“泰迪杯”挑战赛 - 面向网络舆情的关联度分析
目录
- 研究目标
- 分析方法与过程
2.1.总体流程
2.2.具体步骤
2.3.结果分析 - 结论
- 参考文献
1. 挖掘目标
本次建模的目标是利用客户提供的 2013 年热点事件和用户信息表,采用中文分词技术,建立用户和事件的相互关系,通过计算人物属性(姓名,性别,住址)和每个事件中相对应的分词结果中相同的字数,得出用户和事件之间的关联度,通过 clementine软件,得出用户和用户的关联度。从而可以知道一个事件背后,这个人有多大关系,同时还能看出,这个人和其他人是否有关系。从而在一件事中,找出幕后操纵者和同伙。
2. 分析方法与过程
2.1. 总体流程

本次建模主要包括以下步骤:
步骤一:数据预处理
步骤二:建模和诊断
步骤三:模型优化
2.2. 具体步骤
步骤 1:数据预处理
· 缺失值处理
在用户信息表中,一些用户的身份证是错误的,无法修正,当成缺失值,因此该用户的身份证这一项不列入用户属性中。在提取 html 文件中,不一定能够把所需要的属性(如:性别,地址)提取出来,若不能根据网址和标题分词得到的地址对地址进行填补,计算时当缺失值处理。
· 重复值处理
在原始数据中,同样的事件可能会出现很多次,而经过访问,这些事件大多是抓取时间不同,代表了网站有更新,即事件的更新度,该事件的频率可以作为一个热度进行考虑,但在本次挖掘中,我们是研究用户与用户之间的关系,一个事件可能关系着几个用户,那么如果本事件重复出现,就会使这 2 个用户的关联更大,影响着最后结果的正确性。因此把重复事件全都去掉,只保留第一次出现的事件,同时提取了重复事件频率,方便研究事件的热度以及用户和事件频率的关系。
· 分词处理
运用中科院的分词软件,将每个 txt 文本中事件标题进行分词,词性标注,以方便提取各个属性的词语。
· 异常值处理
在分值后,由于分词软件的词库是有限大的,因此有些词语是识别不了。例如:奥巴马,会被自动分成 3 个单独的名词:奥,巴,马。因此,对于这些分词异常的词语,要进行人工处理,修正。分词后数据,见附件 1。
在用户表中,有身份证一列,而在 html 文件中,几乎没出现过身份证号,为了能充分体现着一项数据,因此可以把身份证转换:性别,出生年月日,发证地。以及一些错误身份证号码的修正。用户信息处理后,见附件 2。
· 相关处理
为了找出用户与用户之间的关系,需要事件去连接起来。因此,各事件中找出具有用户任一属性(例如:姓名,住址,关键字)的事件,见附件 3,然后转化成“用户-事件-用户”这样结构的一张表,见附件 4。
步骤 2:建模与诊断
· 用户与用户关联度
为了能让 Clementine 识别附件 4,因此把附件 4 转换为附件 5,以矩阵的形式存储数据。建立以下流程(附件中记为流 1):

· 用户与事件关联度
1、因为编号以 1031 开头的事件均为新闻,有效属性值太少,故主要研究编号以 1083 开头的事件。通过 html 文件,通过对 html 文件进行查找所有可能跟用户有关的 QQ,手机,住址,MSN 等信息。因为帖子中一般发帖人不将个人信息公布,如果不进入网站查看该贴主的个人资料,从帖子中很少有内容是直接包含个人信息。但在一些招聘以及买卖场合,贴主会公布个人信息,如手机,QQ,性别等,且含个人信息的网址主要是西祠胡同(www.xici.net)。故特通过 replace pioneer 文本处理软件,按照合适的正则表达式来提取含贴主个人信息的事件。并将提取得到的 QQ 手机性别等信息作为与该事件的重要属性。
另外,住址主要通过地方网站,如西子论坛(bbs.xizi.com),而地方网站能很好的代表了贴主的住址地或者相关的地址。为了跟用户表的属性相对应,我们将此作为贴主最可能的居住地。毕竟新闻网站占了多数,造成大量与事件有关的居住地的缺失。当然对于新闻来说,事件标题所含的地址不一定能代表贴主的居住地,但仍以最大匹配为原则,根据事件标题分词得到地点对缺失值进行补充。见附件 11,12,13.
而对于用户表中的居住地,因为要跟事件进行关联,我们将该居住地进行扩充。利用身份证得到一个地址,如果两个地址相同,则不对地址进行扩充。如王林,用户表中住址为江西萍乡人,根据他的身份证,查得发证地也为江西萍乡。而对于两个地址不同的用户,如李天,用户表为北京市海淀区,而发证地为辽宁省抚顺市,故李天很可能关注的事件不仅仅是北京,还可能是辽宁,甚至仍使用辽宁的地方网。故我们得到李天相关的地址为北京海淀,辽宁抚顺。
因为 QQ,手机,MSN 等属性具有唯一性,故先对这些属性与用户的 QQ,手机,MSN 进行查找,除了余晓明附加关键字中出现的一个手机号码 18924889850 外,可发现里面未从出现出用户表里的 QQ,MSN,邮箱,手机。而再从 html 查找 18924889850,可知这是顺德 BBS 网站下的一个热线电话,如果这个电话是与余晓明相关的,那么我们初步可以得到余晓明跟含顺德 BBS有关,再通过他的另外一个附加关键字,汽车销售,从提取含 18924889850 的 html 提取出有关汽车销售的,发现均为二手汽车销售有关,则可以认为余晓明跟事 10831435, 10831436, 10831437, 1831438, 10838241, 10838242,10838243 有关。除此之外,找不到用户跟 html中的 QQ,MSN,手机有相同的,因此把用户的姓名,地址,性别作为用户的 3 个主要属性,通过这 3 个属性,去比较每个事件,把事件变成一个 3*1 的属性集。通过 C++软件(代码见附件 7)分别得到各属性的相同字数,组成一个 3 维向量,如事件 10834508-再曝萍乡巨贪姚波无法无天。因其对应的是新闻网,且相应的 html 没有性别,住址等信息,则根据标题分词得到 姚波,,江西萍乡#,而每个用户的向量是根据每个属性所含的字数多少进行设置,如王林,男,江西萍乡#,则对应向量为(2,1,4),则上述两个向量的关联向量是根据对应属性字数相同来得到,为(0,0,4),再通过(2,1,4)和(0,0,4)求欧式距离得到一个距离,如此,可以得到每个事件跟每个用户的欧氏距离,得到附件 6。通过描绘每个人对编号的散点图,如图 2.22.取最下面 2 个点。按照此做法,应用到每个人。

· 模型诊断
以上模型,我们可以容易发现某些用户对所有事件的距离始终保持很小,因为该用户的自身向量长度比较小,就算这个用户与事件没有关联,其自身向量-(0,0,0)求得的欧式距离仍比较小。所以只能比较用户和事件,不能比较用户和用户的相关度。为消除量纲,我们将距离标准化得到附件 8。再从附件 8 中,对每个用户取出距离最短的 5 个事件,然后通过Clementine 软件求出结果。流程如图 3,用户.txt 见附件 9。

步骤 3:模型分析和优化
·模型缺点
1、 鉴于 clementine 的输入结构局限性,模型中,性别,姓名,地名设置了同样的权重,所以匹配的数量会非常多,实际上,如果设置好各项的权重,那么区分细度会更大。
2、 很容易发现,几乎每个人之间都会有直接或间接联系,当匹配数取相对较小时,所有人都成为了一个集体。
·模型优点
1、 利用 clementine 软件,过程容易操作,而且结果直观。
2、 结果可靠,运用置信度,提升度分析。
·模型改进
1、 先算用户-事件的关联度,利用欧氏距离计算用户与事件之间的距离,距离越小代表用户与事件的关联度越大。
2、 通过 1 的结果,联系到用户-事件-用户,从而找出用户-用户之间的关联度。
3、 在整个模型改进中,将距离标准化。这样就可以消除量纲不同带来的影响,从而使数据更加的准确。
2.3. 结果分析
1、 用户与用户
(1)通过 clementine 软件,实行以上流程,得到下图 4:

由于数据集中 0 居多,该事务级较稀疏,因此支持度较不可信,所以本文作者主要从置信度和提升度两方面来分析。
由于提升度一般都是大于 1 才有效,因此设置了筛选条件为:提升度>1。另外,还设置了置信度>20%。上图的结果就是满足设置条件,并且按照置信度从大到小排序的。从图中可以看到各个用户之间的关联,其中,多个用户与余晓明都有关联。再结合附件二中的用户信息表内容,发现余晓明这一用户的多个属性都与其他用户有相同之处。这说明此次关联是合理的,是和用户信息表紧密联系的。
(2)同时也得出了网络图如图 5 所示:

从图 4 中可见,移动范围到 443-500,余晓明与丁羽心、马小龙之间有关联,这亦可以从关联分析的结果中可以看出。说明关联规则和图形展示的结论一致。将匹配次数分等级,见表 1。等级越高说明相关性越大。根据这个等级划分,可以得出用户间的相关等级表如表 2 所示。

2、 用户与事件
在建模过程中,附件就是用户与事件之间的关联。只是,该结果只知道用户与某个事件是否有关联,并不知道用户与各个事件的关联度排序,见附件 3。因此,在模型改进中,本文作者将解决该问题。
3、 模型诊断
(1)用户与事件之间的关联关系如附件 9 所示。此处就不再累述。
(2)用户与用户之间的关联利用 Clementine 软件来进行分析。由图 3 得到结果如图 6(部分结果)和图 7。

从图 5 中可以看出,此次模型检验虽然采用了关联分析。但由于此次的关联分析的事务数较少,支持度具有较大的说服力。所以从支持度、置信度、提升度来分析。从图中可以看出,王五、马小龙、胡万林、陈龙、张秋白几个用户之间具有较大的关联。这和建模过程得到了结果相差较多。由于,此次关联分析的置信度设置了大于 90%,支持度也大于 5%,另外,提升度也设置了大于 10.由此可见,此次的分析结果比建模时候的结果要精确的多。查看用户信息表(附件 2),发现,王五、马小龙、胡万林、陈龙都是广东广州地区的人,彼此的关联度确实比其他用户要大。这也反应了此次的关联分析的结果是合理、准确的。

图 6 是移动图下方的滑块到频数较高区域后得到的网状图。从图中可以看到,此时,有关联的用户有:李江和李天、张秋白和陈龙、张望和丁羽心、周茂名和周世涛、余晓明和黄明、王五和马小龙以及胡万林。这和关联规则分析的结果一致。说明此次的关联分析是成功的。
(3)因为表格之间的数值难以直接体现事件与用户之间的距离差,但因数据量过大,只选取用户和事件的距离进行进一步分析。为消除量纲,将c++程序得到的距离进行标准化形成distance1表格。使用SAS画出相应的散点图或雷达图。一个事件与各个用户:
1.根据事件10831430与各个用户的距离得到的散点图分别如下:

可见 10831430 事件与用户李世民和方小明的距离较小,也就是关联比较大,并且较多的用户跟 10831430 事件的距离还是大的,而且基本与最大距离持平,也就是这些用户跟事件基本没有关系。而 10831430 具体的事件是:深圳 10 单位涉假劣药品被查,该事件去重后,计算出频率为 1372,是所有事件中频率最高的事件。而频率也代表了它的受关注程度,对于该事件所关联的用户应该得到重视。因此选取了与该事件距离近的用户资料进行比对:男,广州,李龙;男,广州,方小明;男,广州,马六李世民;男,深圳广州,陈龙;男,深圳广州,李四, 张秋白。发现距离最近的四个:方小明,李龙,李世民,张秋白竟然均在广州,而在深圳的陈龙,与事件 10831430 却不见得很近。代码见附件 11。
于是特意选取了在广州发生的事件10831537与各个用户进行分析,得到散点图如下:

这时李龙与10831515的距离明显最近,接着是方小明,李世民,这样看来,对于事件与用户的距离小于-1(标准化后)比较有可信度,而对于距离>0的用户和事件可以说几乎没关系。
多个事件多个用户:
2.探寻 10831476,10831477,10831478,10831479,10831504,10831512,10831514,10831515,10831517,10831518,10831519 事件跟用户高连岳,王力宏,郑玉龙,丁羽心的关系:
散点图:
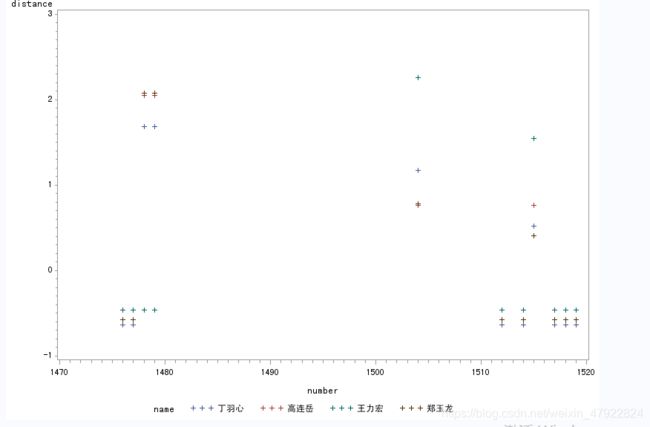
在上述事件中,丁羽心跟除了跟 10831478,10831479 事件外的关联都比较大。10831047 麦 莉-塞勒斯承认与男友分手现在享受单身;10831479 李某某等强奸案 12 月底或将终审因为姓名的原因跟丁羽心找不到关系。10831512,10831514,10831515,10831518,10831519 跟丁羽心,王力宏,郑玉龙的关联比跟高连岳强。但因为距离都比较靠近,不特别悬殊,因此不能说这些事件跟用户的关系程度。
事件 10831537 10831673 10834508 10836579 事件与李世民,李龙,陈龙,李江进行进一步探究,因为雷达图数据需>0;故对上述的距离+4,进行作图,结果更加鲜明:事件 10831673 与李龙特别近,考察事件 10831673:任泉 25 岁女友美艳近照曝光疑为李双江爱徒(组图)。
本来标题中含李双江,目测跟用户中的李江是关联比较大的,而且事件中也提取不了地址,故单单从姓名来得到的距离显示,也是李江与该事件联系最大下述结果也比较吻合,而比较其他类型的姓名,李龙,李世民,陈龙,王林距离越来越大。而对于事件 10834508:再曝萍乡巨贪姚波无法无天。其中唯一信息也只有萍乡,而用户王林恰好就是江西萍乡的,于是在下图 11 中,距离明显比其他用户的近。

3. 结论
本次建模的目标是建立用户和事件的相互关系,并得出用户和用户的关联度。通过此次的数据挖掘,得到用户与事件的关联如表 3 所示:
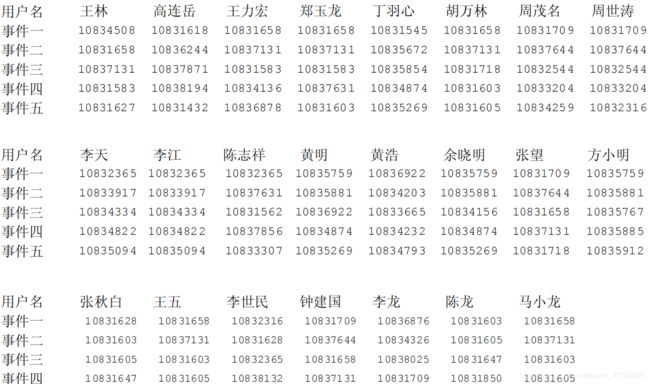

为了更直观显示事件,于是将事件换另一个编号,得到表 4:

根据上表等级排序,可得出用户与用户之间的关联如下所示:
一级关系:李天-李江
二级关系:周世涛-周茂名,黄明-余晓明,张望-钟建国,王五-马小龙
三级关系:王林-郑玉龙-王力宏,郑玉龙-马小龙-钟建国
4. 参考文献
[1]林字等编著.数据仓库原理与实践.北京:人民邮电出版社,2003
[2]朱明,数据挖掘.合肥:中国科技大学出版社 2002,5 [3] 陈京民等.数据仓库与数据挖掘技术[M].北京:电子工业出版社,2002.
[4] 毛国君等.数据挖掘原理与算法[M].北京:清华大学出版社,2005.
[5] 陈文伟等.数据挖掘技术[M].北京:北京工业大学出版社,2002.