
原文地址。
这篇文章讲的非常好,遵循里面的实践会让开发者少走不少弯路,但是译者并不完全同意本文的观点,异议会以译者注这样的形式提出。
在web应用中,数据库常常会成为性能瓶颈。解决这些性能问题不只是DBA的事,作为开发者,一样有义务通过设计合理的表结构,采用优化后的查询和编写更好的代码来提高数据库的性能。在这篇文章中,将列举一些针对开发者的MySQL优化实践。
在这个网站中能找到很多相关的工具。
查询时使用缓存
MySQl服务器默认是开启了查询缓存的。这是提升性能最有效的方式之一,因为所有的一切都是由数据库引擎完成。当同一条查询被执行很多次时,查询结果会直接从缓存中读取,这非常的高效。
问题在于,很多程序员很容易在编写查询的时候忽视了这个简单的方法。有时候一些查询语句是不会读取缓存的。
// query cache does NOT work
$r = mysql_query("SELECT username FROM user WHERE signup_date >= CURDATE()");
// query cache works!
$today = date("Y-m-d");
$r = mysql_query("SELECT username FROM user WHERE signup_date >= '$today'");
上面一条sql将不会读取缓存,因为用到了CURDATE()这个方法,其它的一些方法会导致一样的后果,像NOW(), RAND()。这些函数的返回结果会变,所以MySQL会对这个查询不使用缓存。如果想要从缓存中读取,就使用上面列出的第二条语句。
使用EXPLAIN
使用EXPLAIN关键字能够让你知道在执行查询的时候MySQL到底做了什么。这会帮助你调试,从而发现某些问题。
EXPLAIN语句会展示哪些索引会被使用到,表是如何被扫描,排序的。
写一条sql,在前面加上EXPLAIN关键字。可以用phpadmin编辑这个信息。
假设忘了给一个字段加索引,执行下面的语句
EXPLAIN SELECT username, group_name
FROM users u
JOIN groups g ON (u.group_id=g.id)
WHERE g.id BETWEEN 1 AND 10

给group_id 加了索引后

可以看到,没加索引前,扫描了7883行,加了索引后扫描了9,16行,执行效率大大提高了。
查询返回一行结果时使用LIMIT 1
有时在执行查询时,知道结果只会返回一行。你想查找一个unique记录,或者你只想检查一下任意行的记录是否存在(译者注:这种情况应该使用COUNT)。
这样的情况下,在查询中加入LIMIT 1可以提升性能。因为加入了limit语句,数据库引擎在找到一条数据后,就会停止查询,而不会全表扫描。
添加索引
索引并不仅仅是primary key或者是unique key。如果有字段会被经常查询到,绝大多数情况下都应该给她们加上索引。
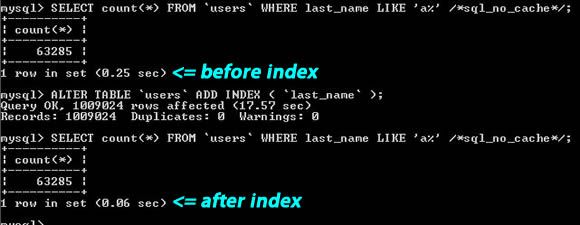
正如上面的示例,即使是像这样的查询
... WHERE last_name LIKE 'a%'
数据库引擎依然会用上索引。
同时,也应该明白有些查询即使添加了索引查询效率也不会提升,比如这样的查询
... WHERE post_content LIKE '%apple%'
JOIN查询条件的优化
在采用大量JOIN查询时,应该让条件两边的字段都是所在表的索引,并且两遍的字段类型要一致。
$r = mysql_query("SELECT company_name FROM users
LEFT JOIN companies ON (users.state = companies.state)
WHERE users.id = $user_id");
比如上面的查询,应该为users的state,和companies的state添加索引,并确认它们的类型一致,如果它们类型不一致的话,MySQL将不会用到它们的索引。对于某些字符串字段,编码也应该保持一致。
不要使用RAND()
有些技巧新手会觉得很酷,但在性能上会很坑,比如下面这条。
$r = mysql_query(
"SELECT username FROM user ORDER BY RAND() LIMIT 1"
);
这条语句的问题在于,MySQL会对表中的每一条数据执行RAND操作(这样会消耗计算),然后排序,再返回一条数据。如果真的需要获取一条随机的结果,可以这样做
$r = mysql_query("SELECT count(*) FROM user");
$d = mysql_fetch_row($r);
$rand = mt_rand(0,$d[0] - 1);
$r = mysql_query("SELECT username FROM user LIMIT $rand, 1");
上面的代码生成一个小于总行数的值,然后将这个值设为offset,返回一条数据。
不要使用SELECT *
查询的数据越多,查询的效率越慢。因为这增加了磁盘IO的时间。当数据库和应用不在同一台机器上时,这还会增加网络的延迟。
只取想要的字段是个好习惯
// not preferred
$r = mysql_query("SELECT * FROM user WHERE user_id = 1");
$d = mysql_fetch_assoc($r);
echo "Welcome {$d['username']}";
// better:
$r = mysql_query("SELECT username FROM user WHERE user_id = 1");
$d = mysql_fetch_assoc($r);
echo "Welcome {$d['username']}";
// the differences are more significant with bigger result sets
总是为表设计一个id字段
为每一张表设计一个id字段,并设置为PRIMARY KEY, AUTO_INCREMENT。类型最好味UNSIGNED,因为这个字段不可能为负。
甚至你的users表中每个人的username都不同,也不要让username成为主键,因为VARCHAR类型作为主键效率更低。
多用ENUM少用VARCHAR
ENUM类型在内部是作为TINYINT类型存储的,所以又快又节省空间,并且还能存储字符串。这让它成为某些字段的最好选择。
如果有一个字段,里面的类型是有限的,比如,status,里面的值可能只有( "active", "inactive", "pending", "expired"),这时选用用ENUM。
(译者注:译者并不完全同意这个观点,实际上在软件开发的过程中,字段出现变化是很正常的事,用VARCHAR可以更好得保持开发灵活性)
善用ANALYSE()
可以使用ANALYSE过程 让MySQL对当前的表和数据进行分析,并提出一些改进意见。只有当表里面存有数据的时候,这个分析才有意义。
举个例子,如果表中有一个主键是INT型,而数据量并不大的情况下,MySQL会建议将这个主键类型改成MEDIUMINT;如果字段使用的是VARCHAR,而值比较单一,MySQL会建议将类型改成ENUM。
注意,这只是建议,最终还是得你自己拿意见。
尽可能使用NOT NULL
除非有特别的原因使用NULL,否则应该永远将字段设置我哦NOT NULL。
首先,想清楚,使用空字符串和NULL有什么区别(或者0和NULL有什么区别),如果没有区别的话,就不要使用NULL(oracle里NULL和空字符串是同义的)。
MySQL官方文档这样说的
"NULL columns require additional space in the row to record whether their values are NULL. For MyISAM tables, each NULL column takes one bit extra, rounded up to the nearest byte."
使用预处理语句
有很多的理由来使用预处理语句,不论是考虑到性能还是安全因素。
预处理会检查绑定好的变量,这样对防治SQL注入攻击很有好处。当然你也可以通过肉眼来检查,但是手工的方法很容易造成错误。使用成熟的框架或者ORM也可以减少这方面的隐患。
再说说性能问题。当同一条查询被使用多次的时候,使用预处理会提升性能。你可以对同一条预处理语句传递多次值,MySQL只会解析一次。
最新的MySQL版本会将预处理语句以二进制文件的形式传输,这样更高效,并会降低网络拥堵。
之前的预处理语句是不会被缓存的,但自从5.1版本后,预处理语句也会被缓存了。
下面是预处理语句的PHP示例
// create a prepared statement
if ($stmt = $mysqli->prepare("SELECT username FROM user WHERE state=?")) {
// bind parameters
$stmt->bind_param("s", $state);
// execute
$stmt->execute();
// bind result variables
$stmt->bind_result($username);
// fetch value
$stmt->fetch();
printf("%s is from %s\n", $username, $state);
$stmt->close();
}
无缓存的查询
每当你执行一条查询时,程序会等待查询的结果出来后再进行下面的逻辑。
使用。使用无缓存查询可以改变这一行为。
用UNSIGNED INT类型存储IP地址
有很多程序员会将IP地址存为VARCHAR(15) 类型,实际上完全可以将IP地址存为4个字节的固定长度。
固定长度的表查询效率更快
当一个表中所有的字段长度都是固定的时候,这个表通常被认为是static 或者是 fixed-length。长度不固定的类型有VARCHAR,BLOB,TEXT,当表中出现上面的任意一种类型时,这个表就不再被认为是fixed-length,引擎在处理的时候会采用不同的方法。
固定长度的表会提高性能,MySQL查询会更快一些,因为固定的长度是很容易计算下一个数据的偏移量的,所以读取的自然也会很快。而如果字段不是定长的,那么,每一次要找下一条的话,都需要程序找到主键。
并且,固定长度的表也更容易被缓存和重建。不过,唯一的副作用是,固定长度的字段会浪费一些空间,因为定长的字段无论你用不用,他都是要分配那么多的空间。
垂直分割
“垂直分割”是一种把数据库中的表按列变成几张表的方法,这样可以降低表的复杂度和字段的数目,从而达到优化的目的。
示例一:在Users表中有一个字段是家庭地址,这个字段是可选字段,相比起其它字段,你并不需要经常读取或是改写这个它。那么,为什么不把它放到另外一张表中呢? 这样会让你的表有更好的性能。小一点的表性能总是更好。
示例二: 你有一个叫 “last_login” 的字段,它会在每次用户登录时被更新。但是,每次更新时会导致该表的查询缓存被清空。所以,你可以把这个字段放到另一个表中,这样就不会影响你对用户ID,用户名,用户角色的不停地读取了,因为查询缓存会帮你增加很多性能。
另外,你需要注意的是,这些被分出去的字段所形成的表,最好经常性地去Join他们,不然的话,这样的性能会比不分割时还要差,而且,会是极数级的下降。
拆分大的INSERT和DELETE语句
当在一个在线网站执行大的INSERT和DELETE语句时,需要格外小心,因为这样的操作会锁表,这可能会导致网站陷入停顿。
Apache 会有很多的子进程或线程。当所有的子进程或线程能快速完成任务时,其效率是最高的。而服务器不希望有过多的子进程和连接,这相当地消耗资源,尤其是内存。
如果你把你的表锁上一段时间,比如30秒钟,那么对于一个有很高访问量的站点来说,这30秒所积累的访问进程/线程,数据库链接,打开的文件数,可能不仅仅会让你的WEB服务Crash,还可能会让你的整台服务器马上挂了。
所以,如果当需要大规模地删除表中的数据时,一定把DELETE语句拆分,使用 LIMIT 条件是一个好的方法。下面是一个示例
while (1) {
mysql_query("DELETE FROM logs WHERE log_date <= '2009-10-01' LIMIT 10000");
if (mysql_affected_rows() == 0) {
// done deleting
break;
}
// you can even pause a bit
usleep(50000);
}
越小的列会越快
对于大多数的数据库引擎来说,硬盘操作可能是最大的瓶颈。所以,把你的数据变得紧凑会对这种情况非常有帮助,因为这减少了对硬盘的访问。
参看 MySQL 的文档 Storage Requirements 查看所有的数据类型。
如果一个表只会有几列罢了(比如说字典表,配置表),那么,我们就没有理由使用 INT 来做主键,使用 MEDIUMINT, SMALLINT 或是更小的 TINYINT 会更经济一些。如果你不需要记录时间,使用 DATE 要比 DATETIME 好得多。
当然,你也需要留够足够的扩展空间,不然,你日后来干这个事,你会死的很难看,参看Slashdot的例子(2009年11月06日),一个简单的ALTER TABLE语句花了3个多小时,因为里面有一千六百万条数据。
选择正确的存储引擎
在 MySQL 中有两个存储引擎 MyISAM 和 InnoDB,每个引擎都有利有弊。
MyISAM 适合于一些需要大量查询的应用,但其对于有大量写的操作支持并不是很好。甚至你只是需要update一个字段,整个表都会被锁起来,而别的进程,就算是读进程都无法操作直到update操作完成。另外,MyISAM 对于 SELECT COUNT(*) 这类的计算是超快无比的。
InnoDB 的趋势会是一个非常复杂的存储引擎,对于一些小的应用,它会比 MyISAM 还慢。但是它支持“行锁” ,于是在写操作比较多的时候,会更优秀。并且,他还支持更多的高级应用,比如:事务。
下面是MySQL的手册
MyISAM Storage Engine
InnoDB Storage Engine
使用一个对象关系映射器(Object Relational Mapper)
使用 ORM (Object Relational Mapper),你能够获得可靠的性能增涨。一个ORM可以做的所有事情,也能被手动的编写出来。但是,这需要一个高级专家。
ORM 的最重要的是“Lazy Loading”,也就是说,只有在需要的去取值的时候才会去真正的去做。但你也需要小心这种机制的副作用,因为这很有可能会因为要去创建很多很多小的查询反而会降低性能。
ORM 还可以把你的SQL语句打包成一个事务,这会比单独执行他们快得多得多。
目前,个人最喜欢的PHP的ORM是:Doctrine。
小心“永久链接”
“永久链接”的目的是用来减少重新创建MySQL链接的次数。当一个链接被创建了,它会永远处在连接的状态,就算是数据库操作已经结束了。而且,自从我们的Apache开始重用它的子进程后——也就是说,下一次的HTTP请求会重用Apache的子进程,并重用相同的 MySQL 链接。
PHP手册:mysql_pconnect()
在理论上来说,这听起来非常的不错。但是从个人经验(也是大多数人的)上来说,这个功能制造出来的麻烦事更多。因为,你只有有限的链接数,内存资源,文件句柄数,等等。
而且,Apache 运行在极端并行的环境中,会创建很多很多的子进程。这就是为什么这种“永久链接”的工作机制不好的原因。在你决定要使用“永久链接”之前,你需要好好地考虑一下你的整个系统的架构。