第一部分 Spark介绍
第二部分 Spark的使用基础
第三部分 Spark工具箱
第四部分 使用不同的数据类型
第五部分 高级分析和机器学习
第六部分 MLlib应用
第七部分 图分析
第八部分 深度学习
到目前为止,已经介绍了Spark引用的基本概念,但这些都是概念性的。 当我们实际运行我们所写的Spark应用时,我们需要一种方式将我们的命令和数据发送给Spark应用。
我们通过SparkSession来做到这些。
当我们在一个交互模式下
(使用spark-shell命令行访问Scala控制台来开始一个交互式会话
或使用pyspark命令行 开始一个交互式Spark应用。)
开始Spark,我们隐式地创建了一个SparkSession来管理Spark应用。当我们通过提交一个job开始Spark,我们必须创建它并访问它。
SparkSession
我们通过一个驱动程序进程来控制Spark应用。 这个驱动程序进程以一个叫做SparkSession的对象 向用户显示自己。这个SparkSession实例是Spark在集群中执行用户自定义操作的方式。
SparkSession和Spark Application之间是一一对应关系。 在Scala和Python中,当启动控制台时 变量以“Spark”为名(变量就是对应的一个SparkSession)可用。
%scala
val myRange = spark.range(1000).toDF("number")
%python
myRange = spark.range(1000).toDF("number")
上述代码创建了一个包含值从0到999的1000行的列。这个数字范围代表一个分布式集合。当运行在一个集群上时,这个数字范围的每个部分存在于不同的执行器上。这就是一个Spark DataFrame。
DataFrame
DataFrame是最常见的结构化API,简单地表一个示具有行和列的数据表。列的清单及这些列的类型 是 schema。 一个简单的类比 就是一个有命名列的电子表格。其 根本的不同是 当一个电子表格 存储在一台电脑的指定为值是每一个Spark DataFrame可以跨数千台计算机。将数据放在不止一台电脑上的原因 是很直观的:或是 数据太大难以存放在一台机器上, 或是在一台机器上执行运算需要太长的时间。
DataFrame的概念不是Spark独有的。R和Python都有类似的概念。R/Python DataFrame(有一些差别)存在与一台机器上而不是多台机器。特定机器上存在的资源 限制了 在Python和R中给定的DataFrame上可以做的事情。然而,因为Spark有对Python和R的语言接口,很容易将Python/R DataFrame转化为Spark DataFrame。
注:Spark游泳许多核心抽象:DataSets、DataFrames、SQL Tables和Resilient Distrubuted Datasets(RDDs)。这些抽象都代表数据的分布式集合,但却有不同的处理数据接口。
最早且最有效率的是DataFrames,对所有语言都是可用的。我们在第二部分介绍DataSets,第三部分介绍RDDs。
下面的概念对所有核心抽象均适用。
Partitions
为了让所有执行器并行地执行任务,Spark将数据分散成块,叫做Partitions。一个 Partition 是一个在集群中一个物理机上的 行集。一个DataFrame的partitions 表示数据是如何在执行过程中 物理地分布在集群的机器上的。 如果你只有一个partition,Spark只会有一个并行进程,即使拥有上千的执行器。 如果你有多个partitions,但只有一个执行器,Spark也只有一个并行进程,因为只有一个计算资源。
需要注意的重要的一点是,对于DataFrame,我们(大多数情况)不会手动操作partitions。我们只简单地指定 在物理partition上的 高级别的 数据转换(transformations),Spark会决定如何在集群上执行这些工作。存在低级别的APIs(通过RDDs接口),我们会在第三部分进行介绍。
Transformations
在Spark中,核心数据结构是不可变的,这意味着一旦被创建就不会被改变。这可能看起来是一个奇怪的概念,如果你不能改变它,那如何来使用它呢?为了“改变”一个DataFrame,你必须告诉Spark你想要如何修改你拥有的DataFrame 为 一个你想要的DataFrame。
这些指令称为transformations。
%scala
val divisBy2 = myRange.where("number % 2 = 0")
%python
divisBy2 = myRange.where("number % 2 = 0")
你会注意到这些返回没有输出,这是因为我们只是指定了一个抽象的转换,Spark不会执行转换直到我们执行一个action操作。Transformations 是使用Spark描述业务逻辑的核心。
有两种Transformations,指定窄依赖的 和 指定宽依赖的。
包含 窄依赖的Transformations(称为窄变换) 每个输入partition只影响一个输出partition。在前面的代码片段示例中,where语句指定一个窄依赖。
一个宽依赖(或宽变换)的变换使 输入partitions影响多个输出partitions。
你会经常听到 宽变换 被称为shuffle,这时Spark会在集群之间 交换partitions。
在窄变换,Spark会自动执行叫做pipelining的操作,这意味着如果我们在DataFrame上指定多个过滤器,他们会在内存中被执行。
但对shuffle来说就不是这样了。当我们执行shuffle时,Spark会将结果写入磁盘。你会在网络之间看到许多关于shuffle最优化的会话。
Transformations 简单的指定了 不同的数据操作,这引入了一个 惰性计算的 话题。
Lazy Evaluation
惰性计算 意思是 Spark会得到最后一刻才执行 计算指令。在Spark中,当我们给出一些操作后不会立即修改数据,而是建立一个 打算作用到源数据的 transformation计划。Spatk会编译 原始的DataFrame转换 为一个在集群上尽可能执行高效的物理计划。
这为终端用户带来了巨大的利益,因为Spark会优化 端到端的 整个数据流。一个例子是DataFrame上被称为“谓词下推”的操作。如果我们构建了一个巨大的Spark job,但在末尾指定了一个只要求从源数据中获取一行的 过滤,最有效的方法是 访问我们需要的单行记录。Spark 实际上会自动下推过滤器来为我们进行优化。
Actions
Transformations 允许我们构建我们的逻辑转换计划。为了触发计算,我们运行一个action。
一个action命令Spark从一系列transformation计算结果。最简单的action是 count ,返回DataFrame中记录的总数。
共有三种actions:
控制台中观察数据;
收集对象为各自语言的原生对象;
写入输出数据源;
在指定action操作时,我们开始了一个Spark job来运行 过滤转换(窄变换),一个聚合操作(宽变换)在每个partition上执行counts,然后 一个 collect操作 将结果传递给 一个各自语言的原生对象。
Spark UI
当Spark执行代码块时,用户可以通过Spark UI来监控 任务的进度。
Spark UI 在驱动节点的4040端口可用。维护Spark任务状态、环境和集群状态的信息。特别在调优调试时非常有用。
一个端到端的例子
在前面的例子中,我们创建了一个由一组数构成的DataFrame;尽管完全不是大数据的背景。在本节中,我们会运用一个例子 巩固前面所介绍的所有东西,并一步一步解释在后台都发生了什么。
Spark具有从大规模数据源读写数据的能力。为了读入本例中的数据,我们会使用一个与我们的SparkSession相关联的DataFrameReader。 这样做时,我们会指定文件的类型。在我们的例子中,我们会做一件事 叫做 schema推断,我们希望Spark能够对DataFrame的模式进行最好的推测。原因是CSV文件不是完全结构化的数据格式。我们也希望指定文件的头就是第一行。
为了获得这些信息,Spark会先读取数据的一小部分,然后尝试去 根据Spark中可用的类型 解析这些行中的数据类型。你会发现这一过程运行效果很好。在读取数据时,我们也有 可以用来 严格指定schema 的选项(我们建议在生产环境下使用)。
%Scala
val flightData2015 = spark
.read
.option("inferSchema","true")
.option("header","true")
.csv("/mnt/defg/flight-data/csv/2015-summary.csv")
%python
flightData2015 = spark\
.read\
.option("inferSchema","true")\
.option("header","true")\
.csv("/mnt/defg/flight-data/csv/2015-summary.csv")
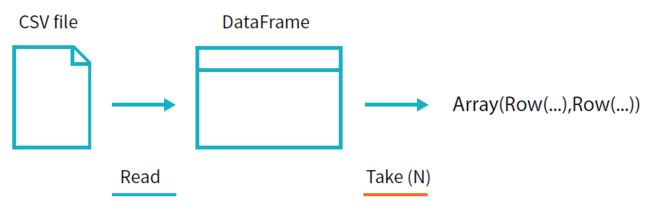
flightData2015.take(3)
Array([United State, Romania, 15], [United States, Croatia...
每个DataFrames(在Scala和Python中)都有一组未指明函数的列。 行的数目是“未指定的”是因为读取数据是一个transformation,其因此是一个lazy操作。Spark只会 为了 猜测每列的数据类型 窥视几行数据。
注释:
记住,sort 不会调整DataFrame。我们使用的sort是一个 transformation,其通过转换原来的DataFrame返回一个新的DataFrame。然我们说明一下当我们在结果DataFrame上使用take时会发生什么。
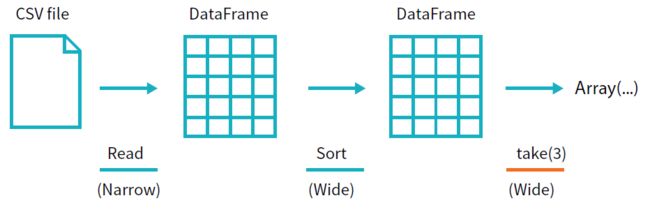
当我们调用sort时 不会有任何事情发生,因为它只是一个transformation。然而,我们可以看到Spark构建了一个关于其将如何跨集群执行的计划,我们可以通过explain看到这个计划。我们可以在任何DataFrame对象上调用explain 来查看DataFrame的血统(或Spark会如何执行相应的查询)。
flightData2015.sort("count").explain()
解释计划 可以同上向下阅读,最上面是最终的结果,底部是源数据。解释计划对调试来说是有用的工具。
接下来,正如我们前面所做的,我们可以指定一个action来开始这个计划。然而在这么做之前,我们会设置一个配置。默认地,当我们执行一个shuffle,Spark会输出200个shuffle partitions。我们将这个值设置为5,为了减少输出 partition分区的数量。
spark.conf.set("spark.sql.shuffle.partitions","5")
flightData2015.sort("count").take(2)
...Array([United States, Singapore, 1], [Moldova, United States, 1])
该操作通过下图来说明。你会注意到除了 逻辑transformation,还包含了物理分区 的 技术。
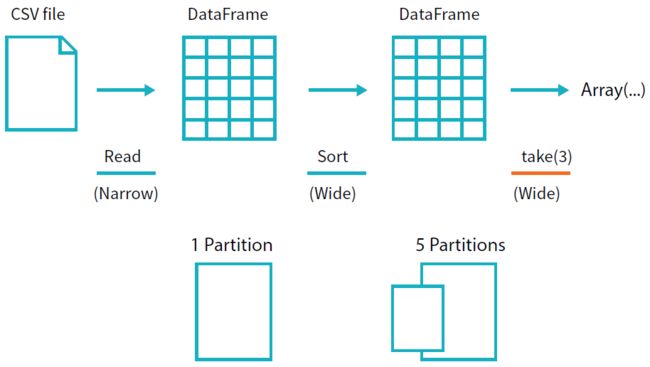
我们所构建的ransformations的逻辑计划 为DataFrame 定义了一个血统,所以Spark在任何时刻 都知道如何 通过执行所有其之前在相同输入数据上执行过的操作 来重新计算任意分区。
这是Spark编程模式的核心,当数据上的转换保持不变时,函数式编程在相同的输入下总是得到 相同的输出。
我们不对物理数据进行操作,而是 通过配置像 shuffle partitions 参数这样的参数 来配置物理执行的特性。你可以通过Spark UI来查看物理和逻辑执行 的 特性。
DataFrame和SQL
Spark中相同的transformation,不管使用什么语言,其完全按相同的方式来执行。
可以用SQL或DataFrame(不论用Scala、Python、R或Java)来描述业务逻辑,Spark会在实际执行代码前 将该逻辑编译为底层计划(在explain函数 中看到的)。SparkSQL允许用户 将任意DataFrame注册为一个表或视图,并使用纯SQL来查询。 在使用SQL和写DataFrame代码之间没有 性能差距。两种方法都会被编译为相同的底层执行计划。
%scala
flightData2015.createOrReplaceTempView("flight_data_2015")
%python
flightData2015.createOrReplaceTempView("flight_data_2015")
注册为表后,我们就可以使用SQL来查询数据了。
执行一个SQL查询,我们使用 spark.sql 函数(spark还是 那个SparkSession变量)方便地返回一个新的DataFrame。作为一个用户,可以在任何给定的时间点以最方便的方式指定转换(使用SQL还是DataFrame),而不需要牺牲任何效率!为了理解这一点,下面举两个例子。
%scala
val sqlWay = spark.sql("""
SELECT DEST_COUNTRY_NAME, count(1)
FROM flight_data_2015
GROUP BY DEST_COUNTRY_NAME
""")
val dataFrameWay = flightData2015
.groupBy('DEST_COUNTRY_NAME')
.count()
sqlWay.explain
dataFrameWay.explain()
%python
sqlWay = spark.sql("""
SELECT DEST_COUNTRY_NAME, count(1)
FROM flight_data_2015
GROUP BY DEST_COUNTRY_NAME
""")
dataFrameWay = flightData2015\
.groupBy("DEST_COUNTRY_NAME")\
.count()
sqlWay.explain()
dataFrameWay.explain()
== Physical Plan ==
*HashAggregate(keys=[DEST_COUNTRY_NAME#182], functions=[count(1)])
+- Exchange hashpartitioning(DEST_COUNTRY_NAME#182, 5)
+- *HashAggregate(keys=[DEST_COUNTRY_NAME#182], functions=[partial_count(1)])
+- *FileScan csv [DEST_COUNTRY_NAME#182] ...
== Physical Plan ==
*HashAggregate(keys=[DEST_COUNTRY_NAME#182], functions=[count(1)])
+- Exchange hashpartitioning(DEST_COUNTRY_NAME#182, 5)
+- *HashAggregate(keys=[DEST_COUNTRY_NAME#182], functions=[partial_count(1)])
+- *FileScan csv [DEST_COUNTRY_NAME#182] ...
可以看到,这些计划被编译成了完全相同的底层计划。
需要知道的一点是,Spark中的DataFrames(和SQL)已有大量可用的操作。上百个函数可以用来帮助你更快地解决大数据问题。