node.js(六)之crawler爬虫模块爬取王者荣耀官网所有英雄资源信息
node.js爬虫模块爬取王者荣耀所有英雄信息
一、准备工作
https://pvp.qq.com/web201605/herolist.shtml进入王者荣耀所有英雄页面:
你会看到所有的英雄,打开F12开发者模式
- 打开network,
- 下面找XHR,刷新下网页,
- 下面会出现一个herolist.json的文件.
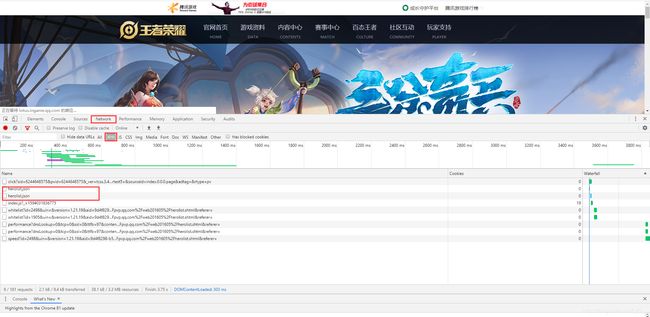
- 鼠标左击herolist.json
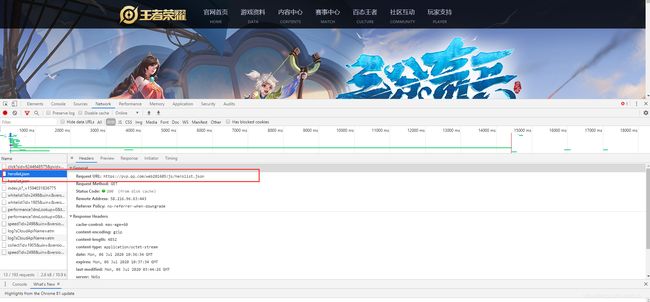
- 得到该json文件路径
二、node.js编码环节
大概步骤:
- 创建一个文件夹
- 用cmd方式打开该文件夹
- 安装
crawler爬虫模块:npm i crawler - 抓包:用爬虫crawler插件来爬网页数据
- 入库:用
mysql-ithm插件把爬到的数据装进数据库中
1、抓包
// 1、抓包:用爬虫crawler插件来爬网页数据
const Crawler = require('crawler')
// 创建一个爬虫实例
const c = new Crawler({
maxConnections: 10,
callback: function (error, res, done) {
if (error) {
console.log(error);
} else {
var $ = res.$
console.log(res.body);
}
}
})
// 发请求
c.queue('https://pvp.qq.com/web201605/js/herolist.json')
发请求的路径就是刚刚在上面获取到的路径,我们来运行一下这个js文件
你会得到一个对象:
message
[
·······························//前面有很多,被我删除了
{
"ename": 524,
"cname": "蒙犽",
"title": "烈炮小子",
"new_type": 0,
"hero_type": 5,
"skin_name": "烈炮小子|归虚梦演"
}, {
"ename": 531,
"cname": "镜",
"title": "破镜之刃",
"new_type": 0,
"hero_type": 4,
"skin_name": "破镜之刃|冰刃幻境"
}, {
"ename": 527,
"cname": "蒙恬",
"title": "秩序统将",
"new_type": 1,
"hero_type": 1,
"skin_name": "秩序统将|秩序猎龙将"}]
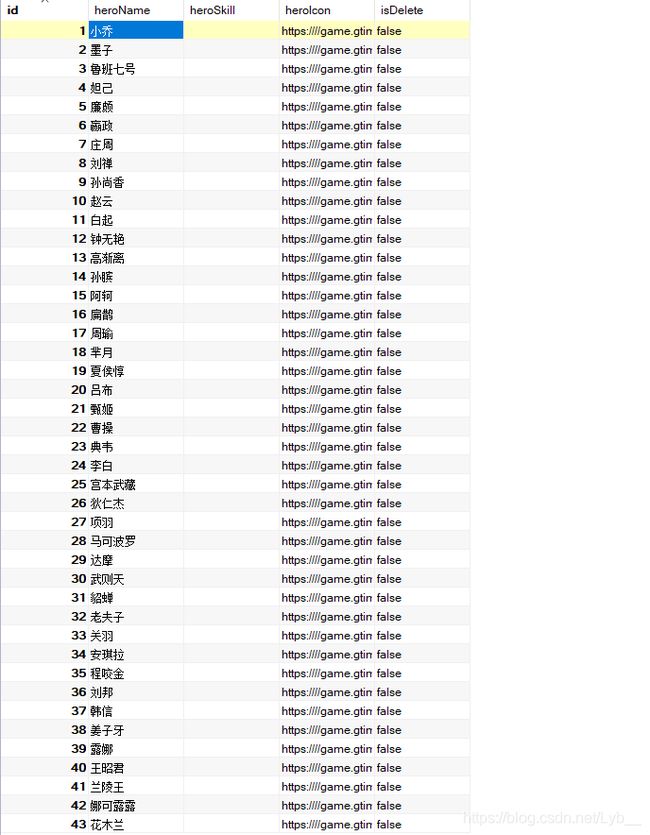
我们可以看出:res.body中就是存放的英雄数据。
我们将console.log(res.body)替换为console.log(JSON.parse(res.body)上述内容会转换为一个对象:
{
ename: 527,
cname: '蒙恬',
title: '秩序统将',
new_type: 1,
hero_type: 1,
skin_name: '秩序统将|秩序猎龙将'
}
上面的数据中没有头像跟技能,我们要获取他们的头像跟技能,要遍历出每一个英雄的ename,拼接一个详情页路径:
JSON.parse(res.body).forEach((v) => {
console.log(`https://pvp.qq.com/web201605/herodetail/${
v.ename}.shtml`)
})
获取到了所有英雄的详情页路径:

获取英雄名称跟技能名称跟头像地址
// 1、抓包:用爬虫crawler插件来爬网页数据
const Crawler = require('crawler')
// 创建一个爬虫实例
const c = new Crawler({
maxConnections: 10,
callback: function (error, res, done) {
if (error) {
console.log(error);
} else {
var $ = res.$
// console.log(JSON.parse(res.body));
JSON.parse(res.body).forEach((v) => {
// console.log(`https://pvp.qq.com/web201605/herodetail/${v.ename}.shtml`)
// 详情请求
xq.queue(`https://pvp.qq.com/web201605/herodetail/${
v.ename}.shtml`)
})
}
}
})
// 发请求
c.queue('https://pvp.qq.com/web201605/js/herolist.json')
// 创建一个请求详情的爬虫实例
var xq = new Crawler({
maxConnections: 10,
// This will be called for each crawled page
callback: function (error, res, done) {
if (error) {
console.log(error);
} else {
var $ = res.$;
// $ is Cheerio by default
//a lean implementation of core jQuery designed specifically for the server
// 英雄名字,技能,头像
console.log($('.cover-name').text(), $('skill-name>b').first().text());
console.log("https://"+$('.ico-play').prev('img').attr('src'));
}
done();
}
});

2、入库
- 首先在全局声明一个数组,用来保存所有信息
let heros = [] - 然后将所有的信息存放到数组中:
// 创建一个请求详情的爬虫实例
var xq = new Crawler({
maxConnections: 10,
// This will be called for each crawled page
callback: function (error, res, done) {
if (error) {
console.log(error);
} else {
var $ = res.$;
// 英雄名字,技能,头像
// console.log($('.cover-name').text(), $('skill-name>b').first().text());
// console.log("https://" + $('.ico-play').prev('img').attr('src'));
heros.push({
heroName: $('.cover-name').text(),
heroSkill: $('skill-name>b').first().text(),
heroIcon: "https://" + $('.ico-play').prev('img').attr('src'),
isDelete: false
})
}
done();
}
});
3.导入 mysql-ithm模块添加到数据库中
//1.导入模块
const hm = require('mysql-ithm');
const {
result } = require('lodash');
//2.连接数据库
//如果数据库存在则连接,不存在则会自动创建数据库
hm.connect({
host: 'localhost', //数据库地址
port: '3306',
user: 'root', //用户名,没有可不填
password: 'qybsjct', //密码,没有可不填
database: 'db1' //数据库名称
});
//3.创建Model(表格模型:负责增删改查)
//如果table表格存在则连接,不存在则自动创建
let heroModel = hm.model('hero', {
heroName: String,
heroSkill: String,
heroIcon: String,
isDelete: String
});
- 最后运行,会发现所有的数据都已经保存到了数据库db中的hero表中