Python爬虫——抖音排行榜
最近公司准备搞个抖音号,叫我们爬一下抖音的排行榜,记录一下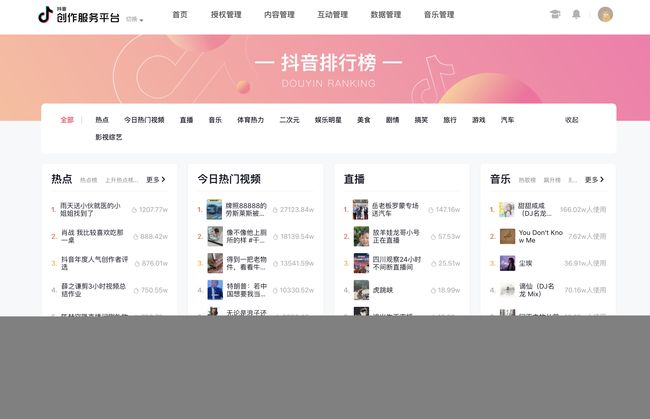
链接在这里
选择二次元榜单,打开network,很快就可以找到数据存放的位置
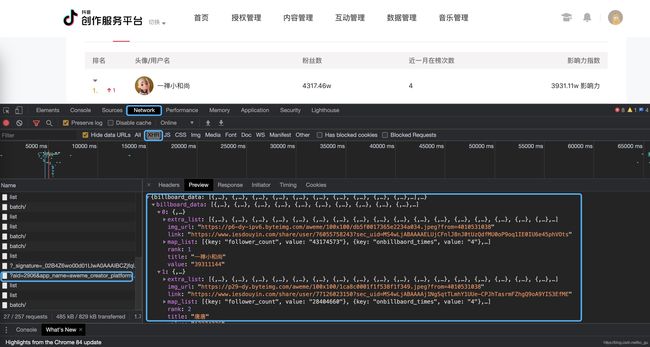
简单分析一下可知,不同榜单的URL区别主要在于“billboard_type=”这个参数,这里需要一个一个确定一下,二次元的几个榜单的话是从61到68;还有得到的数据是json格式,接下来就可以写代码啦。对了,header还是要伪装一下的哈,主要是user-agent和cookie。其他保存自己需要的数据即可
from bs4 import BeautifulSoup
import requests
import os
import json
from datetime import datetime
import pandas as pd
import time
def get_links(linkid):
url = 'https://creator.douyin.com/aweme/v1/creator/data/billboard/?billboard_type={}'.format(linkid)
headers = {
"user-agent":'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36',
"referer": "https://creator.douyin.com/billboard/cospa",
'cookie':'XXX'#填写自己的cookie即可
}
res = requests.get(url,headers=headers)
jd=json.loads(res.text)['billboard_data']
newsdetails=[]
for ent in jd :
newsdetails.append(get_detail(ent,linkid))
return newsdetails
def get_detail(jd,linkid):
result={
}
result['标题']=jd['title']#标题
result['影响力']=str(int(jd['value'])/10000)+'w'#影响力
result['排名']=jd['rank']#排名
result['粉丝数']=str(int(jd['map_list'][0]['value'])/10000)+'w'#粉丝数
result['近一月上榜次数']=jd['map_list'][1]['value']#近一月上榜次数
result['上周排名']=jd['map_list'][2]['value']#上周排名
result['分类']=linkid#分类
result['链接']=jd['link']#链接
now = datetime.now().strftime('%Y-%m-%d')
result['时间']=now
return result
def main():
news_total = []
for i in range(61,68):
news_total.extend(get_links(i))
df = pd.DataFrame(news_total)
now = datetime.now().strftime('%m%d_%H%M%S')
newsname = 'dy'+now+'.xlsx'
df.to_excel(newsname)
if __name__ == '__main__':
main()