全景分割论文阅读:MaX-Deeplab:End-to-End Panoptic Segmentation with Mask Transformers
标题:Max-DeepLab:使用掩模Transformer进行端到端全景分割
作者:Huiyu Wang,Yukun Zhu,Hartwig Adam,Alan Yuille,Liang-Chieh Chen
机构:Johns Hopkins University ,Google Research
论文地址:https://arxiv.org/abs/2012.00759
项目地址:暂未开源代码
摘要
文章方法很大程度上简化了依赖于子任务和手动设计的组件(例如,bbox检测,NMS,thing-stuff合并)的现有方式。
相比之下,本文的MaX-DeepLab可通过Mask Transformers直接预测带有类别标签的Mask,并通过二分法匹配以全景质量启发的损失(panoptic quality inspired loss via bipartite matching. )进行训练。
网络具体设计是Mask Transformers采用双路径架构,除了CNN路径外,还引入了全局memory路径,从而允许与任何CNN层直接通信。
结果:在COCO数据集上,相比之前的的box-free策略的方式,提升了7.1%PQ。此外,MaX-DeepLab就可以在COCO test-dev上达到最新的51.3%PQ。
- mask transformer是怎么设计的?原理是怎样的?
- 优化指标loss是怎么设计的?
- 网络架构是怎么样的?
- 所谓的全局memory路径指的是?
- 效果为什么会好?
介绍
之前的方式: 将全景分割任务分成子任务分支,采用多种分开设计的模型。这些方法在单独的分支效果都还可以,但是处理复杂的全景分割任务时,效果就不那么好了。
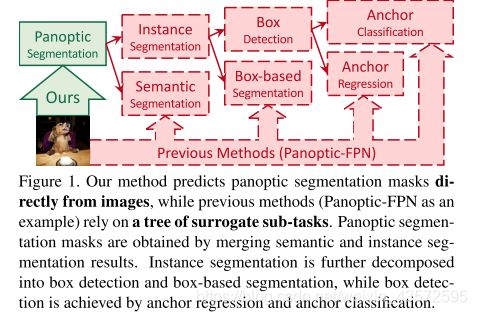

总结起来,之前的方式两类:基于box的,和box free的。box free 的主要以上图b、c为例,缺陷在于难以处理高度不规则的目标和挨得过近的目标。
本文方法:受DETR的启发,我们的模型通过一个Mask Transformer直接预测了一组不重叠的mask及其对应的语义标签。 输出masks和labels使用全景质量(PQ)样式的目标进行了优化。我们将两个类别标记的mask之间的相似性度量定义为它们的mask相似度与class类别相似度的乘积。然后训练模型的目标是最大化groud truth mask和预测的mask的相似性(通过二分法匹配)。
总结Contribution
- MaX-DeepLab是第一个用于全景分割的端到端模型,无需像对象中心或盒子那样经过手工编码的先验即可直接推断蒙版和类。
- 我们提出了一个训练目标,即通过预测蒙版和地面真相蒙版之间的PQ样式二分匹配来优化PQ样式的损失函数。
- 我们的双路径转换器使CNN可以在任何层上读写全局memory,从而提供了一种将transformer与CNN结合的新方法。
- MaX-DeepLab缩小了基于box的方法与box-free的方法之间的差距,并在不使测试时间增加的情况下在COCO上达到了最高水准。
相关工作
- Transformer
- box-based Panoptic segmentation
- box-free Panoptic segmentation
本文方法
表示形式
将每个像素点label的形式表示为:(mi,ci)。mi属于{0,1},ci则属于某一语义类别。这样,就能将所有的thing和stuff一致性表示,并且相互分离。(mi=0/1表示前后景,也就是thing和sutff)。这样就不用有合并thing和stuff的步骤了。
问题:不同instance 对象怎么确定的?
推理阶段
ci就是网络输出的类别概率,通过一个max操作就能取得概率最大的类别作为预测类别。像素赋予maskID。
PQ loss
- 优化指标loss是怎么设计的?
首先,我们在类标记的地面真相掩膜(ground truth mask)和预测掩膜(predict mask)之间定义了PQ风格的相似性度量。 接下来,我们展示如何使用此度量将预测掩码与每个地面真理掩码匹配,最后如何使用相同度量来优化模型
Mask similarity metric:
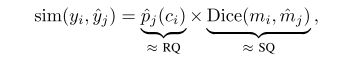
其中ˆpj(ci)∈[0,1]是预测正确类别(识别质量)的概率,而Dice(mi,ˆmj)∈[0,1]是预测的掩码ˆmj与地面之间的Dice系数 。 0<=sim<=1。
Dice系数是,根据Lee Raymond Dice [1]命名,是一种集合相似度变量函数,通常是计算两个样本的相似度(值范围为[0,1])。参考https://www.aiuai.cn/aifarm1159.html
Mask matching:
采用bipartite matching来实现预测和label的的匹配。文章采用的匈牙利算法。取前N个最好的匹配结果作为计算loss 的匹配positive mask。
作者这里提到:
But in our case, assigning multi- ple predicted masks to one ground truth mask is problematic too, because multiple masks cannot possibly be optimized to fit a single ground truth mask at the same time
那为什么还是这么做的呢?直觉上,应该就分配一个匹配度最高的不是吗??
loss的具体形式
上面已经提过了,优化目标转化为最大化预测mask和label的相似度度量(匹配上的mask)。
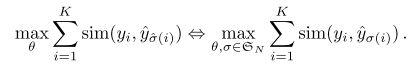
即:
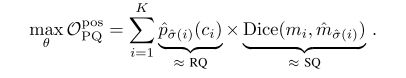
但是作者在实际用的时候,通过应用梯度的乘积规则,然后将概率^p更改为对数概率log ˆp,将Opos PQ重写为两个常见的损失项。因为 从pˆ到logˆp的变化与常见的交叉熵损失一致,并在实践中更好地缩放梯度以进行优化。
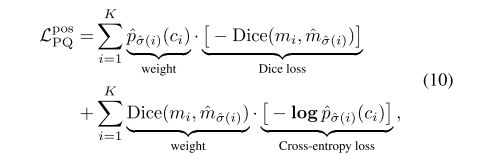
最后,作者还考虑那些negative (unmatched) masks的损失,作为正则项,最终的损失函数如下:

看到这里其实整篇文章端对端的设计思路很清晰了。
网络结构设计
- 网络架构是怎么样的?
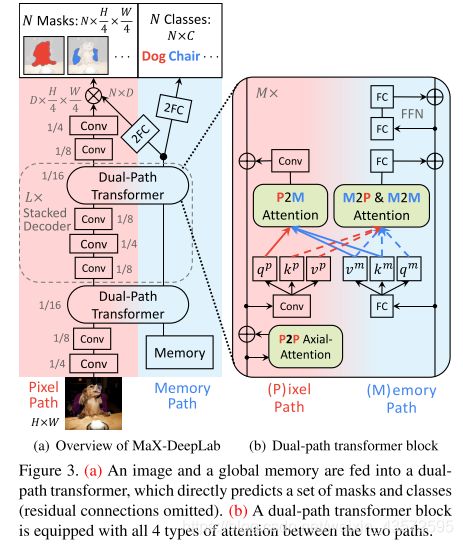
网络由两个路径构成:CNN路径(Pixel Path-输入图像)、Memory路径(size N,前一次的预测结果??)。中间结构如图所示,有许多个卷积和Dual-Path Transformer模块堆叠而成。最后分别接上采样层和2个全连接层(接softmax)得到预测mask和类别。最后双线性插值上采样到原始分辨率。
具体详细结构
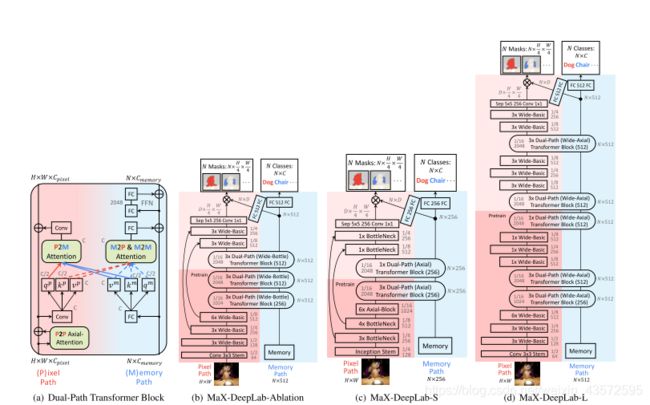
额外的(辅助)损失函数
文章提到,除了上面说的PQstyle相似性损失,加入附加损失是对训练有帮助的。
包括:
-
实例判别损失:帮助实例特征聚类
首先对groud truth mask降采样到1/4大小,进行特征编码,然后对编码的特征进行实例判别。

-
像素mask-ID交叉熵损失:分类每个像素到对应的N个mask
-
语义分割损失:加入了语义分割头(同Panoptic-Deeplab论文中)
Ablation 实验
这部分主要是对:1、不同尺度的输入大小对结果的影响;2、Dual-path transformer结构设计中attention模块的选择设计以及Dual-path transformer模块的深度选取;3、不同损失函数的效果
做了一些实验选取了最优搭配。
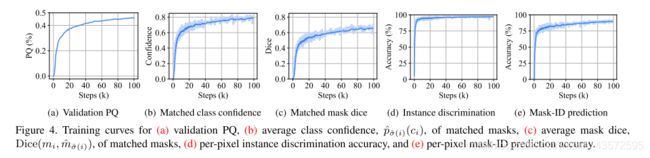
结果
结果就是很diao!
有一个问题:
mask-ID prediction结果不是特别高,实验大概有10%的错误率。像素mask-ID交叉熵损失是否有改进空间?
其实看着结构很清楚,但是里面的内容还有很多疑问:
- 什么是Transformer?里面的attention机制又是什么?
有一篇比较好的讲解:https://jalammar.github.io/illustrated-transformer/ - 文中双路transformer用的几种attention机制有什么不同和特点?
- 上面的Memory路径的输入是什么?
是之前的预测结果:mask和class??但是文中写的memory path输入大小是N×d_in。不太懂。。。有看懂的兄弟姐妹评论告诉我一下。
DETR那篇论文中的Memory看代码是Encoder的输出。那这里的呢 - 不同的实例是怎么确定的?
- 能取得好的结果的深层次原因是什么?
回头再看吧
更新
又看了一遍论文,论文的mask生成和语义类别是类似于SOLO的方法。但是论文里面讲得很模糊…应该是预测的N个(常数)不同mask放在不同的通道维度上,对应的语义类别分支也是N维(C个类别),然后一一对应。
所以这样的话,不同的对象(stuffs和things)是自然而然的分离的,id当然可以直接以mask所在的第i通道作为mask内的所有像素的id。
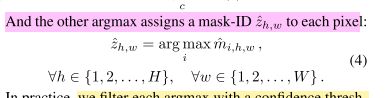
这个公式。没有看太懂,有看懂的兄弟姐妹评论告诉我一下。