Pytorch最简单的图像分类——K折交叉验证处理小型鸟类数据集分类
文章目录
- Pytorch最简单的图像分类——K折交叉验证处理小型鸟类数据集分类
-
- 数据集处理
- 网络模型部分
- 训练函数部分
- k折交叉验证部分
- 最终结果部分
- 完整代码
Pytorch最简单的图像分类——K折交叉验证处理小型鸟类数据集分类
你好! 本篇博客主要是针对基于Pytorch深度学习刚入门的同学,本文基于六种鸟类的分类问题,以小数据集为例,带领读者从总体上了解一个从零开始的图像分类问题,陆续会写一些具体的问题,如本人在跑这个小项目中遇到的所有问题以及解决方法,重点在于掌握图像分类这一基本问题中数据集的分割、读取、封装的基本思想,接着会详细的介绍构建的模型,以及针对小数据集而使用的k折交叉验证的方法,还有使用到的网络,损失函数,优化器,等涉及到图像分类问题的所有的基本内容。
数据集处理
我们的小数据集共有654张照片,共六类鸟,不使用K折交叉验证的话,不需要这一步的分割数据集,这里每一类图像的分割比例为8:2(读者也可以选择7:3等),然后再把所有的数据集分别写入txt文本中(因为本文使用的是k折交叉验证的方法,如不使用该方法,读者需把训练集和测试集分别写到不同的txt文本中,反之使用K折交叉验证的话,只需要把所有的数据写入一份文件里,然后再打乱顺序),接着就可以把txt文本送入Pytorch的torch.utils.data.Dataset类中,因为笔者想把内部的原理搞的透一点,故自己定义了一个torch.utils.data.Dataset的一个子类,来深入理解此类的内部对数据集处理的原理,至此数据集封装完成,最后就可以直接使用torch.utils.data.DataLoader类生成可迭代的数据集了!
- 原始数据集展示;

- 对数据集进行分割(8:2);
import os
import random
import shutil
import time
def MoveFile(imageDir,test_rate,save_test_dir):#三个参数,第一个为每个类别的所有图像在计算机中的位置
#第二个为移动的图片数目所占总的比例,最后一个为移动的图片保存的位置,
#为了方便直接把移动后的原文件夹里剩余的图片当做训练集
image_number = len(imageDir) #图片总数目
test_number = int(image_number * test_rate)#要移动的图片数目
print("要移动到%s目录下的图片数目为:%d"%(save_test_dir,test_number))
test_samples = random.sample(imageDir, test_number)#随机截取列表imageDir中数目为test_number的元素
# 移动图像到目标文件夹
if not os.path.exists(save_test_dir):
os.mkdir(save_test_dir)
print("save_test_dir has been created successfully!")
else:
print("save_test_dir already exited!")
for i,j in enumerate(test_samples):
shutil.move(test_samples[i], save_test_dir)
#原始路径
origion_paths = ['C:\\data\\bird\\001凤头\\001凤头',"C:\\data\\bird\\002小\\002小",
"C:\\data\\bird\\003小白鹭\\003小白鹭","C:\\data\\bird\\004普通翠鸟\\004普通翠鸟",
"C:\\data\\bird\\005戴胜\\005戴胜","C:\\data\\bird\\006山斑鸠\\006山斑鸠"]
# 保存路径
save_test_dirs = ['C:\\data\\bird\\test_001凤头',"C:\\data\\bird\\test_002小",
"C:\\data\\bird\\test_003小白鹭","C:\\data\\bird\\test_004普通翠鸟",
"C:\\data\\bird\\test_005戴胜","C:\\data\\bird\\test_006山斑鸠"]
test_rate = 0.2
for i,origion_path in enumerate(origion_paths):
image_list = os.listdir(origion_path) #获得原始路径下的所有图片的name(默认路径下都是图片)
image_Dir=[]
for x,y in enumerate(image_list):
image_Dir.append (os.path.join(origion_path, y))
print("%s目录下共有%d张图片!"%(origion_path,len(image_Dir)))
MoveFile(image_Dir,test_rate,save_test_dirs[i])
print("All datas has been moved successfully!")
分割后的数据集
- 将所有的数据集读入txt文本;
注: 如果你进行一般的训练(数据集很大),可能需要把train和test数据集信息写入不同的文本中,因为笔者的数据集比较小,故使用的是K折交叉验证的方法,即把所有数据写入下面的all_shuffle_datas_k.txt文件里。
#本段代码为k折交叉验证提供了数据集上的准备
#以读入测试集为例,故只列出了测试集图片所在路径,若读入全部数据需把所有路径加
import glob
import os
import numpy as np
PATHS= ['C:\\data\\bird\\001凤头\\001凤头','C:\\data\\bird\\test_001凤头',
"C:\\data\\bird\\002小\\002小","C:\\data\\bird\\test_002小",
"C:\\data\\bird\\003小白鹭\\003小白鹭","C:\\data\\bird\\test_003小白鹭",
"C:\\data\\bird\\004普通翠鸟\\004普通翠鸟","C:\\data\\bird\\test_004普通翠鸟",
"C:\\data\\bird\\005戴胜\\005戴胜","C:\\data\\bird\\test_005戴胜",
"C:\\data\\bird\\006山斑鸠\\006山斑鸠","C:\\data\\bird\\test_006山斑鸠"]
sum=0
img_path=[]
#遍历上面的12个路径,依次把信息追加到img_path列表中
for label,p in enumerate(PATHS):
image_dir=glob.glob(p+"\\"+"*.jpg")#返回路径下的所有图片详细的路径
sum+=len(image_dir)
print(len(image_dir))
for image in image_dir:
img_path.append((image,str(label//2)))
#print(img_path[0])
print("%d 个图像信息已经加载到txt文本!!!"%(sum))
np.random.shuffle(img_path)
print(img_path[0])
file=open("C:\\data\\bird\\all_shuffle_datas.txt","w",encoding="utf-8")
for img in img_path:
file.write(img[0]+' '+img[1]+'\n')
file.close()
写入后的文件内容:图片路径+对应label
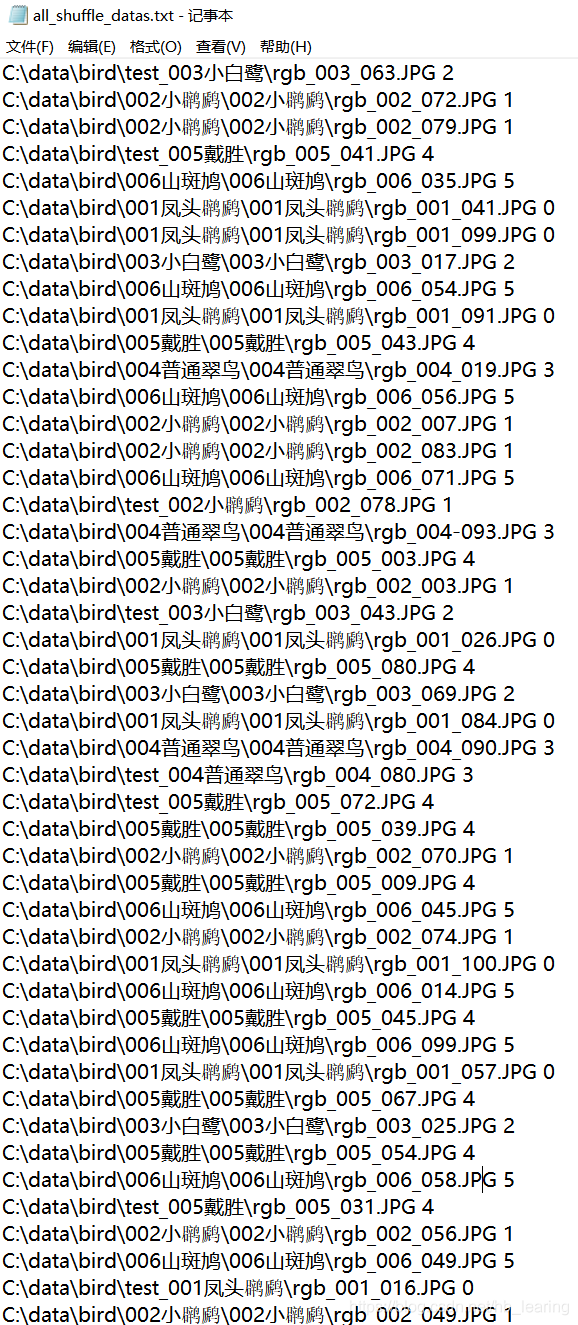
4. 为k折交叉验证做分割数据集的准备,把数据集分成k份,每一份都要作为一次测试集,剩下的作为训练集。代码如下(该函数将会被调用k次);
def get_k_fold_data(k, k1, image_dir):
# 返回第i折交叉验证时所需要的训练和验证数据
assert k > 1
# if k1==0:#第一次需要打开文件
file = open(image_dir, 'r', encoding='utf-8')
reader=csv.reader(file )
imgs_ls = []
for line in file.readlines():
# if len(line):
imgs_ls.append(line)
file.close()
#print(len(imgs_ls))
avg = len(imgs_ls) // k
#print(avg)
f1 = open('/ddhome/bird20_K/train_k.txt', 'w')
f2 = open('/ddhome/bird20_K/test_k.txt', 'w')
writer1 = csv.writer(f1)
writer2 = csv.writer(f2)
for i, row in enumerate(imgs_ls):
if (i // avg) == k1:
writer2.writerow(row)
else:
writer1.writerow(row)
f1.close()
f2.close()
从all_shuffle_datas_k.txt总文件读取每一折需要的数据,然后写到test_k.txt和train_k.txt文件中

5. 对数据集进行封装;
自己写了一个torch.utils.data.Dataset的子类:
class MyDataset(torch.utils.data.Dataset): # 创建自己的类:MyDataset,这个类是继承的torch.utils.data.Dataset
def __init__(self, is_train,root): # 初始化一些需要传入的参数
super(MyDataset, self).__init__()
fh = open(root, 'r', encoding="utf-8") # 按照传入的路径和txt文本参数,打开这个文本,并读取内容
imgs = [] # 创建一个名为img的空列表,一会儿用来装东西
for line in fh: # 按行循环txt文本中的内容
line = line.rstrip() # 删除 本行string 字符串末尾的指定字符,这个方法的详细介绍自己查询python
words = line.split() # 通过指定分隔符对字符串进行切片,默认为所有的空字符,包括空格、换行、制表符等
imgs.append((words[0], int(words[1]))) # 把txt里的内容读入imgs列表保存,具体是words几要看txt内容而定
self.imgs = imgs
self.is_train = is_train
if self.is_train:
self.train_tsf = torchvision.transforms.Compose([
torchvision.transforms.RandomResizedCrop(524, scale=(0.1, 1), ratio=(0.5, 2)),
torchvision.transforms.ToTensor()
])
else:
self.test_tsf = torchvision.transforms.Compose([
torchvision.transforms.Resize(size=524),
torchvision.transforms.CenterCrop(size=500),
torchvision.transforms.ToTensor()])
def __getitem__(self, index): # 这个方法是必须要有的,用于按照索引读取每个元素的具体内容
feature, label = self.imgs[index] # fn是图片path #fn和label分别获得imgs[index]也即是刚才每行中word[0]和word[1]的信息
feature = Image.open(feature).convert('RGB') # 按照path读入图片from PIL import Image # 按照路径读取图片
if self.is_train:
feature = self.train_tsf(feature)
else:
feature = self.test_tsf(feature)
return feature, label
def __len__(self): # 这个函数也必须要写,它返回的是数据集的长度,也就是多少张图片,要和loader的长度作区分
return len(self.imgs)
封装:
train_data = MyDataset(is_train=True, root=train_k)
test_data = MyDataset(is_train=False, root=test_k)
6.使用torch.utils.data.DataLoader类对数据集进行可迭代化处理;
train_loader = torch.utils.data.DataLoader(dataset=train_data, batch_size=10, shuffle=True, num_workers=5)
test_loader = torch.utils.data.DataLoader(dataset=test_data, batch_size=10, shuffle=True, num_workers=5)
至此,数据集处理工作到此完成!
网络模型部分
本部分使用的是很强大的Efficient-Net网络,使用非常简单,仅需要掌握对网络层的理解,以及微调的基本知识,就可以轻松上手。
1.首先要安装efficientnet_pytorch(pip install efficientnet_pytorch)
2.导入已经训练过的网络
from efficientnet_pytorch import EfficientNet
net = EfficientNet.from_pretrained('efficientnet-b0')
3.对下载后的网络模型进行调整
net = EfficientNet.from_pretrained('efficientnet-b0')
net._fc = nn.Linear(1280, 6)
output_params = list(map(id, net._fc.parameters()))
feature_params = filter(lambda p: id(p) not in output_params, net.parameters())
lr = 0.01
optimizer = optim.SGD([{
'params': feature_params},
{
'params': net._fc.parameters(), 'lr': lr * 10}],
lr=lr, weight_decay=0.001)
由于该网络是在很大的ImageNet数据集上预训练的,所以参数已经足够好,因此一般只需使用较小的学习率来微调这些参数,而fc中的随机初始化参数一般需要更大的学习率从头训练。
4.因为我是在Linux服务器上的跑的程序,用到了多块GPU,所以代码如下:
net=net.cuda()
net = torch.nn.DataParallel(net)
至此,网络层部分到此结束。
训练函数部分
def train(i,train_iter, test_iter, net, loss, optimizer, device, num_epochs):
net = net.to(device)
print("training on ", device)
start = time.time()
test_acc_max_l = []
train_acc_max_l = []
train_l_min_l=[]
for epoch in range(num_epochs): #迭代100次
batch_count = 0
train_l_sum, train_acc_sum, test_acc_sum, n = 0.0, 0.0, 0.0, 0
for X, y in train_iter:
X = X.to(device)
y = y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.cpu().item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
#至此,一个epoches完成
test_acc_sum= d2l.evaluate_accuracy(test_iter, net)
train_l_min_l.append(train_l_sum/batch_count)
train_acc_max_l.append(train_acc_sum/n)
test_acc_max_l.append(test_acc_sum)
print('fold %d epoch %d, loss %.4f, train acc %.3f, test acc %.3f'
% (i+1,epoch + 1, train_l_sum / batch_count, train_acc_sum / n, test_acc_sum))
#train_l_min_l.sort()
#¥train_acc_max_l.sort()
index_max=test_acc_max_l.index(max(test_acc_max_l))
f = open("/root/pythoncodes/results.txt", "a")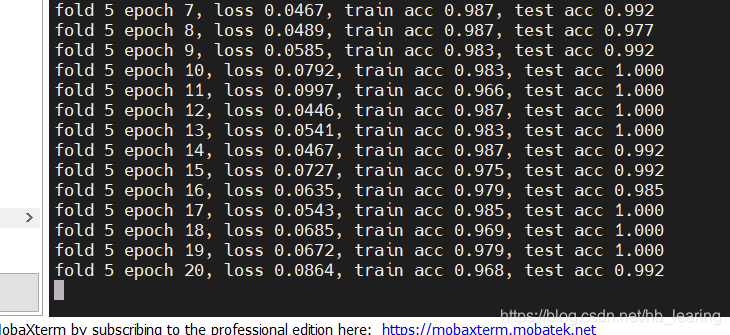
if i==0:
f.write("%d fold"+" "+"train_loss"+" "+"train_acc"+" "+"test_acc")
f.write('\n' +"fold"+str(i+1)+":"+str(train_l_min_l[index_max]) + " ;" + str(train_acc_max_l[index_max]) + " ;" + str(test_acc_max_l[index_max]))
f.close()
print('fold %d, train_loss_min %.4f, train acc max%.4f, test acc max %.4f, time %.1f sec'
% (i + 1, train_l_min_l[index_max], train_acc_max_l[index_max], test_acc_max_l[index_max], time.time() - start))
return train_l_min_l[index_max],train_acc_max_l[index_max],test_acc_max_l[index_max]
k折交叉验证部分
def k_fold(k,image_dir,num_epochs,device,batch_size,optimizer,loss,net):
train_k = '/root/Datasets/bird/train_k.txt'
test_k = '/root/Datasets/bird/test_k.txt'
#loss_acc_sum,train_acc_sum, test_acc_sum = 0,0,0
Ktrain_min_l = []
Ktrain_acc_max_l = []
Ktest_acc_max_l = []
for i in range(k):
get_k_fold_data(k, i,image_dir)
#修改train函数,使其返回每一批次的准确率,tarin_ls用列表表示
train_data = MyDataset(is_train=True, root=train_k)
test_data = MyDataset(is_train=False, root=test_k)
train_loader = torch.utils.data.DataLoader(dataset=train_data, batch_size=10, shuffle=True, num_workers=5)
test_loader = torch.utils.data.DataLoader(dataset=test_data, batch_size=10, shuffle=True, num_workers=5)
loss_min,train_acc_max,test_acc_max=train(i,train_loader,test_loader, net, loss, optimizer, device, num_epochs)
Ktrain_min_l.append(loss_min)
Ktrain_acc_max_l.append(train_acc_max)
Ktest_acc_max_l.append(test_acc_max)
#train_acc_sum += train_acc# train函数epoches(即第k个数据集被测试后)结束后,累加
#test_acc_sum += test_acc#
#loss_acc_sum+=loss_acc
#print('fold %d, lose_rmse_max %.4f, train_rmse_max %.4f, test_rmse_max %.4f ' %(i+1, loss_acc,train_acc, test_acc_max_l[i]))
return sum(Ktrain_min_l)/len(Ktrain_min_l),sum(Ktrain_acc_max_l)/len(Ktrain_acc_max_l),sum(Ktest_acc_max_l)/len(Ktest_acc_max_l)
我对k折交叉验证的理解,只不过是再train训练函数外又套了k层循环,使训练次数由原来的一次变为k次!且每一次仍会对不同的训练集、测试集训练、测试num_epoches次!即相当于原来的train函数由只执行一次变为执行了k次。
最终结果部分
第五折里的一小部分
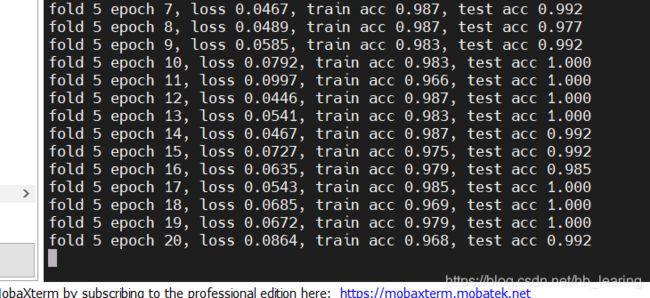
每一折里选取的标准是测试准确率最高的那一个epoch
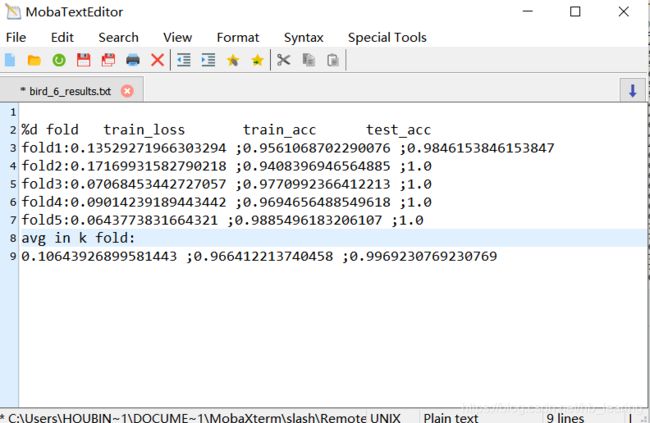
由于我们的数据集比较小而且相机的分辨率很高,再加上强大的efficient—net网络,最后的训练效果几乎完美!
解决问题的方法有很多,如果读者有任何问题以及不同的见解,欢迎留言评论,一起交流,一起进步!
最后感谢指导老师沈龙风老师,为我们小组提供细致的指导,以及提供的鸟类数据集,在深度学习成长的路上能得到良师的指导,感到很幸运!自己也会坚持下去的!希望21年在所研究的细粒度图像识别领域发表一篇论文。
本篇博客为作者原创,转载请注明出处,谢谢!
完整代码
附:完整代码
import os
from PIL import Image
import torch
import torchvision
import sys
from efficientnet_pytorch import EfficientNet
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
from PIL import Image
from torch import optim
from torch import nn
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1'
#import d2lzh_pytorch as d2l
from time import time
import time
import csv
class MyDataset(torch.utils.data.Dataset): # 创建自己的类:MyDataset,这个类是继承的torch.utils.data.Dataset
def __init__(self, is_train,root): # 初始化一些需要传入的参数
super(MyDataset, self).__init__()
fh = open(root, 'r', encoding="utf-8") # 按照传入的路径和txt文本参数,打开这个文本,并读取内容
imgs = [] # 创建一个名为img的空列表,一会儿用来装东西
for line in fh: # 按行循环txt文本中的内容
line = line.rstrip() # 删除 本行string 字符串末尾的指定字符,这个方法的详细介绍自己查询python
words = line.split() # 通过指定分隔符对字符串进行切片,默认为所有的空字符,包括空格、换行、制表符等
imgs.append((words[0], int(words[1]))) # 把txt里的内容读入imgs列表保存,具体是words几要看txt内容而定
self.imgs = imgs
self.is_train = is_train
if self.is_train:
self.train_tsf = torchvision.transforms.Compose([
torchvision.transforms.RandomResizedCrop(524, scale=(0.1, 1), ratio=(0.5, 2)),
torchvision.transforms.ToTensor()
])
else:
self.test_tsf = torchvision.transforms.Compose([
torchvision.transforms.Resize(size=524),
torchvision.transforms.CenterCrop(size=500),
torchvision.transforms.ToTensor()])
def __getitem__(self, index): # 这个方法是必须要有的,用于按照索引读取每个元素的具体内容
feature, label = self.imgs[index] # fn是图片path #fn和label分别获得imgs[index]也即是刚才每行中word[0]和word[1]的信息
feature = Image.open(feature).convert('RGB') # 按照path读入图片from PIL import Image # 按照路径读取图片
if self.is_train:
feature = self.train_tsf(feature)
else:
feature = self.test_tsf(feature)
return feature, label
def __len__(self): # 这个函数也必须要写,它返回的是数据集的长度,也就是多少张图片,要和loader的长度作区分
return len(self.imgs)
def get_k_fold_data(k, k1, image_dir):
# 返回第i折交叉验证时所需要的训练和验证数据
assert k > 1
# if k1==0:#第一次需要打开文件
file = open(image_dir, 'r', encoding='utf-8')
reader=csv.reader(file )
imgs_ls = []
for line in file.readlines():
# if len(line):
imgs_ls.append(line)
file.close()
#print(len(imgs_ls))
avg = len(imgs_ls) // k
#print(avg)
f1 = open('/ddhome/bird20_K/train_k.txt', 'w')
f2 = open('/ddhome/bird20_K/test_k.txt', 'w')
writer1 = csv.writer(f1)
writer2 = csv.writer(f2)
for i, row in enumerate(imgs_ls):
if (i // avg) == k1:
writer2.writerow(row)
else:
writer1.writerow(row)
f1.close()
f2.close()
def k_fold(k,image_dir,num_epochs,device,batch_size,optimizer,loss,net):
train_k = '/root/Datasets/bird/train_k.txt'
test_k = '/root/Datasets/bird/test_k.txt'
#loss_acc_sum,train_acc_sum, test_acc_sum = 0,0,0
Ktrain_min_l = []
Ktrain_acc_max_l = []
Ktest_acc_max_l = []
for i in range(k):
get_k_fold_data(k, i,image_dir)
#修改train函数,使其返回每一批次的准确率,tarin_ls用列表表示
train_data = MyDataset(is_train=True, root=train_k)
test_data = MyDataset(is_train=False, root=test_k)
train_loader = torch.utils.data.DataLoader(dataset=train_data, batch_size=10, shuffle=True, num_workers=5)
test_loader = torch.utils.data.DataLoader(dataset=test_data, batch_size=10, shuffle=True, num_workers=5)
loss_min,train_acc_max,test_acc_max=train(i,train_loader,test_loader, net, loss, optimizer, device, num_epochs)
Ktrain_min_l.append(loss_min)
Ktrain_acc_max_l.append(train_acc_max)
Ktest_acc_max_l.append(test_acc_max)
#train_acc_sum += train_acc# train函数epoches(即第k个数据集被测试后)结束后,累加
#test_acc_sum += test_acc#
#loss_acc_sum+=loss_acc
#print('fold %d, lose_rmse_max %.4f, train_rmse_max %.4f, test_rmse_max %.4f ' %(i+1, loss_acc,train_acc, test_acc_max_l[i]))
return sum(Ktrain_min_l)/len(Ktrain_min_l),sum(Ktrain_acc_max_l)/len(Ktrain_acc_max_l),sum(Ktest_acc_max_l)/len(Ktest_acc_max_l)
def evaluate_accuracy(data_iter, net, device=None):
if device is None and isinstance(net, torch.nn.Module):
# 如果没指定device就使用net的device
device = list(net.parameters())[0].device
acc_sum, n = 0.0, 0
with torch.no_grad():
for X, y in data_iter:
if isinstance(net, torch.nn.Module):
net.eval() # 评估模式, 这会关闭dropout
acc_sum += (net(X.to(device)).argmax(dim=1) == y.to(device)).float().sum().cpu().item()
net.train() # 改回训练模式
else:
if('is_training' in net.__code__.co_varnames): # 如果有is_training这个参数
# 将is_training设置成False
acc_sum += (net(X, is_training=False).argmax(dim=1) == y).float().sum().item()
else:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n
def train(i,train_iter, test_iter, net, loss, optimizer, device, num_epochs):
net = net.to(device)
print("training on ", device)
start = time.time()
test_acc_max_l = []
train_acc_max_l = []
train_l_min_l=[]
for epoch in range(num_epochs): #迭代100次
batch_count = 0
train_l_sum, train_acc_sum, test_acc_sum, n = 0.0, 0.0, 0.0, 0
for X, y in train_iter:
X = X.to(device)
y = y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.cpu().item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
#至此,一个epoches完成
test_acc_sum= evaluate_accuracy(test_iter, net)
train_l_min_l.append(train_l_sum/batch_count)
train_acc_max_l.append(train_acc_sum/n)
test_acc_max_l.append(test_acc_sum)
print('fold %d epoch %d, loss %.4f, train acc %.3f, test acc %.3f'
% (i+1,epoch + 1, train_l_sum / batch_count, train_acc_sum / n, test_acc_sum))
#train_l_min_l.sort()
#train_acc_max_l.sort()
index_max=test_acc_max_l.index(max(test_acc_max_l))
f = open("/root/pythoncodes/results.txt", "a")
if i==0:
f.write("%d fold"+" "+"train_loss"+" "+"train_acc"+" "+"test_acc")
f.write('\n' +"fold"+str(i+1)+":"+str(train_l_min_l[index_max]) + " ;" + str(train_acc_max_l[index_max]) + " ;" + str(test_acc_max_l[index_max]))
f.close()
print('fold %d, train_loss_min %.4f, train acc max%.4f, test acc max %.4f, time %.1f sec'
% (i + 1, train_l_min_l[index_max], train_acc_max_l[index_max], test_acc_max_l[index_max], time.time() - start))
return train_l_min_l[index_max],train_acc_max_l[index_max],test_acc_max_l[index_max]
batch_size=10
k=5
image_dir='/root/Datasets/bird/shuffle_datas.txt'
num_epochs=100
net = EfficientNet.from_pretrained('efficientnet-b0')
net._fc = nn.Linear(1280, 6)
output_params = list(map(id, net._fc.parameters()))
feature_params = filter(lambda p: id(p) not in output_params, net.parameters())
lr = 0.01
optimizer = optim.SGD([{
'params': feature_params},
{
'params': net._fc.parameters(), 'lr': lr * 10}],
lr=lr, weight_decay=0.001)
net=net.cuda()
net = torch.nn.DataParallel(net)
loss = torch.nn.CrossEntropyLoss()
loss_k,train_k, valid_k=k_fold(k,image_dir,num_epochs,device,batch_size,optimizer,loss,net)
f=open("/root/pythoncodes/results.txt","a")
f.write('\n'+"avg in k fold:"+"\n"+str(loss_k)+" ;"+str(train_k)+" ;"+str(valid_k))
f.close()
print('%d-fold validation: min loss rmse %.5f, max train rmse %.5f,max test rmse %.5f' % (k,loss_k,train_k, valid_k))
print("Congratulations!!! hou bin")
torch.save(net.module.state_dict(), "./bird_model_k.pt")