最新hadoop集群搭建(2020)
hadoop集群搭建
- 一、机器准备
- 二、安装JDK
- 三、配置ssh免密码登录
- 四、建立主机名和ip的映射
- 五、 安装配置hadoop
-
- 1. 将hadoop安装包解压到/opt/module下并配置环境变量
- 2. 配置/opt/module/hadoop-2.7.2/etc/hadoop下的core-site.xml
- 3. 配置/opt/module/hadoop-2.7.2/etc/hadoop下的hdfs-site.xml
- 4. 配置/opt/module/hadoop-2.7.2/etc/hadoop下的yarn-site.xml
- 5. 配置/opt/module/hadoop-2.7.2/etc/hadoop下的mapreduce-site.xml
- 6.格式化Namenode
- 测试集群
- 群起集群
- 历史日志查看
一、机器准备
这里我们准备采用的集群模式如下:
DN:datanode
NN:namenode
NM:nodemanager
RM:resourcemanager
2NN:secondarynamenode
hadoop1 hadoop2 hadoop3
DN DN DN
NM NM NM
NN RM 2NN
准备三台机器(您可以安装一台机器后克隆出其他两台机器,修改ip,主机名),,这里我用virtualBox搭建了三台虚拟机,
每台虚拟机分配了4G内存,50G的硬盘空 间,这里我分配的空间大一点主要是为了后面计算时有充足的空间,不然还
得增加硬盘及内存。 所以你得机器内存至少16G以上。
注意:每台机器防火墙要关闭;三台机器可以互相访问;
二、安装JDK
下载安装java1.8:
tar -zxvf jdk1.8.0_161.tar.gz(使用自己的压缩文件名)
配置环境jdk环境:/etc/profile
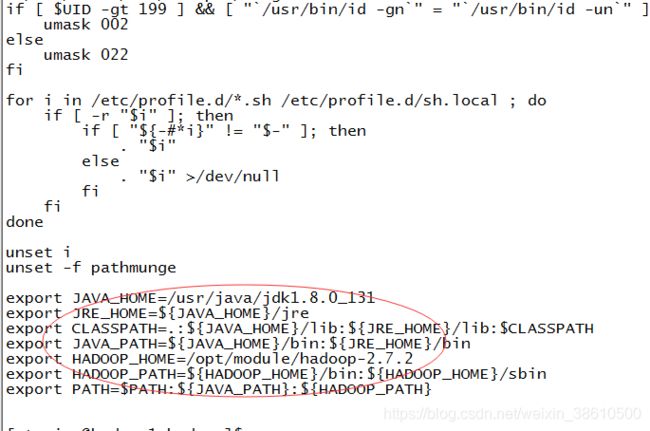
编辑完成后:source /etc/profile

三、配置ssh免密码登录
在hadoop1机器root用户下输入ssh-keygen -t rsa 一路回车(如果用的是其他用户组,需要在该用户组下操作)

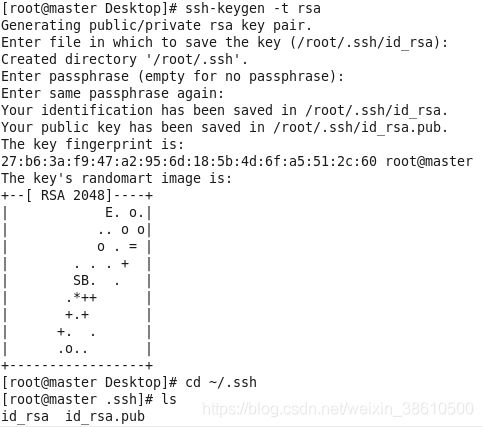
秘钥生成后在~/.ssh/目录下,有两个文件id_rsa(私钥)和id_rsa.pub(公钥),将公钥复制到authorized_keys
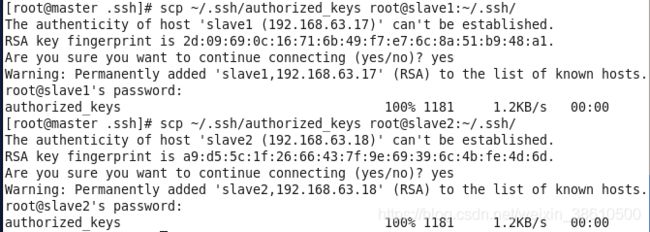
同理在hadoop2和hadoop3节点上进行相同的操作,然后将公钥复制到master节点上的authoized_keys
再将hadoop1节点上的authoized_keys远程传输到hadoop2和hadoop3的~/.ssh/目录下
scp ~/.ssh/authorized_keys root@hadoop2: ~/.ssh/
四、建立主机名和ip的映射

五、 安装配置hadoop
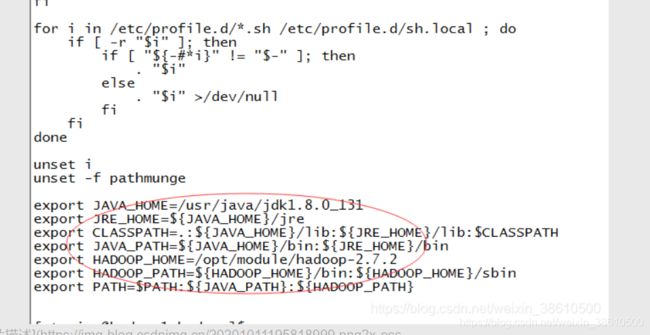
1. 将hadoop安装包解压到/opt/module下并配置环境变量

在etc/profile增加hadoop路径:
2. 配置/opt/module/hadoop-2.7.2/etc/hadoop下的core-site.xml
hadoop1:
[atguigu@hadoop1 hadoop]$ cat core-site.xml
fs.defaultFS
hdfs://hadoop1:9000
hadoop.tmp.dir
/opt/module/hadoop-2.7.2/data/tmp
hadoop2:
[atguigu@hadoop2 hadoop]$ cat core-site.xml
fs.defaultFS
hdfs://hadoop1:9000
hadoop.tmp.dir
/opt/module/hadoop-2.7.2/data/tmp
hadoop3:
[atguigu@hadoop3 hadoop]$ cat core-site.xml
fs.defaultFS
hdfs://hadoop1:9000
hadoop.tmp.dir
/opt/module/hadoop-2.7.2/data/tmp
3. 配置/opt/module/hadoop-2.7.2/etc/hadoop下的hdfs-site.xml
hadoop1:
[atguigu@hadoop1 hadoop]$ cat hdfs-site.xml
dfs.namenode.secondary.http-address
hadoop3:50090
hadoop2:
[atguigu@hadoop2 hadoop]$ cat hdfs-site.xml
dfs.namenode.secondary.http-address
hadoop3:50090
hadoop3:
[atguigu@hadoop3 hadoop]$ cat hdfs-site.xml
dfs.namenode.secondary.http-address
hadoop3:50090
4. 配置/opt/module/hadoop-2.7.2/etc/hadoop下的yarn-site.xml
hadoop1:
[atguigu@hadoop1 hadoop]$ cat yarn-site.xml
yarn.resourcemanager.hostname
hadoop2
yarn.nodemanager.aux-services
mapreduce_shuffle
hadoop2:
[atguigu@hadoop2 hadoop]$ cat yarn-site.xml
yarn.resourcemanager.hostname
hadoop2
yarn.nodemanager.aux-services
mapreduce_shuffle
hadoop3:
[atguigu@hadoop3 hadoop]$ cat yarn-site.xml
yarn.resourcemanager.hostname
hadoop2
yarn.nodemanager.aux-services
mapreduce_shuffle
5. 配置/opt/module/hadoop-2.7.2/etc/hadoop下的mapreduce-site.xml
hadoop1\hadoop2\hadoop3相同:
[atguigu@hadoop1 hadoop]$ cat yarn-site.xml
mapreduce.framework.name
yarn
6.格式化Namenode
因为这里我们是配置的hadoop1为namenode,因此只需格式化hadoop1:
hadoop namenode -format
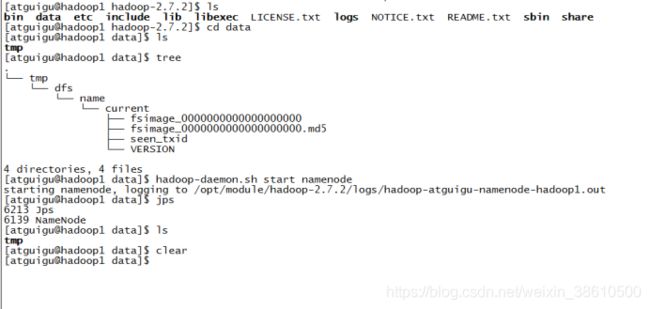
启动hadoop1上的namenode:
hadoop-daemon.sh start namenode
启动hadoop1\hadoop2\hadoop3的datanode:
hadoop-daemon.sh start datanode
启动hadoop3上的secondarynamenode
hadoop-daemon.sh start secondarynamenode
查看启动的进程:
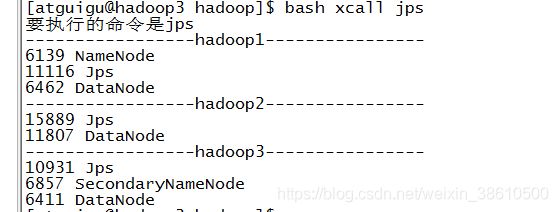
通过50070端口访问地址:

启动hadoop2上的resourcemanager:
yarn-daemon.sh start resourcemanager

查看所有进程是否已启:

测试集群
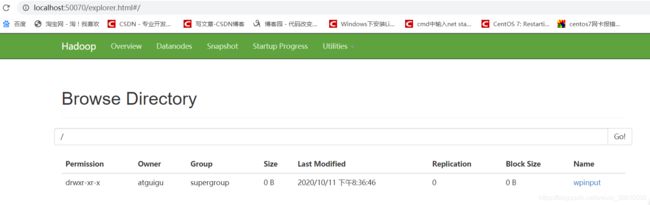
hadoop fs -mkdir /wpinput
查看文件夹是否生成到hdfs下:
上传文件到wpinput下:
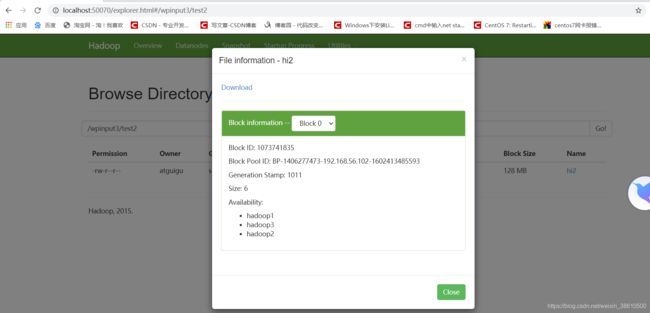
hadoop fs -put test2 /wpinput3
![]()
利用/opt/module/hadoop-2.7.2/share/hadoop/mapreduce下的hadoop-mapreduce-examples-2.7.2.jar 来统计wpinput2下所有文件的单词数:
hadoop jar hadoop-mapreduce-examples-2.7.2.jar wordcount /wpinput2/ /wpoutput3
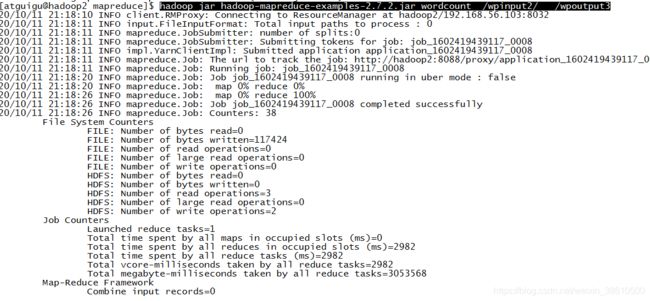
执行成功会在wpoutput3生成执行成功后的文件信息:

群起集群
上面我们是一台台机器上分别启动namenode、datanone、resourcemanager、nodemanager、secondarynamenone进程,
这里介绍群起命令:
首先修改/opt/module/hadoop-2.7.2/etc/hadoop下的salves文件,如下图写入三台机器的主机名,每个主机名占一行,主机名后不能有空格,且不能有空行:

编辑完成后保存,下面演示群起命令:
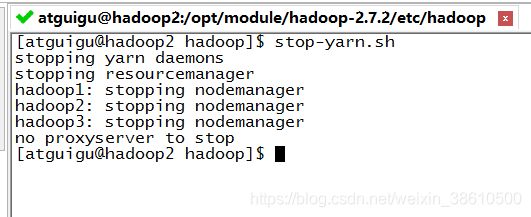
stop-yarn.sh 停止机器中所有yarn进程:
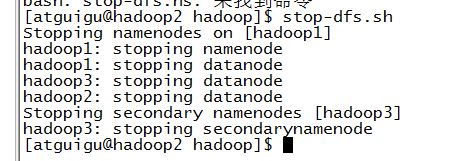
stop-dfs.sh 停止机器中所有dfs进程:
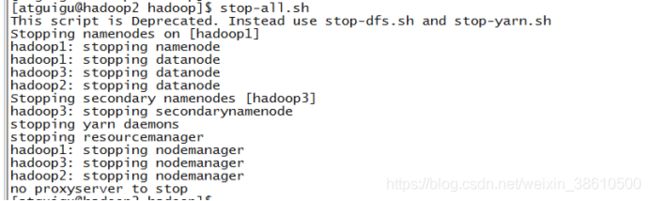
start-all.sh 群起所有进程:

stop-all.sh 群停所有进程:
这里注意一下:start-all.sh命令其实是分布调用了start-dfs.sh和start-yarn.sh
start-dfs.sh可以在任意一台机器中执行,
start-yarn.sh必须在RM所在机器使用,在其他机器不会启动RM进程
所以最好都在RM所在机器执行群起群停命令!
历史日志查看
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
-
配置mapred-site.xml
mapreduce.jobhistory.address hadoop1:10020 mapreduce.jobhistory.webapp.address hadoop1:19888 yarn.log.server.url http://hadoop1:19888/jobhistory/logs -
启动历史服务器
[atguigu@hadoop1 hadoop-2.7.2]$ sbin/mr-jobhistory-daemon.sh start historyserver -
查看历史服务器是否启动
[atguigu@hadoop1 hadoop-2.7.2]$ jps -
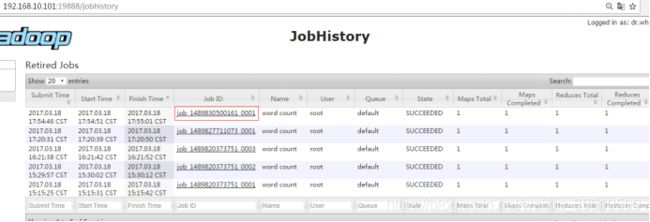
查看JobHistory
http://hadoop1:19888/jobhistory
配置日志的聚集:
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryManager。
开启日志聚集功能具体步骤如下:
1.配置yarn-site.xml
[atguigu@hadoop1 hadoop]$ vi yarn-site.xml
在该文件里面增加如下配置。
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
604800
2.关闭NodeManager 、ResourceManager和HistoryManager
[atguigu@hadoop1 hadoop-2.7.2]$ sbin/yarn-daemon.sh stop resourcemanager
[atguigu@hadoop1 hadoop-2.7.2]$ sbin/yarn-daemon.sh stop nodemanager
[atguigu@hadoop1 hadoop-2.7.2]$ sbin/mr-jobhistory-daemon.sh stop historyserver
3.启动NodeManager 、ResourceManager和HistoryManager
[atguigu@hadoop1 hadoop-2.7.2]$ sbin/yarn-daemon.sh start resourcemanager
[atguigu@hadoop1 hadoop-2.7.2]$ sbin/yarn-daemon.sh start nodemanager
[atguigu@hadoop1 hadoop-2.7.2]$ sbin/mr-jobhistory-daemon.sh start historyserver
4.删除HDFS上已经存在的输出文件
[atguigu@hadoop1 hadoop-2.7.2]$ bin/hdfs dfs -rm -R /user/atguigu/output
5.执行WordCount程序
[atguigu@hadoop1 hadoop-2.7.2]$ hadoop jar
share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/atguigu/input /user/atguigu/output
6.查看日志,如图2-37,2-38,2-39所示
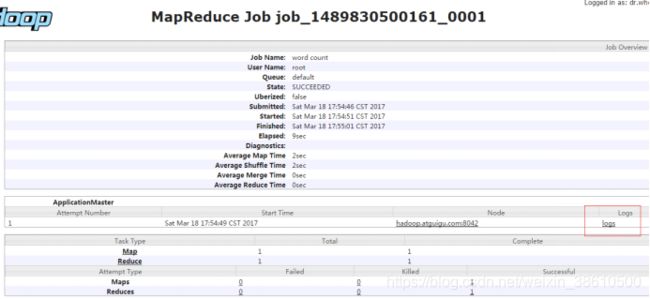
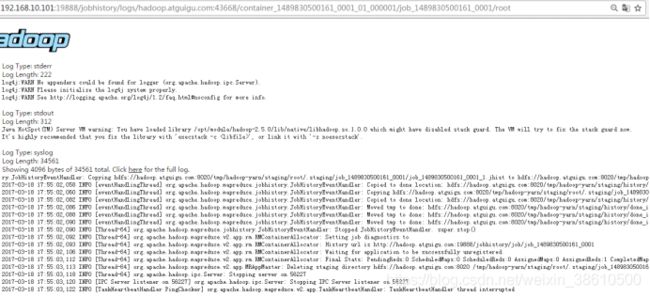
http://hadoop1:19888/jobhistory