匹配网页里的zip_Python网页爬虫入门指导
前段时间由于工作上需要获取一些数据,因此不得不去一些专业网站爬取一些素材,然后进行过滤和筛选,所以就现学了网页爬虫的知识。由于之前有过一些html文本自然语言处理的工作经验,所以使用过beautifulSoup4和正则表达式,因此,前不久的学习算是一次印象加深。虽然之前有过一些基础,但是这次还是耗费了一些时间,因为网上,尤其是中文科技网站太多坑要踩,所以,我在这里用最简洁的方式写下网页爬虫的入门方法,希望能够帮助到对网页爬虫感兴趣却无从下手的同学。
![]()
就如同标题指明的那样,本文主要针对入门,如果寻求进阶,或者在爬虫方面走的更远,本文提供的帮助也许是微乎其微的。本文的主要目的就是用简单的方式、简单的语言帮助对网页爬虫感兴趣的同学入门。
目前网上有关网页爬虫的指导有很多,但是套路却是千篇一律,基本都是围绕以下内容进行展开,
CSS/html等网页知识
requests或urllib
BeautifulSoup或正则表达式
Selenium或者Scrapy
对于我来说,学习爬虫知识一项获取数据的工具,而不是工作的主要内容,因此,没有太多的时间花费在上述知识成体系的学习上面。上述提到的每块都涉及大量的知识,一段时间的学习之后容易让人陷入"云里雾里",然后就丧失了学习的兴趣,没有全局观、没有重点,最终使得学习效率非常低下。
本文不详细的讲解什么是CSS/html,怎么用requests或者urllib,本文主要目的是介绍怎么去爬取一个网站、爬取我们需要的资源,可能会用到上述一个或几个模块里的知识,对我们用到的功能了解即可,没有必要从头至尾的学习一遍,希望能够用这种方法让对爬虫感兴趣的同学对这项技术有一个全局的认识,能够满足日常获取数据的需求,如果想要在这项技术上深入研究,可以后续学习其他成体系的课程,对上述模块认真、详细的学习。
准备工作很多网页爬虫的教程中使用或者提及到很多工具,本文选择以下几项工具,
网页浏览器(Google Chrome)
BeautifulSoup4
requests
网页浏览器主要用于查看网页html源码和检查网页单元使用,浏览器有很多,谷歌、火狐、IE等,每个人的喜好不同,可以根据自己的日常习惯进行选择,本文以Google Chrome为例进行讲解。
BeautifulSoup4是一个HTML、XML的解析器,它能够轻而易举的解析web网页,从中获取我们想要的单元和信息,能够避免筛选信息时的麻烦,它能够提供用于迭代、搜索、修改解析树的用法。在网页匹配过程中BeautifulSoup的速度并不比正则表达式快,甚至还要慢一些,但是它最大的优势就是简单、便捷,因此是很多网页爬虫工程中的必选工具之一。
安装
$ pip install beautifulsoup4

requests是Python大神Kenneth Reitz的力作,是一个用于网络请求的第三方库,Python已经内容了urllib模块用于访问网络资源,但是使用起来相对麻烦,而requests相比之下要方便快捷很多,因此本文选择用requests进行网络请求。
安装
$ pip install requests很多教程选择爬取糗事百科、网页图片,本文就选取另外一个方向,爬取我们常用的百度百科,这样更加直观、易于理解。
示例主要从两个方面入手,
爬取百科词条内部链接
下载词条内部包含图片

经常浏览网页,注意细节或者善于总结的会发现,网址主要有两部分组成,基础部分,和对应词条的后缀,例如上述百科词条,由基础部分https://baike.baidu.com组成,后缀是/item/林志玲/172898?fr=aladdin,因此我们要爬取一个网站首先要获取一个网址。
第一步,要确定一个目标,你要爬取什么数据?
很多人会认为,这不是废话吗?我个人认为这是很重要的,有目的才会效率更好,在没有某种目标驱动的情况下,就很难带着问题和压力去做一件事情,这样会变得漫无目的,导致效率很低,因此,我认为最重要的是首先要清楚想爬取什么数据?
网页上的音乐
图片
素材
…
本文就以爬取百度百科词条内部链接和下载图片为目标进行讲解。
第二步,我们要获取一个基础的网址,百度百科的基础网址,
https://baike.baidu.com/
第三步,打开首页,
以林志玲的百度词条为首页开始爬取。
第四步,查看源码,
很多人都知道查看源码的快捷键是F12,不管是谷歌浏览器还是IE浏览器,都是这样,但是当按下F12之后会不由得疑问,"这是什么东西?",令人毫无头绪。

当然,可以一步一步的去了解源码,学习html的知识,然后用正则表达式去一步一步、一个单元一个单元的匹配我们想要的信息,但是这样未免太复杂了,我个人推荐使用检查工具。
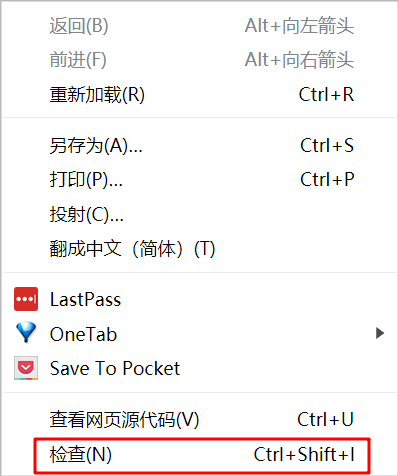
爬取内部链接
指向我们想要了解的元素,
素,鼠标右键->检查,能够快速定位我们关注的元素。
我觉得到这一步就已经够了,最简单的网页爬虫就是反复的重复以下两个步骤:
检查定位我们想要的元素和属性
BeautifulSoup4匹配我们要的信息
通过检查功能可以看到,百科词条内部链接部分的源码是这样的,
元素1:
凯渥模特经纪公司元素2:
决战刹马镇元素3:
月之恋人元素4:
AKIRA从上述4个元素可以看出,我们想要的信息词条内部链接在标签中,标签中有以下几个属性:
target:这个属性贵姓在何处打开链接文档,_blank标明浏览器总在一个新标签页载入目标文档,也就是链接href指向的文档。
href:前面已经提过很多次,属性href用于指定超链接目标的链接,如果用户选中了标签中的内容,则会尝试打开并显示href指定链接的文档。
data-*:这是html的新特性可以存储用户自定义的属性。
可以看出,我们想要的信息就在href中,也就是词条的内部链接。因此,我们爬虫的目标就很明确了,就是解析出href超链接。
到这里,浏览器检查功能已经发挥了它的作用,下一步问题就变成了我们怎么解析出标签中href的链接?
这时,BeautifulSoup4就派上用场了。
用BeautifulSoup4解析我们从网页上抓取的html,
soup = BeautifulSoup(response.text, 'html.parser')看到这里也许会疑惑,html.parser是什么?
这是一种html的解析器,Python中提供几种html解析器,它们的主要特点分别是,

综合来说,我们选取html.parser解析器,
选取好解析器之后就开始着手匹配我们想要的元素,可是看一下html发现,网页中有很多标签,我们该匹配哪一类呢?
AKIRA仔细看一下会发现特点,target="_blank",属性href以/item开头的,于是就有了我们的匹配条件,
{"target": "_blank", "href": re.compile("/item/(%.{2})+$")}用这样的匹配条件去匹配符合target、href要求的标签,
sub_urls = soup.find_all("a", {"target": "_blank", "href": re.compile("/item/(%.{2})+$")})完整代码为,
def main():
url = BASE_URL + START_PAGE
response = sessions.post(url)
response.encoding = response.apparent_encoding
soup = BeautifulSoup(response.text, 'html.parser')
sub_urls = soup.find_all("a", {
"target": "_blank", "href": re.compile("/item/(%.{2})+$")})for sub_url in sub_urls:
print(sub_url)输出结果为,
"/item/%E5%B9%B8%E7%A6%8F%E9%A2%9D%E5%BA%A6" target="_blank">幸福额度
"/item/%E5%8C%97%E4%BA%AC%C2%B7%E7%BA%BD%E7%BA%A6" target="_blank">北京·纽约
"/item/%E5%A4%9A%E4%BC%A6%E5%A4%9A%E5%A4%A7%E5%AD%A6" target="_blank">多伦多大学
"/item/%E5%88%BA%E9%99%B5" target="_blank">刺陵
"/item/%E5%86%B3%E6%88%98%E5%88%B9%E9%A9%AC%E9%95%87" target="_blank">决战刹马镇
"/item/%E5%8C%97%E4%BA%AC%C2%B7%E7%BA%BD%E7%BA%A6" target="_blank">北京·纽约
"/item/%E5%BC%A0%E5%9B%BD%E8%8D%A3" target="_blank">张国荣
"/item/%E5%A5%A5%E9%BB%9B%E4%B8%BD%C2%B7%E8%B5%AB%E6%9C%AC" target="_blank">奥黛丽·赫本
"/item/%E6%9E%97%E5%81%A5%E5%AF%B0" target="_blank">林健寰
"/item/%E6%96%AF%E7%89%B9%E7%BD%97%E6%81%A9%E4%B8%AD%E5%AD%A6" target="_blank">斯特罗恩中学
"/item/%E5%A4%9A%E4%BC%A6%E5%A4%9A%E5%A4%A7%E5%AD%A6" target="_blank">多伦多大学
"/item/%E5%8D%8E%E5%86%88%E8%89%BA%E6%A0%A1" target="_blank">华冈艺校
"/item/%E5%94%90%E5%AE%89%E9%BA%92" target="_blank">唐安麒
"/item/%E6%97%A5%E6%9C%AC%E5%86%8D%E5%8F%91%E7%8E%B0" target="_blank">日本再发现
"/item/%E4%BA%9A%E5%A4%AA%E5%BD%B1%E5%B1%95" target="_blank">亚太影展
"/item/%E6%A2%81%E6%9C%9D%E4%BC%9F" target="_blank">梁朝伟
"/item/%E9%87%91%E5%9F%8E%E6%AD%A6" target="_blank">金城武
......
在用属性字段sub_url["href"]过滤一下即可,
/item/%E5%B9%B8%E7%A6%8F%E9%A2%9D%E5%BA%A6
/item/%E5%8C%97%E4%BA%AC%C2%B7%E7%BA%BD%E7%BA%A6
/item/%E5%A4%9A%E4%BC%A6%E5%A4%9A%E5%A4%A7%E5%AD%A6
/item/%E5%88%BA%E9%99%B5
/item/%E5%86%B3%E6%88%98%E5%88%B9%E9%A9%AC%E9%95%87
/item/%E5%8C%97%E4%BA%AC%C2%B7%E7%BA%BD%E7%BA%A6
/item/%E5%BC%A0%E5%9B%BD%E8%8D%A3
......就得到了词条内部链接的后缀部分,然后和基础的url拼接在一起就是完整的内部链接地址。
同理,用同样的方法也可以爬取其他内容,比如糗事百科的笑话、专业网站的素材、百度百科的词条,当然,有些文本信息比较杂乱,这个过程中需要一些信息的筛选过程,例如利用正则表达式来匹配一段文本中有价值的信息,方法与上述大同小异。
下载图片
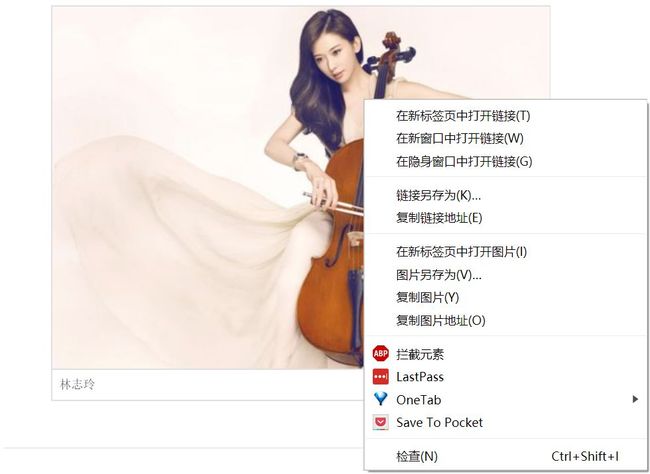
和爬取内部链接一样,要善于利用浏览器的检查功能,检查一下词条内部图片的链接,
class="picture" alt="活动照" src="https://gss2.bdstatic.com/-fo3dSag_xI4khGkpoWK1HF6hhy/baike/s%3D220/sign=85844ee8de0735fa95f049bbae500f9f/dbb44aed2e738bd49d805ec2ab8b87d6267ff9a4.jpg" style="width:198px;height:220px;">发现,图片链接存放在标签内部,用上述方法可以匹配到图片的完整链接,
response = sessions.post(url)
response.encoding = response.apparent_encoding
soup = BeautifulSoup(response.text, "html.parser")
image_urls = soup.find_all("img", {
"class": "picture"})for image_url in image_urls:
print(image_url["src"])输出如下,
https://gss2.bdstatic.com/9fo3dSag_xI4khGkpoWK1HF6hhy/baike/s%3D220/sign=36dbb0f7e1f81a4c2232ebcbe7286029/a2cc7cd98d1001e903e9168cb20e7bec55e7975f.jpg
https://gss2.bdstatic.com/-fo3dSag_xI4khGkpoWK1HF6hhy/baike/s%3D220/sign=85844ee8de0735fa95f049bbae500f9f/dbb44aed2e738bd49d805ec2ab8b87d6267ff9a4.jpg
...然后用requests发送请求,获取图片的数据,然后以读写文件的方式存储到本地,
for image_url in image_urls:
url = image_url["src"]
response = requests.get(url, headers=headers)with open(url[-10:], 'wb') as f:
f.write(response.content)
除了requests之外,还可以使用urllib.request.urlretrieve下载图片,urlretrieve相对要方便一些,但是对于大文件,requests可以分段读写,更具有优势。
上述介绍的方法是比较简单的一种,如果精力有限也可以尝试一下Selenium或者Scrapy,这两款工具的确非常强大,尤其是Selenium,它本是一款自动化测试工具,但是后来发现它同样可以用于网页爬虫,让浏览器帮助你自动爬取数据的工具,它可以以用户访问网页类似的行为去浏览网页并抓取数据,非常高效,感兴趣的可以尝试一下。
福利
我整理了一些计算机视觉、Python、强化学习、优化算法等方面的电子书籍、学习资料,同时还打包了一些我认为比较实用的工具,如果需要请关注公众号,回复相应的关键字即可获取~
![]()
发现更多精彩
关注公众号


历史推荐
●Python命令行神器之Click
●一文配置全面而强大的vim
●学习资源:图像处理从入门到精通
●【动手学计算机视觉】第六讲:传统目标检测之Harris角点检测
·end·
—如果喜欢,快分享给你的朋友们吧—
我们一起愉快的玩耍吧