python自动化(五)接口自动化:1.接口测试基础
一.接口测试价值与体系




二.常见的接口协议
1.TCP/IP协议
-
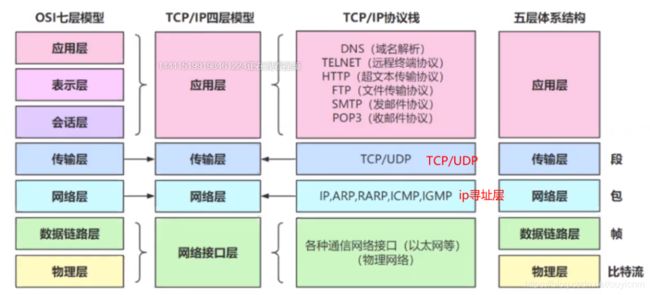
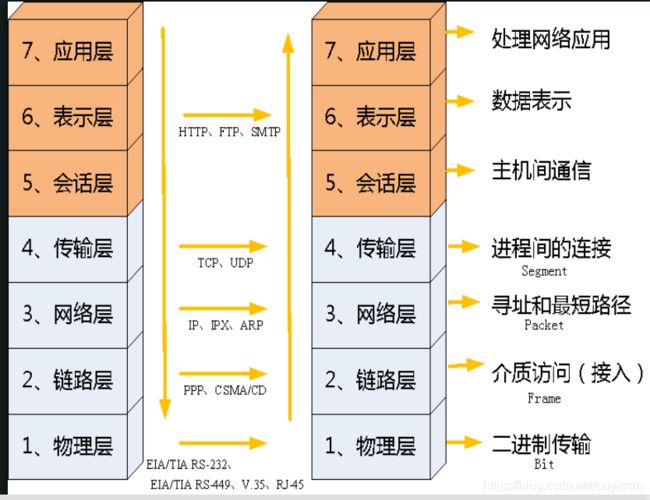
TCP/IP协议是在OS7层模型上总结生成的。
-
TCP/IP 是互联网相关的各类协议族的总称,比如:TCP,UDP,IP,FTP,HTTP,ICMP,SMTP 等都属于 TCP/IP 族内的协议。
-
TCP/IP模型是互联网的基础,它是一系列网络协议的总称。这些协议可以划分为四层,分别为链路层、网络层、传输层和应用层。
- 链路层:负责封装和解封装IP报文,发送和接受ARP/RARP报文等。
- 网络层:负责路由以及把分组报文发送给目标网络或主机。
- 传输层:负责对报文进行分组和重组,并以TCP或UDP协议格式封装报文。
- 应用层:负责向用户提供应用程序,比如HTTP、FTP、Telnet、DNS、SMTP等。

2.TCP与UDP协议
TCP与UDP协议都是传输层协议。在网络中它们都用于处理数据包,但是它们又各有不同。

(1)TCP协议
-
传输层上的协议
-
TCP 协议提供了一种端到端的、基于连接的、可靠的通信服务。
-
TCP协议头

-
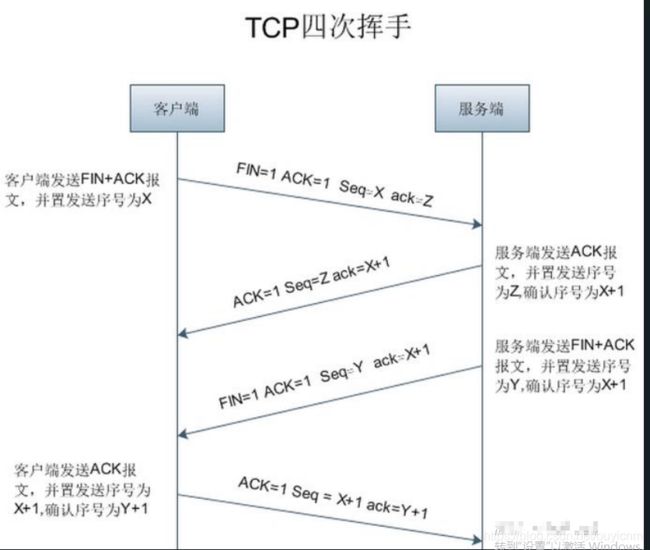
建立TCP需要三次握手才能建立,而断开连接则需要四次挥手。

-
四次挥手,TCP链接是全双工的,因此每个方向上都必须要关闭。
(2)UDP协议
- 定义:UDP(User Data Protocol,用户数据报协议)它是面向非连接的协议,它不与对方建立连接,而是直接就把数据包发送过去!UDP适用于一次只传送少量数据、对可靠性要求不高的应用环境。
- 对比:与TCP最大的差别在于它在建立连接前不会进行三次握手,属于不可靠的传输。
- 优点:可以显著地提高性能。
- 应用:例如:ping命令、QQ、网络电视
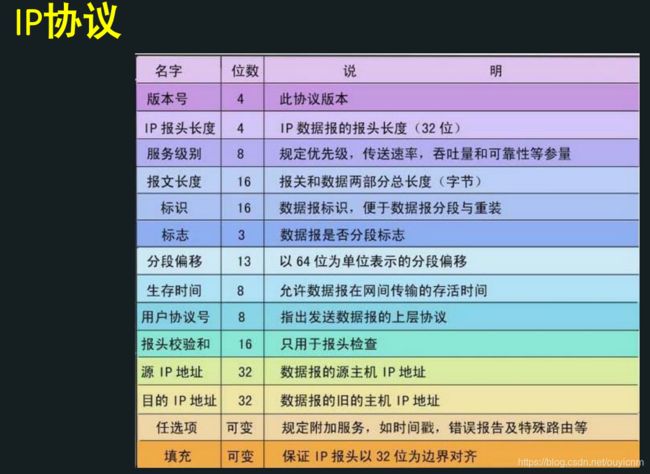
3.IP协议
- IP —Internet Protocol,是Internet层(网络层)的协议
- 用于将多个包交换网络连接起来的,在源地址和目的地址之间传送数据报。
- IP协议头

4.HTTP协议(重点)
HTTP协议,是一种应用层协议。规定了浏览器和www服务器之间互相通信的规则,通过Internet传送www文档的数据传送协议。
(1)HTTP的特点和原理
- HTTP 协议是一种请求-应答式的协议。
- 最显著的特点是客户端发送的每次请求都需要服务器回送响应,在请求结束后,会主动释放连接。从建立连接到关闭连接的过程称为“一次连接”。
- 原理:
• 短连接:用完就释放。
• 需要不断向服务器发起连接请求来保持在线状态。
• 若服务器长时间无法收到客户端的请求,则认为客户端“下线”
• 若客户端长时间无法收到服务器的回复,则认为网络已经断开。
(2)HTTP的工作原理
HTTP协议定义Web客户端如何从Web服务器请求Web页面,以及服务器如何把Web页面传送给客户端。HTTP协议采用了请求/响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据。服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据。
以下是 HTTP 请求/响应的步骤:
-
客户端连接到Web服务器
一个HTTP客户端,通常是浏览器,与Web服务器的HTTP端口(默认为80)建立一个TCP套接字连接。例如,http://www.baidu.com。 -
发送HTTP请求
通过TCP套接字,客户端向Web服务器发送一个文本的请求报文,一个请求报文由请求行、请求头部、空行和请求数据4部分组成。 -
服务器接受请求并返回HTTP响应
Web服务器解析请求,定位请求资源。服务器将资源复本写到TCP套接字,由客户端读取。一个响应由状态行、响应头部、空行和响应数据4部分组成。 -
释放连接TCP连接
若connection 模式为close,则服务器主动关闭TCP连接,客户端被动关闭连接,释放TCP连接;若connection 模式为keepalive,则该连接会保持一段时间,在该时间内可以继续接收请求; -
客户端浏览器解析HTML内容
客户端浏览器首先解析状态行,查看表明请求是否成功的状态代码。然后解析每一个响应头,响应头告知以下为若干字节的HTML文档和文档的字符集。客户端浏览器读取响应数据HTML,根据HTML的语法对其进行格式化,并在浏览器窗口中显示。
例如:在浏览器地址栏键入URL,按下回车之后会经历以下流程:
浏览器向 DNS 服务器请求解析该 URL 中的域名所对应的 IP 地址;
解析出 IP 地址后,根据该 IP 地址和默认端口 80,和服务器建立TCP连接;
浏览器发出读取文件(URL 中域名后面部分对应的文件)的HTTP 请求,该请求报文作为 TCP 三次握手的第三个报文的数据发送给服务器;
服务器对浏览器请求作出响应,并把对应的 html 文本发送给浏览器;
释放 TCP连接;
浏览器将该 html 文本并显示内容;
(3)HTTP请求
HTTP/1.1协议中共定义了八种方法(也叫“动作”)来以不同方式操作指定的资源:
-
GET
向指定的资源发出“显示”请求。使用GET方法应该只用在读取数据,而不应当被用于产生“副作用”的操作中,例如在Web Application中。其中一个原因是GET可能会被网络蜘蛛等随意访问。 -
HEAD
与GET方法一样,都是向服务器发出指定资源的请求。只不过服务器将不传回资源的本文部分。它的好处在于,使用这个方法可以在不必传输全部内容的情况下,就可以获取其中“关于该资源的信息”(元信息或称元数据)。 -
POST
向指定资源提交数据,请求服务器进行处理(例如提交表单或者上传文件)。数据被包含在请求本文中。这个请求可能会创建新的资源或修改现有资源,或二者皆有。 -
PUT
向指定资源位置上传其最新内容。 -
DELETE
请求服务器删除Request-URI所标识的资源。 -
TRACE
回显服务器收到的请求,主要用于测试或诊断。 -
OPTIONS
这个方法可使服务器传回该资源所支持的所有HTTP请求方法。用’*'来代替资源名称,向Web服务器发送OPTIONS请求,可以测试服务器功能是否正常运作。 -
CONNECT
HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。通常用于SSL加密服务器的链接(经由非加密的HTTP代理服务器)。
比较常用的是get和post请求方式。需要重点掌握。
(4)GET请求详解
- GET请求主要是数据的获取

- GET /oscommerce/index.php HTTP/1.1,指明了三个关键信息:请求类型为GET,资源URL地址为/oscommerce/index.php,协议类型和版本为HTTP/1.1。
- Accept:告诉服务器当前浏览器能接受和处理的介质类型,如果*/*表示可接受所有类型。
- Accept-Language:告诉服务器当前浏览器能接受和处理的语言。上述请求表示浏览器接受zh-CN(中国中文)。另外的有en-US(美国英文)。
- User-Agent:告诉服务器当前客户端的操作系统和浏览器内核版本信息
- Accep-Encoding:告诉服务器当前客户端支持gzip格式压缩,这样服务器端可以将HTML, Javascript或CSS这种文本型资源压缩后再传递给浏览器,浏览器接收到后有解压缩的能力。这样可以显著减少资源占用的带宽和在网络上传输的时间。
- Host:要访问的服务器主机名或IP地址。
- Connection:Keep-Alive,告诉服务器在完成本次请求的响应后,保持该TCP连接不释放,等待本次连接的后续请求。这样可以减少打开关闭TCP连接的次数,提升处理性能。另外可选的选项是Close,表明直接响应接收完成后直接将其关闭
- Referer:指定发起该请求的源地址。根据这一值服务器可以跟踪到来访者的基本信息。
- 将客户端的Cookie信息发送给服务器端。
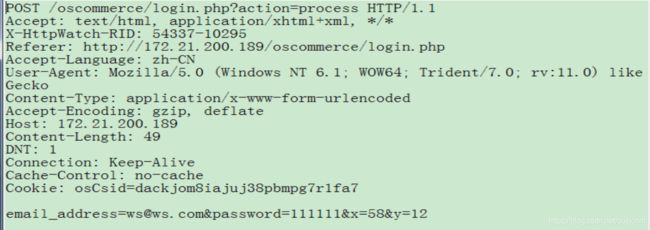
(5)POST请求详解
POST请求主要是数据的提交
(6)GET和POST请求区别
get和post两种基本请求方法的区别
-
GET把参数包含在URL中,POST通过request body传递参数。
-
HTTP-GET的处理特征如下:
- 将参数添加到URL
- 利用一个问号(”?”)代表URL地址的结尾与数据的开端。
- 每一个数据的元素以 名称/值 (name/value) 的形式出现。
- 利用一个分号(“&”)来区分多个数据元素

(7)HTTP响应
- 响应:Response,由服务器端返回给客户端
- 响应包含 正常的响应 和 异常的响应。
- HTTP协议通过响应的状态码来进行定义:1xx, 2xx, 3xx(正常), 4xx, 5xx(异常)
- 参考文档: HTTP响应状态码

(8)session、cookie、token



三.常用接口分析工具
1.常见的协议分析工具

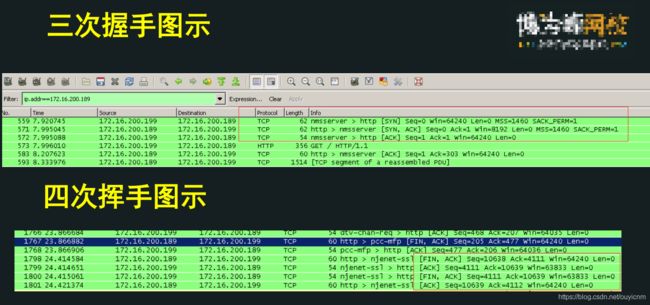
2.tcpdump + wireshark工具
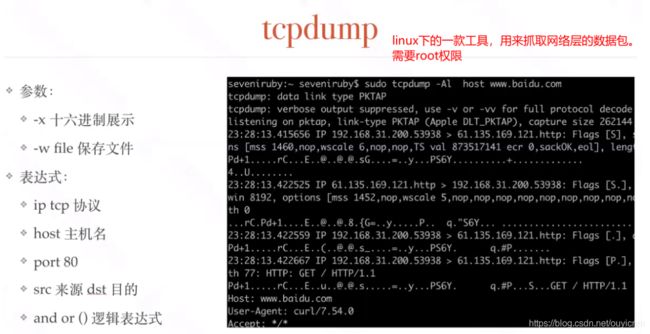
(1)tcpdump工具
tcpdump 主要用来抓取传输层的协议

实战:
第一步:打开一个linux终端,输入命令启动tcpdump,开始监听网络:
sudo tcpdump host www.baidu.com -w /tmp/tcpdump.cap
# host www.baidu.com--指定监听端口
# -w 指定输出文件路径,一般输出为cap文件

第二步:打开另一个终端使用curl访问:www.baidu.com
curl http://www.baidu.com
第三步:关闭tcpdump(CTRL+c),导出日志,使用wireshark打开

(2)wireshark工具
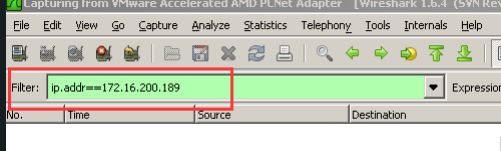
过滤规则:
- 过滤源ip、目的ip
- 查找目的地址为:ip.dst==192.168.101.8;
- 查找源地址为:ip.src==1.1.1.1;
- 过滤80端口
- tcp.port==80
- 过滤目的端口为80:tcp.dstport==80
- 过滤源端口为80:tcp.srcport==80
- 协议过滤
- 直接输入:http
- http模式过滤
- 过滤get包,http.request.method==“GET”
- 过滤post包,http.request.method==“POST”
- and连接符

Wireshark数据与对应的协议层

- Frame: 物理层的数据帧概况
- Ethernet II: 数据链路层以太网帧头部信息
- Internet Protocol Version 4: 互联网层IP包头部信息
- Transmission Control Protocol: 传输层的数据段头部信息,此处是TCP
- Hypertext Transfer Protocol: 应用层的信息,此处是HTTP协议
总结:在抓取底层协议时,往往使用tcpdump工具来抓取数据包,使用wireshark工具来分析数据。
3.postman工具使用
(1)postman介绍
• Postman是一款功能强大的网页调试与发送网页HTTP请求的软件。
• 可以很方便的模拟get或者post或者其他方式的请求来调试接口。
(2)安装
地址:https://www.postman.com/downloads/
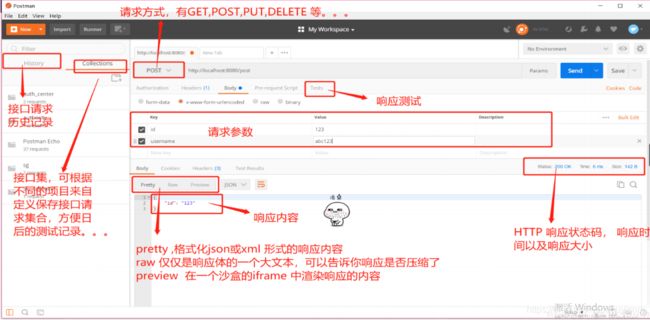
(3)postman界面介绍
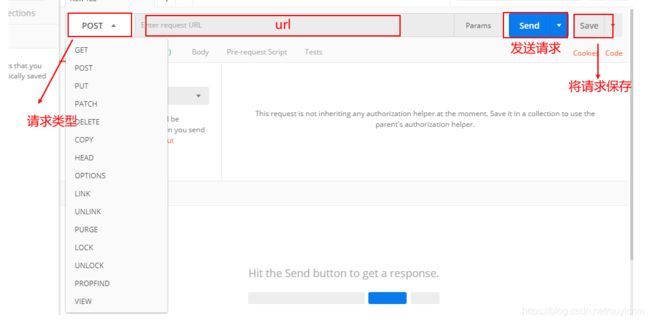


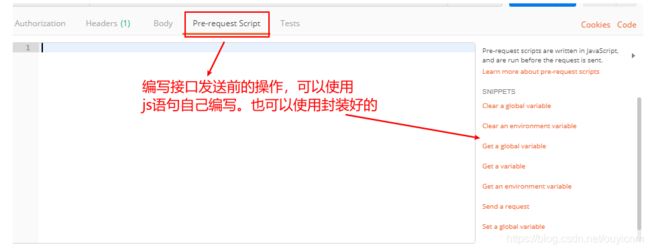

(4)发送get请求
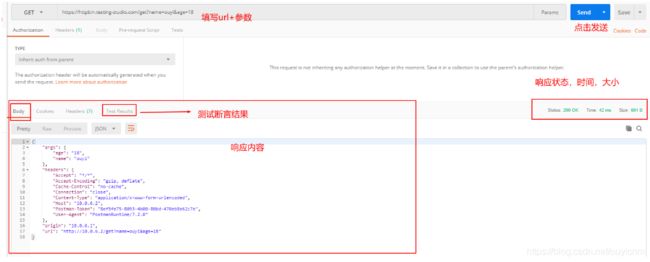
(5)post请求
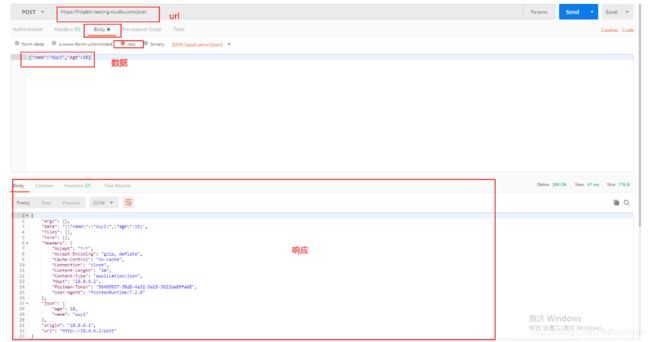
(6)post请求传输文件
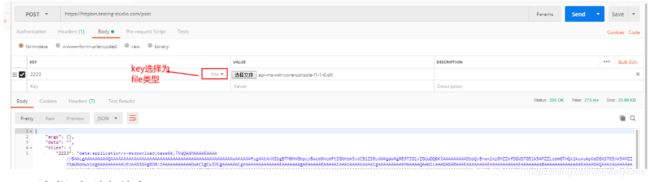
(7)请求添加头部信息
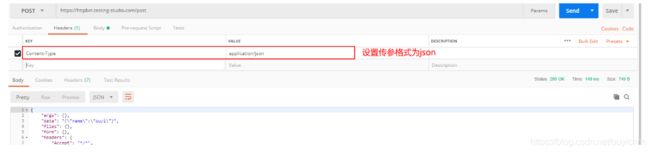
(8)请求中添加断言
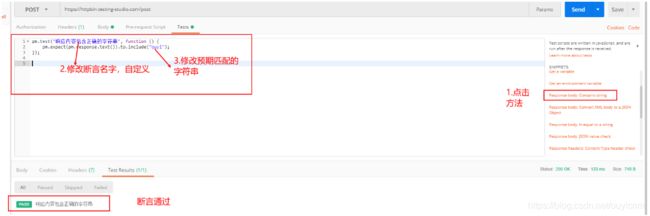
postman自带的常用断言方法:
-
1.检测返回的结果包含字段

-
2.检测返回的内容等于字段

-
3.检测响应状态码为200

-
4.检测响应内容的某个key的value值是否是某字段
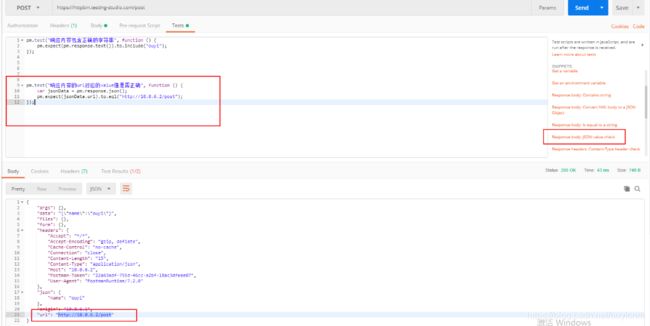
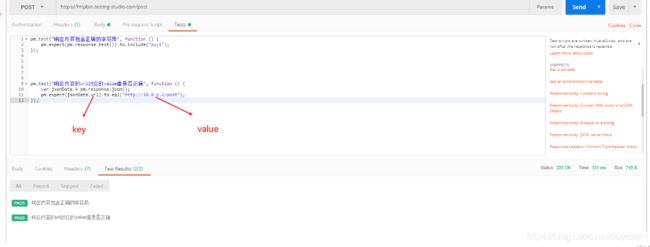
-
5.检测响应的头部信息是否包含某个key
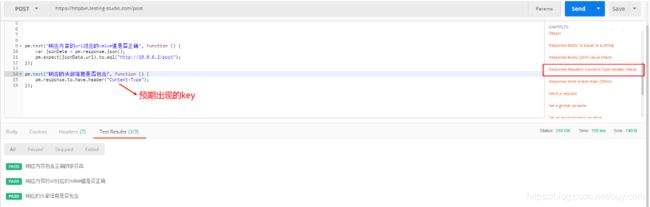
-
6.检测响应时间小于某个值
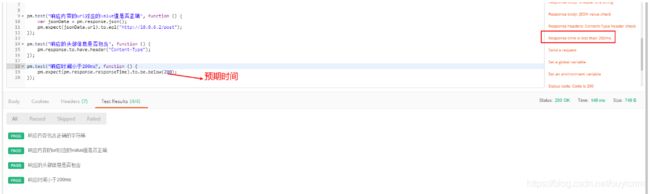
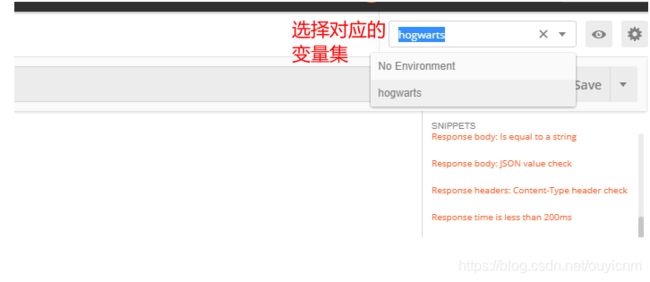
(9)变量的使用

变量的使用场景:
我们在用postman做接口测试时,不同的请求url前面基本上都是一样的。这时我们可以使用变量来代替它
实战:
(1)设置中添加变量

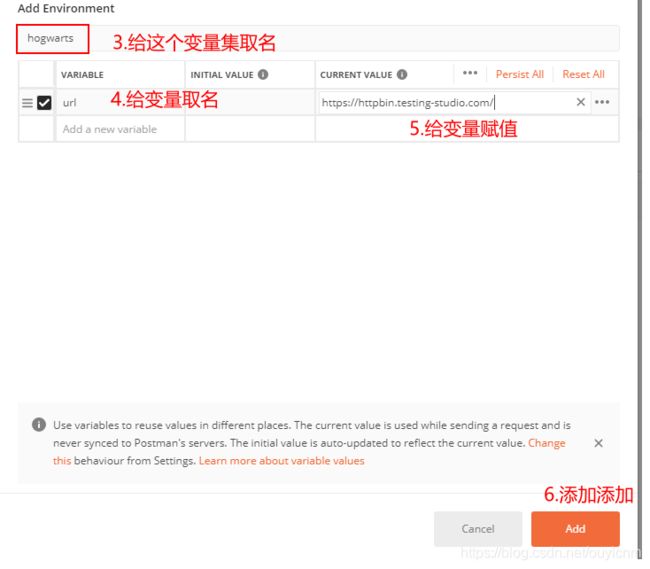

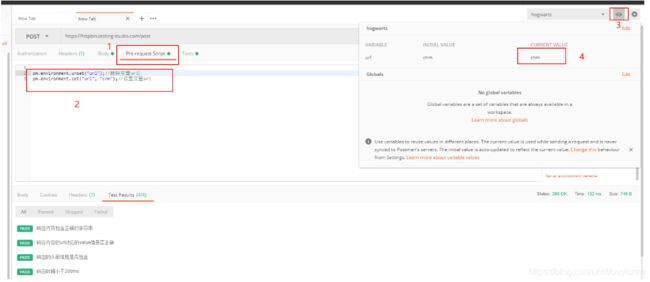
(2)前置脚本中使用变量
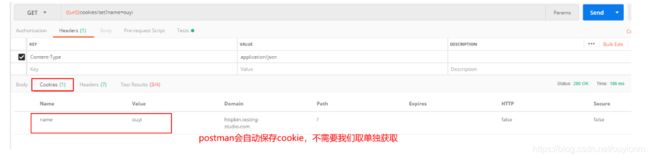
(10)使用cookie

(11)参数的传递

实战:获取token,并在其他接口使用(绕过登录)
获取token
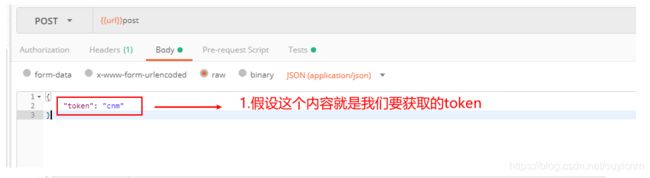

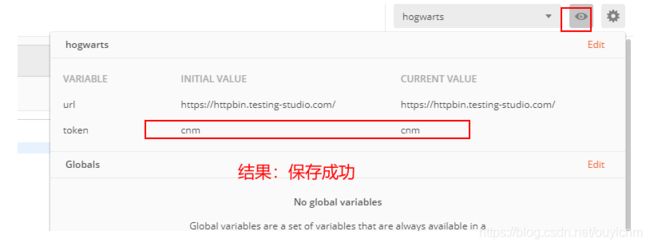
其他接口使用token
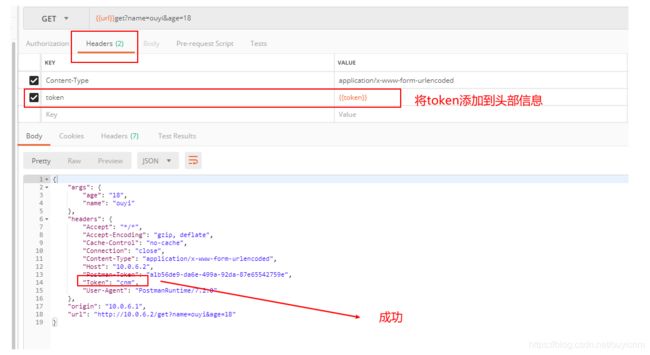
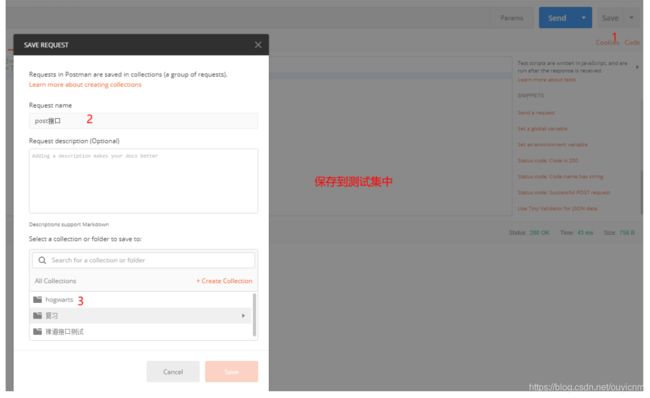
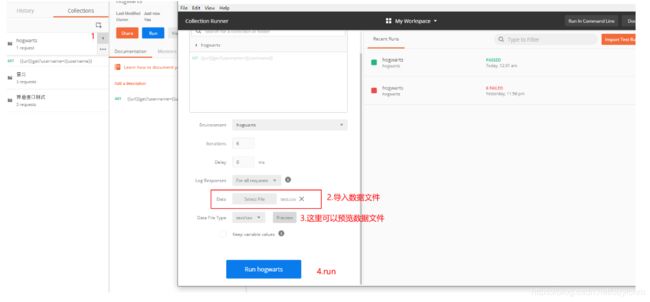
(12)测试集的使用
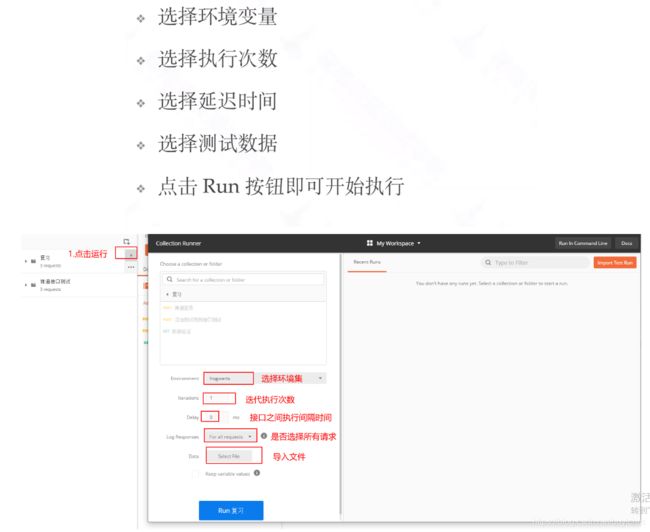
测试集实战:
添加一个get请求,一个post请求到测试集。并使用数据驱动
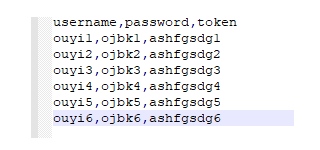
第一:准备测试数据(数据驱动)
-
json

-
csv
第二步:新建测试集
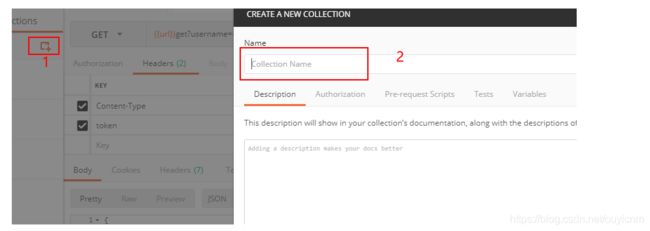
第三步:编写接口并添加到测试集
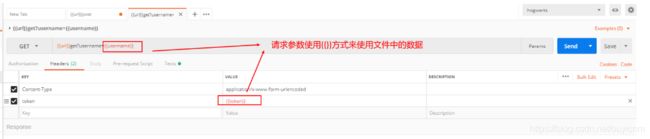
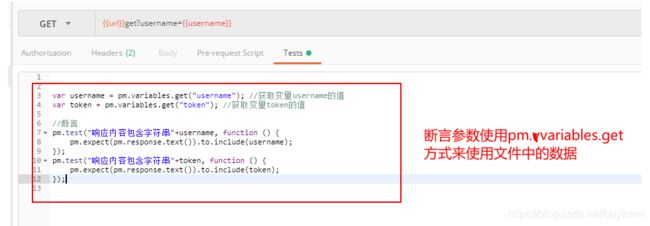
第四步:执行测试集
4.curl工具
(1)介绍
curl是一款经常被使用的http请求分析工具
(2)使用


实战:
- 基本用法
# curl http://www.linux.com
执行后,www.linux.com 的html就会显示在屏幕上了
Ps:由于安装linux的时候很多时候是没有安装桌面的,也意味着没有浏览器,因此这个方法也经常用于测试一台服务器是否可以到达一个网站
- 保存访问的网页
- 使用linux的重定向功能保存
# curl http://www.linux.com >> linux.html
- 可以使用curl的内置option:-o(小写)保存网页
$ curl -o linux.html http://www.linux.com
执行完成后会显示如下界面,显示100%则表示保存成功
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 79684 0 79684 0 0 3437k 0 --:--:-- --:--:-- --:--:-- 7781k
- 可以使用curl的内置option:-O(大写)保存网页中的文件
要注意这里后面的url要具体到某个文件,不然抓不下来
# curl -O http://www.linux.com/hello.sh
- 测试网页返回值
# curl -o /dev/null -s -w %{http_code} www.linux.com
Ps:在脚本中,这是很常见的测试网站是否正常的用法
- 指定proxy服务器以及其端口
很多时候上网需要用到代理服务器(比如是使用代理服务器上网或者因为使用curl别人网站而被别人屏蔽IP地址的时候),幸运的是curl通过使用内置option:-x来支持设置代理
# curl -x 192.168.100.100:1080 http://www.linux.com
- cookie
有些网站是使用cookie来记录session信息。对于chrome这样的浏览器,可以轻易处理cookie信息,但在curl中只要增加相关参数也是可以很容易的处理cookie
- 保存http的response里面的cookie信息。内置option:-c(小写)
# curl -c cookiec.txt http://www.linux.com
执行后cookie信息就被存到了cookiec.txt里面了
- 保存http的response里面的header信息。内置option: -D
# curl -D cookied.txt http://www.linux.com
执行后cookie信息就被存到了cookied.txt里面了
注意:-c(小写)产生的cookie和-D里面的cookie是不一样的。
- 使用cookie
很多网站都是通过监视你的cookie信息来判断你是否按规矩访问他们的网站的,因此我们需要使用保存的cookie信息。内置option: -b
# curl -b cookiec.txt http://www.linux.com
6、模仿浏览器
有些网站需要使用特定的浏览器去访问他们,有些还需要使用某些特定的版本。curl内置option:-A可以让我们指定浏览器去访问网站
# curl -A "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.0)" http://www.linux.com
这样服务器端就会认为是使用IE8.0去访问的
7、伪造referer(盗链)
很多服务器会检查http访问的referer从而来控制访问。比如:你是先访问首页,然后再访问首页中的邮箱页面,这里访问邮箱的referer地址就是访问首页成功后的页面地址,如果服务器发现对邮箱页面访问的referer地址不是首页的地址,就断定那是个盗连了
curl中内置option:-e可以让我们设定referer
# curl -e "www.linux.com" http://mail.linux.com
这样就会让服务器其以为你是从www.linux.com点击某个链接过来的
8、下载文件
8.1:利用curl下载文件。
#使用内置option:-o(小写)
# curl -o dodo1.jpg http:www.linux.com/dodo1.JPG
#使用内置option:-O(大写)
# curl -O http://www.linux.com/dodo1.JPG
这样就会以服务器上的名称保存文件到本地
8.2:循环下载
有时候下载图片可以能是前面的部分名称是一样的,就最后的尾椎名不一样
# curl -O http://www.linux.com/dodo[1-5].JPG
这样就会把dodo1,dodo2,dodo3,dodo4,dodo5全部保存下来
8.3:下载重命名
# curl -O http://www.linux.com/{hello,bb}/dodo[1-5].JPG
由于下载的hello与bb中的文件名都是dodo1,dodo2,dodo3,dodo4,dodo5。因此第二次下载的会把第一次下载的覆盖,这样就需要对文件进行重命名。
# curl -o #1_#2.JPG http://www.linux.com/{hello,bb}/dodo[1-5].JPG
这样在hello/dodo1.JPG的文件下载下来就会变成hello_dodo1.JPG,其他文件依此类推,从而有效的避免了文件被覆盖
8.4:分块下载
有时候下载的东西会比较大,这个时候我们可以分段下载。使用内置option:-r
# curl -r 0-100 -o dodo1_part1.JPG http://www.linux.com/dodo1.JPG
# curl -r 100-200 -o dodo1_part2.JPG http://www.linux.com/dodo1.JPG
# curl -r 200- -o dodo1_part3.JPG http://www.linux.com/dodo1.JPG
# cat dodo1_part* > dodo1.JPG
这样就可以查看dodo1.JPG的内容了
8.5:通过ftp下载文件
curl可以通过ftp下载文件,curl提供两种从ftp中下载的语法
# curl -O -u 用户名:密码 ftp://www.linux.com/dodo1.JPG
# curl -O ftp://用户名:密码@www.linux.com/dodo1.JPG
8.6:显示下载进度条
# curl -# -O http://www.linux.com/dodo1.JPG
8.7:不会显示下载进度信息
# curl -s -O http://www.linux.com/dodo1.JPG
9、断点续传
在windows中,我们可以使用迅雷这样的软件进行断点续传。curl可以通过内置option:-C同样可以达到相同的效果
如果在下载dodo1.JPG的过程中突然掉线了,可以使用以下的方式续传
# curl -C -O http://www.linux.com/dodo1.JPG
10、上传文件
curl不仅仅可以下载文件,还可以上传文件。通过内置option:-T来实现
# curl -T dodo1.JPG -u 用户名:密码 ftp://www.linux.com/img/
这样就向ftp服务器上传了文件dodo1.JPG
11、显示抓取错误
# curl -f http://www.linux.com/error
5.charles工具
(1)常见的代理工具


(2)charles介绍
charles是什么??

charles工作原理
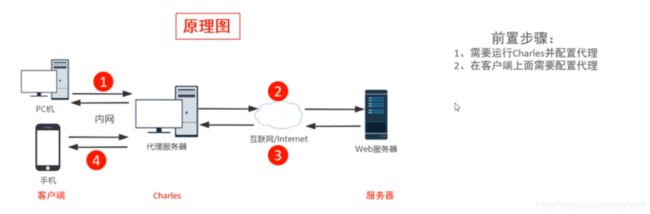
charles能做什么??

charles优点

(3)使用charles工具目标

(4)charles安装
下载地址:https://www.charlesproxy.com/download/

(5)charles组件介绍
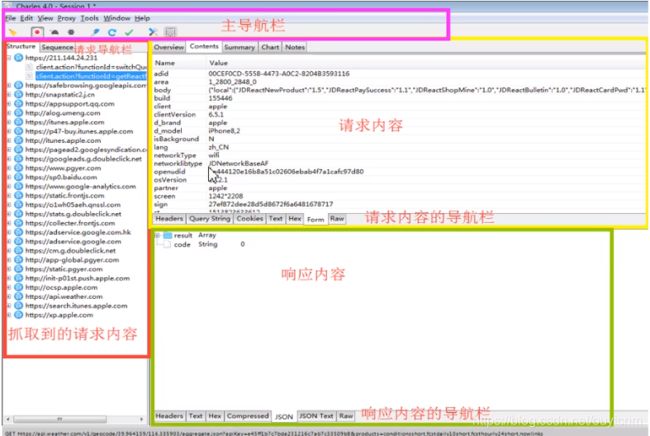
主导航栏介绍

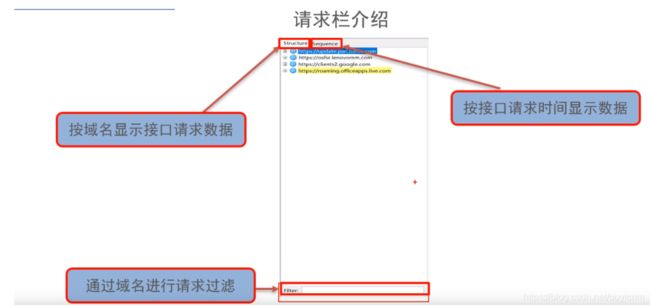
请求栏介绍
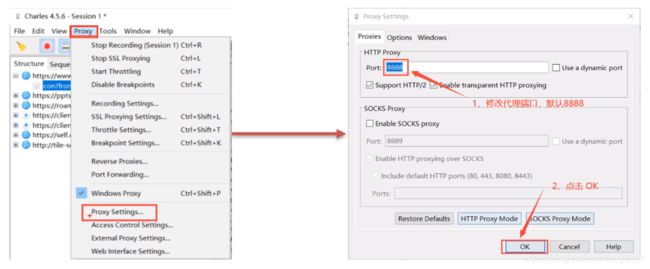
(6)charles设置为代理服务器
(7)charles访问控制

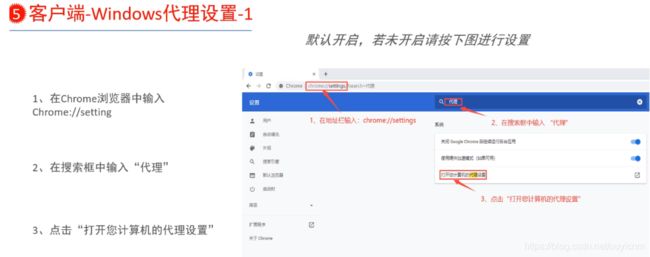
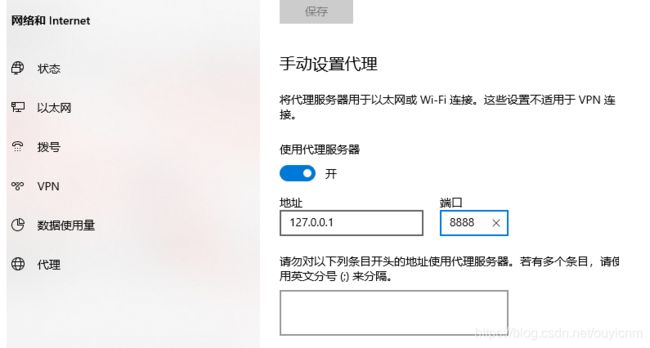
(8)客户端设置代理
windows
android端

(9)charles抓包实战
实战1:
问题

步骤:
分析:

(10)charles抓取https包
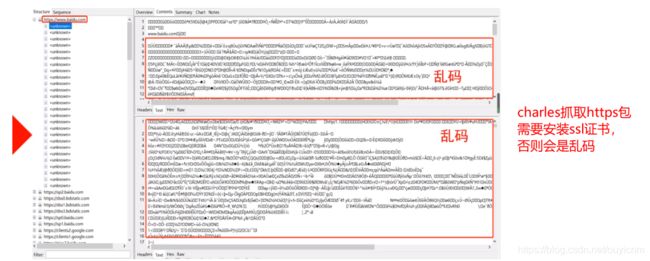
安装ssl证书
windows

android
第一步:打开charles
第二步:设置android为charles代理
第三步:在手机浏览器中访问网址:http://charlesproxy.com/getssl
第四步:


在设置手机密码即可。如果模拟器设置ssl证书后,charles还是无法或取https包。可以将模拟器开关飞行模式几次
charles中配置https代理
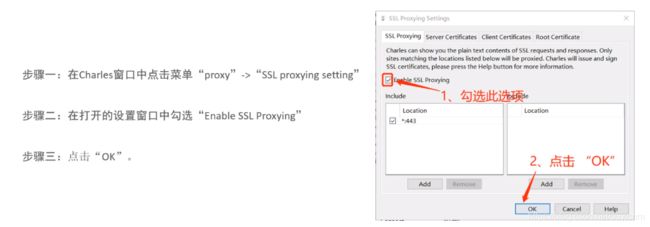
*:443------表示任意请求
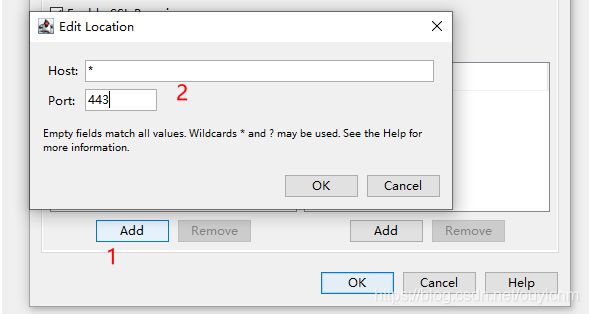
(11)网络配置

(12)断点设置

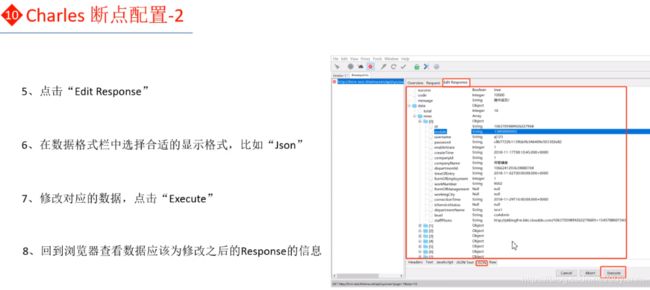
断点实战

实战1:
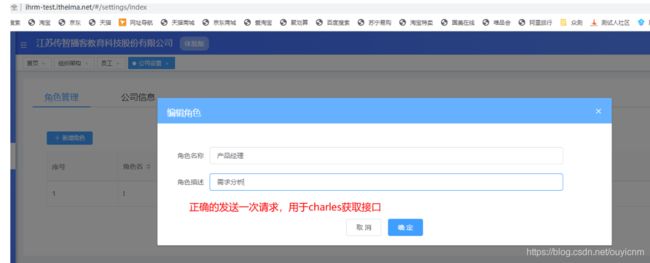
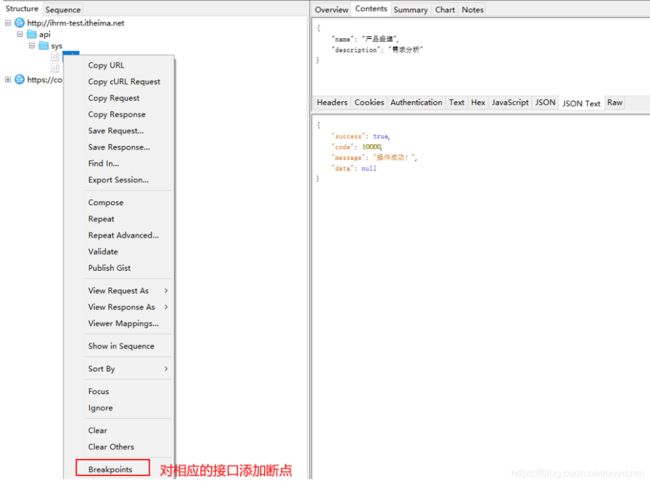
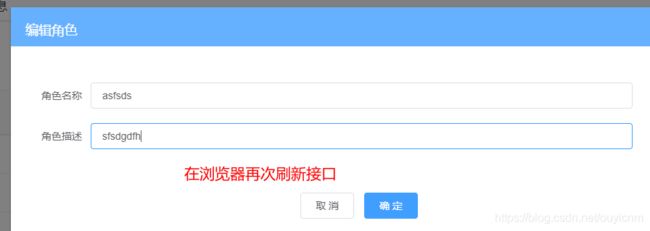

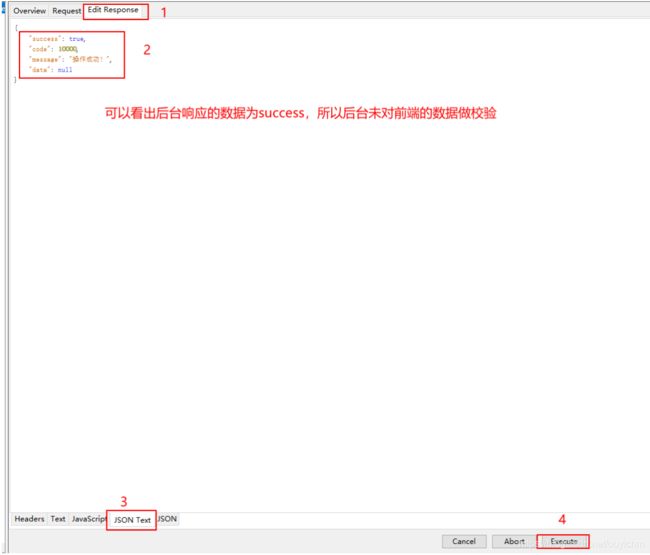
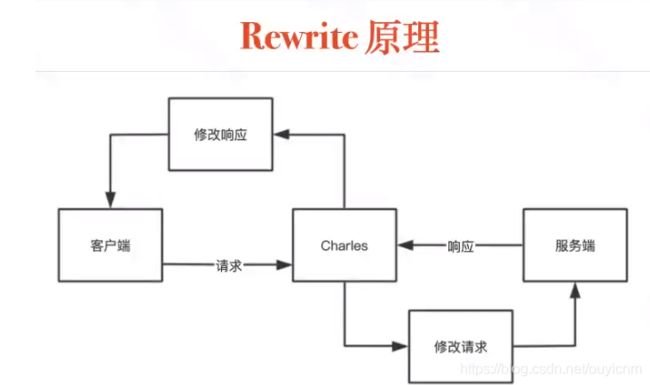
(13)Rewrite功能
断点可以修改单个请求的某种内容,Rewrite可以按照某种正则规则修改某种类型的所有接口请求内容
使用
第一步:Charles 点击Tools > Rewrite
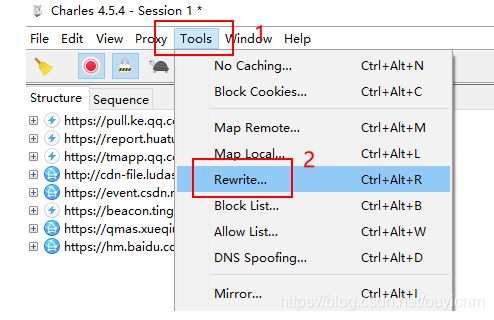
第二步:出来窗口,勾选Enable rewrite,点击Add

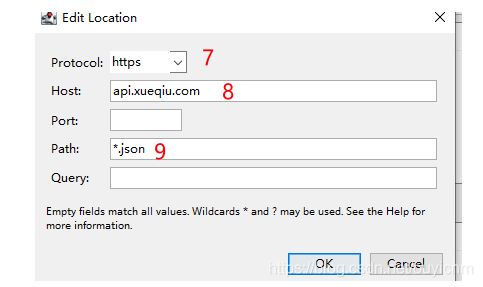
第三步:设置需要rewrite的接口类型

第四步:Rules 点击Add,添加我们要修改的参数:
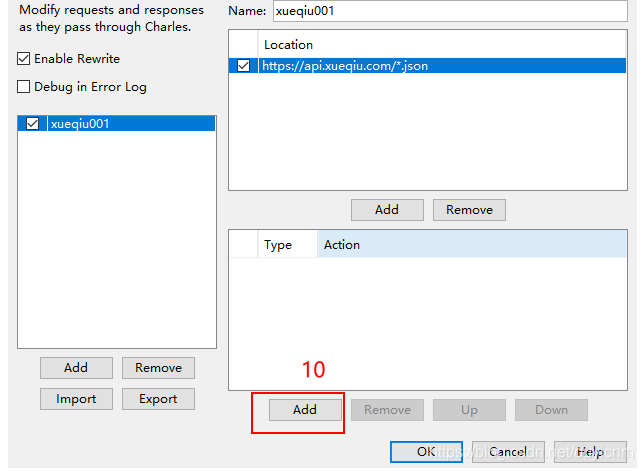
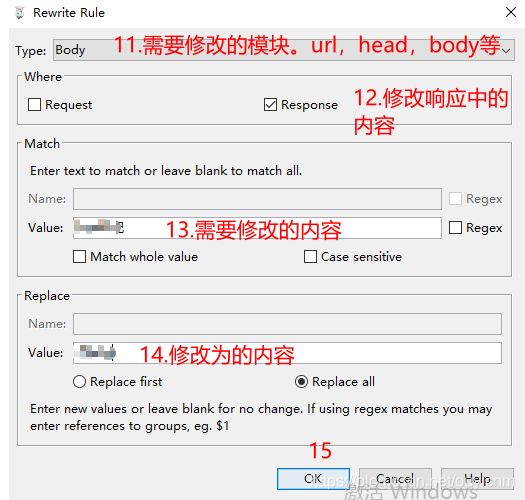
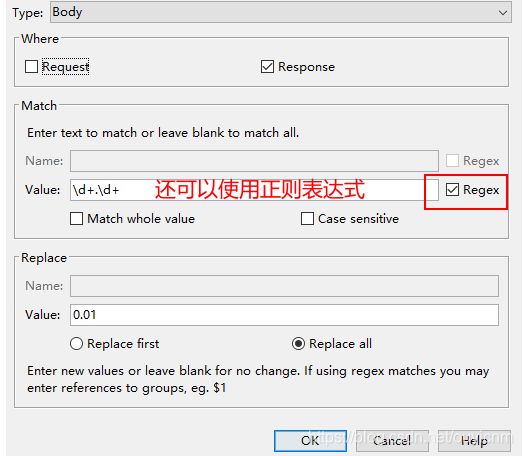


这样我们再访问客户端时,当出现匹配的请求时,就会按照我们的规则进行数据修改
(14)charles的map local功能
(1)介绍
跟rewrite一样map local也可以修改请求的响应数据。不过map local是将本地的文件映射给浏览器。
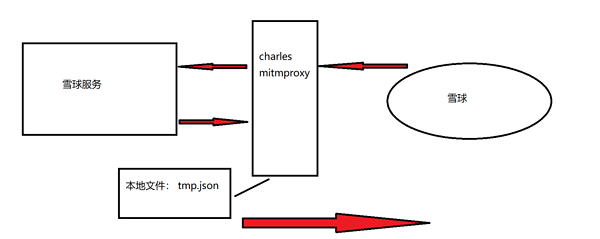
(2)使用
举例:将雪球app的页面中的“百度”和最新价分别修改为“xxx”和“9999”
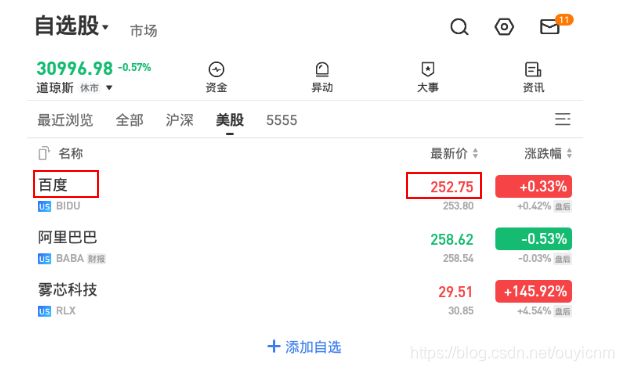
实现:
第一步:配置好charles及其代理后,抓取该页面的正常数据。

第二步:将响应内容写入本地文件,并且将数据修改为想要修改的内容

第三步:在charles中添加map local
在对应的请求连接右键,选择 maplocal ,选择本地文件(或者打开 tools , 点击 maplocal)
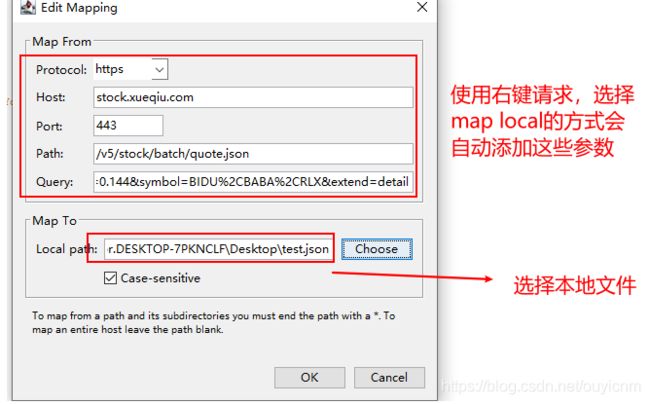
第四步:客户端再次访问url
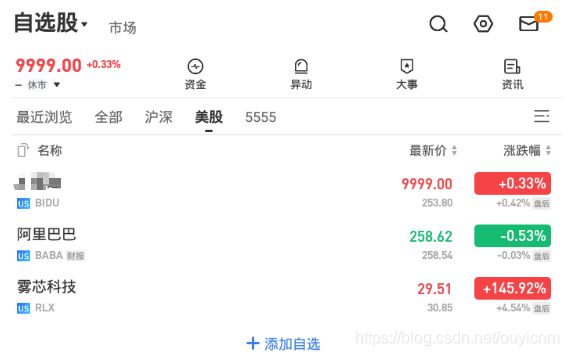
(15)charles反向代理
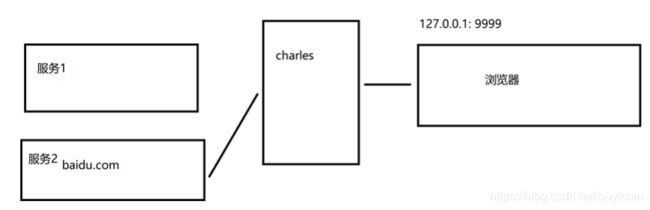
(1)正向代理和反向代理
正向代理:是代理客户端,为客户端收发请求,使真实客户端对服务器不可见;在客户这一端的,替客户收发请求(类似现在正常使用的charles的功能)
反向代理:是代理服务器,为服务器收发请求,使真实服务器对客户端不可见;在服务器这端的,替服务器收发请求,应用场景常见是就是请求分发到多台服务器的负载均衡应用。
charles的反向代理就是,将本地的一个端口映射到另一个服务端。当我们在客户端访问本地的这个被反向代理的端口时,实际上是访问另一个服务端
(2)charles反向代理
第一步:打开 charles 的 Proxy , 点击 reverse prxies,再点击add添加一个反向代理
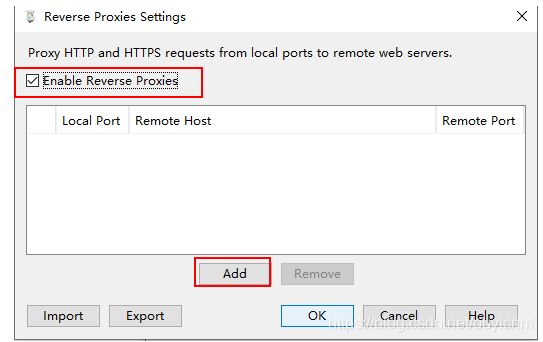
第二步:添加反向代理
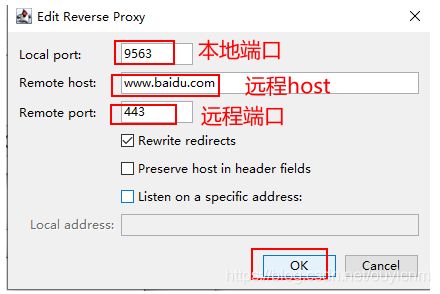
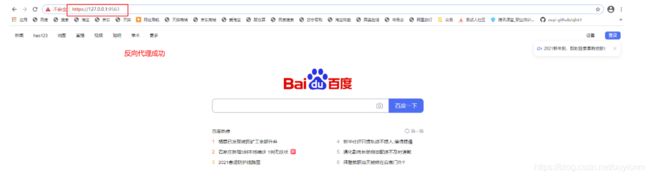
第三步:访问本地端口
6.mitmproxy工具
(1)mitmproxy 是什么
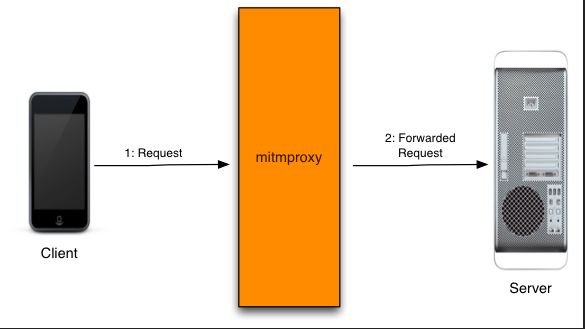
不同于charles, fiddler 或 wireshark 等抓包工具,mitmproxy 不仅可以截获请求帮助开发者查看、分析,更可以通过自定义脚本进行二次开发。举例来说,利用 fiddler 可以过滤出浏览器对某个特定 url 的请求,并查看、分析其数据,但实现不了高度定制化的需求,类似于:“截获对浏览器对该 url 的请求,将返回内容置空,并将真实的返回内容存到某个数据库,出现异常时发出邮件通知”。而对于 mitmproxy,这样的需求可以通过载入自定义 python 脚本轻松实现。
(2)mitmproxy 的分类
- mitmproxy:交互式工具(不支持 windows ),这里不讲
- mitmweb: web UI 代理工具(可视化,功能少),使用charles更方便。这里不讲
3. mitmdump: 可扩展的无 UI 代理工具(扩展功能强,可人为写插件增强),推荐使用
(3)安装
pip install mitmproxy
(4)使用
1.安装证书
通过mitmdump获取HTTPS协议,也需要安装证书
第一步:cmd命令行启动mitmdump
mitmdump
第二步:安装证书
在电脑浏览器或者手机浏览器上访问:http://mitm.it/。下载安装证书
2.基本使用
- 基本使用
mitmdump #开启mitmdump

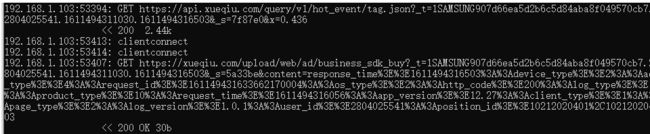
日志只有最基本的请求方式,url,返回状态等信息
- 设置日志级别
mitmdump --flow-detail 3 # 设置日志级别为3.总共分为0-3,3是日志最详细的级别
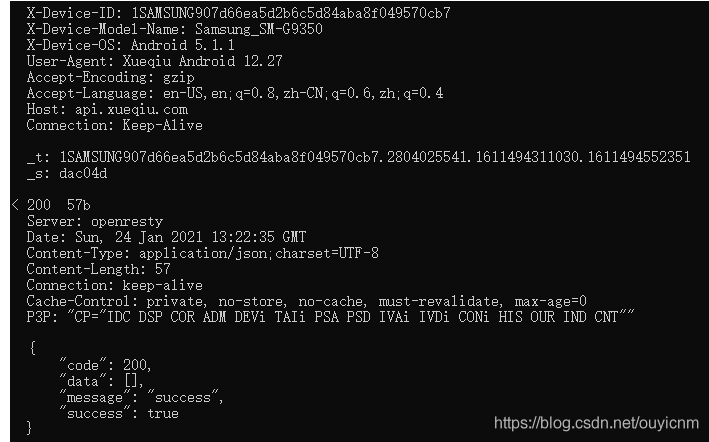
这个级别下的日志包含了body,head等所有内容
- 日志输出到文件中
mitmdump --flow-detail 3 -w C:\CS\test.txt
- 自定义监听端口
mitmdump --flow-detail 3 -p 55963
![]()
mitmdump还有许多参数,可以查看官方文档下(https://docs.mitmproxy.org/stable/)的options研究
3.脚本扩展
mitmdump可以使用脚本进行扩展,这也是我们主要使用mitmdump的地方
- 使用步骤
第一步:编写脚本
from mitmproxy import ctx
class Counter:
def __init__(self):
self.num = 0
# request是mitmproxy的内置事件,通过mitmproxy的每一次请求都会访问。//flow表示数据流
def request(self, flow):
self.num = self.num + 1
ctx.log.info("We've seen %d flows" % self.num)
# 将创建的类加入到mitmproxy的addons中
addons = [
Counter()
]
第二步:使用脚本扩展模式启动mitmdump
mitmdump --flow-detail 3 -s C:\mitmdump_script.py # -s 指定脚本路径

-
mitmdump的常见事件
请求拦截函数名:
def request(flow):
pass
响应拦截:
def responset(flow):
// flow 表示数据流
pass
更多事件可以参考官方文档下(https://docs.mitmproxy.org/stable/)的events研究
- 实战
(1)将https://www.baidu.com的响应改为字符串(盗版百度)
from mitmproxy import http
class ABC:
def __init__(self):
self.num = 0
def request(self, flow: http.HTTPFlow) -> None:
if "baidu" in flow.request.pretty_url and 'from=' in flow.request.url: # 筛选出baidu的url
flow.response = http.HTTPResponse.make(
200, # (optional) status code # 返回状态码 int
"盗版百度", # (optional) content # 内容 str或者字节流
# {"Content-Type": "application/json"} # (optional) headers # 头部信息
)
addons = [
ABC()
]

(2)使用mitmdump实现map local(将雪球app的行情页响应数据修改为指定文件中的数据)
from mitmproxy import http
class ABC:
def __init__(self):
self.num = 0
def request(self, flow: http.HTTPFlow) -> None:
if "quote.json" in flow.request.pretty_url:
with open(r"C:\Users\Administrator.DESKTOP-7PKNCLF\Desktop\test.json", 'r', encoding="utf-8") as f:
flow.response = http.HTTPResponse.make(
200, # (optional) status code
f.read(), # (optional) content
{
"Content-Type": "application/json"} # (optional) headers
)
addons = [
ABC()
]

(5)mitmdump总结
mitmdump更多是使用他的脚本扩展功能,实现自动化的mock(修改接口数据)的功能
7.抓包工具的总结
- charles,fillder等代理工具是用于抓取应用层http协议的包
- tcpdump + wireshark工具是用于抓取传输层TCP协议的包(3次握手,4次挥手)
- postman,curl是用于模拟get或者post或者其他方式的请求来调试接口。
- mitmproxy工具主要用来在代码中自动处理请求数据。
四.mock测试技术
(1)什么是mock
mock 的意思是模拟,也就是模拟接口返回的信息,用已有的信息替换它需要返回的信息,从实现对上级模块的测试。
这里分为两类测试:一类是前端对接口的mock,一类是后端单元测试中涉及的mock
单纯的前端mock可以通过抓包工具Fiddler,Charles实现,通过修改代理返回的数据,实现多种场景的测试。这里在抓包工具之中会解释。
后端的Mock则是从接口的角度,如果一个接口A返回的数据需要依赖于另一个接口B,当敏捷开发中B接口还未开发完全时候这里会需要用到Mock。
(2)怎么使用mock
- 根据协议选择工具
- 应用层 charles , mitmproxy :http,https (网络数据传输:打开网页), websocket(通信:微信聊天)
- socket mitmproxy pysocket:粘贴剂(不属于层,是一个把理论变为现实的工具,让人们去调用)
- 传输层 mitmproxy :tcp(可靠传输),udp(不可靠)
- 传输层之下:不要测
2.根据工具构造数据,进行mock测试