「Python数据挖掘系列」2. NumPy 和 pandas
来源 | Python Data Analysis 3rd Edition
作者 | Navlani,et al.
翻译 | Harper
校对 | gongyouliu
编辑 | auroral-L
全文共7943字,预计阅读时间40分钟。
第二章 NumPy 和 pandas
1. 技术需求
2. 了解 NumPy 分组
2.1 数组功能
2.2 选择数组元素
3. 数值数据类型的NumPy 数组
3.1 dtype 对象
3.2 数据类型字符代码
3.3 dtype 构造函数
3.4 dtype 属性
4. 对数组形状进行操纵
5. NumPy 数组的堆叠
6. 对 NumPy 数组进行分区
7. 更改 NumPy 数组的数据类型
8. 创建NumPy视图和副本
9. 对NumPy数组进行切片
现在我们已经了解了数据分析,其过程以及在不同平台上的安装,现在该学习NumPy数组和pandas DataFrames了。本章将带你熟悉NumPy数组和pandas DataFrames的基础知识。在本章的最后,你将对NumPy数组,pandas DataFrame及其相关功能有基本的了解。
Pandas参考panel data(计量经济学术语)和Python数据分析而命名,并且是一个流行的开源Python库。我们将在本章中了解pandas的基本功能,数据结构和操作。pandas官方文件坚持以所有小写字母命名pandas项目。pandas项目坚持的另一项约定是以“import pandas as pd ”作为导入声明。
1. 技术需求
本章具有以下技术需求:
〇你可以在以下GitHub链接上找到代码和数据集:
https//github.com/PacktPublishing/Python-Data-Analysis-Third-Edition/tree/master/Chapter02。
〇所有代码块均位于ch2.ipynb。
〇本章使用四个CSV文件(WHO_first9cols.csv,dest.csv,purchase.csv和tips.csv)进行练习。
〇在本章中,我们将使用NumPy,pandas和Quandl Python库。
2. 了解NumPy数组
NumPy可以使用pip或brew安装在PC上,但是如果用户使用Jupyter Notebook,则无需安装。NumPy已安装在Jupyter Notebook中。建议你使用Jupyter Notebook作为你的IDE,因为我们正在执行Jupyter Notebook中的所有代码。我们已经在第1章“ Python库入门”中展示了如何安装Anaconda(这是用于数据分析的完整套件)。NumPy数组是一系列同质项。同质意味着数组的所有元素具有相同数据类型。接下来使用NumPy创建一个数组。你可以使用带有项列表的array()函数创建一个数组。用户还可以确定数组的数据类型。可能的数据类型为bool,int,float,long,double和long double。
让我们看看如何创建一个空数组:
# Creating an array
import numpy as np
a = np.array([2,4,6,8,10])
print(a)
输出:
[ 2 4 6 8 10]
创建NumPy数组的另一种方法是使用arange()。它创建一个均匀间隔的NumPy数组。可以将三个值(起点,终点和步长)传递给arange(start,[stop],step)函数。起点是范围的初始值,终点是范围的最后一个值,步长是该范围的增量。stop参数是强制性的。在下面的示例中,我们将1用作start参数,将11用作stop参数。arange(1,11)函数将以一个步长返回1到10个值,因为默认情况下该步长为1。range()函数生成的值比stop参数值小1。我们可以通过以下示例了解这一点:
# Creating an array using arange()
import numpy as np
a = np.arange(1,11)
print(a)
输出:
[ 1 2 3 4 5 6 7 8 9 10]
除了array()和arange()函数外,还有其他选项,例如zeros(),ones(),full(),eye()和random(),它们也可以用于创建NumPy数组 ,因为这些函数是初始占位符。这是每个函数的详细说明:
zeros():zeros()函数创建一个所有值为0的给定维度的数组。
ones():ones()函数创建一个所有值为1的给定维度的数组。
fulls():full()函数生成一个具有常量值的数组。
eyes():eye()函数创建一个单位矩阵。
random():random()函数创建任何给定维数的数组。
让我们通过以下示例了解这些功能:
import numpy as np
# Create an array of all zeros
p = np.zeros((3,3))
print(p)
# Create an array of all ones
q = np.ones((2,2))
print(q)
# Create a constant array
r = np.full((2,2), 4)
print(r)
# Create a 2x2 identity matrix
s = np.eye(4)
print(s)
# Create an array filled with random values
t = np.random.random((3,3))
print(t)
结果为以下输出:
[[0. 0. 0.]
[0. 0. 0.]]
[[1. 1.]
[1. 1.]]
[[4 4]
[4 4]]
[[1. 0. 0. 0.]
[0. 1. 0. 0.]
[0. 0. 1. 0.]
[0. 0. 0. 1.]]
[[0.16681892 0.00398631 0.61954178]
[0.52461924 0.30234715 0.58848138]
[0.75172385 0.17752708 0.12665832]]
在前面的代码中,我们已经看到了一些内置函数,这些函数可以创建具有全零值,全一值和全常数值的数组。之后,我们使用eye()函数创建了单位矩阵,并使用random.random()函数创建了随机矩阵。在下一节中,我们将介绍其他一些数组功能。
2.1 数组功能
通常,NumPy数组是具有相同型的项的同类数据结构。数组的主要优点是由于其具有相同类型的项而具有确定的存储大小。Python列表使用循环来迭代元素并对其执行操作。NumPy数组的另一个好处是提供矢量化操作,而不是迭代每个项目并对其执行操作 NumPy数组的索引就像Python列表一样,从0开始。NumPy使用优化的C API来快速处理数组操作。
像上一节一样,让我们使用arange()函数创建一个数组,并检查其数据类型:
# Creating an array using arange()
import numpy as np
a = np.arange(1,11)
print(type(a))
print(a.dtype)
Output:
int64
当你使用type()时,它将返回numpy.ndarray。这意味着type()函数返回容器的类型。使用dtype()时,它将返回int64,因为它是元素的类型。如果你使用的是32位Python,则输出也可能为int32。两种情况都使用整数(32位和64位)。一维NumPy数组也称为向量。
让我们得到前面所产生的向量:
print(a.shape)
Output: (10,)
如你所见,向量有10个元素,值的范围是1到10。该数组的shape是一个元组。在这种情况下,它是一个元素的元组,该元组在每个维度中保持其长度。
2.2 选择数组元素
在本节中,我们将看到如何选择数组的元素。让我们看一个2 * 2矩阵的示例:
a = np.array([[5,6],[7,8]])
print(a)
Output:
[[5 6]
[7 8]]
在前面的示例中,使用array()函数以及列表的列表作为输入来创建矩阵。
选择数组元素非常简单。我们只需要将矩阵的索引指定为a[m,n]。此处,m是矩阵的行索引,n是矩阵的列索引。现在,我们将一一选择矩阵中的每个项,如以下代码所示:
print(a[0,0])
Output: 5
print(a[0,1])
Output: 6
printa([1,0])
Output: 7
printa([1,1])
Output: 8
在前面的代码示例中,我们尝试使用数组索引访问数组的每个元素。你还可以通过此处的图表了解这一点:
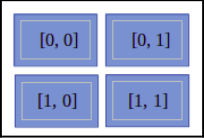
在上图中,我们可以看到它有四个块,每个块代表一个数组的元素。每个块中写入的值均显示其索引。在本节中,我们了解了数组的基础。现在,让我们跳到数值数据类型的数组。
3. 数值数据类型的NumPy数组
Python提供了三种类型的数字数据类型:整数类型,浮点类型和复杂类型。实际上,我们需要更多具有精度,范围和大小的数据类型来进行科学计算。NumPy提供了大量具有数学类型和数字的数据类型。让我们看一下NumPy数值类型的下表:
数据类型 |
描述 |
bool |
这是一个布尔类型,它存储一个bit并采用True或False值。 |
inti |
整数可以是int32或int64。 |
int8 |
字节存储范围是-128至127。 |
int16 |
它存储从-32768到32767的整数。 |
int32 |
它存储从-2 ** 31到2 ** 31 -1的整数。 |
int64 |
它存储从-2 ** 63到2 ** 63 -1的整数。 |
uint8 |
它存储0到255的无符号整数。 |
uint16 |
它存储从0到65535的无符号整数。 |
uint32 |
它存储0到2 ** 32 – 1的无符号整数。 |
uint64 |
它存储0到2 ** 64 – 1的无符号整数。 |
float16 |
半精度浮点数;符号位具有5位指数和10位尾数。 |
float32 |
单精度浮点数;符号位具有8位指数和23位的尾数 |
float64 or float |
双精度浮点;符号位具有11位指数和52位尾数。 |
complex64 |
复数存储两个32位浮点数:实数和虚数。 |
complex128 or complex |
复数存储两个64位浮点数:实数和虚数。 |
对于每种数据类型,都有一个匹配的转换函数:
print(np.float64(21))
Output: 21.0
print(np.int8(21.0))
Output: 42
print(np.bool(21))
Output: True
print(np.bool(0))
Output: False
print(np.bool(21.0))
Output: True
print(np.float(True))
Output: 1.0
print(np.float(False))
Output: 0.0
许多函数都有一种数据类型的参数,该参数通常是可选的:
arr=np.arange(1,11, dtype= np.float32)
print(arr)
Output:
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
请务必注意,不允许将复数更改为整数。如果你尝试将复数数据类型转换为整数,则将收到TypeError。让我们看下面的例子:
np.int(42.0 + 1.j)
结果为以下输出:

如果你尝试将复数转换为浮点数,则会遇到相同的错误。但是你可以通过设置单个部分(即实部和虚部)的值将浮点值转换为复数。你还可以使用real和imag属性提取片段。让我们使用以下示例进行查看:
c= complex(42, 1)
print(c)
Output: (42+1j)
print(c.real,c.imag)
Output: 42.0 1.0
在前面的示例中,你已经使用complex()方法定义了一个复数。另外,你还使用real和imag属性提取了实和虚值。现在让我们跳到dtype对象。
3.1 dtype对象
在本章的前面几节中,我们已经通过dtype了解了数组中各个元素的类型。NumPy数组元素具有相同的数据类型,这意味着所有元素都具有相同的dtype。dtype对象是numpy.dtype类的实例:
# Creating an array
import numpy as np
a = np.array([2,4,6,8,10])
print(a.dtype)
Output: 'int64'
dtype对象还使用itemsize属性告诉我们数据类型的大小(以字节为单位):
print(a.dtype.itemsize)
Output:8
3.2 数据类型字符代码
提供字符代码是为了与后面的Numeric兼容。Numeric是NumPy的前身。不建议使用它,但是此处提供了代码,因为它会在不同的地方出现。你应该改用dtype对象。下表列出了几种不同的数据类型以及与它们相关的字符编码:
数据类型 |
字符代码 |
Integer |
i |
Unsigned integer |
u |
Single-precision float |
f |
Double-precision float |
d |
Bool |
b |
Complex |
D |
String |
S |
Unicode |
U |
Void |
V |
让我们看一下下面的代码,以生成一个单精度浮点数组:
# Create numpy array using arange() function
var1=np.arange(1,11, dtype='f')
print(var1)
Output:
[ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.]
同样,以下代码创建一个复数数组:
print(np.arange(1,6, dtype='D'))
Output:
[1. +0.j, 2.+0.j, 3.+0.j, 4.+0.j, 5.+0.j]
3.3 dtype构造函数
有很多使用构造函数创建数据类型的方法。构造函数用于实例化或为对象分配值。在本节中,我们将借助浮点数据示例来理解数据类型的创建:
〇要尝试常规的Python浮点数,请使用以下代码:
print(np.dtype(float))
Output: float64
〇要尝试使用带字符代码的单精度浮点数,请使用以下命令:
print(np.dtype('f'))
Output: float32
〇要尝试使用带字符代码的双精度浮点数,请使用以下命令:
print(np.dtype('d'))
Output: float64
〇要尝试使用具有两个字符的代码的dtype构造函数,请使用以下命令:
print(np.dtype('f8'))
Output: float64
这里,第一个字符代表类型,第二个字符是指定类型中的字节数,例如2、4或8。
3.4 dtype属性
〇dtype类提供了几个有用的属性。例如,我们可以使用dtype属性获取有关数据类型的字符代码的信息:
# Create numpy array
var2=np.array([1,2,3],dtype='float64')
print(var2.dtype.char)
Output: 'd'
〇type属性对应于数组元素的对象类型
print(var2.dtype.type)
Output:
现在我们已经了解了NumPy数组中使用的各种数据类型,让我们在下一部分开始操作它们。
4. 对数组形状进行操纵
在本节中,我们的主要重点是数组操作。让我们学习一些NumPy的新Python函数,例如reshape(),flatten(),ravel(),transpose()和resize():
〇reshape()将更改数组的形状:
# Create an array
arr = np.arange(12)
print(arr)
Output: [ 0 1 2 3 4 5 6 7 8 9 10 11]
# Reshape the array dimension
new_arr=arr.reshape(4,3)
print(new_arr)
Output: [[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11]]
# Reshape the array dimension
new_arr2=arr.reshape(3,4)
print(new_arr2)
Output:
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
〇可以应用于数组的另一个操作是flatten()。flatten()将n维数组转换为一维数组:
# Create an array
arr=np.arange(1,10).reshape(3,3)
print(arr)
Output:
[4 5 6]
[7 8 9]]
print(arr.flatten())
Output:
[1 2 3 4 5 6 7 8 9]
〇ravel()函数类似于flatten()函数。还是将n维数组转换为一维数组。二者主要区别在于,flatten()返回实际数组,而ravel()返回原始数组的引用。ravel()函数比flatten()函数快,因为它不占用额外的内存:
print(arr.ravel())
Output:
[1, 2, 3, 4, 5, 6, 7, 8, 9]
〇transpose()函数是线性代数函数,可对给定的二维矩阵进行转置。转置一词是指将行转换为列,将列转换为行:
# Transpose the matrix
print(arr.transpose())
Output:
[[1 4 7]
[2 5 8]
[3 6 9]]
〇resize()函数能够更改NumPy数组的大小。它类似于reshape(),但是resize ()改变了原始数组的形状:
# resize the matrix
arr.resize(1,9)
print(arr)
Output:[[1 2 3 4 5 6 7 8 9]]
在本节的所有代码中,我们都已经看到了诸如reshape(),flatten(),ravel(),transpose()和resize()之类的内置函数来处理形状。现在,该学习NumPy数组的堆叠了。
5. NumPy数组的堆叠
NumPy提供了一堆数组。堆叠意味着将相同尺寸的数组与一条轴连接在一起。可以水平,垂直,按列,按行或按深度堆叠:
〇水平堆叠:在水平堆叠中,使用hstack()和concatenate()函数将相同维度的数组沿水平轴连接在一起。让我们看下面的例子:
arr1 = np.arange(1,10).reshape(3,3)
print(arr1)
Output:
[[1 2 3]
[4 5 6]
[7 8 9]]
我们已经创建了一个3 * 3数组;接下来就创建另一个3 * 3数组了:
arr2 = 2*arr1
print(arr2)
Output:
[[ 2 4 6]
[ 8 10 12]
[14 16 18]]
创建两个数组后,我们将执行水平堆叠:
# Horizontal Stacking
arr3=np.hstack((arr1, arr2))
print(arr3)
Output:
[[ 1 2 3 2 4 6]
[ 4 5 6 8 10 12]
[ 7 8 9 14 16 18]]
在前面的代码中,两个数组沿x轴水平堆叠。concatenate()函数当参数值为1时也可用于生成水平堆叠:
# Horizontal stacking using concatenate() function
arr4=np.concatenate((arr1, arr2), axis=1)
print(arr4)
Output:
[[ 1 2 3 2 4 6]
[ 4 5 6 8 10 12]
[ 7 8 9 14 16 18]]
在前面的代码中,使用concatenate()函数将两个数组水平堆叠。
〇垂直堆叠:在垂直堆叠中,使用vstack()和concatenate()函数将相同维数的数组沿垂直轴连接在一起,让我们看下面的示例:
# Vertical stacking
arr5=np.vstack((arr1, arr2))
print(arr5)
Output:
[[ 1 2 3]
[ 4 5 6]
[ 7 8 9]
[ 2 4 6]
[ 8 10 12]
[14 16 18]]
在前面的代码中,两个数组沿y轴垂直堆叠。而concatenate()函数当参数值为0时也可用于生成垂直堆叠:
arr6=np.concatenate((arr1, arr2), axis=0)
print(arr6)
Output:
[[ 1 2 3]
[ 4 5 6]
[ 7 8 9]
[ 2 4 6]
[ 8 10 12]
[14 16 18]]
在前面的代码中,使用concatenate()函数将两个数组垂直堆叠。
〇深度堆叠:在深度堆叠中,使用dstack()函数将相同尺寸的数组与第三个轴(深度轴)连接在一起。让我们看下面的例子:
arr7=np.dstack((arr1, arr2))
print(arr7)
Output:
[[[ 1 2]
[ 2 4]
[ 3 6]]
[[ 4 8]
[ 5 10]
[ 6 12]]
[[ 7 14]
[ 8 16]
[ 9 18]]]
在前面的代码中,两个数组沿深度方向堆叠。
〇列堆叠:列堆叠将多个序列一维数组作为列堆叠到一个二维数组中。让我们看一个列堆叠的例子:
# Create 1-D array
arr1 = np.arange(4,7)
print(arr1)
Output: [4, 5, 6]
在前面的代码块中,我们创建了一个一维NumPy数组。
# Create 1-D array
arr2 = 2 * arr1
print(arr2)
Output: [ 8, 10, 12]
在前面的代码块中,我们创建了另一个一维NumPy数组。
# Create column stack
arr_col_stack=np.column_stack((arr1,arr2))
print(arr_col_stack)
Output:
[[ 4 8]
[ 5 10]
[ 6 12]]
在前面的代码中,我们创建了两个一维数组并将它们按列堆叠。
〇行堆叠:行堆叠将多个序列一维数组作为行堆叠到一个二维数组中。让我们看一个行堆叠的例子:
# Create row stack
arr_row_stack = np.row_stack((arr1,arr2))
print(arr_row_stack)
Output:
[[ 4 5 6]
[ 8 10 12]]
在前面的代码中,两个一维数组按行堆叠在一起,现在让我们看看如何将NumPy数组划分为多个子数组。
6. 将NumPy数组分区
NumPy数组可以划分为多个子数组。NumPy提供三种类型的分割功能:垂直,水平和深度分割。默认情况下,所有拆分功能均拆分为相同大小的数组,但我们也可以指定拆分位置。让我们详细看一下每个函数:
〇水平拆分:在水平拆分中,使用hsplit()函数将给定的数组沿水平轴划分为N个相等的子数组。让我们看看如何拆分数组:
# Create an array
arr=np.arange(1,10).reshape(3,3)
print(arr)
Output:
[[1 2 3]
[4 5 6]
[7 8 9]]
# Peroform horizontal splitting
arr_hor_split=np.hsplit(arr, 3)
print(arr_hor_split)
Output:
[array([[1],
[4],
[7]]), array([[2],
[5],
[8]]), array([[3],
[6],
[9]])]
在前面的代码中,hsplit(arr,3)函数将数组分为三个子数组。每个部分都是原始数组的一列。
〇垂直拆分:在垂直拆分中,使用vsplit()和split()函数将给定的数组沿垂直轴划分为N个相等的子数组。axis = 0的split函数执行与vsplit()函数相同的操作:
# vertical split
arr_ver_split=np.vsplit(arr, 3)
print(arr_ver_split)
Output:
[array([[1, 2, 3]]), array([[4, 5, 6]]), array([[7, 8, 9]])]
在前面的代码中,vsplit(arr,3)函数将数组分为三个子数组。每个部分都是原始数组的一行。在下面的示例中,让我们来看另一个函数split(),它可以用作垂直和水平拆分:
# split with axis=0
arr_split=np.split(arr,3,axis=0)
print(arr_split)
Output:
[array([[1, 2, 3]]), array([[4, 5, 6]]), array([[7, 8, 9]])]
# split with axis=1
arr_split = np.split(arr,3,axis=1)
Output:
[array([[1],
[4],
[7]]), array([[2],
[5],
[8]]), array([[3],
[6],
[9]])]
在前面的代码中,split(arr,3)函数将数组分为三个子数组。每个部分都是原始数组的一行。当axis = 0时,分割输出类似于vsplit()函数,而当axis = 1时,分割输出类似于hsplit()函数。
7. 更改NumPy数组的数据类型
如前所述,NumPy支持多种数据类型,例如int,float和复数。astype()函数可用于转换数组的数据类型。我们来看一个astype()函数的示例:
# Create an array
arr=np.arange(1,10).reshape(3,3)
print("Integer Array:",arr)
# Change datatype of array
arr=arr.astype(float)
# print array
print("Float Array:", arr)
# Check new data type of array
print("Changed Datatype:", arr.dtype)
在前面的代码中,我们创建了一个NumPy数组,并使用dtype属性检查了其数据类型。
现在让我们使用astype()函数更改数组的数据类型:
# Change datatype of array
arr=arr.astype(float)
# Check new data type of array
print(arr.dtype)
Output:
float64
在前面的代码中,我们使用astype()将列数据类型从整数更改为浮点型。
tolist()函数将NumPy数组转换为Python列表。我们来看一个tolist()函数的示例:
# Create an array
arr=np.arange(1,10)
# Convert NumPy array to Python List
list1=arr.tolist()
print(list1)
Output:
[1, 2, 3, 4, 5, 6, 7, 8, 9]
在前面的代码中,我们已使用tolist()函数将数组转换为Python列表对象。
8. 创建NumPy views和copies
有些Python函数能够返回输入数组的views和copies。Python copy将数组存储在另一个位置,而view使用相同的内存。这意味着copies是单独的对象,在Python中被视为深层copies。views是原始基础数组,并被视为浅层copies。以下是copies和views的一些属性:
〇views中的修改会影响原始数据,而copies的修改不会影响原始数组。
〇views使用共享内存的概念。
〇与views相比,copies需要更多空间。
〇copies比views慢。
让我们使用以下示例了解copy和view的概念:
# Create NumPy Array
arr = np.arange(1,5).reshape(2,2)
print(arr)
Output:
[[1, 2],
[3, 4]]
创建NumPy数组后,现在我们向对象执行copy操作:
# Create no copy only assignment
arr_no_copy=arr
# Create Deep Copy
arr_copy=arr.copy()
# Create shallow copy using View
arr_view=arr.view()
print("Original Array: ",id(arr))
print("Assignment: ",id(arr_no_copy))
print("Deep Copy: ",id(arr_copy))
print("Shallow Copy(View): ",id(arr_view))
Output:
Original Array: 140426327484256
Assignment: 140426327484256
Deep Copy: 140426327483856
Shallow Copy(View): 140426327484496
在前面的示例中,你可以看到原始数组和分配的数组具有相同的对象ID,这意味着它们都指向同一对象。Copies和views都具有不同的对象ID。两者都有不同的对象,但是view对象将引用相同的原始数组,而copy将具有该对象的不同副本。
让我们继续这个示例,并更新原始数组的值,并检查其对view和copy的影响:
# Update the values of original array
arr[1]=[99,89]
# Check values of array view
print("View Array:\n", arr_view)
# Check values of array copy
print("Copied Array:\n", arr_copy)
Output:
View Array:
[[ 1 2]
[99 89]]
Copied Array:
[[1 2]
[3 4]]
在前面的示例中,我们可以从结果中得出结论,view是原始数组。当我们更新原始数组时,值更改了,但是copy是一个单独的对象,因为其值保持不变。
9. 对NumPy数组进行切片
在NumPy中切片类似于Python列表。索引倾向于选择单个值,而切片则用于从数组中选择多个值.NumPy数组还支持负索引和切片。在这里,负号指示相反的方向,索引从右侧开始,起始值为-1:
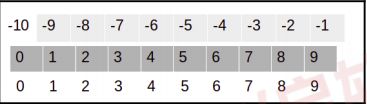
让我们使用以下代码进行检查:
# Create NumPy Array
arr = np.arange(0,10)
print(arr)
Output: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
在切片操作中,我们使用冒号来选择值的集合。切片采用三个值:start,stop和step:
print(arr[3:6])
Output: [3, 4, 5]
可以表示如下:
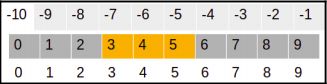
在前面的示例中,我们使用3作为起始索引,使用6作为终止索引:
print(arr[3:])
Output: array([3, 4, 5, 6, 7, 8, 9])
在前面的示例中,仅给出了起始索引。3是起始索引。此切片操作将选择从起始索引到数组结尾的值:
print(arr[-3:])
Output: array([7, 8, 9])
可以表示如下:
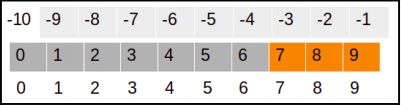
在前面的示例中,切片操作将选择从数组右侧到数组末尾的第三个值:
print(arr[2:7:2])
Output: array([2,4,6])
可以表示如下:
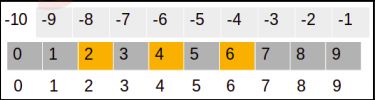
在前面的示例中,start,stop和step索引分别为2、7和2。在此处,切片操作从第二索引值到第六索引值(比stop值小一个)中选择值,索引值屡次加2。因此,输出将是2、4和6。

