较简单,因为知乎文章超字数了,实在不知道该删哪里,就把这些不重要的地方略写了。不得不说韩松组的工作属实硬核而且丰富,在这里再次致敬大佬们为我们后浪铺路造坑。
这篇工作很好地结合了知识蒸馏和NAS的思路,NAS就是通过sample-->evaluation的办法来实现的。知识蒸馏是通过搞一个
数据集处理:
combine_A_and_B.py:
用法:
We provide a python script to generate pix2pix training data in the form of pairs of images {A,B}, where A and B are two different depictions of the same underlying scene. For example, these might be pairs {label map, photo} or {bw image, color image}. Then we can learn to translate A to B or B to A:
注意这个用法:首先要在数据集文件夹edges2shoes-r下面,创建子文件夹A/train,A/val,A/test和B/train,B/val,B/test,这里面的数据必须size一致。
python datasets/combine_A_and_B.py --fold_A /path/to/data/A --fold_B /path/to/data/B --fold_AB /path/to/dataThis will combine each pair of images (A,B) into a single image file, ready for training。