【深度学习】— 分布式训练常用技术总结
【深度学习】— 分布式训练常用技术总结
概述
分布式、高并发、多线程,似乎是一个程序员永远逃离不了的3个关键词,只要脱离了单机/单节点,涉及到2台以上的机器,就会碰到分布式。深度学习领域也一样,当你拥有海量数据/巨大模型的训练需求时,即使你拥有一台8块TESLA V100的服务器,仍显不够,为了加速训练,自然地拓展为2机、4机甚至更多机器节点的分布式训练…
CV领域,为了将训练ImageNet的时间压缩至最短,腾讯团队曾在2018年,使用了2048块Tesla P40,将ResNet50在ImageNet上的训练时间压缩至6.6分钟,详见论文《Highly Scalable Deep Learning Training System withMixed-Precision: Training ImageNet in Four Minutes》,知乎也有相关报道:4分钟训练ImageNet!腾讯机智创造AI训练世界纪录
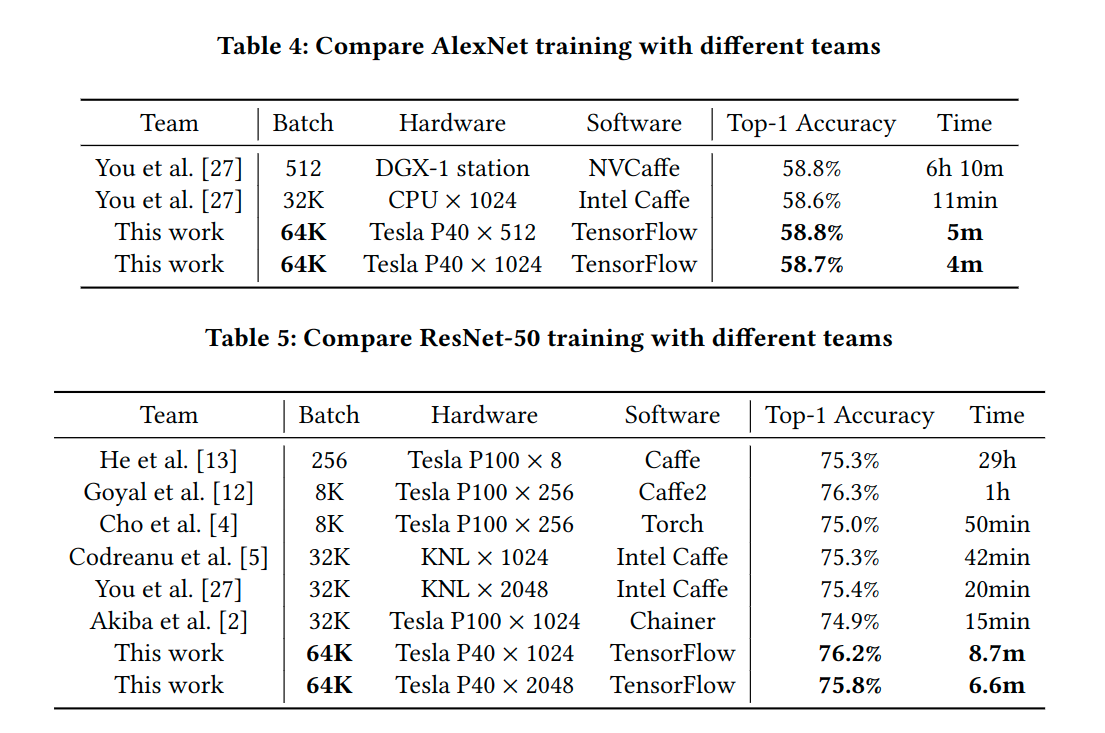
NLP领域,更是大模型频出,如BERT、GTP系列。为了训练GPT-2模型,用了256个Google Cloud TPU v3,据说GPT-3的训练更是耗费了N多显卡和1200万美金,知乎上也有相关文章:如何评价1700亿参数的GPT-3?
天下武功,唯快不破,要想快,就必须走分布式训练的路子。现在,各大深度学习框架基本都支持了深度学习模型的分布式训练,那么问题来了:深度学习的分布式训练究竟使用了哪些技术和框架,原理又是什么?各大框架的分布式训练上手难易程度如何,训练孰优孰劣,加速比如何?
本系列文章文将对以上问题进行粗浅的回答和总结,权当抛砖引玉,欢迎大家关注和交流!其中**本篇文章重点梳理深度学习分布式训练领域常用的一些技术及概念;下一篇文章将着重梳理各框架的分布式接口,使用方法及测评速度对比。**如有疏漏和不足之处,还请多指点。最后,**安利一下我们最近的工作——DLPerf仓库。**里面包含了以上各个框架的速度评测,以及详细的ReadMe,让你可以轻松复现、跑起来各框架的分布式多机。
1.数据并行or模型并行
通常,深度学习领域的分布式模型训练主要有以下两种方式:
- 数据并行(Data Parallel)
- 模型并行(Model Parallel)
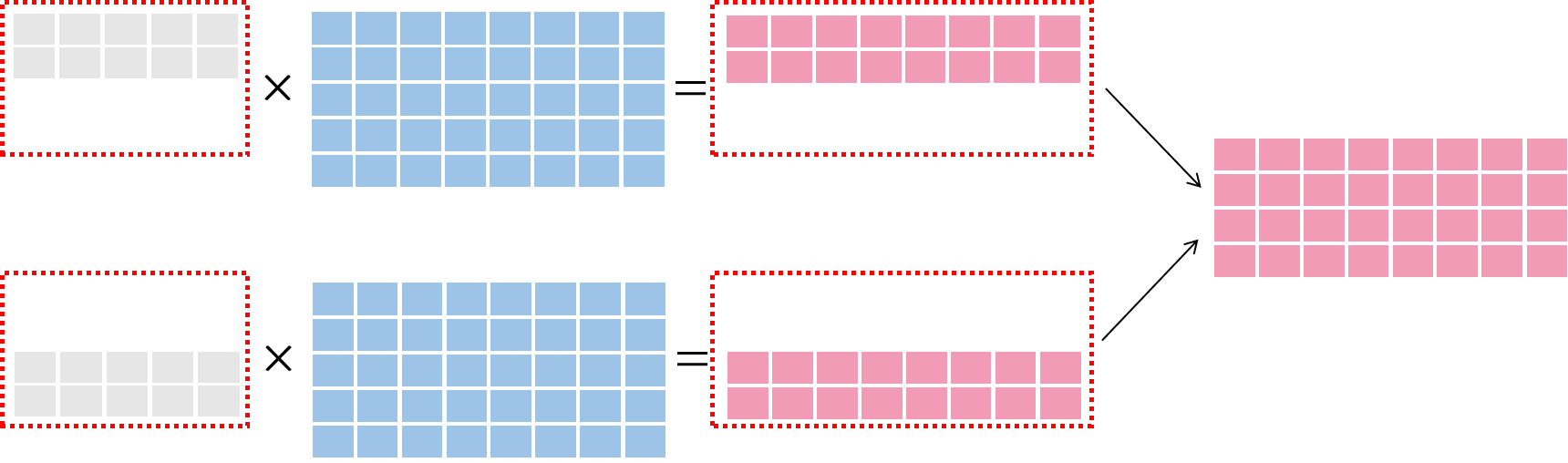
数据并行图示
在 数据并行 中,将样本数据进行切分,切分后的数据 被送至各个训练节点,与 完整的模型 进行运算,最后将多个节点的信息进行合并,如下图所示:
模型并行图示
在 模型并行 中,将模型进行切分,完整的数据 被送至各个训练节点,与 切分后的模型 进行运算,最后将多个节点的运算结果合并,如下图所示:
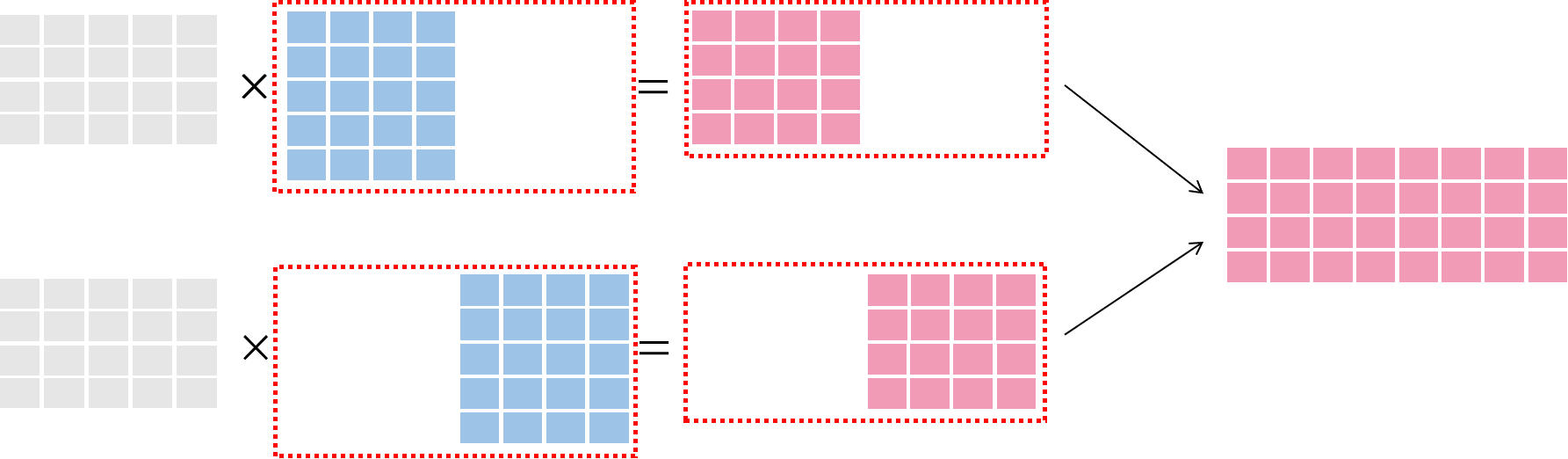
灰色表示数据,蓝色表示模型
1.1 数据并行
什么是数据并行?
以GPU的维度来看,数据并行简单来说就是在并行训练的设备上,对完整训练数据进行分片训练,同一个训练的时间间隔内,不同GPU设备上用各自分片的数据对模型进行训练,其后再进行模型梯度的汇总更新和各GPU间的状态同步。这样做的结果就是在一个训练的时间间隔内,各个GPU设备可以并行地用各自分片的数据进行模型训练,从而大大加速了整体模型的训练。
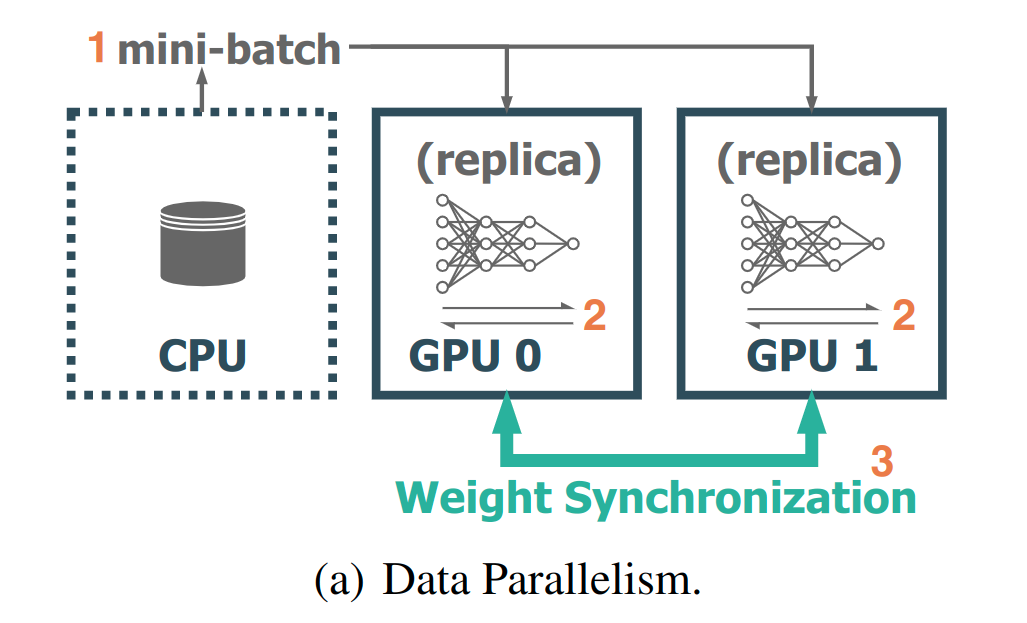
从上图可见,数据并行时,每个GPU设备上保持了同样的模型数据,且一次完整的训练过程包括以下3步:
1.CPU负责将不同的训练数据(mini-batch)分别喂给GPU0和GPU1设备;
2.不同的显卡设备上存储了完全一致的模型,通过mini-batch数据进行了前向和反向传播;
3.位于不同GPU设备上的模型进行权重同步和更新
为什么需要数据并行?
简单来说,天下武功唯快不破,当我们的数据规模越来越大,训练一个完整模型所需的时间越来越长,为了加速训练,我们通常不会用单个GPU设备进行训练,而是采用单机多卡(GPU)、多机多卡的方式进行模型训练。即我们希望通过分布式训练的方式,通过拓展设备数量来压缩训练时间,达到近乎线性的加速比。
举个栗子?已知:
假设训练集为128万张的ImageNet;模型为ResNet50;单GPU的显存能支持的最大batch size为128;
迭代1个batch(完成数据加载+前向+反向梯度更新)需要的时间为7.2秒,且GPU设备越多速度越快(线性加速)
求:
单个GPU训练1个epoch、100epoch所需时间?单机8卡(GPU)呢?4机×10卡呢?
答案:
完成一个epoch需要的时间为1280000/128 * 7.2 = 72000(s),即20小时,迭代100epoch,则在单张GPU上所需的时间是20*100=2000小时,如果用单GPU的方式训练模型,需要耗时间近3个月(头发都掉光了~)
1机8卡,则训练时间理论上仅为原来的1/8;如果用4台8卡的机器(多机多卡数据并行)训练,则时间更是缩短至原来的1/32,即2000/32=62.5小时(还是可以接受的)。
大多数情况下,我们使用数据并行的方式来进行分布式模型训练。在此种方式下,我们希望通过更多的GPU或机器节点来加速模型训练,目标是通过横向拓展,达到理想情况下的线性加速比。
1.2 模型并行
什么是模型并行?
模型并行和数据并行类似,将整个模型的不同网络层(或者某一层)的参数矩阵切分至不同的GPU设备上,进行模型训练的过程。
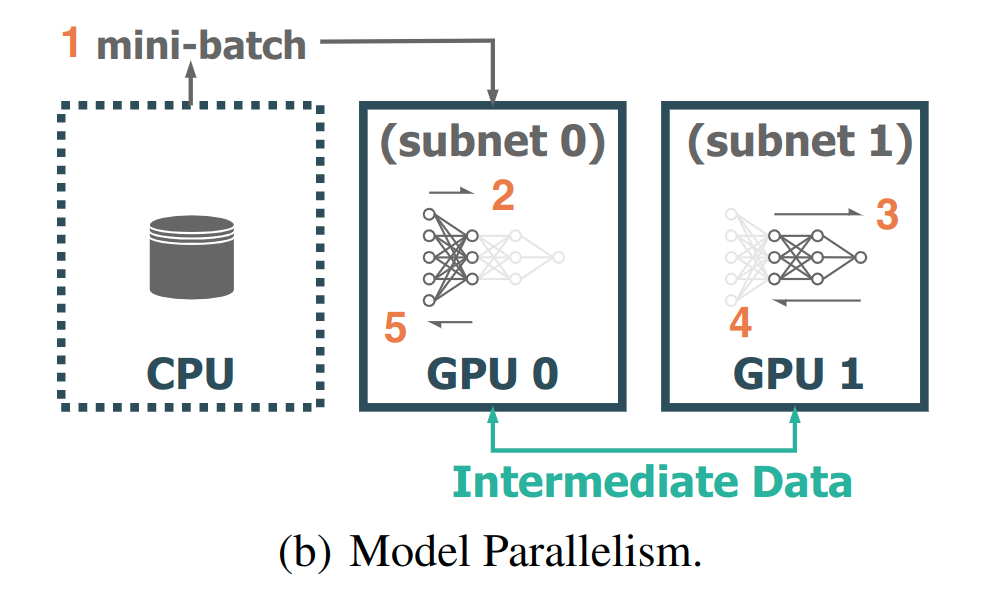
从上图可知,模型并行时,完整的模型网络切分到了不同设备:GPU0和GPU1,且训练过程分为如下几步:
1.mini-batch喂送给GPU0;
2.数据在GPU0所在网络上进行前向过程;
3.上一步的数据继续喂给GPU1并在GPU1的网络上继续进行前向;
4.GPU1进行反向;
5.反向数据回传给GPU0,继续进行反向;
可见,模型并行时,并不需要进行各个设备上模型权重参数的同步更新,而是会有中间数据在各个GPU上的模型之间流动。
为什么需要模型并行?
少数情况下,模型规模特别巨大,参数特别多以至于单个GPU的显存塞不下(譬如某些分类网络/人脸模型由于num_classes特别大,导致最后FC全连接层的参数量巨大),于是只能通过模型并行的方式进行训练,即将模型的各网络层甚至是某一层的参数矩阵划分至多张GPU上进行训练。
当然,除了常见的数据并行、模型并行以外,还有数据-模型混合并行,流水并行等其他并行方式,本系列文章重点内容为分布式下的数据并行模型训练。
2.分布式下的集合通信(Collective communication)
何为集合通信(Collective communication)?要说集合通信,首先得了解P2P点对点通信(Point-to-point)。P2P通信通常为两个不同进程间的通信,是1对1的;相应的,集合通信则是1对多或是多对多的。在分布式系统中,各个节点间往往存在大量的集合通信需求,而我们可以用消息传递接口(Message Passing Interface, MPI)来定义一些比较底层的消息通信行为譬如Reduce、All reduce、Scatter、Gather等。
MPI 的历史简介
在 90 年代之前,程序员可没我们这么幸运。对于不同的计算架构写并发程序是一件困难而且冗长的事情。当时,很多软件库可以帮助写并发程序,但是没有一个大家都接受的标准来做这个事情。
在当时,大多数的并发程序只出现在科学和研究的领域。最广为接受的模型就是消息传递模型。什么是消息传递模型?它其实只是指程序通过在进程间传递消息(消息可以理解成带有一些信息和数据的一个数据结构)来完成某些任务。在实践中,并发程序用这个模型去实现特别容易。举例来说,主进程(manager process)可以通过对从进程(worker process)发送一个描述工作的消息来把这个工作分配给它。另一个例子就是一个并发的排序程序可以在当前进程中对当前进程可见的(我们称作本地的,locally)数据进行排序,然后把排好序的数据发送的邻居进程上面来进行合并的操作。几乎所有的并行程序可以使用消息传递模型来描述。
由于当时很多软件库都用到了这个消息传递模型,但是在定义上有些微小的差异,这些库的作者以及一些其他人为了解决这个问题就在 Supercomputing 1992 大会上定义了一个消息传递接口的标准- 也就是 MPI。这个标准接口使得程序员写的并发程序可以在所有主流的并发框架中运行。并且允许他们可以使用当时已经在使用的一些流行库的特性和模型。
到 1994 年的时候,一个完整的接口标准定义好了(MPI-1)。我们要记住 MPI 只是_一个接口的定义而已。然后需要程序员去根据不同的架构去实现这个接口。很幸运的是,仅仅一年之后,一个完整的 MPI 实现就已经出现了。在第一个实现之后,MPI 就被大量地使用在消息传递应用程序中,并且依然是写这类程序的_标准(de-facto)。

第一批 MPI 程序员的一个真实写照
引用自:https://mpitutorial.com/tutorials/mpi-introduction/zh_cn/
MPI作为高性能计算领域的元老和通信标准,定义了一系列的通信接口,其上层可以由多种编程语音实现(如c/c++、fortran、java…),有一些比较流行的通信库实现如:MPICH2、OpenMPI,这些通信库用不同的代码/算法实现了MPI的接口定义的通信模式。其中常用的通信模式有:
- Send
- Receive
- Broadcast
- Scatter
- Gather
- Reduce
- All reduce
下面,我们通过文字和示意图对其中一些通信模式作简单讲解,插图来自:https://mpitutorial.com/tutorials/
2.1集合通信
通常,作为算法开发者,只需要了解各个框架提供的上层api,能进行分布式模型训练即可;不过作为框架开发者,了解一下常见的集合通信模式/算法,绝对是很有必要的,因为常用的分布式通信库如OpenMPI、NCCL等,本质上都是基于MPI接口实现了一系列算法,使得分布式情况下的节点间能快速地进行通信和数据传输。
Send&Receive
在MPI中既有同步阻塞的消息发送、接收接口,如:MPI_send和MPI_Recv,也有非阻塞(nonblocking)接口如MPI_Isend和MPI_Irecve。这些接口定义了P2P通信模式中的发送和接收方法。作为MPI中最为基础的通信接口,其底层可以走不同的通信协议来传输(也可人为指定)。
需要说明的是,Send&Receive属于P2P通信,把它单独介绍的原因在于它们很基础,很多集合通信实现是可以通过Send&Receive的组合来完成。
Broadcast&Scatter
圆圈表示分布式系统中的独立节点(进程),如上图的0~3,共4个节点;小方块则代表了数据,颜色相同表示数据一样。
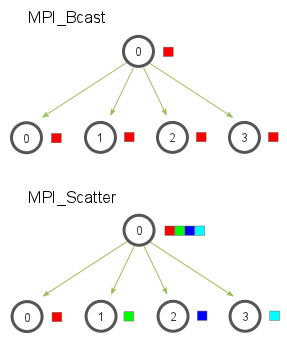
broadcast代表了一种广播的行为,执行broadcast时,数据从主节点广播至其他各个指定的节点;和broadcast类似,scatter表示一种散播行为,将主节点的数据划分散布至其他指定的节点。
Gather
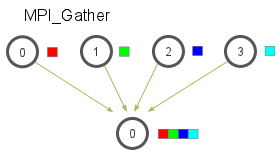
gather行为和scatter行为相反,对应的是收集,执行gather的节点将会从其他指定节点收集相应的数据。
All gather
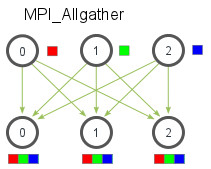
all gather则是加强版的gather,将使得每个节点都执行一次gather行为
Reduce
reduce称为规约运算,是一系列运算操作的统称,细分来说包括SUM、MIN、MAX、PROD、LOR等。reduce意为减少/精简,因为其操作在每个进程上获取一个输入元素数组,通过执行操作后,将得到精简的更少的元素。例如下面的Reduce sum:
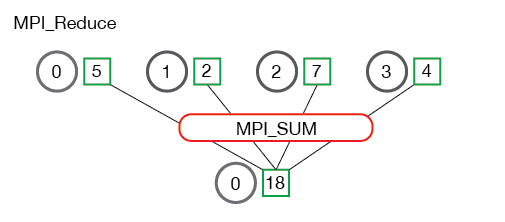
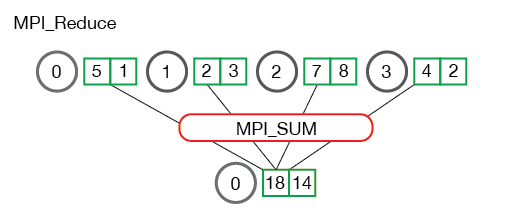
All reduce
reduce是一系列操作的统称,all reduce则是在所有的节点进程上都应用同样的reduce操作。
All reduce sum:
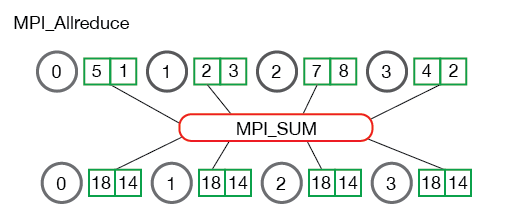
从图中可以看出,all reduce操作可通过单节点上reduce+broadcast操作完成。
2.2通信库
Open MPI
借用官网描述:Open MPI项目是一个开源MPI(消息传递接口 )实现,由学术,研究和行业合作伙伴联盟开发和维护。因此,Open MPI可以整合高性能计算社区中所有专家,技术和资源,以构建可用的最佳MPI库。
Gloo
Gloo是facebook开源的一套集体通信库,他提供了对机器学习中有用的一些集合通信算法如:barrier, broadcast, allreduce
NCCL
NCCL是英伟达基于NCIDIA-GPU的一套开源的集体通信库,如其官网描述:NVIDIA集体通信库(NCCL)实现了针对NVIDIA GPU性能优化的多GPU和多节点集体通信原语。NCCL提供了诸如all-gather, all-reduce, broadcast, reduce, reduce-scatter等实现,这些实现优化后可以通过PCIe和NVLink等高速互联,从而实现高带宽和低延迟。
因为MPI针对的是通用的分布式环境,而NCCL则是NVIDIA基于自身硬件定制的,能做到更有针对性且更方便优化,故在英伟达硬件上,NCCL的效果往往比传统的MPI更好。
Horovod
Horovod其实不是通信库,利用底层通信库包装的一套,适用于深度学习分布式训练的框架。
Horovod是Uber开源的,针对TensorFlow,Keras,PyTorch和Apache MXNet的分布式深度学习训练框架Horovod的目标是使分布式深度学习快速且易于使用,其底层支持mpi、gloo或者nccl进行数据通信。通常,在nvidia-gpu上,使用horovod+nccl的组合,能使深度学习的分布式训练达到较高的性能和加速比,尽管Horovod的出现已经大大方便了在深度学习中进行分布式训练,然而要支持horovod,除了需要安装mpi、nccl等通信库外,还是需要手动改一些模型训练的代码。
3.分布式训练和All reduce
3.1 二者关系?

在1.1节,我们知道了一个分布式深度学习(数据并行)训练的主要过程大致分为3步:
-
**数据划分 **
不同GPU设备上划分出不同的mini-batch,作为训练的数据集 -
**前向+反向 **
不同GPU设备上用相同的模型,用各自接收到的mini-batch数据进行训练(前向和反向传播) -
梯度同步更新
每个GPU设备得到了mini-batch训练后的权重值,这些值需要汇总然后更新至每一个GPU设备,保证每一次迭代后,每个GPU设备上的模型完全一致。
我们可以看见,第3步梯度同步更新包含从各节点收集梯度、汇总、更新至每一节点的全部过程,这些组合起来就是一个all reduce的过程,具体点说是all reduce sum操作。通过all reduce sum,各自节点更新的梯度值汇总后,再更新至每一个节点。由此可见,深度学习的分布式训练和all reduce的关系是十分紧密的。
3.2 All reduce哪家强?
3.2.1 OpenMPI
MPI的实现里,有各种各样的all reduce算法,在最新的OpenMPI-4.0.5的代码中(openmpi-4.0.5/ompi/mca/coll/tuned/coll_tuned_allreduce_decision.c),我们可以看到有7种不同的all reduce算法实现:
{
0, "ignore"},
{
1, "basic_linear"},
{
2, "nonoverlapping"},
{
3, "recursive_doubling"},
{
4, "ring"},
{
5, "segmented_ring"},
{
6, "rabenseifner"},
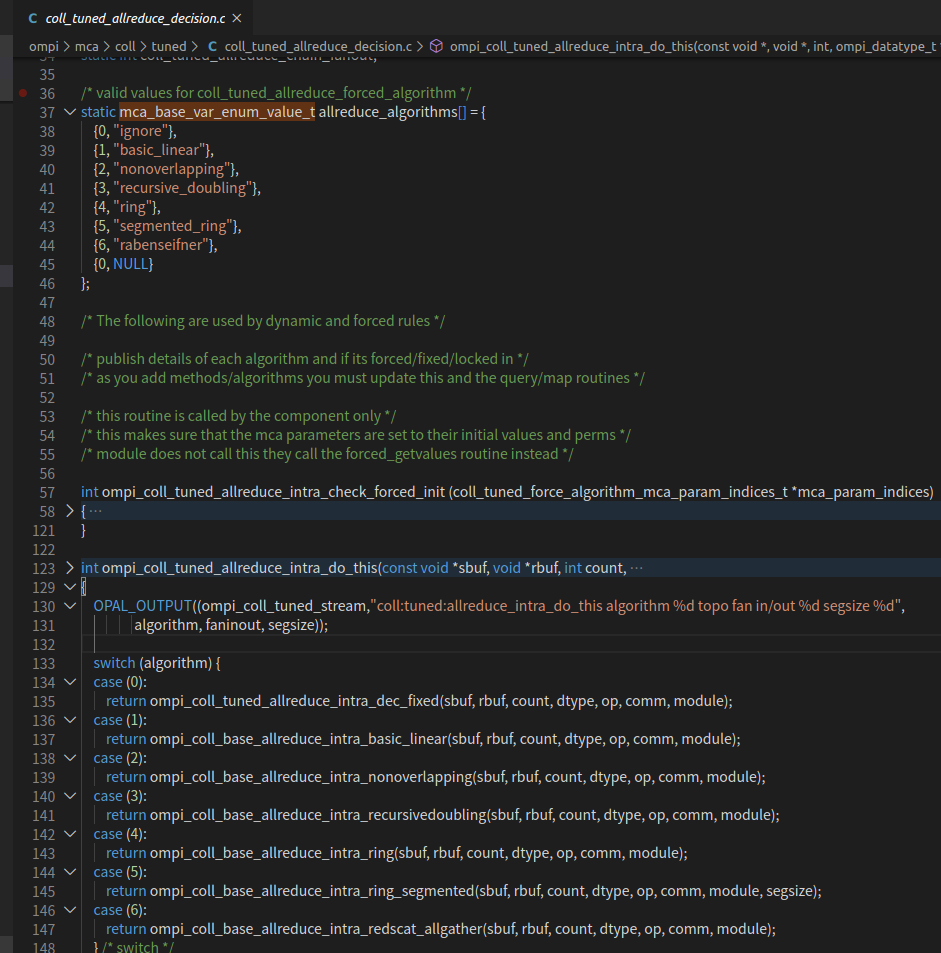
在深度学习分布式训练环境下,ring all reduce算法是比较优秀的,能充分利用节点带宽,降低时间。关于这些算法的更具体的比较和分析,可以参考:腾讯机智团队分享–AllReduce算法的前世今生
3.3.2 NCCL All reduce
英伟达于2015年公开发布NCCL,一个开源的、基于自身硬件的闭源的集合通信库实现。其算法基本实现原理,和mpi的实现是基本类似的,由于其完全基于自家硬件,可以进行充分的优化,所以基于nvidia-gpu时,使用nccl性能是很强的,真香!
NCCL VS MPI
NCCL沿袭了MPI,定义了一系列名称不同但功能类似的通信方法,针对GPU部分常用的接口做了比较大的优化,一起其他的则没有实现,有点类似于MPI的一个对GPU通信支持的很强的子集,不过并没有用MPI统一的接口。我们通过NCCL官方文档Overview和NCCL and MPI可以看出:
1.NCCL是一个实现了多GPU间集合通信原语的库
这些库具有拓扑感知的功能,易于集成到应用程序中。NCCL的集合通信算法采用了许多协调工作的处理器来聚合数据;
2.NCCL并不是一个成熟的集合通信框架,其更像是一个lib库
用于实现和加速集合通信的一些源语,NCCL当前支持以下集合通信操作:
- AllReduce
- Broadcast
- Reduce
- AllGather
- ReduceScatter
3.NCCL可轻松与MPI结合使用。
NCCL类似于MPI,因此,从MPI通信实现中创建NCCL通信实现非常简单。因此,很容易将MPI用于CPU到CPU的通信,将NCCL用于GPU到GPU的通信(但是,在MPI程序中使用NCCL时,MPI中的一些实现细节可能导致问题,譬如死锁)。
3.3.3 百度Ring Allreduce
尽管在MPI的各种实现中(譬如OpenMPI),很早就有了优秀的Ring All reduce算法,不过将其引入到深度学习中,还是百度首创的。百度2016年在论文:Bringing HPC Techniques to Deep Learning中介绍了一种来自高性能分布式计算中的概念——Ring All reduce,并将其引入了深度学习(给tensorflow贡献了代码,增加了基于mpi源语实现的ring all reduce),且获得了显著的性能提升。
可参考知乎:[翻译] Bringing HPC Techniques to Deep Learning
代码:https://github.com/baidu-research/baidu-allreduce
3.3.4 其他All reduce
- 基于double binary tree的all reduce
《Two-Tree Algorithms for Full BandwidthBroadcast, Reduction and Scan》
double binary tree于2009年在MPI中引入,并随后在NCCL2.4中也引入了此实现:https://developer.nvidia.com/blog/massively-scale-deep-learning-training-nccl-2-4/#ref3
- 分层ring all reduce
《Highly Scalable Deep Learning Training System with Mixed-Precision: Training ImageNet in Four Minutes》
- 基于spanning tree的all reduce
《Blink: Fast and Generic Collectives for Distributed ML》