在 Spark Streaming 中,DStreamGraph 是一个非常重要的组件,主要用来:
- 通过成员 inputStreams 持有 Spark Streaming 输入源及接收数据的方式
- 通过成员 outputStreams 持有 Streaming app 的 output 操作,并记录 DStream 依赖关系
- 生成每个 batch 对应的 jobs
下面,我将通过分析一个简单的例子,结合源码分析来说明 DStreamGraph 是如何发挥作用的。例子如下:
val sparkConf = new SparkConf().setAppName("HdfsWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(2))
val lines = ssc.textFileStream(args(0))
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
创建 DStreamGraph 实例
代码val ssc = new StreamingContext(sparkConf, Seconds(2))创建了 StreamingContext 实例,StreamingContext 包含了 DStreamGraph 类型的成员graph,graph 在 StreamingContext主构造函数中被创建,如下
private[streaming] val graph: DStreamGraph = {
if (isCheckpointPresent) {
cp_.graph.setContext(this)
cp_.graph.restoreCheckpointData()
cp_.graph
} else {
require(batchDur_ != null, "Batch duration for StreamingContext cannot be null")
val newGraph = new DStreamGraph()
newGraph.setBatchDuration(batchDur_)
newGraph
}
}
可以看到,若当前 checkpoint 可用,会优先从 checkpoint 恢复 graph,否则新建一个。还可以从这里知道的一点是:graph 是运行在 driver 上的
DStreamGraph记录输入源及如何接收数据
DStreamGraph有和application 输入数据相关的成员和方法,如下:
private val inputStreams = new ArrayBuffer[InputDStream[_]]()
def addInputStream(inputStream: InputDStream[_]) {
this.synchronized {
inputStream.setGraph(this)
inputStreams += inputStream
}
}
成员inputStreams为 InputDStream 类型的数组,InputDStream是所有 input streams(数据输入流) 的虚基类。该类提供了 start() 和 stop()方法供 streaming 系统来开始和停止接收数据。那些只需要在 driver 端接收数据并转成 RDD 的 input streams 可以直接继承 InputDStream,例如 FileInputDStream是 InputDStream 的子类,它监控一个 HDFS 目录并将新文件转成RDDs。而那些需要在 workers 上运行receiver 来接收数据的 Input DStream,需要继承 ReceiverInputDStream,比如 KafkaReceiver。
我们来看看val lines = ssc.textFileStream(args(0))调用。
为了更容易理解,我画出了val lines = ssc.textFileStream(args(0))的调用流程

从上面的调用流程图我们可以知道:
- ssc.textFileStream会触发新建一个FileInputDStream。FileInputDStream继承于InputDStream,其start()方法定义了数据源及如何接收数据
- 在FileInputDStream构造函数中,会调用
ssc.graph.addInputStream(this),将自身添加到 DStreamGraph 的inputStreams: ArrayBuffer[InputDStream[_]]中,这样 DStreamGraph 就知道了这个 Streaming App 的输入源及如何接收数据。可能你会奇怪为什么inputStreams 是数组类型,举个例子,这里再来一个val lines1 = ssc.textFileStream(args(0)),那么又将生成一个 FileInputStream 实例添加到inputStreams,所以这里需要集合类型 - 生成FileInputDStream调用其 map 方法,将以 FileInputDStream 本身作为 partent 来构造新的 MappedDStream。对于 DStream 的 transform 操作,都将生成一个新的 DStream,和 RDD transform 生成新的 RDD 类似
与MappedDStream 不同,所有继承了 InputDStream 的定义了输入源及接收数据方式的 sreams 都没有 parent,因为它们就是最初的 streams。
DStream 的依赖链
每个 DStream 的子类都会继承 def dependencies: List[DStream[_]] = List()方法,该方法用来返回自己的依赖的父 DStream 列表。比如,没有父DStream 的 InputDStream 的 dependencies方法返回List()。
MappedDStream 的实现如下:
class MappedDStream[T: ClassTag, U: ClassTag] (
parent: DStream[T],
mapFunc: T => U
) extends DStream[U](parent.ssc) {
override def dependencies: List[DStream[_]] = List(parent)
...
}
在上例中,构造函数参数列表中的 parent 即在 ssc.textFileStream 中new 的定义了输入源及数据接收方式的最初的 FileInputDStream实例,这里的 dependencies方法将返回该FileInputDStream实例,这就构成了第一条依赖。可用如下图表示,这里特地将 input streams 用蓝色表示,以强调其与普通由 transform 产生的 DStream 的不同:

继续来看val words = lines.flatMap(_.split(" ")),flatMap如下:
def flatMap[U: ClassTag](flatMapFunc: T => Traversable[U]): DStream[U] = ssc.withScope {
new FlatMappedDStream(this, context.sparkContext.clean(flatMapFunc))
}
每一个 transform 操作都将创建一个新的 DStream,flatMap 操作也不例外,它会创建一个FlatMappedDStream,FlatMappedDStream的实现如下:
class FlatMappedDStream[T: ClassTag, U: ClassTag](
parent: DStream[T],
flatMapFunc: T => Traversable[U]
) extends DStream[U](parent.ssc) {
override def dependencies: List[DStream[_]] = List(parent)
...
}
与 MappedDStream 相同,FlatMappedDStream#dependencies也返回其依赖的父 DStream,及 lines,到这里,依赖链就变成了下图:

之后的几步操作不再这样具体分析,到生成wordCounts时,依赖图将变成下面这样:
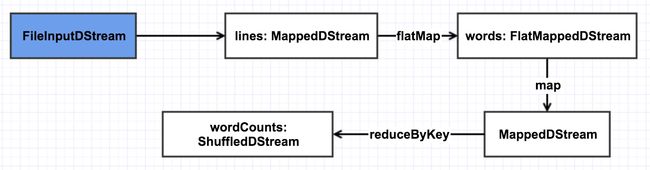
在 DStream 中,与 transofrm 相对应的是 output 操作,包括 print, saveAsTextFiles, saveAsObjectFiles, saveAsHadoopFiles, foreachRDD。output 操作中,会创建ForEachDStream实例并调用register方法将自身添加到DStreamGraph.outputStreams成员中,该ForEachDStream实例也会持有是调用的哪个 output 操作。本例的代码调用如下,只需看箭头所指几行代码
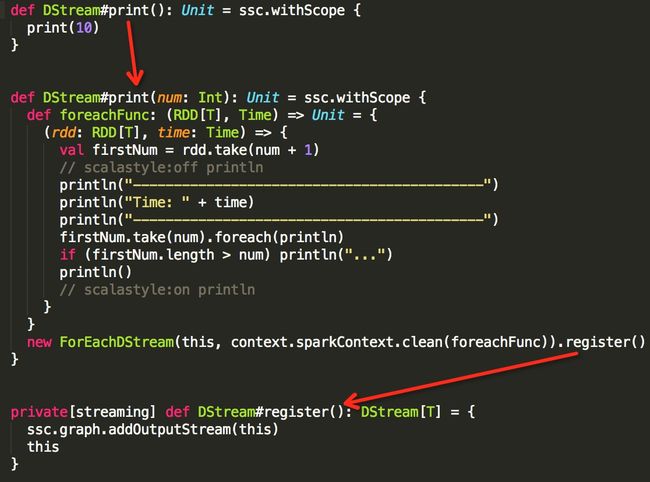
与 DStream transform 操作返回一个新的 DStream 不同,output 操作不会返回任何东西,只会创建一个ForEachDStream作为依赖链的终结。
至此, 生成了完成的依赖链,也就是 DAG,如下图(这里将 ForEachDStream 标为黄色以显示其与众不同):
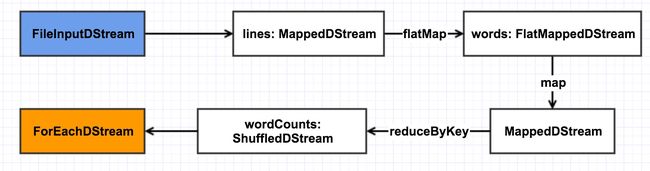
这里的依赖链又叫 DAG。本文以一个简单的例子说明 DStream DAG 的生成过程,之后将再写两篇文章说明如何根据这个 DStream DAG 得到 RDD DAG 及如何定时生成 job。