免费送书啦!《深度学习训练营21天实战》
点击上方“人工智能与算法学习”,选择“星标”
干货第一时间送达
简介
本书基于TensorFlow、Keras和scikit-learn,介绍了21个典型的人工智能应用场景。全书共3篇,分别是预测类项目实战篇、识别类项目实战篇和生成类项目实战篇。其中预测类项目包括房价预测、泰坦尼克号生还预测、共享单车使用情况预测、福彩3D中奖预测、股票走势预测等8个项目;识别类项目包括数字识别、人脸识别、表情识别、人体姿态识别等7个项目;生成类项目包括看图写话、生成电视剧剧本、风格迁移、生成人脸等6个项目。

内容预览
基于Keras实现房价预测
本文章将使用神经网络模型来实现房价预测,使用的是TensorFlow下的Keras的API代码。我们将使用Keras创建模型、训练模型、预测和对比图预览。
Keras封装了一套高级的API用来构建深度学习模型,常用于快速实现原型和高级搜索;得益于Keras对开发者的友好性、模块化、可组合性和易于扩展的关键特征,使得Keras成为目前使用是较为广泛的深度学习开源框架,它的backend之一就是TensorFlow。Keras在2015年12月份就将其的TensorFlow的backend的API部分融合到了TensorFlow框架中,所以目前我们可以通过tf.keras或者独立的Keras库来使用它。
一、数据准备
通过TensorFlow提供的Keras接口下的datasets模块来加载数据,数据集是由卡内基梅隆大学维护的,它来自波士顿近郊房价数据。读者也可以在本书中1.1小节的介绍中的链接去查看后续更新的数据集。在tf.keras.datasets下加载的数据集和在链接中看到的数据集是一样格式的,只是年代不同。加载数据集代码如下:
import tensorflow as tf
# 从TensorFlow导入Keras模块
from tensorflow import keras
import numpy as np
# 加载波士顿的房价数据
(train_data, train_labels), (test_data, test_labels) = \
keras.datasets.boston_housing.load_data()
# 清洗训练集数据
# np.random.random()表示在0.0到1.0之间返回指定个数的随机浮点数
# np.argsort()表示返回对数组进行排序的索引
order = np.argsort(np.random.random(train_labels.shape))
train_data = train_data[order]
train_labels = train_labels[order]
# 归一化处理数据
# 对不同的范围和比例进行归一化处理,并且每个元素都要减去均值除以标准差
# 模型虽然在没有特征归一化时也可以得到收敛,但是这会让训练更加困难,
# 而且会是结果模型很依赖于训练数据
mean = train_data.mean(axis=0)
std = train_data.std(axis=0)
train_data = (train_data - mean) / std
test_data = (test_data - mean) / std
print("train_data.shape: {}, train_labels.shape: {}."
.format(train_data.shape, train_labels.shape))
print("test_data.shape: {}, test_labels.shape: {}."
.format(test_data.shape, test_labels.shape))
输出为:
train_data.shape: (404, 13), train_labels.shape: (404,).
test_data.shape: (102, 13), test_labels.shape: (102,).
二、创建神经网络模型
在Keras中,我们创建神经网络模型,就是使用Sequential类来创建Keras模型。本次创建的模型比较简单,通过Dense类来创建神经网络层;对于输入层,层的深度是64个units,输入层必须传入input_shape参数,表示的是输入数据的特征维度的大小。
激活函数(activation),我们指定的是修正线性单元(ReLU),它是神经网络中最常用的激活函数。当输入的值为正数时,导数不为0,返回它本身,这就允许在训练模型时进行基于梯度的学习,也会使计算变得更快。当输入的值为负数时,学习速度可能会变得很慢,甚至会使神经元直接失效;这是因为输入的值是小于0的值,计算它的梯度也为0,从而使其权重无法得到更新,那么在传播到下一个神经网络层的时候,返回的值为0就没有什么意义了。
然后我们再添加一个隐藏层,这一层不需要input_shape参数了,因为在第一层时已经指定了;我们仍然设置是64个units,激活函数是ReLu。
输出层只有一个unit,代码如下:
# 定义创建模型函数
def build_model():
model = keras.Sequential([
keras.layers.Dense(64, activation=tf.nn.relu,
input_shape=(train_data.shape[1],)),
keras.layers.Dense(64, activation=tf.nn.relu),
keras.layers.Dense(1)
])
# 使用RMSProp(均方根传播)优化器,它可以加速梯度下降,其中学习速度适用于每个参数
optimizer = tf.train.RMSPropOptimizer(0.001)
# mse(均方差)一般用在回归问题的损失函数
# mae(平均绝对误差)也是一般用在回归问题的测量/评估上
model.compile(loss='mse', optimizer=optimizer, metrics=['mae'])
return model
model = build_model()
# 查看模型的架构
model.summary()
输出模型架构,如图所示。全部的参数有5,121个,模型中的每一层参数都可以在表格的Param列看到;每一层的输出大小就是Output Shape,其中None表示是可变的batch size,它会在训练模型或者模型预测时被自动填充上具体的值。

图1 一个简单的Keras模型架构图
三、训练网络模型
这个模型我们训练500次,并且将训练精确度和验证精确度记录在history对象中,以便于下面的绘图预览。我们自定义一个回调对象类,重写了on_epoch_end()方法,该方法会在每次epoch结束时调用。代码如下:
# 自定义一个回调类,在每次epoch(代)结束时都会调用该函数
class PrintDot(keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs):
if epoch % 100 == 0: print('')
print('.', end='')
EPOCHS = 500
# 训练模型
# 参数1:房屋特征数据
# 参数2:房屋价格数据
# 参数3:epochs,迭代次数
# 参数4:validation_split,表示验证集分割比例,0.2表示20%的数据用于验证,80%的数据用于训练
# 参数5:verbose,表示输出打印日志信息,0表示不输出打印任何日志信息
# 参数6:callbacks,回调对象,这里我们使用自定义的回调类PrintDot
history = model.fit(train_data, train_labels, epochs=EPOCHS,
validation_split=0.2, verbose=0,
callbacks=[PrintDot()])
四、可视化模型的结果
通过history对象,我可以读取到该模型训练时的误差数值,以便于来决定何时是最佳模型,何时应该停止训练。
import matplotlib.pyplot as plt
# 绘制图来显示训练时的accuracy和loss
def plot_history(history):
plt.figure()
plt.xlabel('Epoch')
plt.ylabel('Mean Abs Error [1000$]')
plt.plot(history.epoch, np.array(history.history['mean_absolute_error']),
label='Train Loss')
plt.plot(history.epoch, np.array(history.history['val_mean_absolute_error']),
label='Val loss')
plt.legend()
plt.ylim([0, 5])
plt.show()
plot_history(history)
输出如图2所示。
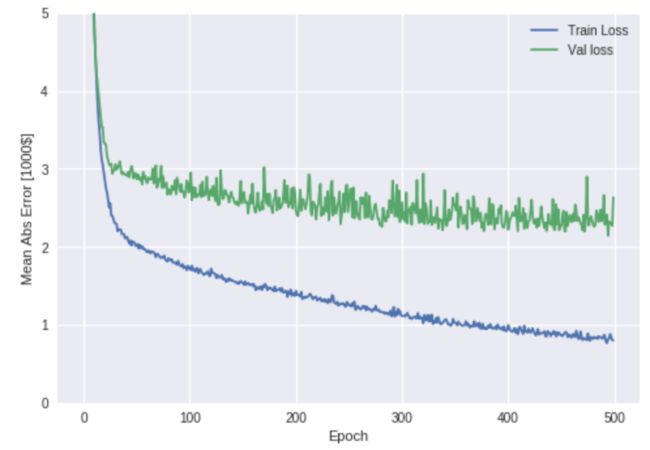
图12 训练模型时的平均绝对误差表现图
通过这个曲线图来看,大约在150到200次迭代时,训练损失值就没有怎么降低了。所以,这里我们用到一个降低过拟合技术叫做:早期停止(EarlyStopping),它会在指定的迭代次数时,如果依旧没有损失降低,模型性能提升的话,则自动终止训练。
我们重新构建和训练该模型,在重新构建模型前,请先清除Keras的内存状态,最简单的办法就是重新运行Jupyter Notebook整个环境;如果使用终端的话,就重新启动该脚本程序。代码如下:
# 重新构建模型
model = build_model()
# 设置早期停止,如果20次的迭代依旧没有降低验证损失,则自动停止训练
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=20)
# 重新训练模型,此时的callbacks有两个回调函数,所以我们使用数组的形式传入它们
history = model.fit(train_data, train_labels, epochs=EPOCHS,
validation_split=0.2, verbose=0,
callbacks=[early_stop, PrintDot()])
# 打印输出历史记录的曲线图
plot_history(history)
输出如图3所示。
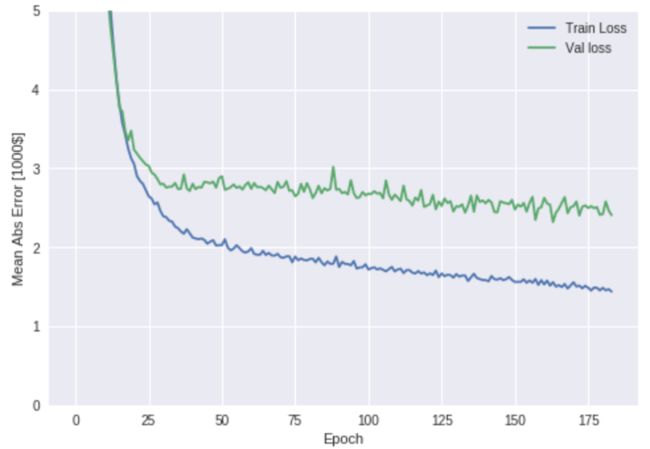
图3 训练和验证模型时的平均绝对误差图,使用早期停止技术
五、评估和预测模型
接下来,我们来测试下模型在测试集下的表现,这就需要对模型进行评估了。通过evaluate()函数,传入测试房屋特征数据集,测试房屋价格数据,计算测试集的平均绝对误差。代码如下:
[loss, mae] = model.evaluate(test_data, test_labels, verbose=0)
print("Testing set Mean Abs Error: ${:7.2f}".format(mae * 1000))
输出日志为:
Testing set Mean Abs Error: $2930.86
然后,预测模型,通过predict()函数,传入测试房屋特征数据集,返回预测到的房屋价格;最后将这个返回的数据通过flatten()函数扁平化处理,以便于在绘制的散点图中显示。代码如下:
# 使用测试集数据预测模型
test_predictions = model.predict(test_data).flatten()
plt.scatter(test_labels, test_predictions)
plt.xlabel('True Values [1000$]')
plt.ylabel('Predictions [1000$]')
plt.axis('equal')
plt.xlim(plt.xlim())
plt.ylim(plt.ylim())
plt.plot([-100, 100], [-100, 100])
plt.show()
输出如图5所示。
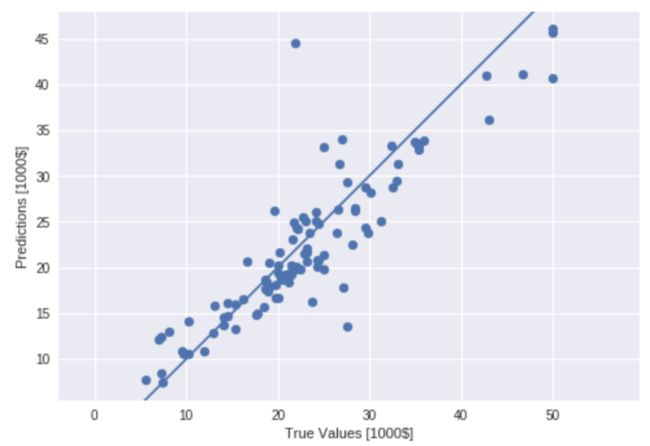
图5 预测房价的回归模型图
六、预测可视化显示
接下来,我们来看下真实的房屋价格数据和预测到的房屋价格数据对比,形成价格差的直方图。那我们就使用预测到的房价减去真实房价所得的差价,代码如下:
error = test_predictions - test_labels
plt.hist(error, bins=50)
plt.xlabel("Prediction Error [1000$]")
plt.ylabel("Count")
plt.show()
输出如图6所示。

图6 预测的房价减去真实的房价产生的房屋差价图
最后,我们再通过真实房价和预测的房价生成一张更直观的图来显示。函数plotVersusFigure()在上面的代码中已经定义过,这里就不再写了,代码如下:
plotVersusFigure(test_labels, test_predictions)
输出如图7所示。
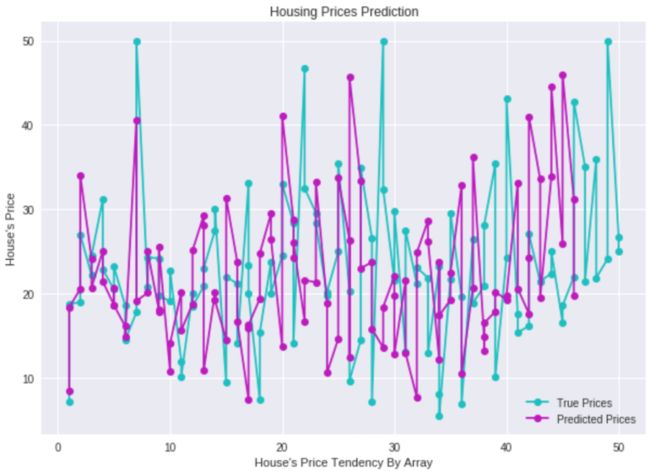
图7 真实房价与预测房价的对比图
通过以上分析,不管是用Scikit-learn的机器学习库来预测房价,还是使用Keras的神经网络模型来预测房价,真实的房价和预测的房价总是有些误差。所以我们能控制的就是在训练神经网络模型时,调整训练的超参数、迭代次数、网络层数和优化器等参数,以达到更好的适用于该房屋数据的预测模型。这里的数据量比较小,如果数据量更大一些,模型效果会更好。
---------- 本文章摘自《深度学习训练营 21天实战》一书中,经授权发布。

如果你对深度学习感兴趣
请在评论区留言
截止9月28日晚上8点
留言集赞最多的4位同学各赠一本
《深度学习训练营21天实践》



觉得有用,麻烦给个赞和在看~ 