第二章 Tomcat源码分析—从启动流程到请求处理笔记
Tomcat 8.5下载地址
https://tomcat.apache.org/download-80.cgi
一、Tomcat启动流程
1、Tomcat源码目录
catalina目录:apache-tomcat-8.5.42-src\java\org\apache\catalina
catalina包含所有的Servlet容器实现,以及涉及到安全、会话、集群、部署管理Servlet容器的各个方面,同时它还包含了启动入口。
coyote目录:apache-tomcat-8.5.42-src\java\org\apache\coyote
coyote是Tomcat链接器框架的名称,是Tomcat服务器提供的客户端访问的外部接口,客户端通过Coyote与服务器建立链接、发送请求并接收响应。
El目录(org.apache.el),提供java表达式语言:
- Jasper模块提供JSP引擎
- Naming模块提供JNDI的服务
- Juli提供服务器日志的服务
- tomcat提供外部调用的接口api
2、Tomcat启动流程分析
2.1、启动流程解析:
注意是标准的启动,也就是从bin目录下的启动文件中启动Tomcat
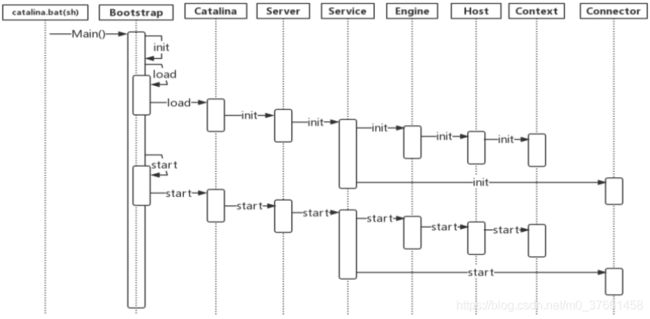
我们可以看到这个流程非常的清晰,同时注意到,Tomcat的启动非常的标准,除去Boostrap和Catalin,我们可以对照一下Server.xml的配置文件。Server,service等等这些组件都是一一对照,同时又有先后顺序。
基本的顺序是先init方法,然后再start方法。
2.2、加入调试信息():
注意是标准的启动,也就是从bin目录下的启动文件中启动Tomcat


可以看到,在源码中加入调试的信息和流程图是一致的。
我们可以看到,除了Bootstrap和catalina类,其他的Server、service等等之类的都只是一个接口,实现类均为StandardXXX类。我们来看下StandardServer类:

问题来了,我们发现StandardServer类中没有init方法,只有一个类似于init的initInternal方法,这个是为什么?带着问题我们进入下面的内容。
二、组件的生命周期管理
1、各种组件如何统一管理
Tomcat的架构设计是清晰的、模块化、它拥有很多组件,加入在启动Tomcat时一个一个组件启动,很容易遗漏组件,同时还会对后面的动态组件拓展带来麻烦。如果采用我们传统的方式的话,组件在启动过程中如果发生异常,会很难管理,比如你的下一个组件调用了start方法,但是如果它的上级组件还没有start甚至还没有init的话,Tomcat的启动会非常难管理,因此Tomcat的设计者提出一个解决方案:用Lifecycle管理启动、停止、关闭。
2、生命周期统一接口—Lifecycle
Tomcat内部架构中各个核心组件有包含与被包含关系,例如:Server包含了Service.Service又包含了Container和Connector,这个结构有一点像数据结构中的树,树的根结点没有父节点,其他节点有且仅有一个父节点,每一个父节点有0至多个子节点。所以,我们可以通过父容器启动它的子容器,这样只要启动根容器,就可以把其他所有的容器都启动,从而达到了统一的启动,停止、关闭的效果。
所有组件有一个统一的接口——Lifecycle,把所有的启动、停止、关闭、生命周期相关的方法都组织到一起,就可以很方便管理Tomcat各个容器组件的生命周期。
Lifecycle其实就是定义了一些状态常量和几个方法,主要方法是init、start、stop三个方法。
例如:Tomcat的Server组件的init负责遍历调用其包含所有的Service组件的init方法。
注意:Server只是一个接口,实现类为StandardServer,有意思的是StandardServer没有init方法,init方法是在哪里,其实是在它的父类LifecycleBase中,这个类就是统一的生命周期管理。
public final class StandardServer extends LifecycleMBeanBase implements Server {
public abstract class LifecycleMBeanBase extends LifecycleBase implements JmxEnabled {
@Override
public final synchronized void init() throws LifecycleException {
//这个就是为了防止 组件启动的顺序不对
if (!state.equals(LifecycleState.NEW)) {
invalidTransition(Lifecycle.BEFORE_INIT_EVENT);
}
try { //只打印核心组件
if(this.getClass().getName().startsWith("org.apache.catalina.core")
|| this.getClass().getName().startsWith("org.apache.catalina.connector")){
System.out.println(this.getClass()+"--init()");
}
setStateInternal(LifecycleState.INITIALIZING, null, false);
initInternal();
setStateInternal(LifecycleState.INITIALIZED, null, false);
} catch (Throwable t) {
ExceptionUtils.handleThrowable(t);
setStateInternal(LifecycleState.FAILED, null, false);
throw new LifecycleException(sm.getString("lifecycleBase.initFail",toString()), t);
}
}
protected abstract void initInternal() throws LifecycleException;
所以StandardServer最终只会调用到initInternal方法,这个方法会初始化子容器Service的init方法
// class loaders
if (getCatalina() != null) {
ClassLoader cl = getCatalina().getParentClassLoader();
// Walk the class loader hierarchy. Stop at the system class loader.
// This will add the shared (if present) and common class loaders
while (cl != null && cl != ClassLoader.getSystemClassLoader()) {
if (cl instanceof URLClassLoader) {
URL[] urls = ((URLClassLoader) cl).getURLs();
for (URL url : urls) {
if (url.getProtocol().equals("file")) {
try {
File f = new File (url.toURI());
if (f.isFile() && f.getName().endsWith(".jar")) {
ExtensionValidator.addSystemResource(f);
}
} catch (URISyntaxException e) {
// Ignore
} catch (IOException e) {
// Ignore
}
}
}
}
cl = cl.getParent();
}
}
// Server组件中的init方法负责遍历所有的子容器service组件的init方法
for (int i = 0; i < services.length; i++) {
services[i].init();
}为什么LifecycleBase这么玩,其实很多架构源码都是这么玩的,包括JDK的容器源码都是这么玩的,一个类有一个接口,同时抽象一个抽象骨架类,把通用的实现放在抽象骨架类中,这样设计就方便组件的管理,使用LifecycleBase骨架抽象类,在抽象方法中就可以进行统一的处理,具体的内容见下面。
抽象类LifecycleBase统一管理组件生命周期:
@Override
public final synchronized void init() throws LifecycleException {
//初始化统一的状态验证,这个就是为了防止组件启动的顺序不对
if (!state.equals(LifecycleState.NEW)) {
invalidTransition(Lifecycle.BEFORE_INIT_EVENT);
}
try {// 只打印核心组件
if(this.getClass().getName().startsWith("org.apache.catalina.core")
|| this.getClass().getName().startsWith("org.apache.catalina.connector")){
System.out.println(this.getClass()+"--init()");
}
setStateInternal(LifecycleState.INITIALIZING, null, false);
initInternal();
setStateInternal(LifecycleState.INITIALIZED, null, false);
} catch (Throwable t) {
ExceptionUtils.handleThrowable(t);
setStateInternal(LifecycleState.FAILED, null, false);
throw new LifecycleException(sm.getString("lifecycleBase.initFail",toString()), t);
}
}Start方法:
@Override
public final synchronized void start() throws LifecycleException {
// 统一的生命周期组件的状态验证
if (LifecycleState.STARTING_PREP.equals(state) || LifecycleState.STARTING.equals(state) ||
LifecycleState.STARTED.equals(state)) {
if (log.isDebugEnabled()) {
Exception e = new LifecycleException();
log.debug(sm.getString("lifecycleBase.alreadyStarted", toString()), e);
} else if (log.isInfoEnabled()) {
log.info(sm.getString("lifecycleBase.alreadyStarted", toString()));
}
return;
}
if (state.equals(LifecycleState.NEW)) {
init();
} else if (state.equals(LifecycleState.FAILED)) {
stop();
} else if (!state.equals(LifecycleState.INITIALIZED) &&
!state.equals(LifecycleState.STOPPED)) {
invalidTransition(Lifecycle.BEFORE_START_EVENT);
}
try {
//只打印核心组件
if(this.getClass().getName().startsWith("org.apache.catalina.core")||this.getClass().getName().startsWith("org.apache.catalina.connector")){
System.out.println(this.getClass()+"--start()");
}
setStateInternal(LifecycleState.STARTING_PREP, null, false);
startInternal();
if (state.equals(LifecycleState.FAILED)) { // 启动完成后状态验证
// This is a 'controlled' failure. The component put itself into the
// FAILED state so call stop() to complete the clean-up.
stop();
} else if (!state.equals(LifecycleState.STARTING)) {
// Shouldn't be necessary but acts as a check that sub-classes are
// doing what they are supposed to.
invalidTransition(Lifecycle.AFTER_START_EVENT);
} else {
setStateInternal(LifecycleState.STARTED, null, false);
}
} catch (Throwable t) {
// This is an 'uncontrolled' failure so put the component into the
// FAILED state and throw an exception.
ExceptionUtils.handleThrowable(t);
setStateInternal(LifecycleState.FAILED, null, false);
throw new LifecycleException(sm.getString("lifecycleBase.startFail", toString()), t);
}
}具体实现类StandardXXX类调用initInternal方法实现具体的业务处理。
三、分析Tomcat请求过程
1、解耦:网络协议与容器的解耦。
Connector链接器封装了底层的网络请求(Socket请求及相应处理),提供了统一的接口,使Container容器与具体的请求协议以及I/O方式解耦。
Connector将Socket输入转换成Request对象,交给Container容器进行处理,处理请求后,Container通过Connector提供的Response对象将结果写入输出流。
因为无论是Request对象还是Response对象都没有实现Servlet规范对应的接口,Container会将它们进一步分装成ServletRequest和ServletResponse。
问题来了,在Engine容器中,有四个级别的容器,他们的标准实现分别是StandardEngine、StandardHost、StandardContext、StandardWrapper。
2、Host设计的目的
Tomcat诞生时,服务器资源很贵,所以一般一台服务器其实可以有多个域名映射,满了满足这种需求,比如,我的这台电脑,有一个localhost域名,同时在我的hosts文件中配置两个域名,一个www.a.com 一个localhost。
3、Context设计的目的
container从上一个组件connector手上接过解析好的内部request,根据request来进行一系列的逻辑操作,直到调用到请求的servlet,然后组装好response,返回给connecotr。
先来看看container的分类吧:Engine、Host、Context、Wrapper。
它们各自的实现类分别是StandardEngine, StandardHost, StandardContext, and StandardWrapper,他们都在tomcat的org.apache.catalina.core包下。
它们之间的关系,可以查看tomcat的server.xml也能明白(根据节点父子关系),这么比喻吧:除了Wrapper最小,不能包含其他container外,Context内可以有零或多个Wrapper,Host可以拥有零或多个Context,Engine可以有零到多个Host。
Standard的container都是直接继承抽象类:org.apache.catalina.core.ContainerBase:
4、Tomcat处理一个HTTP请求的过程
用户点击网页内容,请求被发送到本机端口8080,被在那里监听的Coyote HTTP/1.1 Connector获得。
- Connector把该请求交给它所在的Service的Engine来处理,并等待Engine的回应。
- Engine获得请求localhost/test/index.jsp,匹配所有的虚拟主机Host。
- Engine匹配到名为localhost的Host(即使匹配不到也把请求交给该Host处理,因为该Host被定义为该Engine的默认主机),名为localhost的Host获得请求/test/index.jsp,匹配它所拥有的所有的Context。Host匹配到路径为/test的Context(如果匹配不到就把该请求交给路径名为“ ”的Context去处理)。
- path=“/test”的Context获得请求/index.jsp,在它的mapping table中寻找出对应的Servlet,Context匹配到URL PATTERN为*.jsp的Servlet,对应于JspServlet类。
- 构造HttpServletRequest对象和HttpServletResponse对象,作为参数调用JspServlet的doGet()或doPost()执行业务逻辑、数据存储等程序。
- Context把执行完之后的HttpServletResponse对象返回给Host。
- Host把HttpServletResponse对象返回给Engine。
- Engine把HttpServletResponse对象返回Connector。
- Connector把HttpServletResponse对象返回给客户Browser。
四、管道模式
1、管道与阀门
在一个比较复杂的大型系统中,如果一个对象或数据流需要进行繁杂的逻辑处理,我们可以选择在一个大的组件中直接处理这些繁杂的逻辑处理,这个方式虽然达到目的,但是拓展性和可重用性差,因为牵一发而动全身。
管道是就像一条管道把多个对象连接起来,整体看起来就像若干个阀门嵌套在管道中,而处理逻辑放在阀门上。 它的结构和实现是非常值得我们学习和借鉴的。
首先要了解的是每一种container都有一个自己的StandardValve
上面四个container对应的四个是:
StandardEngineValve、StandardHostValve、StandardContextValve、StandardWrapperValve
Pipeline就像一个工厂中的生产线,负责调配工人(valve)的位置,valve则是生产线上负责不同操作的工人。
一个生产线的完成需要两步:
- 把原料运到工人边上。
- 工人完成自己负责的部分。
而tomcat的Pipeline实现是这样的:
- 在生产线上的第一个工人拿到生产原料后,二话不说就人给下一个工人,下一个工人模仿第一个工人那样扔给下一个工人,直到最后一个工人,而最后一个工人被安排为上面提过的StandardValve,他要完成的工作居然是把生产资料运给自己包含的container的Pipeline上去。
- 四个container就相当于有四个生产线(Pipeline),四个Pipeline都这么干,直到最后的StandardWrapperValve拿到资源开始调用servlet。完成后返回来,一步一步的valve按照刚才丢生产原料是的顺序的倒序一次执行。如此才完成了tomcat的Pipeline的机制。
2、手写管道模式实现
具体代码见工程代码,通过一个简单的demo,我们了解到了,在管道中连接一个或者多个阀门,每一个阀门负责一部分逻辑处理,数据按照规定的顺序往下流。此种模式分解了逻辑处理任务,可方便对某个任务单元进行安装、拆卸,提高流程的可拓展性,可重用性,机动性,灵活性。
3、源码分析
在CoyoteAdapter的service方法里,由下面这一句就进入Container的,connector.getContainer().getPipeline().getFirst().invoke(request, response); 是的,这就是进入container迷宫的大门,欢迎来到Container。
// 调用容器---责任链模式(pipeline)的开始(CoyoteAdapter类343行)
connector.getService().getContainer().getPipeline().getFirst().invoke(request, response);
一个StandardValve来自org.apache.catalina.core.StandardEngineValve的invoke方法:
@Override
public final void invoke(Request request, Response response)
throws IOException, ServletException {
// 拿到Engine中包含的host
Host host = request.getHost();
if (host == null) {
response.sendError(HttpServletResponse.SC_BAD_REQUEST,
sm.getString("standardEngine.noHost",request.getServerName()));
return;
}
if (request.isAsyncSupported()) {
request.setAsyncSupported(host.getPipeline().isAsyncSupported());
}
// 最为自己pipeline上最后一位工人,负责把原料运给下一个pipeline
// 这是把所有pipeline串联起来的关键
host.getPipeline().getFirst().invoke(request, response);
}其他的类似StandardHostValve、StandardContextValve、StandardWrapperValve
4、Tomcat中定制阀门
管道机制给我们带来了更好的拓展性,例如,你要添加一个额外的逻辑处理阀门是很容易的。
1)自定义个阀门PrintIPValve,只要继承ValveBase并重写invoke方法即可。注意在invoke方法中一定要执行调用下一个阀门的操作,否则会出现异常。
public class PrintIPValve extends ValveBase {
@Override
public void invoke(Request request, Response response) throws IOException, ServletException {
System.out.println("---自定义阀门PrintIPValve-----"+request.getRemoteAddr());
getNext().invoke(request,response);//这个必须写,不写有问题
}2)配置Tomcat的核心配置文件server.xml,这里把阀门配置到Engine容器下,作用范围就是整个引擎,也可以根据作用范围配置在Host或者是Context下
3)源码中是直接可以有效果,但是如果是运行版本,则可以将这个类导出成一个Jar包放入Tomcat/lib目录下,也可以直接将.class文件打包进catalina.jar包中。
5、Tomcat中提供常用的阀门
AccessLogValve:请求访问日志阀门,通过此阀门可以记录所有客户端的访问日志,包括远程主机IP,远程主机名,请求方法,请求协议,会话ID,请求时间,处理时长,数据包大小等。它提供任意参数化的配置,可以通过任意组合来定制访问日志的格式。
JDBCAccessLogValve:同样是记录访问日志的阀门,但是它有助于将访问日志通过JDBC持久化到数据库中。
ErrorReportValve:这是一个讲错误以HTML格式输出的阀门
PersistentValve:这是对每一个请求的会话实现持久化的阀门
RemoteAddrValve:访问控制阀门。可以通过配置决定哪些IP可以访问WEB应用
RemoteHostValve:访问控制阀门,通过配置觉得哪些主机名可以访问WEB应用
RemoteIpValve:针对代理或者负载均衡处理的一个阀门,一般经过代理或者负载均衡转发的请求都将自己的IP添加到请求头”X-Forwarded-For”中,此时,通过阀门可以获取访问者真实的IP。
SemaphoreValve:这个是一个控制容器并发访问的阀门,可以作用在不同容器上。