Python 从菜鸟到大咖的必经之路
目录
- 一、模块和包
-
- 1.1 模块的基础知识
- 1.2 模块的导入
- 1.3 使用第三方模块
- 1.4 包
- 二、文件和目录操作
-
- 2.1 open() 函数——打开文件并返回文件对象
- 2.2 文件操作的常用方法
- 2.3 应用
- 三、面向对象
-
- 3.1 面向对象基础语法
- 3.2 初始化方法__init__
- 3.3 属性查找与绑定方法
- 3.4 案例
-
- 3.4.1 跑步案例
- 3.4.2 家具案例
- 3.5 私有属性
- 3.6 继承
-
- 3.6.1 面向对象的三大特性
- 3.6.2 单继承
-
- 3.6.2.1 继承的概念
- 3.6.2.2 继承的语法
- 3.6.2.3 方法的重写
- 3.6.2.4 父类的私有属性和私有方法
- 3.6.3 多继承
-
- 3.6.3.1 概念及语法
- 3.6.3.2 多继承使用注意事项
- 3.6.3.3 新式类与旧式(经典)类
- 3.6.3.4 继承的实现原理
- 3.7 多态
-
- 3.7.1 多态案例演练
- 3.7.2 案例总结
- 3.8 类属性和类方法
-
- 3.8.1 类的结构
-
- 3.8.1.1 术语——实例
- 3.8.1.2 类是一个特殊的对象
- 3.8.2 类属性和实例属性
-
- 3.8.2.1 概念和使用
- 3.8.2.2 属性的获取机制
- 3.8.3 类方法和静态方法
-
- 3.8.3.1 类方法
- 3.8.3.2 静态方法
- 3.8.3.3 方法综合案例
- 3.8.3.4 案例小结
- 四、Python 常用模块
- 五、数据库编程
- 六、网络编程
- 七、多任务编程
在 超详细的 Python 基础语句总结(多实例、视频讲解持续更新) 一文中,博主详细讲解了 Python 常用的基础语句并给出了大量实例,如运算符操作、流程控制、函数定义、异常使用等,除开这些基础语句外,还有一些其他语句也是我们必须掌握的,比如文件读写、导包操作、面向对象操作、常用的一些内置函数、模块等,那本文就来对这些知识点进行补充。
一、模块和包
1.1 模块的基础知识
1. 在 Python 中,一个以 .py 为扩展名的文件就叫作一个模块(Module),每一个模块在 Python 里都是一个独立的文件。
2. 模块可以被其他模块、脚本,甚至是交互式解析器导入(import) 使用,也可以被其他程序引用。
3. 使用模块的好处。
- 提高代码的可维护性。
- 提高代码的重用性。
- 避免命名冲突,避免代码污染。
4. Python 模块分为3种类型。
- 内置标准模块,又称为标准库,如 sys、time、math、json 模块等。内置 Python 模块一般都位于安装目录下 Lib 文件夹中。
- 第三方开源模块。这类模块一般通过
pip install 模块名进行在线安装。如果 pip 安装失败,也可以直接访问模块所在官网下载安装包,在本地离线安装。 - 自定义模块。由开发者自己开发的模块,方便在其他程序或脚本中使用。
5. 自定义的模块名称不能与系统模块重名,否则有覆盖掉内置模块的风险。例如,自定义一个 sys.py 模块后,就不能再使用系统的 sys 模块。并且自定义模块名必须要符合 Python 标识符的命名规则。
6. 当 Python 解释器在源代码中解析到 import 关键字时,会自动在搜索路径中寻找对应的模块,如果发现就会立即导入。导入成功,会运行这个模块的源码并进行初始化,然后就可以使用该模块了。
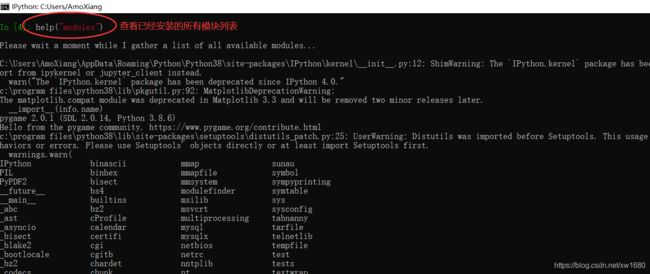
7. 模块的搜索路径。import sys sys.path查看。模块搜索顺序:当前目录 ⇒ PYTHONPATH(环境变量)下的每个目录 ⇒ Python 安装目录
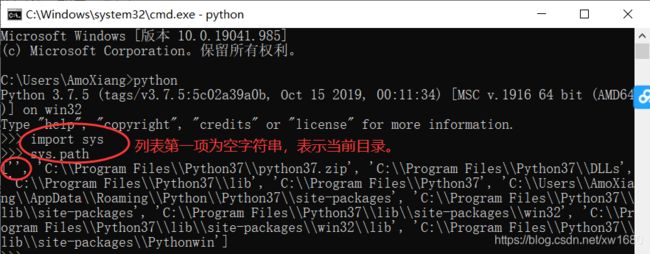
在脚本中手动添加搜索路径:
import sys
sys.path.append("路径")
1.2 模块的导入
1.2.1 import
# 1. 导入模块
import 模块名
import 模块名1, 模块名2... # 但是pep8建议分行进行模块的导入
# 2. 调用功能
模块名.功能名()
import math
print(math.sqrt(9))
# 3.导入模块之后,可以使用 dir(模块名) 方法查看该模块中可用的成员。
import math
print(dir(math))
# 4.每当导入新的模块,sys.modules 会自动记录该模块
# 5.一般 import 命令放在脚本文档的顶端。在一个文档中,
# 不管执行了多少次 import 命令,一个模块仅导入一次,防止滥用 import 命令。
1.2.2 from…import…
# 语法:from 模块名 import 功能1, 功能2, 功能3...
from random import randint
print(randint(1, 10))
1.2.3 from … import *
# 语法:from 模块名 import *
from math import *
print(sqrt(9))
1.2.4 as定义别名。如果模块名字比较长,在导入模块时可以给它起一个别名。
# 模块定义别名 语法: import 模块名 as 别名
import numpy as np
# 功能定义别名 语法: from 模块名 import 功能 as 别名
In [17]: from math import sqrt as s
In [18]: s(16)
Out[18]: 4.0
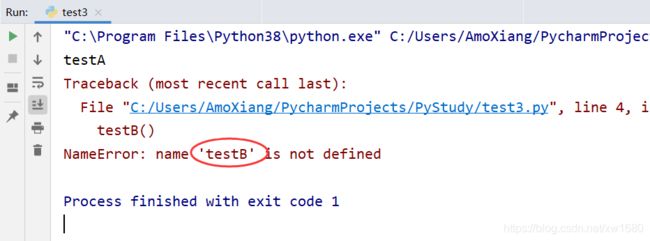
1.2.5 如果一个模块文件中有 __all__ 变量,当使用 from xxx import * 导入时,只能导入这个列表中的元素。
# test.py 代码如下
__all__ = ['testA']
def testA():
print('testA')
def testB():
print('testB')
# test3.py 代码如下
from test import *
testA()
testB()
执行结果如下图所示:
1.3 使用第三方模块
除了使用 Python 内置的标准模块外,也可以使用第三方模块。访问 https://pypi.org/,可以查看 Python 开源模块库。
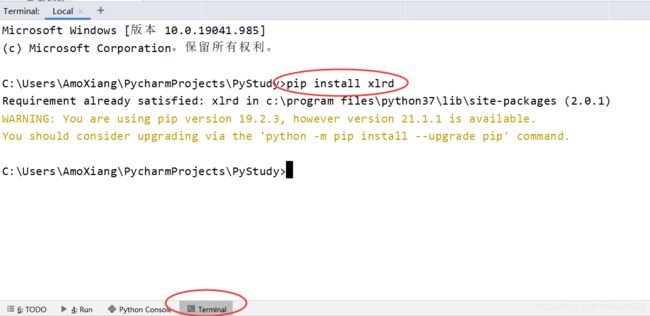
1. 使用 pip 命令安装 语法格式:pip install 模块名 默认连接在国外的 Python 官方服务器下载。
Windows 中权限不够可以使用命令:pip install --user 模块名(不能用于虚拟环境)
提高下载速度可以使用命令:
pip install --user -i http://pypi.douban.com/simple --trusted-host pypi.douban.com 模块名
pip uninstall 模块名 卸载指定模块
pip list 显示已经安装的第三方模块
pip 可以在 cmd 窗口中输入,如下图所示:

也可以在 Pycharm 下方的 Terminal 中输入,如下图所示:
2. 离线安装。在 PyPI 首页搜索模块,找到需要的模块后,单击 Download files 进入下载页面,然后可以选择下载二进制安装文件(.whl) 或者源代码压缩包(.gz)
1.对于二进制文件,直接使用 pip 命令进行安装,安装时把模块名
替换为二进制安装文件即可。注意:在命令行下要改变当前目录到安装文件的目录下。
2.对于源代码压缩包,先解压,并进入目录,然后执行下面的命令完成安装。
编译源码:python setup.py build
安装源码:python setup.py install
3. Pycharm 安装。File ⇒ Settings ⇒ Project: 你的项目名 ⇒ Python Interpreter
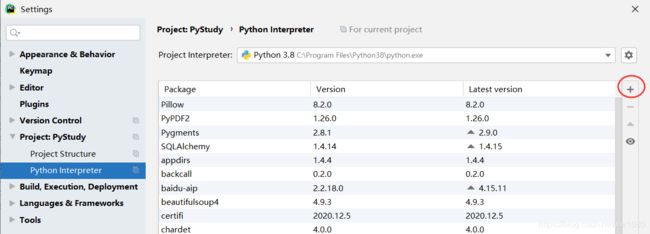
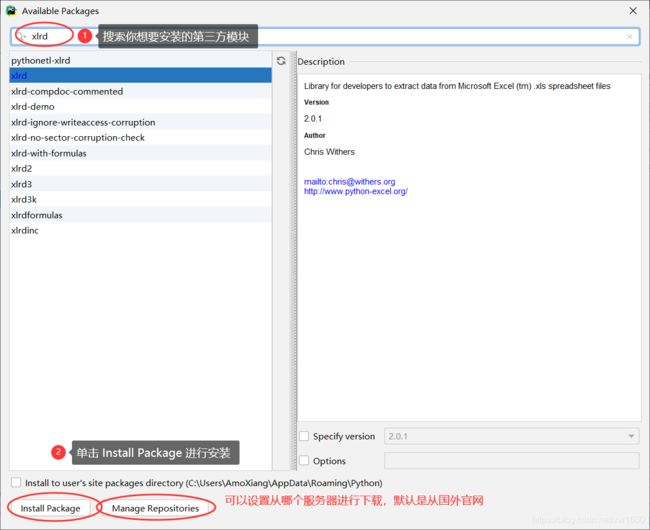
1.4 包
包将有联系的模块组织在一起,即放到同一个文件夹下,并且在这个文件夹创建一个名字为 __init__.py 文件,那么这个文件夹就称之为包。导入方式如下:
import 包名.模块名
包名.模块名.目标
from 包名 import *
模块名.目标
二、文件和目录操作
2.1 open() 函数——打开文件并返回文件对象
open() 函数用于打开文件,返回一个文件读写对象,然后可以对文件进行相应读写操作。语法格式如下:
open(filename, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明:
-
filename:必需参数,文件路径,表示需要打开文件的相对路径(相对于程序所在路径,例如,要创建或打开程序所在路径下的
test.txt文件,则可以直接写成相对路径test.txt,如果是程序所在路径下的soft子路径下的test.txt文件,则可写成soft/test.txt或者绝对路径(需要输入包含盘符的完整文件路径,如D:/test.txt)。文件路径注意需要使用单引号或双引号括起来。 -
mode:可选参数,用于指定文件的打开模式。常见的打开模式有 r(以只读模式打开)、w(以只写模式打开)、a(以追加模式打开),默认的打开模式为只读(即 r)。实际调用的时候可以根据情况进行组合,mode 参数的参数值及说明如下表所示。
模式 功能 说明 ‘t’ 文本模式 默认,以文本模式打开文件。一般用于文本文件 ‘b’ 二进制模式 以二进制格式打开文件。一般用于非文本文件,如图片等。 ‘r’ 只读模式 默认。以只读方式打开一个文件,文件指针被定位到文件头的位置。如果该文件不存在,则会报错 ‘w’ 只写模式 打开一个文件只用于写入,如果该文件已存在,则打开文件,清空文件内容,并把文件指针定位到
文件头位置开始编辑。如果该文件不存在,则创建新文件,打开并编辑。‘a’ 追加模式 打开一个文件用于追加,仅有只写权限,无权读操作。如果该文件已存在,文件指针定位到文件尾
新内容被写入到原内容之后。如果该文件不存在,则创建新文件并写入。‘+’ 更新模式 打开一个文件进行更新,具有可读、可写权限。注意,该模式不能单独使用,需要与r、w、a模式
组合使用。打开文件后,文件指针的位置由r、w、a组合模式决定。‘x’ 只写模式 新建一个文件,打开并写入内容,如果该文件已存在,则会报错。 ‘r+’ 文本格式读写 打开文件后,可以读取文件内容,也可以写入新的内容覆盖原有内容(从文件开头进行覆盖)
如果该文件不存在,则会报错。‘rb’ 二进制格式只读 以二进制格式打开文件,并且采用只读模式。文件的指针将会放在文件的开头。一般用于非文本文件,如图片、声音等。如果该文件不存在,则会报错。 ‘rb+’ 二进制格式读写 以二进制格式打开文件,并且采用读写模式。文件的指针将会放在文件的开头。一般用于非文本文件,如图片、声音等。如果该文件不存在,则会报错。 ‘w+’ 文本格式读写 打开文件后,先清空原有内容,使其变为一个空的文件,对这个空文件有读写权限 ‘wb’ 二进制格式只写 以二进制格式打开文件,并且采用只写模式。一般用于非文本文件,如图片、声音等 ‘wb+’ 二进制格式读写 以二进制格式打开文件,并且采用读写模式。一般用于非文本文件,如图片、声音等 ‘a+’ 文本格式读写 以读写模式打开文件。如果该文件已经存在,文件指针将放在文件的末尾(即新内容会被写入到已有内容之后),否则,创建新文件用于读写 ‘ab’ 二进制格式只写 以二进制格式打开文件,并且采用追加模式。如果该文件已经存在,文件指针将放在文件的末尾(即新内容会被写入到已有内容之后),否则,创建新文件用于写入 ‘ab+’ 二进制格式读写 以二进制格式打开文件,并且采用追加模式。如果该文件已经存在,文件指针将放在文件的末尾(即新内容会被写入到已有内容之后),否则,创建新文件用于读写 -
buffering:可选参数,用于指定读写文件的缓冲模式,值为 0 表示不缓冲,直接写入磁盘;值为 1 表示缓冲(默认为缓冲模式),缓冲区碰到 \n 换行符时写入磁盘;如果大于 1,则缓冲区文件大小达到该数字大小时,写入磁盘。
-
encoding:表示读写文件时所使用的文件编码格式,一般使用 UTF-8。
-
errors:表示读写文件时碰到错误的报错级别。
-
newline:表示用于区分换行符(只对文本模式有效,可以取的值有 None、’\n’、’\r’、’\r\n’)
-
closefd:表示传入的 file 参数类型(缺省为True),传入文件路径时一定为 True,传入文件句柄则为 False。
-
opener:传递可调用对象。
2.2 文件操作的常用方法
打开文件后对文件读取操作通常有三种方法:read() 方法表示读取全部内容;readline() 方法表示逐行读取;readlines() 方法表示读取所有行内容。下面分别进行介绍。
1. read() 方法。读取文件的全部或部分内容,对于连续的面向行的读取,则不使用该方法。语法如下:
fp.read([size])
其中,size 为可选参数,用于指定要读取文件内容的字符数(所有字符均按一个计算,包括汉字,如 name:无 的字符数为 6),如 read(8),表示读取前 8 个字符。如果省略,则返回整个文件的内容。注意:使用 read() 方法读取文件内容时,如果文件大于可用内存,则不能实现文件的读取,而是返回空字符串。
2. readline() 方法。返回文件中一行的内容,具体语法为:
file.readline([size])
其中,size为可选参数,用于指定读取一行内容的范围,如 readline(8),表示指读取一行中前8个字符的内容。如果省略,则返回整行的内容。
3. readlines() 方法。返回一个列表,列表中每个元素为文件中的一行数据,语法如下:
file.readlines()
除了对文件读取操作,还可以对文件进行写入、获取文件指针位置和关闭文件等操作。具体方法如下:
4. write() 方法。将内容写入文件,语法如下:
f.write(obj)
其中,obj 为要写入的内容。
5. tell() 方法。返回一个整数,表示文件指针的当前位置,即在二进制模式下距离文件头的字节数,语法如下:
f.tell()
说明:使用 tell() 方法返回的位置与为 read() 方法指定的 size 参数不同。tell() 方法返回的不是字符的个数,而是字节数,其中汉字所占的字节数根据其采用的编码有所不同,如果采用 GBK 编码,则一个汉字按两个字符计算;如果采用 UTF-8 编码,则一个汉字按 3 个字符计算。
6. seek() 方法。将文件的指针移动到新的位置,位置通过字节数进行指定。这里的数值与tell()方法返回的数值的计算方法一致。语法如下:
file.seek(offset[,whence])
参数说明:
- file:表示已经打开的文件对象;
- offset:用于指定移动的字符个数,其具体位置与whence有关;
- whence:用于指定从什么位置开始计算。值为 0 表示从文件头开始计算, 1 表示从当前位置开始计算,2 表示从文件尾开始计算,默认为 0。
7. close() 方法。关闭打开的文件,语法如下:
file.close()
2.3 应用
【示例1】常用文件读取操作。
""" 一次读取文件的全部内容"""
f = open('test.txt') # 以只写模式打开文件
f.read()
print('--------------------------------------')
f = open('test.txt') # 以只写模式打开文件
lines = f.readline(20000) # 设置读取的字符足够大
print(lines) # 输出读取到的文件内容
f.close() # 关闭文件
print('--------------------------------------')
''' 读取文件或者每行的前几个字符'''
f = open('test.txt') # 以只写模式打开文件
f.read(8)
print('--------------------------------------')
f = open('test.txt') # 以只写模式打开文件
while True:
line = f.readline(5) # 一次读取一行中的5个字符
print(line) # 输出读取的内容
if line == '': # 如果读取的内容为空
break # 跳出循环
f.close() # 关闭文件
print('--------------------------------------')
''' 逐行读取文件内容'''
f = open('test.txt') # 以只写模式打开文件
line = f.readline() # 读取一行
while line:
print(line) # 输出读取的一行内容
line = f.readline() # 读取一行
f.close() # 关闭文件
print('--------------------------------------')
f = open('test.txt') # 以只写模式打开文件
while True:
line = f.readline() # 读取一行
print(line) # 输出读取的一行内容
if line == '': # 如果读取的内容为空
break # 跳出循环
f.close() # 关闭文件
print('--------------------------------------')
for line in open('test.txt'):
print(line) # 输出一行内容
【示例2】使用 with open 语句打开文件。
with open('test.txt', 'r') as f: # 以只读方式打开文件
print(f.read()) # 读取全部文件内容并输出
with open('test.txt', 'r') as f: # 以只写模式打开文件
lines = f.readlines() # 读取全部内容
for line in lines: # 遍历每行内容
print(line.rstrip()) # 输出每行中去掉右侧空白字符的内容
【示例3】在相对路径下创建或写入文件。
with open('lift.txt', 'w') as f: # 以只写模式打开文件
f.write('生命美妙之处, 就在于你的勇气会成就更美的你。')
【示例4】读取操作文件时去除空格,空行等。
with open('lift.txt', 'r') as f: # 以只读模式打开文件
for line in f.readlines():
print(line.strip()) # 去除空格
print(line.strip('\n')) # 去除换行符
print(line.strip('\t')) # 去除制表符
【示例5】读取非UTF-8编码的文件。
with open('test.txt', 'r', encoding='gbk') as f: # 以只读模式打开文件
print(f.readlines()) # 读取全部内容
with open('test.txt', 'r', encoding='gbk', errors='ignore') as f: # 以只读模式打开文件
print(f.readlines()) # 读取全部内容
【示例6】在指定目录(绝对路径)下生成TXT文件。
with open('D:/lift.txt', 'w') as fp: # 以只写模式打开文件
fp.write(' *' * 10 + '生命之美妙' + ' *' * 10)
fp.write('\n 生命美妙之处, 就在于你的勇气会成就更美的你。')
【示例7】以二进制方式打开图片文件。
file = open('python.jpg', 'rb') # 以二进制方式打开图片文件
print(file)
【示例8】多个文件的读取操作。
f1 = open('lift.txt', 'r') # 打开一个文件,命名为f1
f2 = open('test.txt', 'r') # 打开一个文件,命名为f2
f3 = open('digits.txt', 'r') # 打开一个文件,命名为f3
i = f1.readline() # 读取一行
j = f2.readline() # 读取一行
k = f3.readline() # 读取一行
print(i, j, k) # 输出读取到的数据
f1 = open('lift.txt', 'r') # 打开一个文件,命名为f1
f2 = open('test.txt', 'r') # 打开一个文件,命名为f2
f3 = open('digits.txt', 'r') # 打开一个文件,命名为f3
for i, j, k in zip(f1, f2, f3): # 读取每个文件的内容
print(i, j, k)
【示例9】读取一个文件夹下所有文件。
import os # 导入文件与系统操作模块
path = './temp' # 待读取文件的文件夹相对地址
names = os.listdir(path) # 获得目录下所有文件的名称列表
all_list = [] # 保存文件信息的列表
for item in names: # 读取每一个文件
f = open(path + '/' + item, encoding="utf8") # 打开文件
new = [] # 保存单个文件内容的列表
for i in f: # 按行读取文件内容
new.append(i)
all_list.append(new) # 将new添加到列表中
for i in all_list: # 遍历并输出列表
print(i)
【示例10】将文件的写入和读取写入类。
class Operatxt(object): # 定义操作文件类
def __init__(self, encoding):
self.enc = encoding
def write_txt(self, s): # 写入文件的方法
with open("test.txt", "a+", encoding=self.enc) as fileInfo:
fileInfo.write(s) # 写入内容
def read_txt(self): # 读取文件的方法
with open("test.txt", "r", encoding=self.enc) as fileInfo:
con = fileInfo.read() # 读取全部文件内容
return con
# 接收用户输入,将输入内容写入到文件,同时询问用户是读取文件还是继续写入文件
# 当用户选择读取文件时,将前面已经写入的内容读取出来并输出给用户,然后结束用户输入
while True:
content = input("请输入要写入到文件的内容:")
ot = Operatxt("utf-8") # 创建操作文件类的对象,指定编码为UTF-8
ot.write_txt(content) # 写入文件内容
yn = input("内容已写入文件,是否要读取?输入y则读取文件,继续写入请输入n:")
if yn == 'y':
s = ot.read_txt() # 读取文件
print("文件内容为:", s) # 输出文件内容
break # 退出循环
【示例11】查看文件最后一行。
with open("Grade.txt", "rb") as f:
data = f.readlines()
print("最后一行为:", data[-1].decode("utf-8")) # 解码方式以实际为准
with open("Grade.txt", "rb") as f:
data = list(f)[-1]
print("最后一行为:", data.decode("utf-8")) # 解码方式以实际为准
with open("Grade.txt", "rb") as f:
obj = f.__iter__() # 获取迭代器对象
print("最后一行为:", list(obj)[-1].decode("utf-8")) # 解码方式以实际为准
with open("Grade.txt", "rb") as f:
for i in f:
offset = -10 # 光标定位偏移量,根据实际情况调整其大小
while True:
f.seek(offset, 2) # 光标定位从文件尾部开始向前计数
data = f.readlines()
if len(data) > 1:
end_data = data[-1]
print("最后一行数据为:", end_data.decode("utf-8")) # 解码方式以实际为准
break
offset *= 2
三、面向对象
3.1 面向对象基础语法
# -*- coding: utf-8 -*-
# @Time : 2019/12/9 14:33
# @Author : 我就是任性-Amo
# @FileName: 1.面向对象基础语法.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/xw1680
"""
1.类: 类是对一群具有相同特征或者行为的事物的一个统称,是抽象的,不能直接使用
特征被称为属性
行为被称为方法
类就相当于制造飞机时的图纸,是一个模板,是复制创建对象的
2.对象: 对象是由类创建出来的一个具体存在,可以直接使用
由哪一个类创建出来的对象,就拥有在哪一个类中定义的: 属性和方法
对象就相当于用图纸制造的飞机
在程序开发中,应该先有类,再有对象
3.类和对象的关系
类是模板,对象是根据类这个模板创建出来的,应该先有类,再有对象
类只有一个,而对象可以有很多个
不同的对象之间属性 可能会各不相同
类中定义了什么属性和方法,对象中就有什么属性和方法,不可能多,也不可能少
4.类的设计
在程序开发中,要设计一个类,通常需要满足一下三个要素:
类名: 这类事物的名字,满足大驼峰命名法(每一个单词的首字母大写并且单词与单词之间没有下划线)
属性: 这类事物具有什么样的特征
方法: 这类事物具有什么样的行为
4.1 类名的确定
名词提炼法 分析整个业务流程,出现的名词,通常就是找到的类
4.2 属性和方法的确定
对对象的特征描述,通常可以定义成属性
对象具有的行为(动词),通常可以定义成方法
提示: 需求中没有涉及的属性或者方法在设计类时,不需要考虑
"""
# 第一个面向对象程序: 小猫爱吃鱼 小猫要喝水
# 这里的话按照需求首先是不需要定义属性的
class Cat:
"""这是一个猫类"""
def eat(self):
# self: 由哪一个对象调用的方法,方法内的self就是哪一个对象的引用
# 1.在类封装的方法内部,self就表示当前调用方法的对象自己
# 2.调用方法时,我们是不需要传递self参数的 解释器会自动帮我们传入
# 3.在方法内部 可以通过self.访问对象的属性 也可以通过self.调用其他的对象方法
print("%s 爱吃鱼" % self.name)
def drink(self):
print("小猫在喝水")
# 创建对象
tom = Cat()
# tom.eat() # 在设置属性之前 调用方法报错
tom.drink()
# 在类的外部是可以直接通过.的方式去给对象添加属性的,但是不推荐
# 因为对象属性的封装应该封装在类的内部
tom.name = "Tom"
# print(tom.name)
tom.eat() # tom.eat(tom)
# print(tom.__dict__) # 可以查看对象绑定了哪些属性
# print(Cat.__dict__) # 可以查看类绑定了哪些命名空间
lazy_cat = Cat()
lazy_cat.name = "大懒猫"
lazy_cat.eat()
# 在类的外部通过变量名.访问对象的属性和方法
# 在类的封装方法中,通过self.访问对象的属性和方法
3.2 初始化方法__init__
# -*- coding: utf-8 -*-
# @Time : 2019/12/9 14:40
# @Author : 我就是任性-Amo
# @FileName: 2.初始化方法.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/xw1680
"""
初始化方法:
1.当使用类名()创建对象时,会自动执行以下操作:
为对象在内存中分配空间--创建对象
为对象的属性设置初始值--初始化方法(init)
2.__init__方法是专门用来定义一个类具有哪些属性的方法
"""
# 在Cat中增加__init__方法,验证该方法在创建对象时会被调用
class Cat:
"""这是一个猫类"""
# def __init__(self):
# print("这是一个初始化方法")
# # 定义用Cat类创建的猫对象都有一个name的属性
# self.name = "Tom"
# 在开发中,如果希望在创建对象的同时,就设置对象的属性,可以对_init__方法进行改造
# 把希望设置的属性值,定义成__init__方法的参数,在方法内部使用
# self.属性 = 形参 接收外部传递的参数
# 在创建对象时,使用类名(属性1, 属性2...)
def __init__(self, name):
self.name = name
def eat(self):
print("%s 爱吃鱼" % self.name)
# 如果在开发中,希望使用print输出对象变量时,能够打印自定义的内容,就可以利用__str__这个内置方法了
def __str__(self):
return "我是小猫: %s" % self.name
# def __del__(self):
# __del__:如果希望在对象被销毁前,再做一些事情,可以考虑此方法
def __del__(self):
print("准备删除~~~")
tom = Cat("Tom") # 创建对象时 会自动调用初始化__init__方法
tom.eat()
lazy_cat = Cat("大懒猫")
lazy_cat.eat()
# 在Python中,使用print输出对象变量,默认情况下,会输出这个变量引用的对象是由哪一个类创建的对象,
# 以及在内存中的地址(十六进制表示)
print(tom) # <__main__.Cat object at 0x103959bd0>
del lazy_cat
print("-" * 50)
3.3 属性查找与绑定方法
# -*- coding: utf-8 -*-
# @Time : 2019/12/9 15:00
# @Author : 我就是任性-Amo
# @FileName: 3.属性查找与绑定方法.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/xw1680
# 属性查找与绑定方法
class Person:
"""这是一个猫类"""
# nationality = "中国"
# def __init__(self, name, age, address, nationality):
# self.name = name
# self.age = age
# self.address = address
# self.nationality = nationality 给对象绑定国籍属性
def __init__(self, name, age, address):
self.name = name
self.age = age
self.address = address
def eat(self):
print(f"{self.name}正在吃饭~~~")
# 1.分别创建amo对象和paul对象
# amo = Person("amo", 18, "重庆市沙坪坝区", "美国")
# paul = Person("paul", 22, "重庆市沙坪坝区", "中国")
# 属性: 首先会从对象本身先去查找,如果对象本身没有绑定该属性,则会从类中去找
# print(id(amo.nationality)) # 4406863312
# print(id(paul.nationality)) # 4406863504
amo = Person("amo", 18, "重庆市沙坪坝区")
paul = Person("paul", 22, "重庆市沙坪坝区")
# 如果对象身上没有绑定该属性 则去在类中查找 类属性是被所有对象共用的 所以返回的地址值是一致的.
# print(id(amo.nationality)) # 4461503952
# print(id(paul.nationality)) # 4461503952
# 如果在类中查找该属性 还是没有 程序就会报错
# print(id(paul.nationality)) # AttributeError: 'Person' object has no attribute 'nationality'
# 函数属性:是绑定给对象使用的,绑定到不同的对象是不同的绑定方法,对象调用绑定方法时,会把对象本身作为一个参数进行传入,传给self
print(amo.eat) # >
print(paul.eat) # >
# 可以看到 两个的绑定方法的内存地址值是不一致的
print(Person.__dict__)
print(id(Person.eat(amo))) # 4393136216
print(id(Person.eat(paul))) # 4393136216
3.4 案例
3.4.1 跑步案例
# -*- coding: utf-8 -*-
# @Time : 2019/12/10 16:28
# @Author : 我就是任性-Amo
# @FileName: 4.练习1.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/xw1680
# 封装是面向对象编程的一大特点
# 面向对象编程的第一步:将属性和方法封装到一个抽象的类中
# 外界使用类创建对象,然后让对象调用方法
# 对象方法的细节都被封装在类的内部
"""
需求:amo和jerry都爱跑步
amo体重75.0公斤
jerry体重45.0 公斤
每次跑步都会减少0.5公斤
每次吃东西都会增加1公斤
"""
class Person:
def __init__(self, name, weight):
self.name = name
self.weight = weight
def run(self):
self.weight -= 0.5
print("%s 爱锻炼,跑步锻炼身体" % self.name)
def eat(self):
self.weight += 1
# 注意: 在对象的方法内部,是可以直接访问对象的属性的
print("%s 是吃货,吃完这顿在减肥" % self.name)
def __str__(self):
return "我的名字是%s,体重%.2f公斤" % (self.name, self.weight)
amo = Person("amo", 75.0)
amo.run()
amo.eat()
amo.eat()
print(amo)
print("-" * 50)
jerry = Person("jerry", 45.0) # 同一个类创建的多个对象之间,属性互不干扰
jerry.run()
jerry.eat()
jerry.eat()
print(jerry)
代码运行结果如下:

3.4.2 家具案例
# -*- coding: utf-8 -*-
# @Time : 2019/12/20 09:26
# @Author : 我就是任性-Amo
# @FileName: 5.家具案例.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/xw1680
"""
需求:
1.房子(House)有户型、总面积和家具名称列表
新房子没有任何的家具
2.家具(HouseItem)有名字和占地面积,其中
席梦思(bed)占地4平米
衣柜(chest)占地2平米
餐桌(table)占地1.5平米
3.将以上三件家具添加到房子中
4.打印房子时,要求输出:户型、总面积、剩余面积、家具名称列表
"""
# 分析: 要去添加家具 首先肯定要有一个家具类 被使用的类 通常应该先被开发
class HouseItem:
def __init__(self, name, area):
self.name = name # 家具名称
self.area = area # 占地面积
def __str__(self):
return "[%s] 占地面积 %.2f" % (self.name, self.area)
bed = HouseItem("bed", 4) # 席梦思
chest = HouseItem("chest", 2) # 衣柜
table = HouseItem("table", 1.5) # 餐桌
print(bed)
print(chest)
print(table)
class House:
def __init__(self, apartment, area):
self.apartment = apartment # 户型
self.total_area = area # 总面积
self.free_area = area # 剩余面积开始的时候和总面积是一样的
self.furniture_list = [] # 家具名称列表 默认是没有放置任何家具的
def add_item(self, furniture):
"""添加家具"""
print(f"添加:{furniture.name}")
# 判断家具的面积是否超过剩余面积,如果超过,提示不能添加这件家具
if furniture.area > self.free_area:
print("房间剩余面积不够,不能添置这件家具...")
return
self.furniture_list.append(furniture.name) # 将家具名称追加到家具名称列表中
self.free_area -= furniture.area # 用房子的剩余面积-家具面积
def __str__(self):
return f"房子户型为:{self.apartment},总面积为:{self.total_area}," \
f"剩余面积为{self.free_area},家具列表为:{self.furniture_list}"
if __name__ == "__main__":
my_house1 = House("两室一厅", 60)
my_house1.add_item(bed)
my_house1.add_item(chest)
my_house1.add_item(table)
print(my_house1)
my_house2 = House("一室一厅", 10)
my_house2.add_item(bed)
my_house2.add_item(chest)
my_house2.add_item(table)
my_house2.add_item(bed)
print(my_house2)
代码运行结果如下:

3.5 私有属性
# -*- coding: utf-8 -*-
# @Time : 2019/12/20 10:08
# @Author : 我就是任性-Amo
# @FileName: 6.私有属性.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/xw1680
"""
应用场景:
在实际开发中,对象的某些属性或方法可能只希望在对象的内部被使用,而不希望在外部被访问到
私有属性就是对象不希望公开的属性
私有方法就是对象不希望公开的方法
定义的方式: 在定义属性或方法时,在属性名或者方法名前增加两个下划线,定义的就是私有属性或方法
在java中的话是使用private关键字
"""
class Women:
def __init__(self, name):
self.name = name
self.__age = 18
def __secret(self):
print("我的年龄是 %d" % self.__age)
xiao_fang = Women("小芳")
# 私有属性外界不能直接访问
# print(xiao_fang.__age) 报错:AttributeError: 'Women' object has no attribute '__age'
# 私有方法,外部不嫩直接调用
# xiao_fang.__secret()
# 在日常开发中,不要使用这种方式,访问对象的私有属性或私有方法
# 在Python中,并没有真正意义的私有
# 在给属性、方法 命名时,实际是对名称做了一些特殊处理,使得外界无法访问到
# 处理方式:在名称前面加上 _类名 => _类名__名称
print(xiao_fang.__dict__) # 查看名称空间
print(xiao_fang._Women__age)
# print(Women.__dict__)
xiao_fang._Women__secret()
程序运行结果如下:

3.6 继承
3.6.1 面向对象的三大特性
- 封装: 根据职责将属性和方法封装到一个抽象的类中
- 继承: 实现代码的重用,相同的代码不需要重复的编写
- 多态: 不同的对象调用相同的方法,产生不同的执行结果,增加代码的灵活度
3.6.2 单继承
3.6.2.1 继承的概念
继承的概念: 子类拥有父类的所有方法和属性
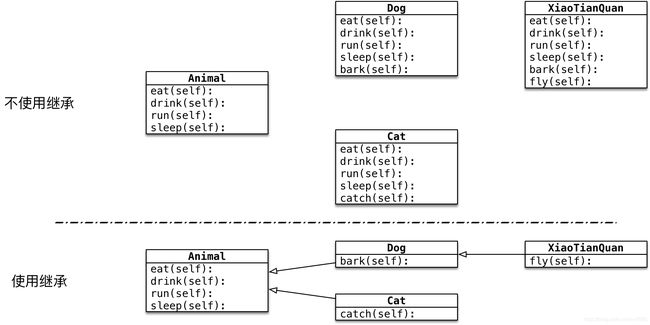
# ---------不使用继承开发动物和狗---------------
class Animal:
def eat(self):
print("吃")
def drink(self):
print("喝")
def run(self):
print("跑")
def sleep(self):
print("睡")
class Dog:
def eat(self): # 不使用继承重复书写的代码太多
print("吃")
def drink(self):
print("喝")
def run(self):
print("跑")
def sleep(self):
print("睡")
def bark(self):
print("汪汪叫")
# 创建一个狗对象
wang_cai = Dog()
wang_cai.eat()
wang_cai.drink()
wang_cai.run()
wang_cai.sleep()
wang_cai.bark()
# # ---------使用继承开发动物和狗---------------
class Animal:
def eat(self):
print("吃---")
def drink(self):
print("喝---")
def run(self):
print("跑---")
def sleep(self):
print("睡---")
class Dog(Animal):
def bark(self):
print("汪汪叫---")
# 创建一个狗对象
wang_cai = Dog()
wang_cai.eat()
wang_cai.drink()
wang_cai.run()
wang_cai.sleep()
wang_cai.bark() # 直接享受父类中已经封装好的方法 不需要再次开发
3.6.2.2 继承的语法
class 类名(父类名):
pass
- 子类继承自父类,可以直接享受父类中已经封装好的方法,不需要再次开发
- 子类中应该根据职责,封装子类特有的属性和方法
- 专业术语
- Dog类是Animal类的子类,Animal类是Dog类的父类,Dog类从Animal类继承
- Dog类是Animal类的派生类,Animal类是Dog类的基类,Dog类从Animal类派生
- 继承的传递性
C类从B类继承,B类又从A类继承,那么C类就具有B类和A类的所有属性和方法
# -*- coding: utf-8 -*-
# @Time : 2019/12/21 10:52
# @Author : 我就是任性-Amo
# @FileName: 9.继承的传递性.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/xw1680
class Animal:
def eat(self):
print("吃---")
def drink(self):
print("喝---")
def run(self):
print("跑---")
def sleep(self):
print("睡---")
class Dog(Animal):
def bark(self):
print("汪汪叫")
class XiaoTianQuan(Dog):
def fly(self):
print("我会飞")
# 创建一个哮天犬的对象
xtq = XiaoTianQuan()
xtq.fly()
xtq.bark()
xtq.eat()
程序运行结果如下:

3.6.2.3 方法的重写
- 子类拥有父类的所有方法和属性
- 子类继承自父类,可以直接享受父类中已经封装好的方法,不需要再次开发
- 应用场景: 当父类的方法实现不能满足子类需求时,可以对方法进行 重写(override)
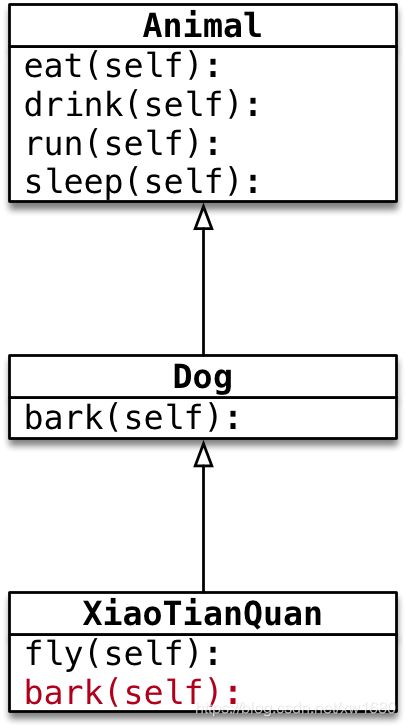
- 重写父类的方法有两种情况
- 覆盖父类的方法
如果在开发中,父类的方法实现和子类的方法实现,完全不同。就可以使用覆盖的方式,在子类中重新编写父类的方法实现。具体的实现方式,就相当于在子类中定义了一个和父类同名的方法并且实现。重写之后,在运行时,只会调用子类中重写的方法,而不再会调用父类封装的方法
# -*- coding: utf-8 -*-
# @Time : 2019/12/21 10:55
# @Author : 我就是任性-Amo
# @FileName: 10.覆盖父类方法.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/xw1680
class Animal:
def eat(self):
print("吃---")
def drink(self):
print("喝---")
def run(self):
print("跑---")
def sleep(self):
print("睡---")
class Dog(Animal):
def bark(self):
print("汪汪叫")
class XiaoTianQuan(Dog):
def fly(self):
print("我会飞")
def bark(self):
print("叫得跟神一样...")
xtq = XiaoTianQuan()
# 如果子类中,重写了父类的方法
# 在使用子类对象调用方法时,会调用子类中重写的方法
xtq.bark()
- 对父类方法进行扩展
如果在开发中,子类的方法实现中包含父类的方法实现。父类原本封装的方法实现是子类方法的一部分。就可以使用扩展的方式:
1. 在子类中重写父类的方法
2. 在需要的位置使用super().父类方法来调用父类方法的执行
3. 代码其他的位置针对子类的需求,编写子类特有的代码实现
- 关于super
- 在
Python中super是一个特殊的类 super()就是使用super类创建出来的对象- 最常使用的场景就是在重写父类方法时,调用在父类中封装的方法实现
- 在Python 2.x时,如果需要调用父类的方法,还可以使用以下方式:父类名.方法(self)
- 这种方式,目前在 Python 3.x 还支持这种方式
- 这种方法不推荐使用,因为一旦父类发生变化,方法调用位置的类名同样需要修改
- 在开发时,父类名和 super()两种方式不要混用
- 如果使用当前子类名调用方法,会形成递归调用,出现死循环
- 在
# -*- coding: utf-8 -*-
# @Time : 2019/12/21 11:03
# @Author : 我就是任性-Amo
# @FileName: 11.扩展父类方法.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/xw1680
class Animal:
def eat(self):
print("吃---")
def drink(self):
print("喝---")
def run(self):
print("跑---")
def sleep(self):
print("睡---")
class Dog(Animal):
def bark(self):
print("汪汪叫")
class XiaoTianQuan(Dog):
def fly(self):
print("我会飞")
def bark(self):
# 1.针对子类特有的需求,编写代码
print("神一样的叫唤...")
# 2.使用super().调用原本在父类中封装的方法
# super().bark()
# 父类名.方法(self)
Dog.bark(self) # 但是一旦父类名改变 这里也要随之改变
# 注意: 如果使用子类调用方法,会出现递归调用-死循环!
# XiaoTianQuan.bark(self)
# 3. 增加其他子类的代码
print("$%^*%^$%^#%$%")
xtq = XiaoTianQuan()
# 如果子类中,重写了父类的方法
# 在使用子类对象调用方法时,会调用子类中重写的方法
xtq.bark()
程序运行结果如下:

3.6.2.4 父类的私有属性和私有方法
- 子类对象不能在自己的方法内部,直接访问父类的私有属性或私有方法
- 子类对象可以通过父类的公有方法间接访问到私有属性或私有方法
- 示例:
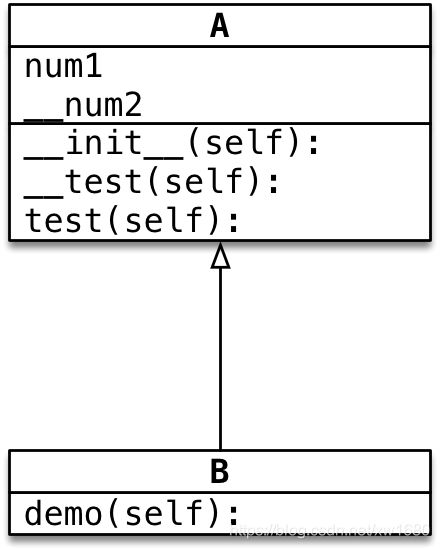
B的对象不能直接访问__num2属性B的对象不能在demo方法内访问__num2属性B的对象可以在demo方法内,调用父类的test方法- 父类的
test方法内部,能够访问__num2属性和__test方法
# -*- coding: utf-8 -*-
# @Time : 2019/12/21 11:11
# @Author : 我就是任性-Amo
# @FileName: 13.父类的公有方法.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/xw1680
class A:
def __init__(self):
self.num1 = 100
self.__num2 = 200
def __test(self):
print("私有方法 %d %d" % (self.num1, self.__num2))
def test(self):
print("父类的公有方法 %d" % self.__num2)
self.__test()
class B(A):
def demo(self):
# 1. 在子类的对象方法中,不能访问父类的私有属性
# print("访问父类的私有属性 %d" % self.__num2)
# 2. 在子类的对象方法中,不能调用父类的私有方法
# self.__test()
# 3. 访问父类的公有属性
print("子类方法 %d" % self.num1)
# 4. 调用父类的公有方法
self.test()
pass
# 创建一个子类对象
b = B()
print(b)
b.demo()
# 在外界访问父类的公有属性/调用公有方法
# print(b.num1)
# b.test()
# 在外界不能直接访问对象的私有属性/调用私有方法
# print(b.__num2)
# b.__test()
3.6.3 多继承
3.6.3.1 概念及语法
- 子类可以拥有多个父类,并且具有所有父类的属性和方法
- 例如:孩子会继承自己 父亲和母亲的特性
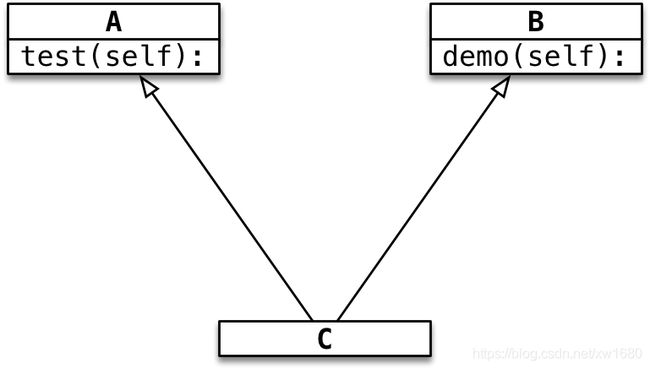
- 语法:
class 子类名(父类名1, 父类名2...):
pass
class A:
def test(self):
print("test 方法")
class B:
def demo(self):
print("demo 方法")
class C(A, B):
"""多继承可以让子类对象,同时具有多个父类的属性和方法"""
pass
# 创建子类对象
c = C()
c.test()
c.demo()
3.6.3.2 多继承使用注意事项
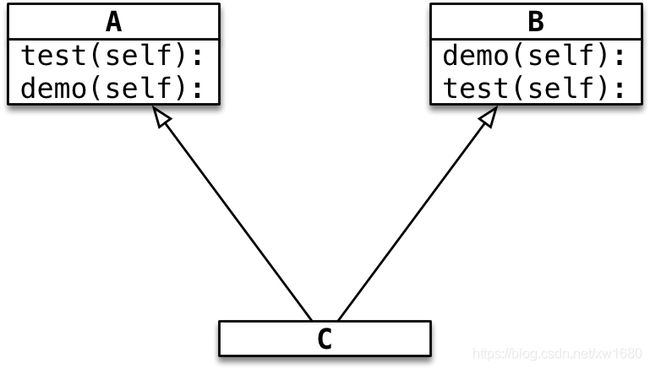
- 如果不同的父类中存在同名的方法,子类对象在调用方法时,会调用哪一个父类中的方法呢?
提示:开发时,应该尽量避免这种容易产生混淆的情况。
如果父类之间存在同名的属性或者方法,应该尽量避免使用多继承
class A:
def test(self):
print("A --- test 方法")
def demo(self):
print("A --- demo 方法")
class B:
def test(self):
print("B --- test 方法")
def demo(self):
print("B --- demo 方法")
class C(B, A):
"""多继承可以让子类对象,同时具有多个父类的属性和方法"""
pass
# 创建子类对象
c = C()
c.test()
c.demo()
# 确定C类对象调用方法的顺序
print(C.__mro__)
3.6.3.3 新式类与旧式(经典)类
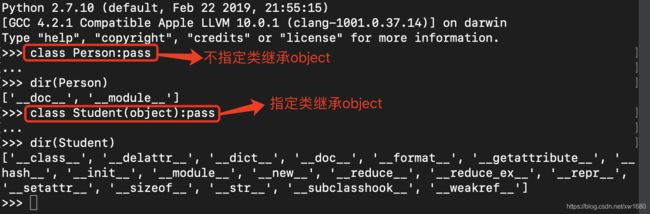
object是Python为所有对象提供的基类,提供有一些内置的属性和方法,可以使用dir函数查看
在Python3中,使用dir函数查看效果图如下:

在Python2中,使用dir函数查看效果如下:
- 新式类:以
object为基类的类,推荐使用 - 经典类:不以
object为基类的类,不推荐使用 - 在Python3.x中定义类时,如果没有指定父类,会默认使用object 作为该类的基类——Python 3.x 中定义的类都是新式类
- 在Python2.x中定义类时,如果没有指定父类,则不会以object作为基类
- 为了保证编写的代码能够同时在Python 2.x和Python3.x运行!今后在定义类时,如果没有父类,建议统一继承自object
3.6.3.4 继承的实现原理
python到底是如何实现继承的,对于你定义的每一个类,python会计算出一个方法解析顺序(MRO)列表,这个MRO列表就是一个简单的所有基类的线性顺序列表,例如
(, , , , , , )
为了实现继承,python会在MRO列表上从左到右开始查找基类,直到找到第一个匹配这个属性的类为止。而这个MRO列表的构造是通过一个C3线性化算法来实现的。我们不去深究这个算法的数学原理,它实际上就是合并所有父类的MRO列表并遵循如下三条准则:
- 子类会先于父类被检查
- 多个父类会根据它们在列表中的顺序被检查
- 如果对下一个类存在两个合法的选择,选择第一个父类
- 在Java和C#中子类只能继承一个父类,而Python中子类可以同时继承多个父类,如果继承了多个父类,那么属性的查找方式有两种,分别是:深度优先和广度优先
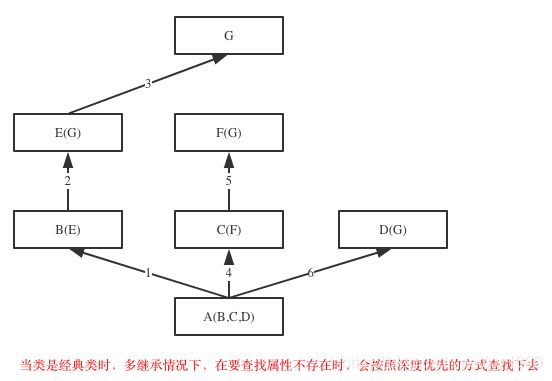
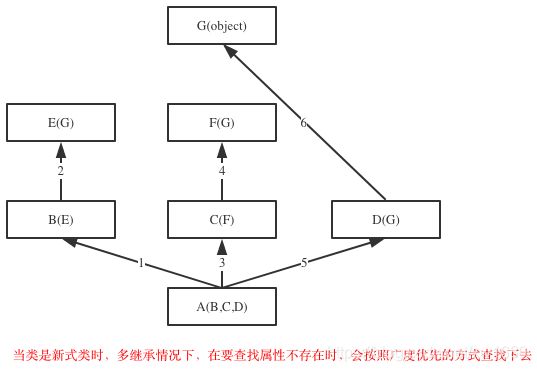
示例代码:
# -*- coding: utf-8 -*-
# @Time : 2019/12/24 09:30
# @Author : 我就是任性-Amo
# @FileName: 15.新式类与经典类.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/xw1680
class A(object):
def test(self):
print('from A')
class B(A):
def test(self):
print('from B')
class C(A):
def test(self):
print('from C')
class D(B):
def test(self):
print('from D')
class E(C):
def test(self):
print('from E')
class F(D, E):
# def test(self):
# print('from F')
pass
f1 = F()
f1.test()
print(F.__mro__) # 只有新式才有这个属性可以查看线性列表,经典类没有这个属性
# import inspect # 使用inspect模块中的getmro()方法可以查看python2.x的mro顺序
MRO顺序如下:
# 新式类继承顺序如下:
# ,
# ,
# ,
# ,
# ,
# ,
#
# 经典类继承顺序如下:
# ,
# ,
# ,
# ,
# ,
#
3.7 多态
不同的子类对象调用相同的父类方法,产生不同的执行结果
- 多态可以增加代码的灵活度
- 以继承和重写父类方法为前提
- 是调用方法的技巧,不会影响到类的内部设计

3.7.1 多态案例演练
- 在Dog类中封装方法 game 普通狗只是简单的玩耍
- 定义XiaoTianDog继承自Dog,并且重写game方法 哮天犬需要在天上玩耍
- 定义 Person 类,并且封装一个和狗玩的方法 在方法内部,直接让狗对象调用game方法
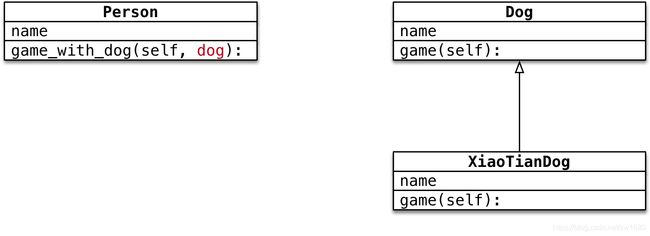
# -*- coding: utf-8 -*-
# @Time : 2019/12/24 15:20
# @Author : 我就是任性-Amo
# @FileName: 17.多态.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/xw1680
class Dog(object):
def __init__(self, name):
self.name = name
def game(self):
print("%s 蹦蹦跳跳的玩耍..." % self.name)
class XiaoTianDog(Dog):
def game(self):
print("%s 飞到天上去玩耍..." % self.name)
class Person(object):
def __init__(self, name):
self.name = name
def game_with_dog(self, dog):
print("%s 和 %s 快乐的玩耍..." % (self.name, dog.name))
# 让狗玩耍
dog.game()
# 1. 创建一个狗对象
# wang_cai = Dog("旺财")
wang_cai = XiaoTianDog("飞天旺财")
# 2. 创建一个小明对象
xiao_ming = Person("小明")
# 3. 让小明调用和狗玩的方法
xiao_ming.game_with_dog(wang_cai)
程序运行结果如下:

3.7.2 案例总结
- Person类中只需要让狗对象调用game方法,而不关心具体是什么狗 game方法是在Dog父类中定义的
- 在程序执行时,传入不同的狗对象实参,就会产生不同的执行效果
- 多态更容易编写出通用的代码,做出通用的编程,以适应需求的不断变化!
3.8 类属性和类方法
3.8.1 类的结构
3.8.1.1 术语——实例
- 使用面相对象开发,第1步是设计类
- 使用类名()创建对象,创建对象的动作有两步:
- 在内存中为对象分配空间
- 调用初始化方法
__init__为对象初始化
- 对象创建后,内存中就有了一个对象的实实在在的存在—实例
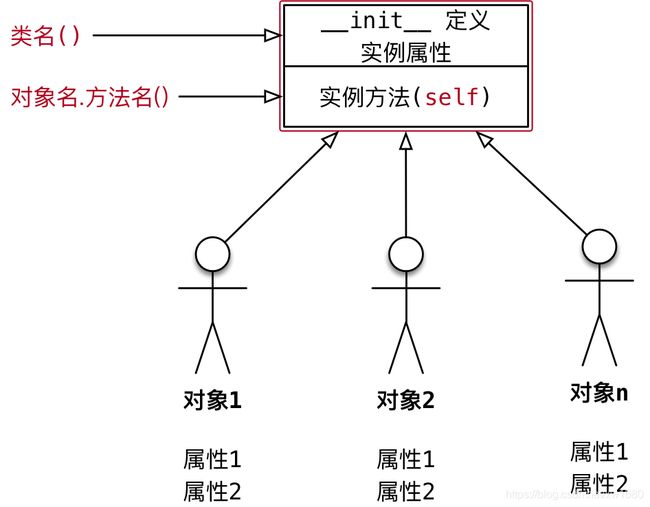
因此,通常也会把:- 创建出来的对象叫做类的实例
- 创建对象的动作叫做实例化
- 对象的属性叫做实例属性
- 对象调用的方法叫做实例方法
在程序执行时:对象各自拥有自己的实例属性 调用对象方法,可以通过 self.访问自己的属性和调用自己的方法
结论:
- 每一个对象都有自己独立的内存空间,保存各自不同的属性
- 多个对象的方法,在内存中只有一份,在调用方法时,需要把对象的引用传递到方法内部
3.8.1.2 类是一个特殊的对象
Python中一切皆对象,class AAA: 定义的类属于类对象 obj1 = AAA() 属于实例对象
- 在程序运行时,类同样会被加载到内存
- 在Python中,类是一个特殊的对象–类对象
- 在程序运行时,类对象在内存中只有一份,使用一个类可以创建出很多个对象实例
- 除了封装实例的属性和方法外,类对象还可以拥有自己的属性和方法
- 类属性
- 类方法
- 通过类名
.的方式可以访问类的属性或者调用类的方法

3.8.2 类属性和实例属性
3.8.2.1 概念和使用
- 类属性就是给类对象中定义的属性
- 通常用来记录与这个类相关的特征
- 类属性不会用于记录具体对象的特征
示例需求:
- 定义一个工具类
- 每件工具都有自己的name
- 需求——知道使用这个类,创建了多少个工具对象?

class Tool(object):
# 使用赋值语句,定义类属性,记录创建工具对象的总数
count = 0
def __init__(self, name):
self.name = name
# 针对类属性做一个计数+1
Tool.count += 1
# 创建工具对象
tool1 = Tool("斧头")
tool2 = Tool("榔头")
tool3 = Tool("铁锹")
# 知道使用 Tool 类到底创建了多少个对象?
print("现在创建了 %d 个工具" % Tool.count)

3.8.2.2 属性的获取机制
在Python中属性的获取存在一个向上查找机制

因此,要访问类属性有两种方式:
- 类名.类属性
- 对象.类属性 (不推荐)
如果使用对象.类属性 = 值赋值语句,只会给对象添加一个属性,而不会影响到类属性的值
3.8.3 类方法和静态方法
3.8.3.1 类方法
- 类属性就是针对类对象定义的属性
- 使用赋值语句在class关键字下方可以定义类属性
- 类属性用于记录与这个类相关的特征
- 类方法就是针对类对象定义的方法
- 在类方法内部可以直接访问类属性或者调用其他的类方法
- 语法如下
@classmethod
def 类方法名(cls):
pass
- 类方法需要用@classmethod来标识,告诉解释器这是一个类方法
- 类方法的第一个参数应该是cls
- 由哪一个类调用的方法,方法内的
cls就是哪一个类的引用 - 这个参数和实例方法的第一个参数是
self类似 - 提示使用其他名称也可以,不过习惯使用
cls
- 由哪一个类调用的方法,方法内的
- 通过
类名.调用类方法,调用方法时,不需要传递cls参数 - 在方法内部
- 可以通过
cls.访问类的属性 - 也可以通过
cls.调用其他的类方法

- 可以通过
# 定义一个工具类 每件工具都有自己的name 需求—在类封装一个show_tool_count的类方法,输出使用当前这个类,创建的对象个数
@classmethod
def show_tool_count(cls):
"""显示对象工具的总数"""
print("工具对象的总数 %d" % cls.count)
# 在类方法内部,可以直接使用cls访问类属性或者调用类方法
3.8.3.2 静态方法
- 在开发时,如果需要在类中封装一个方法,这个方法:
- 既不需要访问实例属性或者调用实例方法
- 也不需要访问类属性或者调用类方法
- 这个时候,可以把这个方法封装成一个静态方法
- 语法如下
@staticmethod
def 静态方法名():
pass
- 静态方法需要用
@staticmethod来标识,告诉解释器这是一个静态方法 - 通过
类名.调用静态方法
class Dog(object):
# 狗对象计数
dog_count = 0
@staticmethod
def run():
# 不需要访问实例属性也不需要访问类属性的方法
print("狗在跑...")
def __init__(self, name):
self.name = name
3.8.3.3 方法综合案例
- 设计一个Game类
- 属性:
- 定义一个类属性
top_score记录游戏的历史最高分 - 定义一个实例属性
player_name记录当前游戏的玩家姓名
- 定义一个类属性
- 方法:
- 静态方法
show_help显示游戏帮助信息 - 类方法
show_top_score显示历史最高分 - 实例方法
start_game开始当前玩家的游戏
- 静态方法
- 主程序步骤
- 查看帮助信息
- 查看历史最高分
- 创建游戏对象,开始游戏

class Game(object):
# 游戏最高分,类属性
top_score = 0
@staticmethod
def show_help():
print("帮助信息:让僵尸走进房间")
@classmethod
def show_top_score(cls):
print("游戏最高分是 %d" % cls.top_score)
def __init__(self, player_name):
self.player_name = player_name
def start_game(self):
print("[%s] 开始游戏..." % self.player_name)
# 使用类名.修改历史最高分
Game.top_score = 999
# 1. 查看游戏帮助
Game.show_help()
# 2. 查看游戏最高分
Game.show_top_score()
# 3. 创建游戏对象,开始游戏
game = Game("小明")
game.start_game()
# 4. 游戏结束,查看游戏最高分
Game.show_top_score()
# 如果方法内部即需要访问实例属性,又需要访问类属性,应该定义成什么方法?
# 应该定义实例方法
# 因为,类只有一个,在实例方法内部可以使用类名.访问类属性
3.8.3.4 案例小结
- 实例方法 —— 方法内部需要访问实例属性
- 实例方法内部可以使用
类名.访问类属性
- 实例方法内部可以使用
- 类方法 —— 方法内部只需要访问类属性
- 静态方法 —— 方法内部,不需要访问实例属性和类属性
四、Python 常用模块
【吐血整理】Python 常用模块(一):random模块
【吐血整理】Python 常用模块(二):json 模块
【吐血整理】Python 常用模块(三):re 模块
五、数据库编程
https://blog.csdn.net/xw1680/article/details/109960597
六、网络编程
https://blog.csdn.net/xw1680/article/details/104703306
七、多任务编程
https://blog.csdn.net/xw1680/article/details/104442017