本文结构安排
图聚类简介
正则化割
Louvain
非负矩阵分解(NMF)
其他常见方法
图(graph):是一种由点和边集构成的结构
图聚类(graph clustering) : 将点划分为不同的簇,使得簇内的边尽量多,簇之间的边尽量少。也称为图划分(partitioning),社区检查(community detection)
应用Louvain算法产生的社区检测图示
Normalized cut
正则化割的基本原理是使各簇之间的割最小,但不是算其最小割,因为这会使相对孤立的边缘点“自成一团”,造成社区大小的不均衡。算法的基本过程的前半部分类似于谱聚类,先由度矩阵和邻接矩阵,计算出拉普拉斯矩阵,得到第二小到K+1小的特征向量,对其进行K-means聚类,预处理得到k’个簇。之后,计算两两簇合并之后,计算其正则化割,选择正则化割最小的两个簇合并。每次合并减小一个簇,直到减小到K个簇。
k-路划分:
(1)计算相似度矩阵W和度矩阵D
(2)计算标准化拉普拉斯矩阵
(3)从第二小的特征值开始找个最小的特征值对应的特征向量构造维度的特征矩阵F
(4)对特征矩阵F按行进行标准化后,进行Kmeans聚类得到簇
(5)在这个簇中,每次选取两个簇进行合并,直到最后剩下k个簇,选取的策略是最小化Ncut时的合并组合
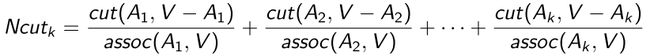
Louvain
Louvain算法的基本原理也是采用合并的策略,但是它合并的标准是模块度增益。首先将每个节点初始化为不同社区,计算将节点加入其邻居社区的模块度增益△Q,选择使模块度增益最大的邻居进行合并,合并后的社区看做一个新的节点,直到两两社区合并的模块度增益都不大于0,则停止合并。
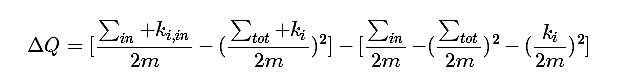
Louvain算法步骤如下:
(1)初始化每个数据点为一个社区;
(2)对每个数据点,尝试加入其邻居所在的社区,计算比较加入前后的模块度增益ΔQ,选出增益最大的那个邻居社区,若其对应的增益ΔQ>0,则该数据点加入这个社区,否则不改变其原来社区划分;
(3)将得到的社区视为一个节点,社区内节点之间边权重转化为新节点环的权重,社区间的边权重转化为新节点间的边权重;
(4)重复(2)(3)步骤,直至满足收敛条件。
收敛条件可以是迭代了一定的次数,亦或是模块度不再增加。
NMF

NMF的基本原理是将原始矩阵分解得到社区指示矩阵和基矩阵,随机初始化这两个矩阵的元素,迭代更新这两个矩阵,更新规则如下:
最小化目标函数:
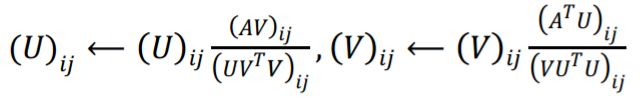
停止条件是目标函数收敛,即上一个计算的目标函数值,与本次目标函数值的差小于一个设定的阈值。
而对于目标函数收敛后得到的U,我们可以根据其每行(对应每个数据点)的最大值对应的列数,得到该数据点对应的类标(即将它分配给这个社区),故而可以得到如下NMF算法的算法步骤:
(1)初始化U、V矩阵(非负)
(2)根据U、V的更新公式异步迭代更新
(3)满足终止条件后终止更新U、V
(4)找到U中每个数据点最大值对应的列数,分配其作为类标
LPA
标签传播算法(LPA)的做法比较简单:
第一步: 为所有节点指定一个唯一的标签;
第二步: 逐轮刷新所有节点的标签,直到达到收敛要求为止。对于每一轮刷新,节点标签刷新的规则如下:
对于某一个节点,考察其所有邻居节点的标签,并进行统计,将出现个数最多的那个标签赋给当前节点。当个数最多的标签不唯一时,随机选一个。
KeyCode
Normalized cut
构建相似度矩阵W和计算度矩阵D;由于有每个节点的特征向量feature vector,故而节点之间的相似性可以通过对应特征向量的余弦距离度量出来,由于数据集是.mat文件,所以我使用matlab生成相似度矩阵和高斯距离矩阵后再作为Java Code的输入。
= zeros(length(A),length(A));
for i = 1:length(A)
for j = 1:i-1
W(i,j) = 1-pdist2(F(i,:),F(j,:),'cosine');
W(j,i) = W(i,j);
end
end
public void calculateW(){
this.W=DenseMatrix.Factory.zeros(nsamples, nsamples);
for (int p=0;p计算标准化拉普拉斯矩阵,由度矩阵D和相似度矩阵W可得拉普拉斯矩阵L再进行标准化
Matrix I = DenseMatrix.Factory.eye(this.nsamples,this.nsamples);
Matrix D = DenseMatrix.Factory.eye(this.nsamples,this.nsamples);
for (int i=0;i构建特征矩阵;计算标准化拉普拉斯矩阵的特征值和特征向量,从第二小的特征值开始选取k′个最小的特征值对应的特征向量组成特征矩阵:
Matrix[] eigenValueDecompostion = this.L.eig();
Matrix eigenVector = eigenValueDecompostion[0];
Matrix eigenValue = eigenValueDecompostion[1];
List res = eigenVector.getColumnList();
List NCutResult=new ArrayList<>();
for (int i=1;i 对特征矩阵进行聚类,不断选取两个簇合并直至剩下k个簇,选取哪两个簇进行合并取决于 此时哪两个簇合并得到的Ncut值最小.
KMeans NCutkMeans = new KMeans(this.k,NCut);
NCutkMeans.clustering();
Louvain
初始化每个数据点为一个社区:
initSingletonClusters();
public void initSingletonClusters()
{
int i;
clustercount = nodecount;
cluster = new int[nodecount];
for (i= 0; i < nodecount; i++)
cluster[i] = i;
}
对每个数据点,尝试加入其邻居所在的社区,计算比较加入前后的模块度增益ΔQ,记录最大的模块度增益和它对应的社区,若最大增益max>0,则将该数据点加入对应的社区:特别地,这里的数据点既指单个节点,也指一个社区,故统一按社区视为数据点来处理,只是单个数据点算只有一个节点的社区。
public void communityDetection(){
boolean update=true;
Set cur_set = new TreeSet<>();
for (int i=0;i c1 = diGraph.getClusterList(i);//Cluster C1 vertex_id_set
Set c2 = diGraph.getClusterList(j);//Cluster C2 vertex_id_set
if (c1.size()!=0 && c2.size()!=0) {
double deltaQ = calculateDeltaQ(c1, c2, i, j);//calculate DeltaQ
if (deltaQ > bestdeltaQ) {
bestdeltaQ = deltaQ;
bestcluster = j;
}
}
}
}
if (bestdeltaQ > 0){
diGraph.adjList.get(i).setCluserlabel(bestcluster);//change clusterlabel
}
else {
diGraph.adjList.get(i).setCluserlabel(i);//keep clusterlabel
}
diGraph.clearVisited();//clear all
}
last_set = current;//judge algorithm converge or not
cur_set.clear();
current="";
for (int i=0;i 计算模块度增益的函数
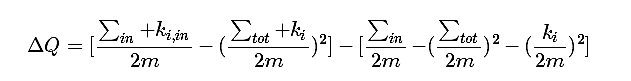
public double calculateDeltaQ(Set c1,Set c2,int startlabel,int endlabel) {
double m=((double) diGraph.getE());
double k_i_in = diGraph.getClusterWeightIn(c1,c2,startlabel,endlabel);
double sigma_in = diGraph.getIn(c2);
double total = diGraph.getClusterWeightTotal(endlabel);
double k_i = diGraph.getClusterWeightTotal(startlabel);
double tmp1 = (sigma_in+k_i_in)/(2.0*m);
double tmp2 = (total+k_i)/(2.0*m);
double tmp3 = sigma_in/(2.0*m);
double tmp4 = total/(2.0*m);
double tmp5 = k_i/(2.0*m);
double deltaQ=tmp1-tmp2*tmp2-tmp3+tmp4*tmp4+tmp5*tmp5;
return deltaQ;
}
NMF
根据迭代更新公式写代码:

public void communityDetection() {
Matrix fenzi = DenseMatrix.Factory.zeros(this.N,this.K);
Matrix fenmu = DenseMatrix.Factory.zeros(this.N,this.K);
Matrix DU = DenseMatrix.Factory.zeros(this.N,this.K);
Matrix DV = DenseMatrix.Factory.zeros(this.N,this.K);
Matrix Tmp = this.U.mtimes(this.V.transpose());
Matrix E = this.A.minus(Tmp);
double cur_error = E.norm2();
double last_error = 0.0;
for (int it = 0; it < this.maxiterator ; it++){
fenzi = this.A.mtimes(this.V);
fenmu = this.U.mtimes(this.V.transpose());
fenmu = fenmu.mtimes(this.V);
DU = fenzi.divide(fenmu);
this.U = this.U.times(DU);
fenzi = this.A.transpose().mtimes(this.U);
fenmu = this.V.mtimes(this.U.transpose());
fenmu = fenmu.mtimes(this.U);
fenmu = fenmu.plus(this.lambda);
DV = fenzi.divide(fenmu);
this.V = this.V.times(DV);
last_error=cur_error;
Matrix Tmp1 = this.U.mtimes(this.V.transpose());
Matrix E1 = this.A.minus(Tmp1);
cur_error = E1.norm2();
if (Math.abs(cur_error-last_error)<0.00001){
break;
}
}
}
Experiments on Datasets
说明:相似度矩阵使用属性矩阵构造的余弦相似度
高斯距离矩阵使用全连接度量模式下的高斯核函数

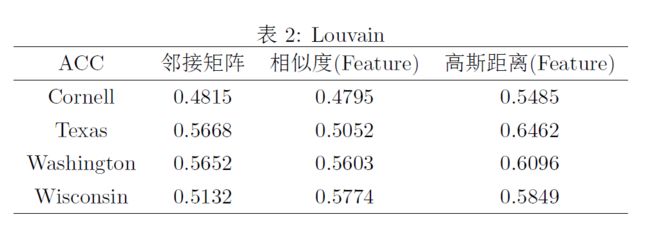
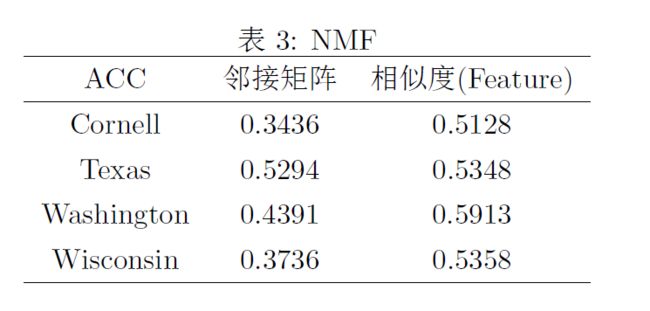
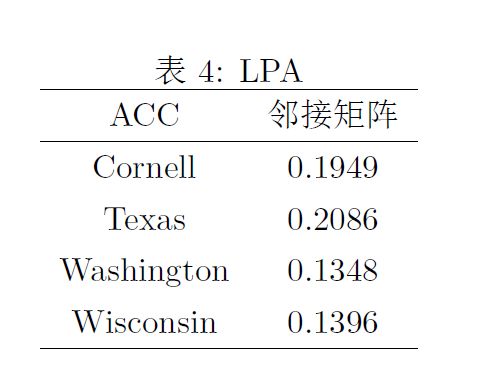
Algorithm Comparison and Hyperparameter
Normalized cut
所谓Clustering,就是说聚类,把一堆东西(合理地)分成两份或者K份。从数学上来说,
聚类的问题就相当于Graph Partition的问题,即给定一个图G = (V, E),如何把它的顶点集划分为不相交的子集,
使得这种划分最好。谱聚类算法的主要优点有:谱聚类只需要数据之间的相似度矩阵,因此对于处理稀疏数据的聚类很有效。这点传统聚类算法比如K-Means很难做到。由于使用了降维,因此在处理高维数据聚类时的复杂度比传统聚类算法好。谱聚类算法的主要缺点有:如果最终聚类的维度非常高,则由于降维的幅度不够,谱聚类的运行速度和最后的聚类效果均不好。聚类效果依赖于相似矩阵,不同的相似矩阵得到的最终聚类效果可能很不同。
Louvain
Louvain算法是一种基于多层次优化Modularity的算法,它的优点是快速、准确,是性能最好的社区发现算法之一。Modularity函数最初被用于衡量社区发现算法结果的质量,它能够刻画发现的社区的紧密程度。那么既然能刻画社区的紧密程度,也就能够被用来当作一个优化函数,即将结点加入它的某个邻居所在的社区中,如果能够提升当前社区结构的modularity。Louvain不断地遍历网络中的结点,尝试将单个结点加入能够使modularity提升最大的社区中,直到所有结点都不再变化,并且将一个个小的社区归并为一个超结点来重新构造网络,这时边的权重为两个结点内所有原始结点的边权重之和。一直迭代直至算法稳定。Louvain可以利用modularity的特性,决定是否进行合并,相比于谱聚类——无论是否合理都进行分割,Louvain的使用更加灵活,算法进行时不需要设置具体的社区个数,社区的个数由社区自己的性质决定。但是也可以在合并的过程中加入终止条件或者是别的约束,以满足固定的社区个数。
NMF
NMF(非负矩阵分解)对原始矩阵的重构误差最小化,且原始数据的统计信息也可以得到保持。NMF在处理聚类问题上有以下几个方面的优势:
- 非负性,由于NMF中分解得到的簇划分子矩阵具有非负性,只需要找到数据在哪个簇中的值最大就可以确定该数据的簇标签。非负矩阵分解的非负约束性使其能够清晰的指出数据点的簇标签。
- 易构性,根据不同的数据和目标,可以构造与之匹配的非负矩阵分解方法。只需要根据原始数据构造出原始矩阵,接着只需要加入具体的约束即可开始训练。
- 易于优化,因为非负矩阵分解的方法目标公式类似,所有优化的方式比较容易套用。
劣势:由于非负矩阵分解处理输入和输出全是矩阵形式的,当数据量过大时,很容易出现内存消耗过大甚至超出运行内存报错的情况,可以往这几个方面解决。采取缩减方案——多层图划分,采取划分方案——主成分分析或k均值预聚类,递增方案——随机优化非负矩阵分解方法,采取分布式并行实施方案。
LPA
标签传播算法是不重叠社区发现的经典算法,其基本思想是:将一个节点的邻居节点的标签中数量最多的标签作为该节点自身的标签。给每个节点添加标签(label)以代表它所属的社区,并通过标签的“传播”形成同一标签的“社区”结构。给每个节点添加标签(label)以代表它所属的社区,并通过标签的“传播”形成同一标签的“社区”结构。一个节点的标签取决于它邻居节点的标签:假设节点z的邻居节点有z1至zk,那么哪个社区包含z的邻居节点最多z就属于那个社区(或者说z的邻居中包含哪个社区的标签最多,z就属于哪个社区)。优点是收敛周期短,无需任何先验参数(不需事先指定社区个数和大小),算法执行过程中不需要计算任何社区指标。
时间复杂度接近线性:对顶点分配标签的复杂度为O(n),每次迭代时间为O(m),找出所有社区的复杂度为O(n+m),但迭代次数难以估计。