kubernetes-二进制安装,亲测无坑,在参考安装过程中如果有什么问题欢迎交流,超级详细的文档
Kubernetes环境搭建(手动K8s集群安装配置、服务部署和管理使用详细步骤,入门K8s容器云平台架构)
前言
说明: 本博客是教大家如何手动搭建kubernetes集群(业内简称K8s),包括集群中所有相关服务、存储、网络等等,本博客一到九章属于第一个阶段,就已经把基本架构搭建好了,后面几章属于锦上添花并在最后部署几个开源的集群可视化管理界面。尤其对于刚入门docker/k8s的新手,可以通过一步步搭建的详细过程了解集群的架构。本博客非常长,涵盖了K8s搭建的整个过程,所有内容,花了我很长时间,大家搭建的时候不必心急非要一次性完成,可以每天完成一到两步,我初学时搭建环境也是走了很多坑,很慢花了一周才完成,加油!
我们知道,在容器技术、微服务日益发展的今天,基于docker容器技术的kubernetes集群已经在行业内已经越来越流行,成为方便易操作的轻量级云平台,使得人们更容易、更灵活地部署自己的应用、管理自己的应用。其主从架构的分布式特点也与很多其他技术框架相似,使得开发人员更容易理解上手。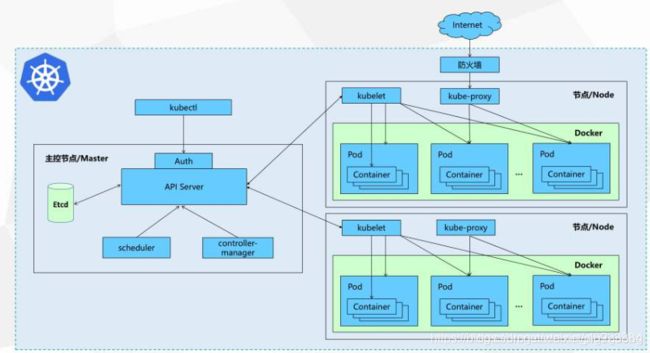
Kubernetes简介: 简称K8s,是Google开源的一个容器编排引擎,再简单地说,就是用于管理云平台中多个主机上的容器化的应用。K8s的目标是让部署容器化的应用简单并且高效,K8s提供了应用部署,规划,更新,维护的一种机制,它支持自动化部署、大规模可伸缩、应用容器化管理。 特点:
可移植: 支持公有云,私有云,混合云,多重云
可扩展: 模块化,插件化,可挂载,可组合
自动化: 自动部署,自动重启,自动复制,自动伸缩/扩展
我们知道,传统的应用部署方式是通过插件或脚本来安装应用。这样做的缺点是应用的运行、配置、管理、所有生存周期将与当前操作系统绑定,这样做并不利于应用的升级更新/回滚等操作,当然也可以通过创建虚拟机的方式来实现某些功能,但是虚拟机非常重,并不利于可移植性。
使用K8s新的方式是通过部署容器方式实现,优点是每个容器之间互相隔离,每个容器有自己的文件系统 ,容器之间进程不会相互影响,能区分计算资源。相对于虚拟机,容器能快速部署,由于容器与底层设施、机器文件系统解耦的,所以它能在不同云、不同版本操作系统间进行迁移。
容器占用资源少、部署快,每个应用可以被打包成一个容器镜像,每个应用与容器间成一对一关系也使容器有更大优势,使用容器可以在build或release 的阶段,为应用创建容器镜像,因为每个应用不需要与其余的应用堆栈组合,也不依赖于生产环境基础结构,这使得从研发到测试、生产能提供一致环境。类似地,容器比虚拟机轻量、更“透明”,这更便于监控和管理。
一般情况下:我们在K8s生产环境中部署一个应用程序时,通常要部署该应用的多个实例以便对应用请求进行负载均衡。我们可以创建多个容器,每个容器里面运行一个应用实例,然后通过内置的负载均衡策略,实现对这一组应用实例的管理、发现、访问,而这些细节都不需要运维人员去进行复杂的手工配置和处理,由集群自动化管理方便运维人员使用。
关于K8s的介绍暂时就到这里,至于K8s的各个内部组件在本章节就不一一详细说明了,在下面的各个搭建步骤中,也会为大家简单介绍每个所搭建的组件,相信大家在每步搭建的过程中会逐步了解的。下面就让我们来开始具体搭建步骤!
搭建详细步骤
一、各节点基础配置
K8s集群的节点信息如下:
操作系统:centos7.5
192.168.0.21 master01
192.168.0.22 master02
192.168.0.23 master03
192.168.0.24 node01
192.168.0.25 node02
注意说明: 我们这里搭建的kubernetes集群,是在VMWare虚拟机中搭建的五个节点,均采用centos 7.5 Server版本的系统,每个节点系统分配2G内存,20G的储存。整个集群主从架构包括3个主节点,2个子节点,相关信息如上表。
当然,并不是说一定就要搭建5个节点,节点信息也不一定非要按我上面这样设置,也不一定要像我这样分配每个节点的资源。毕竟考虑到每个人的电脑配置不同,可能受限制于自身电脑内存等影响。大家可以自己灵活选择,这丝毫不影响我们下面的搭建步骤。不过我的个人建议是:你至少至少要配置3个节点的集群(包括1个master主节点,2个slave子节点),每个节点最少最少要分配不低于1G内存,不低于15G的储存。当然具体怎么分配集群取决于你自己,你有多少数量的节点下面搭建配置过程就配置多少个,资源少点可能就跑的慢点,没有太大关系。好的,下面就让我们正式开始一步步搭建K8s集群!
1、节点基本信息配置
# 在每台机器上配置hosts解析文件(注意:这里,每个节点的hosts文件都是一样的,要配置集群所有节点的信息)
[root@master01 manifests]# cat /etc/hosts
192.168.0.21 master01
192.168.0.22 master02
192.168.0.23 master03
192.168.0.24 node01
192.168.0.25 node02
# 配置每台机器hostname名字(注意每个节点都只填自己对应的hostname)
[root@master01 manifests]# hostnamectl set-hostname 主机名字
[root@master01 manifests]# hostname 主机名字
注释临时修改立即生效
配置dns主机地址(一般为网关具体自己配置,可以访问外网)
[root@master01 manifests]# cat /etc/resolv.conf
nameserver 192.168.0.254
# 测试一下看看
[root@linux-node1 ~]# ifconfig
[root@linux-node1 ~]# ping www.baidu.com
# 节点之间都相互ping一下看看
[root@linux-node1 ~]# ping 192.168.185.132
开启 ipvs
cat > /etc/sysconfig/modules/ipvs.modules <
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4
# 设置ssh免密登录
[root@linux-node1 ~]# ssh-keygen -t rsa
# 上面这条命令,遇到什么都别管,一路回车键敲下去
# 拷贝本密钥到五个节点上
[root@master01 yum.repos.d]# ssh-copy-id master01
[root@master01 yum.repos.d]# ssh-copy-id master02
[root@master01 yum.repos.d]# ssh-copy-id master03
[root@master01 yum.repos.d]# ssh-copy-id node01
[root@master01 yum.repos.d]# ssh-copy-id node02
# 注意!!!将上面“设置ssh免密登录”和“拷贝本密钥到五个节点上”这两个步骤在其他所有节点上都要分别做一遍
# 每个节点都做完后,都要像下面这样测试一下,是否能在一个节点上免密登录到其他任何一个节点
#设置yum源
[root@master01 yum.repos.d]# ssh master01 "mkdir /etc/yum.repos.d/bak"
[root@master01 yum.repos.d]# ssh master01 "mv /etc/yum.repos.d/* /etc/yum.repos.d/bak/"
[root@master01 yum.repos.d]# wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
[root@master01 yum.repos.d]# wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
[root@master01 yum.repos.d]# yum clean all && yum makecache
#安装依赖包;
yum install epel-release
yum install -y curl git iptables conntrack ipvsadm ipset jq sysstat libseccomp vim bash-completion net-tools
#关闭防火墙、selinux 和 swap,重置 iptables:
systemctl stop firewalld && systemctl disable firewalld
sed -i 's/=enforcing/=disabled/g' /etc/selinux/config && setenforce 0
iptables -F && iptables -X && iptables -F -t nat && iptables -X -t nat && iptables -P FORWARD ACCEPT
swapoff -a
sed -i '/swap/s/^\(.*\)$/#\1/g' /etc/fstab
systemctl stop dnsmasq && systemctl disable dnsmasq
否则可能导致 docker 容器无法解析域名
#系统参数设置:
cat > /etc/sysctl.d/kubernetes.conf <
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.ipv4.ip_forward=1
vm.swappiness=0
vm.overcommit_memory=1
vm.panic_on_oom=0
fs.inotify.max_user_watches=89100
EOF
# modprobe br_netfilter
# sysctl -p /etc/sysctl.d/kubernetes.conf
安装 docker:
curl http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -o /etc/yum.repos.d/docker.repo
yum makecache fast
yum install -y docker-ce
systemctl start docker && systemctl enable docker
cat > /etc/docker/daemon.json <
{
"exec-opts":["native.cgroupdriver=cgroupfs"]
}
EOF
这步非常重要,因为我们知道,K8s技术本身就是基于docker容器技术的。安装docker时可能会很慢,这取决于你的网速问题,当然安装方法也不只我这一种,你也可以参考官方给出的其他方式安装,但务必要确保每个节点上都安装成功了docker,否则不能继续后面的操作。
2、准备K8s的相关安装配置文件
为了方便各位读者的操作,我已将所有K8s相关安装配置文件打包上传到百度云(链接:https://pan.baidu.com/s/17YxQnXd7SJhO9ucdE_IMMA 密码:urhu),提供给大家,读者可以自行下载,而不用再花费时间到处寻找了。然后将从百度云下载好的k8s-v1.10.1-manual.zip,上传到主节点的/usr/local/src下(如果不知道怎么上传,自己主机是windows可以用软件winSCP,如果自己主机是linux可以用scp命令)。上传后解压下:
[root@master01 kubernetes-bin-1.14.0]# ls master/
etcd etcdctl kubeadm kube-apiserver kube-controller-manager kubectl kube-scheduler
[root@master01 kubernetes-bin-1.14.0]# ls worker/
kubelet kube-proxy
创建bash目录分发文件到其它节点:
[root@master01 ~]# ssh root@master01 " mkdir -p /opt/kubernetes/{cfg,bin,pki,log}"
[root@master01 ~]# ssh root@master02 " mkdir -p /opt/kubernetes/{cfg,bin,pki,log}"
[root@master01 ~]# ssh root@master03 " mkdir -p /opt/kubernetes/{cfg,bin,pki,log}"
[root@master01 ~]# ssh root@node01 " mkdir -p /opt/kubernetes/{cfg,bin,pki,log}"
[root@master01 ~]# ssh root@node02 " mkdir -p /opt/kubernetes/{cfg,bin,pki,log}"
分发二进制文件
[root@master01 kubernetes-bin-1.14.0]# scp master/* master01:/opt/kubernetes/bin/
[root@master01 kubernetes-bin-1.14.0]# scp master/* master02:/opt/kubernetes/bin/
[root@master01 kubernetes-bin-1.14.0]# scp master/* master03:/opt/kubernetes/bin/
[root@master01 kubernetes-bin-1.14.0]# scp worker/* node01:/opt/kubernetes/bin/
[root@master01 kubernetes-bin-1.14.0]# scp worker/* node02:/opt/kubernetes/bin/
设置 PATH:
[root@master01 kubernetes-bin-1.14.0]# ssh root@master01 "echo 'PATH=/opt/kubernetes/bin:$PATH' >> ~/.bashrc"
[root@master01 kubernetes-bin-1.14.0]# ssh root@master02 "echo 'PATH=/opt/kubernetes/bin:$PATH' >> ~/.bashrc"
[root@master01 kubernetes-bin-1.14.0]# ssh root@master03 "echo 'PATH=/opt/kubernetes/bin:$PATH' >> ~/.bashrc"
[root@master01 kubernetes-bin-1.14.0]# ssh root@node01 "echo 'PATH=/opt/kubernetes/bin:$PATH' >> ~/.bashrc"
[root@master01 kubernetes-bin-1.14.0]# ssh root@node02 "echo 'PATH=/opt/kubernetes/bin:$PATH' >> ~/.bashrc"
[root@master01 kubernetes-bin-1.14.0]# ssh root@master01 "source ~/.bashrc"
[root@master01 kubernetes-bin-1.14.0]# ssh root@master02 "source ~/.bashrc"
[root@master01 kubernetes-bin-1.14.0]# ssh root@master03 "source ~/.bashrc"
[root@master01 kubernetes-bin-1.14.0]# ssh root@node01 "source ~/.bashrc"
[root@master01 kubernetes-bin-1.14.0]# ssh root@node02 "source ~/.bashrc"
创建证书存放路径:
[root@master02 ~]# ssh master01 "mkdir -p /etc/kubernetes/pki"
[root@master02 ~]# ssh master02 "mkdir -p /etc/kubernetes/pki"
[root@master02 ~]# ssh master03 "mkdir -p /etc/kubernetes/pki"
[root@master02 ~]# ssh node01 "mkdir -p /etc/kubernetes/pki"
[root@master02 ~]# ssh node02 "mkdir -p /etc/kubernetes/pki"
#部署K8s安装目录
# 说明一下,其中子目录cfg/下为相关配置文件,bin/目录下为可执行文件,/pki文件下为网络安全通信相关文件,log/下为日志文件
# 该/opt/kubernetes/才是我们真正的安装目录,每个节点都要配置
# 我们以后的工作,说白了就是从我们上一步准备好的相关安装配置文件中,
# 找到需要的文件,配置好后,分发到各个节点安装目录/opt/kubernetes/下对应的位置1
- 2
- 3
二、制作CA证书
kubernetes系统各组件需要使用TLS(SSL)证书对通信进行加密,我们这里使用cfssl 来生成Certificate Authority (CA) 证书和秘钥文件,CA是自签名的证书,用来签名后续创建的其它证书。
CA 证书是集群所有节点共享的,只需要创建一个 CA 证书,后续创建的所有证书都由它签名。
1、在主节点上配置已下载好的cfssl
cfssl 是非常好用的 CA 工具,我们用它来生成证书和秘钥文件。
wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64 -O /usr/local/bin/cfssl
wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64 -O /usr/local/bin/cfssljson
chmod +x /usr/local/bin/cfssl /usr/local/bin/cfssljson
cfssl version
2、创建用来生成 CA 文件的 JSON 配置文件:
[root@master01 pki]# mkdir -p /pyl/pki/
[root@master01 pki]# cd /pyl/pki/
[root@master01 pki]# cat ca-config.json
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"kubernetes": {
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
],
"expiry": "87600h"
}
}
}
}
注:
① signing :表示该证书可用于签名其它证书,生成的 ca.pem 证书中CA=TRUE ;
② server auth :表示 client 可以用该该证书对 server 提供的证书进行验证;
③ client auth :表示 server 可以用该该证书对 client 提供的证书进行验证;
3、创建用来生成 CA 证书签名请求(CSR)的 JSON 配置文件:
[root@master01 pki]# cat ca-csr.json
{
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "seven"
}
]
}
注:
① CN: Common Name ,kube-apiserver 从证书中提取该字段作为请求的用户名(User Name),浏览器使用该字段验证网站是否合法;
② O: Organization ,kube-apiserver 从证书中提取该字段作为请求用户所属的组(Group);
③ kube-apiserver 将提取的 User、Group 作为 RBAC 授权的用户标识;
4、根证书是集群所有节点共享的,只需要创建一个 CA 证书,后续创建的所有证书都由它签名,证书(ca.pem)和密钥(ca-key.pem):
[root@master01 pki]# cfssl gencert -initca ca-csr.json | cfssljson -bare ca
[root@master01 pki]# ls
ca-config.json ca-csr.json ca-key.pem ca.pem
# 拷贝到我们之前创建的用来放证书的目录下
分发到每个 master 节点,
# scp ca*.pem master01:/opt/kubernetes/pki/
# scp ca*.pem master02:/opt/kubernetes/pki/
# scp ca*.pem master03:/opt/kubernetes/pki/
三、配置etcd
etcd是Kubernetes提供默认的存储系统,保存所有集群数据,使用时需要为etcd数据提供备份计划。
etcd 是基于 Raft 的分布式 key-value 存储系统,由 CoreOS 开发,常用于服务发现、共享配置以及并发控制(如 leader 选举、分布式锁等)。kubernetes 使用 etcd 存储所有运行数据。
本文档介绍部署一个三节点高可用 etcd 集群的步骤:
① 下载和分发 etcd 二进制文件
② 创建 etcd 集群各节点的 x509 证书,用于加密客户端(如 etcdctl) 与 etcd 集群、etcd 集群之间的数据流;
③ 创建 etcd 的 systemd unit 文件,配置服务参数;
④ 检查集群工作状态;
1、创建 etcd 证书签名请求,生成 etcd 证书和私钥
# 创建
[root@master01 pki]# mkdir -p /pyl/pki/etcd/
[root@master01 pki]# cd /pyl/pki/etcd/
[root@master01 etcd]# cat etcd-csr.json
{
"CN": "etcd",
"hosts": [
"127.0.0.1",
"192.168.0.21",
"192.168.0.22",
"192.168.0.23"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "seven"
}
]
}
注:key 字段指定生成证书格式为“rsa”加密,“size”多少位的加密方式;
hosts 字段指定授权使用该证书的 etcd 节点 IP 或域名列表,这里将 etcd 集群的三个节点 IP 都列在其中
后期如果重新添加主机需要重新修改证书请求文件,并修改主机IP地址;
name: 加密的用户信息;
*1.CN: Common Name ,kube-apiserver 从证书中提取该字段作为请求的用户名(User Name),浏览器使用该字段验证网站是否合法;
*2.O: Organization ,kube-apiserver 从证书中提取该字段作为请求用户所属的组(Group);
3.ST: 证书所属区域
4.L: 证书所属组织
5.O kube-apiserver 将提取的 User、Group 作为 RBAC 授权的用户标识;
6.OU 组织单位
# 生成
[root@master01 etcd]# cfssl gencert -ca=../ca.pem \
-ca-key=../ca-key.pem \
-config=../ca-config.json \
-profile=kubernetes etcd-csr.json | cfssljson -bare etcd
[root@master01 etcd]# ls
etcd.csr etcd-csr.json etcd-key.pem etcd.pem
# 分发拷到相应位置
# scp etcd*.pem master01:/opt/kubernetes/pki/
# scp etcd*.pem master02:/opt/kubernetes/pki/
# scp etcd*.pem master03:/opt/kubernetes/pki/
4、配置etcd配置文件
[root@master01 etcd]# vim etcd.service
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
Documentation=https://github.com/coreos
[Service]
Type=notify
WorkingDirectory=/var/lib/etcd/
ExecStart=/opt/kubernetes/bin/etcd \
--data-dir=/var/lib/etcd \
--name=master01 \
--cert-file=/opt/kubernetes/pki/etcd.pem \
--key-file=/opt/kubernetes/pki/etcd-key.pem \
--trusted-ca-file=/etc/kubernetes/pki/ca.pem \
--peer-cert-file=/opt/kubernetes/pki/etcd.pem \
--peer-key-file=/opt/kubernetes/pki/etcd-key.pem \
--peer-trusted-ca-file=/opt/kubernetes/pki/ca.pem \
--peer-client-cert-auth \
--client-cert-auth \
--listen-peer-urls=https://192.168.0.21:2380 \
--initial-advertise-peer-urls=https://192.168.0.21:2380 \
--listen-client-urls=https://192.168.0.21:2379,http://127.0.0.1:2379 \
--advertise-client-urls=https://192.168.0.21:2379 \
--initial-cluster-token=etcd-cluster-0 \
--initial-cluster=master01=https://192.168.0.21:2380,master02=https://192.168.0.22:2380,master03=https://192.168.0.23:2380 \
--initial-cluster-state=new
Restart=on-failure
RestartSec=5
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
注:
User :指定账户运行默认为root;
WorkingDirectory 、 --data-dir :指定工作目录和数据目录为/opt/lib/etcd ,需在启动服务前创建这个目录;
--name :指定节点名称,当 --initial-cluster-state 值为 new 时, --name 的参数值必须位于 --initial-cluster 列表中;
--cert-file 、 --key-file :etcd server 与 client 通信时使用的证书和私钥;
--trusted-ca-file :签名 client 证书的 CA 证书,用于验证 client 证书;
--peer-cert-file 、 --peer-key-file :etcd 与 peer 通信使用的证书和私钥;
--peer-trusted-ca-file :签名 peer 证书的 CA 证书,用于验证 peer 证书;
注意!!!在其余节点上,都要对配置文件做出相应修改,这里给出在node2下需要修改配置文件的地方,其他节点也一样做出对应修改不一一赘述。
分发 etcd 服务文件到每个 master 节点,并创建数据目录,
# scp etcd.service master01:/etc/systemd/system/
# scp etcd.service master02:/etc/systemd/system/
# scp etcd.service master03:/etc/systemd/system/
# ssh root@master1 "mkdir /var/lib/etcd"
# ssh root@master2 "mkdir /var/lib/etcd"
# ssh root@master3 "mkdir /var/lib/etcd"
5、master 节点启动 etcd 服务,
# ssh root@master1 "systemctl daemon-reload && systemctl enable etcd && systemctl start etcd"
# ssh root@master2 "systemctl daemon-reload && systemctl enable etcd && systemctl start etcd"
# ssh root@master3 "systemctl daemon-reload && systemctl enable etcd && systemctl start etcd
验证etcd状态;
[root@mh-1-101 system]#systemctl status etcd #查看服务状态为ruuning
[root@mh-1-101 system]#journalctl -f -u etcd #查看日志
[root@mh-1-101 system]# netstat -luntp|grep etcd #查看端口
[root@mh-1-101 system]# etcdctl member list #查看集群信息
[root@mh-1-101 system]# etcdctl cluster-health #查看集群节点状态;
注释报错:failed to check the health of member 1f474d8df2edd45 on https://192.168.0.22:2379: Get https://192.168.0.22:2379/health: x509: certificate signed by unknown authority
etcdctl工具是一个可以对etcd数据进行管理的命令行工具,这个工具在两个不同的etcd版本下的行为方式也完全不同。
export ETCDCTL_API=2
export ETCDCTL_API=3
解决方法:
[root@k8s-master01 ssl]# export ETCDCTL_API=3
[root@k8s-master01 ssl]# systemctl restart etcd
[root@k8s-master01 ssl]# etcdctl member list
4b28ead506078a9, started, k8s-master01, https://172.18.98.21:2380, https://172.18.98.21:2379
四、在master主节点上配置Kubernetes API服务
kube-apiserver用于暴露Kubernetes API。任何的资源请求/调用操作都是通过kube-apiserver提供的接口进行。
- 创建生成CSR的 JSON 配置文件
[root@master01 pki]# mkdir apiserver/^C
[root@master01 pki]# cd apiserver/
[root@master01 apiserver]# cat kubernetes-csr.json
{
"CN": "kubernetes",
"hosts": [
"127.0.0.1",
"192.168.0.21",
"192.168.0.22",
"192.168.0.23",
"192.168.0.100",
"10.254.0.1",
"kubernetes",
"kubernetes.default",
"kubernetes.default.svc",
"kubernetes.default.svc.cluster",
"kubernetes.default.svc.cluster.local"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "seven"
}
]
}
注释:hosts中是集群中master的ip地址和vip地址
3、生成证书和私钥,并分发到所有节点
# cfssl gencert -ca=../ca.pem \
-ca-key=../ca-key.pem \
-config=../ca-config.json \
-profile=kubernetes kubernetes-csr.json | cfssljson -bare kubernetes
[root@master01 apiserver]# ls
kubernetes.csr kubernetes-csr.json kubernetes-key.pem kubernetes.pem
# scp kubernetes*.pem master01:/opt/kubernetes/pki/
# scp kubernetes*.pem master02:/opt/kubernetes/pki/
# scp kubernetes*.pem master03:/opt/kubernetes/pki/
4、创建启动文件;
[root@master01 apiserver]# cat kube-apiserver.service
[Unit]
Description=Kubernetes API Server
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
After=network.target
[Service]
ExecStart=/opt/kubernetes/bin/kube-apiserver \
--enable-admission-plugins=NamespaceLifecycle,NodeRestriction,LimitRanger,ServiceAccount,DefaultStorageClass,ResourceQuota \
--anonymous-auth=false \
--advertise-address=192.168.0.21 \
--bind-address=0.0.0.0 \
--insecure-port=0 \
--authorization-mode=Node,RBAC \
--runtime-config=api/all \
--enable-bootstrap-token-auth \
--service-cluster-ip-range=10.254.0.0/16 \
--service-node-port-range=8400-89000 \
--tls-cert-file=/opt/kubernetes/pki/kubernetes.pem \
--tls-private-key-file=/opt/kubernetes/pki/kubernetes-key.pem \
--client-ca-file=/opt/kubernetes/pki/ca.pem \
--kubelet-client-certificate=/opt/kubernetes/pki/kubernetes.pem \
--kubelet-client-key=/opt/kubernetes/pki/kubernetes-key.pem \
--service-account-key-file=/opt/kubernetes/pki/ca-key.pem \
--etcd-cafile=/opt/kubernetes/pki/ca.pem \
--etcd-certfile=/o/kptubernetes/pki/kubernetes.pem \
--etcd-keyfile=/opt/kubernetes/pki/kubernetes-key.pem \
--etcd-servers=https://192.168.0.21:2379,https://192.168.0.22:2379,https://192.168.0.23:2379 \
--enable-swagger-ui=true \
--allow-privileged=true \
--apiserver-count=3 \
--audit-log-maxage=30 \
--audit-log-maxbackup=3 \
--audit-log-maxsize=100 \
--audit-log-path=/var/log/kube-apiserver-audit.log \
--event-ttl=1h \
--alsologtostderr=true \
--logtostderr=false \
--log-dir=/var/log/kubernetes \
--v=2
Restart=on-failure
RestartSec=5
Type=notify
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
注释:!!!适当修改ip地址即可;
分发 api-server 服务文件到每个 master 节点,并创建日志目录,
# scp kube-apiserver.service master01:/opt/systemd/system/
# scp kube-apiserver.service master02:/opt/systemd/system/
# scp kube-apiserver.service master03:/opt/systemd/system/
# ssh root@master1 "mkdir /var/log/kubernetes"
# ssh root@master2 "mkdir /var/log/kubernetes"
# ssh root@master3 "mkdir /var/log/kubernetes"
master 节点启动 api-server:
# ssh root@master1 "systemctl daemon-reload && systemctl enable kube-apiserver && systemctl start kube-apiserver"
# ssh root@master2 "systemctl daemon-reload && systemctl enable kube-apiserver && systemctl start kube-apiserver"
# ssh root@master3 "systemctl daemon-reload && systemctl enable kube-apiserver && systemctl start kube-apiserver"
注意:K8s集群的 api服务的Service文件只需要部署在master主节点上,也只需要启动在主节点上。不需要分发给其他节点,在本篇博客中,如需要分发给其他的节点的东西我都会特意注释出来说明的,没说要分发的就不用做;
另外,如果你的各个节点的ip地址并不是和我一样的,别忘了把文件中涉及节点ip的地方改成你自己的哦,以后也一样
5、检查服务启动状态
# systemctl status kube-apiserver
# journalctl -f -u kube-apiserver
# [root@master01 apiserver]# netstat -lntp |grep 6443
若显示active(running),则成功。Ok,本步骤搞定!
· 部署 keepalived+nginx: 2个 master 节点安装 keepalived,2个节点部署nginx 4层代理,保证 master 节点的 api server 进程高可用。 注意:云服务器一般不支持自定义虚拟 ip,请跳过安装 keepalived。高可用可 以使用云商的负载均衡服务(比如阿里云的 SLB),把 backends 设置成你的 3 个 master 节点,然后虚拟 ip 就配置成负载均衡的内网 ip 即可。
安装 keepalived和nginx,
# ssh root@master1 "yum install -y keepalived nginx"
# ssh root@master2 "yum install -y keepalived nginx"
# ssh root@master3 "yum install -y keepalived nginx"
修改keepalived配置文件master
[root@master01 apiserver]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id 192.168.0.21
}
vrrp_script chk_nginx {
script "/etc/keepalived/check_port.sh 7443"
interval 2
weight -20
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 251
priority 100
advert_int 1
mcast_src_ip 192.168.0.21
nopreempt
authentication {
auth_type PASS
auth_pass 11111111
}
track_script {
chk_nginx
}
virtual_ipaddress {
192.168.0.100
}
修改keepalived配置文件worke节点
[root@master02 system]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id 192.168.0.22
}
vrrp_script chk_nginx {
script "/etc/keepalived/check_port.sh 7443"
interval 2
weight -20
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 251
mcast_src_ip 192.168.0.22
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 11111111
}
track_script {
chk_nginx
}
virtual_ipaddress {
192.168.0.100
}
}
keepalived防止脑裂脚本:
[root@master1 kubernetes-ha-binary]# vim /etc/keepalived/check_port.sh
#!/bin/bash
#keepalived 监控端口脚本
#使用方法:
#在keepalived的配置文件中
#vrrp_script check_port {#创建一个vrrp_script脚本,检查配置
# script "/etc/keepalived/check_port.sh 6379" #配置监听的端口
# interval 2 #检查脚本的频率,单位(秒)
#}
CHK_PORT=$1
if [ -n "$CHK_PORT" ];then
PORT_PROCESS=`ss -lnt|grep $CHK_PORT|wc -l`
if [ $PORT_PROCESS -eq 0 ];then
echo "Port $CHK_PORT Is Not Used,End."
exit 1
fi
else
echo "Check Port Cant Be Empty!"
fi
两个节点都要布置;!!!
安装nginx做4层代理(如果上边的yum源没有安装包用下边这个源)
nginx的yum源
vi /etc/yum.repos.d/nginx.repo
[nginx]
name=nginx repo
baseurl=http://nginx.org/packages/centos/7/$basearch/
gpgcheck=0
enabled=1
[root@master1 system]# yum -y install nginx
[root@master2 system]# yum -y instlal nginx
[root@master3 system]# yum -y instlal nginx
[root@master01 apiserver]# vim /etc/nginx/nginx.conf
stream {
upstream kube-apiserver {
server 192.168.0.21:6443 max_fails=3 fail_timeout=30s;
server 192.168.0.22:6443 max_fails=3 fail_timeout=30s;
server 192.168.0.23:6443 max_fails=3 fail_timeout=30s;
}
server {
listen 7443;
proxy_connect_timeout 2s;
proxy_timeout 900s;
proxy_pass kube-apiserver;
}
}
启动服务检查状态
[root@master1 system]# systemctl start nginx
[root@master1 system]# systemctl enable nginx
[root@master1 system]# systemctl status nginx
[root@master1 system]# netstat -ntulp |grep 7443
[root@master1 system]# systemctl start keepalived.service
[root@master1 system]# systemctl enable keepalived.service
[root@master1 system]# systemctl status keepalived.service
[root@master1 kubernetes-ha-binary]# ip a s | grep 192.168.0.100
inet 192.168.0.100/32 scope global ens33
[root@master1 system]# journalctl -f -u keepalived
[root@master2 system]# systemctl start keepalived.service
[root@master2 system]# systemctl enable keepalived.service
[root@master2 system]# systemctl status keepalived.service
[root@master2 system]# ip a s | grep 192.168.0.100
没有vip
[root@master2 system]# journalctl -f -u keepalived
五、在master上安装kubectl命令工具
部署 kubectl:
kubectl 是 kubernetes 集群的命令行管理工具,它默认从~/.kube/config 文件读取 kube-apiserver 地址、证书、用户名等信息。 kubectl 与 apiserver https 安全端口通信,apiserver 对提供的证书进行认证和授权。kubectl 作 为集群的管理工具,需要被授予最高权限;
生成 admin 证书、私钥,
制作证书请求文件
[root@master01 pki]# mkdir admin/
[root@master01 pki]# cd admin/
[root@master01 pki ]# vim admin-csr.json
{
"CN": "admin",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "system:masters",
"OU": "seven"
}
]
}
[root@master01 pki]# cfssl gencert -ca=../ca.pem \
-ca-key=../ca-key.pem \ -config=../ca-config.json \
-profile=kubernetes admin-csr.json | cfssljson -bare admin
[root@master01 admin]# ls
admin.csr admin-csr.json admin-key.pem admin.pem
kubeconfig 为 kubectl 的配置文件,包含访问 apiserver 的所有信息,如 apiserver 地址、CA 证书和自身使用的证书。 创建 kubeconfig 配置文件,
[root@master01 admin]# kubectl config set-cluster kubernetes \
--certificate-authority=../ca.pem \
--embed-certs=true \
--server=https://192.168.0.100:7443 \
--kubeconfig=kube.config
[root@master01 admin]# kubectl config set-credentials admin \
--client-certificate=admin.pem \
--client-key=admin-key.pem \
--embed-certs=true \
--kubeconfig=kube.config
[root@master01 admin]# kubectl config set-context kubernetes \
--cluster=kubernetes \
--user=admin \
--kubeconfig=kube.config
[root@master01 admin]# kubectl config use-context kubernetes --kubeconfig=kube.config
[root@master01 admin]# ls
admin.csr admin-csr.json admin-key.pem admin.pem kube.config
# ssh root@master01 "mkdir ~/.kube"
# ssh root@master02 "mkdir ~/.kube"
# ssh root@master03 "mkdir ~/.kube"
# scp kube.config maste0r1:~/.kube/config
# scp kube.config master02:~/.kube/config
# scp kube.config master03:~/.kube/config
在执行 kubectl 命令时,apiserver 会转发到 kubelet。这里定义 RBAC 规则,授权 apiserver 调
用 kubelet API。
[root@master1 admin]# kubectl create clusterrolebinding kube-apiserver:kubelet-apis \ --clusterrole=system:kubelet-api-admin --user kubernetes
clusterrolebinding.rbac.authorization.k8s.io/kube-apiserver:kubelet-apis created
报错:Error from server (AlreadyExists): clusterrolebindings.rbac.authorization.k8s.io "kube-apiserver:kubelet-apis" already exists
错误分析:这是因为之前已经创建过错误的签名,签名被占用,需要删除已经被占用的签名
删除签名:kubectl delete clusterrolebindings kubelet-bootstrap
kubectl delete clusterrolebindings kube-apiserver:kubelet-apis
检查kubectl命令调用状态
[root@master1 admin]# kubectl cluster-info
Kubernetes master is running at https://192.168.0.100:7443
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
[root@master1 admin]# kubectl get all --all-namespaces
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default service/kubernetes ClusterIP 10.4.0.1
[root@master1 admin]# kubectl get componentstatuses
NAME STATUS MESSAGE ERROR
scheduler Unhealthy Get http://127.0.0.1:10251/healthz: dial tcp 127.0.0.1:10251: connect: connection refused
controller-manager Unhealthy Get http://127.0.0.1:10252/healthz: dial tcp 127.0.0.1:10252: connect: connection refused
etcd-1 Healthy {"health": "true"}
etcd-2 Healthy {"health": "true"}
etcd-0 Healthy {"health": "true"}
六、在master主节点上部署Controller Manager、Kubernetes Scheduler
kube-controller-manager,运行管理控制器,它们是集群中处理常规任务的后台线程。逻辑上,每个控制器是一个单独的进程,但为了降低复杂性,它们都被编译成单个二进制文件,并在单个进程中运行。这些控制器包括:
节点(Node)控制器;
副本(Replication)控制器:负责维护系统中每个副本中的pod;
端点(Endpoints)控制器:填充Endpoints对象(即连接Services&Pods);
Service Account和Token控制器:为新的Namespace创建默认帐户访问API Token。
kube-scheduler,监视新创建没有分配到Node的Pod,为Pod选择一个Node。
部署 controller-manager(master 节点):
controller-manager 启动后将通过竞争选举机制产生一个 leader 节点,其它节点为阻塞状态。
当 leader 节点不可用后,剩余节点将再次进行选举产生新的 leader 节点,从而保证服务的
可用性。
生成证书、私钥,并分发到每个 master 节点,
制作证书请求文件
[root@master01 pki]# mkdir controller-manager/^C
[root@master01 pki]# cd controller-manager/
[root@master01 controller-manager]# vim controller-manager-csr.json
{
"CN": "system:kube-controller-manager",
"key": {
"algo": "rsa",
"size": 2048
},
"hosts": [
"127.0.0.1",
"192.168.0.21",
"192.168.0.22",
"192.168.0.23"
],
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "system:kube-controller-manager",
"OU": "seven"
}
]
}
[root@master01 controller-manager]# cfssl gencert -ca=../ca.pem \
-ca-key=../ca-key.pem \
-config=../ca-config.json \
-profile=kubernetes controller-manager-csr.json | cfssljson -bare controller-manager
[root@master01 controller-manager]# scp controller-manager*.pem master1:/etc/kubernetes/pki/
[root@master01 controller-manager]# scp controller-manager*.pem master2:/etc/kubernetes/pki/
[root@master01 controller-manager]#scp controller-manager*.pem master3:/etc/kubernetes/pki/
创建 controller-manager 的 kubeconfig,并分发到每个 master 节点,
[root@master01 controller-manager]# kubectl config set-cluster kubernetes \
--certificate-authority=../ca.pem \
--embed-certs=true \
--server=https://192.168.0.100:7443 \
--kubeconfig=controller-manager.kubeconfig
[root@master01 controller-manager]# kubectl config set-credentials system:kube-controller-manager \
--client-certificate=controller-manager.pem \
--client-key=controller-manager-key.pem \
--embed-certs=true \
--kubeconfig=controller-manager.kubeconfig
[root@master01 controller-manager]# kubectl config set-context system:kube-controller-manager \
--cluster=kubernetes \
--user=system:kube-controller-manager \
--kubeconfig=controller-manager.kubeconfig
[root@master01 controller-manager]# kubectl config use-context system:kube-controller-manager --kubeconfig=controller-manager.kubeconfig
[root@master01 controller-manager]# scp controller-manager.kubeconfig master01:/opt/kubernetes/
[root@master01 controller-manager]# scp controller-manager.kubeconfig master02:/opt/kubernetes/
[root@master01 controller-manager]# scp controller-manager.kubeconfig master03:/opt/kubernetes/
创建服务启动文件:
[root@master01 controller-manager]# vim kube-controller-manager.service
[Unit]
Description=Kubernetes Controller Manager
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
[Service]
ExecStart=/opt/kubernetes/bin/kube-controller-manager \
--kubeconfig=/opt/kubernetes/controller-manager.kubeconfig \
--service-cluster-ip-range=10.254.0.0/16 \
--cluster-name=kubernetes \
--cluster-signing-cert-file=/opt/kubernetes/pki/ca.pem \
--cluster-signing-key-file=/opt/kubernetes/pki/ca-key.pem \
--allocate-node-cidrs=true \
--cluster-cidr=172.22.0.0/16 \
--experimental-cluster-signing-duration=8760h \
--root-ca-file=/opt/kubernetes/pki/ca.pem \
--service-account-private-key-file=/opt/kubernetes/pki/ca-key.pem \
--leader-elect=true \
--feature-gates=RotateKubeletServerCertificate=true \
--controllers=*,bootstrapsigner,tokencleaner \
--horizontal-pod-autoscaler-use-rest-clients=true \
--horizontal-pod-autoscaler-sync-period=10s \
--tls-cert-file=/opt/kubernetes/pki/controller-manager.pem \
--tls-private-key-file=/opt/kubernetes/pki/controller-manager-key.pem \
--use-service-account-credentials=true \
--alsologtostderr=true \
--logtostderr=false \
--log-dir=/var/log/kubernetes \
--v=2
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
注释:修改主机ip即可!!!
分发 controller-manager 服务文件到每个 master 节点,
# cd /software/kubernetes-ha-binary/
# scp kube-controller-manager.service master01:/opt/systemd/system/
# scp kube-controller-manager.service master02:/opt/systemd/system/
# scp kube-controller-manager.service master03:/opt/systemd/system/
master 节点启动 controller-manager,
# ssh root@master1 "systemctl daemon-reload && systemctl enable kube-controller-manager && systemctl start kube-controller-manager"
# ssh root@master2 "systemctl daemon-reload && systemctl enable kube-controller-manager && systemctl start kube-controller-manager"
# ssh root@master3 "systemctl daemon-reload && systemctl enable kube-controller-manager && systemctl start kube-controller-manager"
# systemctl status kube-controller-manager
# journalctl -f -u kube-controller-manager
[root@master01 controller-manager]# kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Unhealthy Get http://127.0.0.1:10251/healthz: dial tcp 127.0.0.1:10251: connect: connection refused
controller-manager Unhealthy HTTP probe failed with statuscode: 400
etcd-1 Healthy {"health": "true"}
etcd-0 Healthy {"health": "true"}
etcd-2 Healthy {"health": "true"}
报错:Unhealthy HTTP probe failed with statuscode: 400
我们在service文件中加了--port=0和--secure-port=10252和--bind-address=127.0.0.1
这三行配置的功能是:
--port=0:关闭监听 http /metrics 的请求,同时 --address 参数无效,--bind-address 参数有效
--secure-port=10252、--bind-address=0.0.0.0: 在所有网络接口监听 10252 端口的 https /metrics 请求
这里我们去掉这三行配置:
#部署 scheduler:#
scheduler 启动后将通过竞争选举机制产生一个 leader 节点,其它节点为阻塞状态。当 leader
节点不可用后,剩余节点将再次进行选举产生新的 leader 节点,从而保证服务的可用性。
生成证书、私钥,
[root@master01 pki]# mkdir scheduler/^C
[root@master01 pki]# cd scheduler/
[root@master01 scheduler]# vim scheduler-csr.json
{
"CN": "system:kube-scheduler",
"hosts": [
"127.0.0.1",
"192.168.0.21",
"192.168.0.22",
"192.168.0.23"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "system:kube-scheduler",
"OU": "seven"
}
]
}
~
# cfssl gencert -ca=../ca.pem \
-ca-key=../ca-key.pem \
-config=../ca-config.json \
-profile=kubernetes scheduler-csr.json | cfssljson -bare kube-scheduler
[root@master01 scheduler]# ls
kube-scheduler.csr kube-scheduler-key.pem kube-scheduler.kubeconfig kube-scheduler.pem scheduler-csr.json
创建 scheduler 的 kubeconfig,并分发 kubeconfig 到每个 master 节点,
[root@master01 scheduler]# kubectl config set-cluster kubernetes \
--certificate-authority=../ca.pem \
--embed-certs=true \ --server=https://192.168.0.100:7443 \
--kubeconfig=kube-scheduler.kubeconfig
[root@master01 scheduler]# kubectl config set-credentials system:kube-scheduler \
--client-certificate=kube-scheduler.pem \
--client-key=kube-scheduler-key.pem \
--embed-certs=true \
--kubeconfig=kube-scheduler.kubeconfig
[root@master01 scheduler]# kubectl config set-context system:kube-scheduler \
--cluster=kubernetes \
--user=system:kube-scheduler \
--kubeconfig=kube-scheduler.kubeconfig
[root@master01 scheduler]# kubectl config use-context system:kube-scheduler --kubeconfig=kube-scheduler.kubeconfig
[root@master01 scheduler]# scp kube-scheduler.kubeconfig master01:/opt/kubernetes/
[root@master01 scheduler]# scp kube-scheduler.kubeconfig master02:/opt/kubernetes/
[root@master01 scheduler]# scp kube-scheduler.kubeconfig master03:/opt/kubernetes/
制作服务启动文件
[root@master01 scheduler]# vim kube-scheduler.service
[Unit]
Description=Kubernetes Scheduler
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
[Service]
ExecStart=/opt/kubernetes/bin/kube-scheduler \
--address=127.0.0.1 \
--kubeconfig=/etc/kubernetes/kube-scheduler.kubeconfig \
--leader-elect=true \
--alsologtostderr=true \
--logtostderr=false \
--log-dir=/var/log/kubernetes \
--v=2
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
注释三个master节点都一样
master 节点启动 scheduler,
# ssh root@master1 "systemctl daemon-reload && systemctl enable kube-scheduler && systemctl start kube-scheduler"
# ssh root@master2 "systemctl daemon-reload && systemctl enable kube-scheduler && systemctl start kube-scheduler"
# ssh root@master3 "systemctl daemon-reload && systemctl enable kube-scheduler && systemctl start kube-scheduler"
# systemctl status kube-scheduler
# journalctl -f -u kube-scheduler
确认安装的集群状态:
[root@master3 system]# kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-1 Healthy {"health": "true"}
etcd-0 Healthy {"health": "true"}
etcd-2 Healthy {"health": "true"}
七、在worker计算节点上部署kube-proxy kubelet
kublet 运行在每个 worker 节点上,接收 kube-apiserver 发送的请求,管理 Pod 容器,执行交互式命令,如 exec、run、logs 等。
kublet 启动时自动向 kube-apiserver 注册节点信息,内置的 cadvisor 统计和监控节点的资源使用情况。
为确保安全,本文档只开启接收 https 请求的安全端口,对请求进行认证和授权,拒绝未授权的访问(如 apiserver、heapster)。
制作批量下载镜像脚本:aliyum镜像仓库
预先下载镜像到每个 node 节点,
[root@master01 pki]# cd admin/
[root@master01 admin]# vim download-images.sh
#!/bin/bash
docker pull registry.cn-hangzhou.aliyuncs.com/liuyi01/calico-node:v3.1.3
docker tag registry.cn-hangzhou.aliyuncs.com/liuyi01/calico-node:v3.1.3 quay.io/calico/node:v3.1.3
docker rmi registry.cn-hangzhou.aliyuncs.com/liuyi01/calico-node:v3.1.3
docker pull registry.cn-hangzhou.aliyuncs.com/liuyi01/calico-cni:v3.1.3
docker tag registry.cn-hangzhou.aliyuncs.com/liuyi01/calico-cni:v3.1.3 quay.io/calico/cni:v3.1.3
docker rmi registry.cn-hangzhou.aliyuncs.com/liuyi01/calico-cni:v3.1.3
docker pull registry.cn-hangzhou.aliyuncs.com/liuyi01/pause-amd64:3.1
docker tag registry.cn-hangzhou.aliyuncs.com/liuyi01/pause-amd64:3.1 k8s.gcr.io/pause-amd64:3.1
docker rmi registry.cn-hangzhou.aliyuncs.com/liuyi01/pause-amd64:3.1
docker pull registry.cn-hangzhou.aliyuncs.com/liuyi01/calico-typha:v0.7.4
docker tag registry.cn-hangzhou.aliyuncs.com/liuyi01/calico-typha:v0.7.4 quay.io/calico/typha:v0.7.4
docker rmi registry.cn-hangzhou.aliyuncs.com/liuyi01/calico-typha:v0.7.4
docker pull registry.cn-hangzhou.aliyuncs.com/liuyi01/coredns:1.1.3
docker tag registry.cn-hangzhou.aliyuncs.com/liuyi01/coredns:1.1.3 k8s.gcr.io/coredns:1.1.3
docker rmi registry.cn-hangzhou.aliyuncs.com/liuyi01/coredns:1.1.3
docker pull registry.cn-hangzhou.aliyuncs.com/liuyi01/kubernetes-dashboard-amd64:v1.8.3
docker tag registry.cn-hangzhou.aliyuncs.com/liuyi01/kubernetes-dashboard-amd64:v1.8.3 k8s.gcr.io/kubernetes-dashboard-amd64:v1.8.3
docker rmi registry.cn-hangzhou.aliyuncs.com/liuyi01/kubernetes-dashboard-amd64:v1.8.3
[root@master01 admin]# scp download-images.sh node01:/root/
[root@master01 admin]# scp download-images.sh node02:/root/
[root@master01 admin]# ssh root@node01 "sh /root /download-images.sh"
[root@master01 admin]# ssh root@node02 "sh /root /download-images.sh"
创建 bootstrap 配置文件,并分发到每个 node 节点,
[root@master01 admin]# cd /software/kubernetes-ha-binary/target/pki/admin/
[root@master01 admin]# export BOOTSTRAP_TOKEN=$(kubeadm token create \
--description kubelet-bootstrap-token \
--groups system:bootstrappers:worker \
--kubeconfig kube.config)
[root@master01 admin]# kubectl config set-cluster kubernetes \
--certificate-authority=../ca.pem \
--embed-certs=true \
--server=https://192.168.0.100:6443 \
--kubeconfig=kubelet-bootstrap.kubeconfig
[root@master01 admin]# kubectl config set-credentials kubelet-bootstrap \
--token=${BOOTSTRAP_TOKEN} \
--kubeconfig=kubelet-bootstrap.kubeconfig
[root@master01 admin]# kubectl config set-context default \
--cluster=kubernetes \
--user=kubelet-bootstrap \
--kubeconfig=kubelet-bootstrap.kubeconfig
[root@master01 admin]# kubectl config use-context default --kubeconfig=kubelet-bootstrap.kubeconfig
[root@master01 admin]# scp kubelet-bootstrap.kubeconfig node1:/etc/kubernetes/
[root@master01 admin]# scp kubelet-bootstrap.kubeconfig node2:/etc/kubernetes/
[root@master01 admin]# scp kubelet-bootstrap.kubeconfig node3:/etc/kubernetes/
[root@master01 admin]# scp ../ca.pem node01:/opt/kubernetes/pki/
[root@master01 admin]# scp ../ca.pem node02:/opt/kubernetes/pki/
制作kubelet配置文件并分发node节点
[root@master01 admin]# vim /opt/kubernetes/kubelet.config.json
{
"kind": "KubeletConfiguration",
"apiVersion": "kubelet.config.k8s.io/v1beta1",
"authentication": {
"x509": {
"clientCAFile": "/opt/kubernetes/pki/ca.pem"
},
"webhook": {
"enabled": true,
"cacheTTL": "2m0s"
},
"anonymous": {
"enabled": false
}
},
"authorization": {
"mode": "Webhook",
"webhook": {
"cacheAuthorizedTTL": "5m0s",
"cacheUnauthorizedTTL": "30s"
}
},
"address": "192.168.0.24",
"port": 10250,
"readOnlyPort": 10255,
"cgroupDriver": "cgroupfs",
"hairpinMode": "promiscuous-bridge",
"serializeImagePulls": false,
"featureGates": {
"RotateKubeletClientCertificate": true,
"RotateKubeletServerCertificate": true
},
"clusterDomain": "cluster.local.",
"clusterDNS": ["10.254.0.2"]
制作服务启动文件
[root@master01 admin]# vim kubelet.service
[Unit]
Description=Kubernetes Kubelet
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
After=docker.service
Requires=docker.service
[Service]
WorkingDirectory=/var/lib/kubelet
ExecStart=/opt/kubernetes/bin/kubelet \
--bootstrap-kubeconfig=/opt/kubernetes/kubelet-bootstrap.kubeconfig \
--cert-dir=/kubernetes/pki \
--kubeconfig=/opt/kubernetes/kubelet.kubeconfig \
--config=/opt/kubernetes/kubelet.config.json \
--network-plugin=cni \
--pod-infra-container-image=k8s.gcr.io/pause-amd64:3.1 \
--allow-privileged=true \
--alsologtostderr=true \
--logtostderr=false \
--log-dir=/var/log/kubernetes \
--v=2
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
分发 kubelet 配置文件和服务文件到每个 node 节点,
[root@master01 admin]# scp kubelet.config.json node01:/opt/kubernetes/
[root@master01 admin]# scpkubelet.config.json node02:/opt/kubernetes/
[root@master01 admin]# scpkubelet.service node01:/etc/systemd/system/
[root@master01 admin]# scp kubelet.service node02:/etc/systemd/system/
[root@master1 admin]# scp ../ca.pem node01:/opt/kubernetes/pki/
[root@master1 admin]# scp ../ca.pem node02:/opt/kubernetes/pki/
bootstrap 附权,
[root@master01 admin]# kubectl create clusterrolebinding kubelet-bootstrap --clusterrole=system:node-bootstrapper --group=system:bootstrappers
创建bootstrap角色赋予权限用于连接apiserver请求签名时报错,修改如下所示:
[root@localhost kubeconfig]# kubectl create clusterrolebinding kubelet-bootstrap --clusterrole=system:node-bootstrapper --user=kubelet-bootstrap
Error from server (AlreadyExists): clusterrolebindings.rbac.authorization.k8s.io “kubelet-bootstrap” already exists
问题分析
这是因为之前已经创建过错误的签名,签名被占用,需要删除已经被占用的签名
问题解决
1、删除签名
kubectl delete clusterrolebindings kubelet-bootstrap
2、重新创建成功
[root@localhost kubeconfig]# kubectl create clusterrolebinding kubelet-bootstrap --clusterrole=system:node-bootstrapper --user=kubelet-bootstrap
clusterrolebinding.rbac.authorization.k8s.io/kubelet-bootstrap created
node 节点启动 kubelet,
[root@master01 admin]# ssh root@node1 "mkdir /var/lib/kubelet"
[root@master01 admin]# ssh root@node2 "mkdir /var/lib/kubelet"
[root@master01 admin]# ssh root@node3 "mkdir /var/lib/kubelet"
[root@master01 admin]# ssh root@node1 "systemctl daemon-reload && systemctl enable kubelet && systemctl start kubelet"
[root@master01 admin]# ssh root@node2 "systemctl daemon-reload && systemctl enable kubelet && systemctl start kubelet"
[root@master01 admin]# ssh root@node3 "systemctl daemon-reload && systemctl enable kubelet && systemctl start kubelet"
现象示例
提示以下信息(日志报错)
Feb 11 08:19:11 host141 kubelet[5278]: F0211 08:19:11.385889 5278 server.go:261] failed to run Kubelet: failed to create kubelet: misconfiguration: kubelet cgroup driver: "cgroupfs" is different from docker cgroup driver: "systemd"
问题确认
确认启动信息
08:16:06 host141 kubelet[5278]: I0211 08:16:06.214804 5278 flags.go:33] FLAG: --cgroup-driver="cgroupfs"
确认docker info的Cgroup
[root@host141 node]# docker info |grep Cgroup
WARNING: You're not using the default seccomp profile
Cgroup Driver: systemd
root@host141 node]#
原因确认,两者不符合,保持一直即可
对应方式
做如下修正在kubelet.server启动文件中添加这一行重新启动即可
–cgroup-driver=“cgroupfs”
->
cgroup-driver=“systemd”
再次重启
再次重启之后,问题解决
[root@host141 node]# kubectl get nodes -o wide
同意 bootstrap 请求,
# kubectl get csr
#获取 csr name NAME AGE REQUESTOR CONDITION node-csr-IxZr_CqrO0DyR8EgmEY8QzEKcVIb1fq3CakxzyNMz-E 18s system:bootstrap:2z33di Pending node-csr-TwfuVIfLWJ21im_p64jTCjnakyIAB3LYtbJ_O0bfYfg 9s system:bootstrap:2z33di Pending node-csr-oxYYnJ8-WGbxEJ8gL-Q41FHHUM2FOb8dv3g8_GNs7Ok 3s system:bootstrap:2z33di Pending
# kubectl certificate approve node-csr-IxZr_CqrO0DyR8EgmEY8QzEKcVIb1fq3CakxzyNMz-E
# kubectl certificate approve node-csr-TwfuVIfLWJ21im_p64jTCjnakyIAB3LYtbJ_O0bfYfg
# kubectl certificate approve node-csr-oxYYnJ8-WGbxEJ8gL-Q41FHHUM2FOb8dv3g8_GNs7Ok
node 节点查看服务状态与日志,
# ssh root@node1 "systemctl status kubelet"
# ssh root@node1 "journalctl -f -u kubelet
部署 kube-proxy: 生成证书、私钥,
制作证书请求文件:
[root@master01 pki]# mkdir proxy/
[root@master01 pki]# cd proxy/
[root@master01 proxy]# vim kube-proxy-csr.json
{
"CN": "system:kube-proxy",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "seven"
}
]
}
制作证书
[root@master1 proxy]# cfssl gencert -ca=../ca.pem -ca-key=../ca-key.pem -config=../ca-config.json -profile=peer kube-proxy-csr.json | cfssljson -bare kube-proxy
创建kubeconfig文件分发
[root@master1 proxy]# kubectl config set-cluster kubernetes --certificate-authority=../ca.pem --embed-certs=true --server=https://192.168.0.100:7443 --kubeconfig=kube-proxy.kubeconfig
Cluster "kubernetes" set.
[root@master1 proxy]# kubectl config set-credentials kube-proxy --client-certificate=kube-proxy.pem --client-key=kube-proxy-key.pem --embed-certs=true --kubeconfig=kube-proxy.kubeconfig
User "kube-proxy" set.
[root@master1 proxy]# kubectl config set-context default --cluster=kubernetes --user=kube-proxy --kubeconfig=kube-proxy.kubeconfig
Context "default" created.
[root@master1 proxy]# kubectl config use-context default --kubeconfig=kube-proxy.kubeconfig
Switched to context "default".
分发config文件
# scp kube-proxy.kubeconfig node1:/etc/kubernetes/
# scp kube-proxy.kubeconfig node2:/etc/kubernetes/
# scp kube-proxy.kubeconfig node3:/etc/kubernetes/
制作kube-proxy配置文件
[root@node01 ~]# vim /etc/kubernetes/kube-proxy.config.yaml
apiVersion: kubeproxy.config.k8s.io/v1alpha1
bindAddress: 192.168.0.24
clientConnection:
kubeconfig: /etc/kubernetes/kube-proxy.kubeconfig
clusterCIDR: 172.22.0.0/16
healthzBindAddress: 192.168.0.24:10256
kind: KubeProxyConfiguration
metricsBindAddress: 192.168.0.24:10249
mode: "iptables"
注释:修改主机地址即可!!!
制作kube-proxy.server启动文件
[root@node1 kubernetes]# cat /etc/systemd/system/kube-proxy.service
[Unit]
Description=Kubernetes Kube-Proxy Server
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
After=network.target
[Service]
WorkingDirectory=/var/lib/kube-proxy
ExecStart=/opt/kubernetes/bin/kube-proxy \
--config=/opt/kubernetes/kube-proxy.config.yaml \
--alsologtostderr=true \
--logtostderr=false \
--log-dir=/var/log/kubernetes \
--v=2
Restart=on-failure
RestartSec=5
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
node 节点启动 kube-proxy,
# ssh root@node1 "mkdir /var/lib/kube-proxy && mkdir /var/log/kubernetes"
# ssh root@node2 "mkdir /var/lib/kube-proxy && mkdir /var/log/kubernetes"
# ssh root@node3 "mkdir /var/lib/kube-proxy && mkdir /var/log/kubernetes"
# ssh root@node1 "systemctl daemon-reload && systemctl enable kube-proxy && systemctl start kube-proxy"
# ssh root@node2 "systemctl daemon-reload && systemctl enable kube-proxy && systemctl start kube-proxy"
# ssh root@node3 "systemctl daemon-reload && systemctl enable kube-proxy && systemctl start kube-proxy"
# ssh root@node1 "systemctl status kube-proxy"
# ssh root@node1 "journalctl -f -u kube-proxy"
八、K8s网络插件flannel与calico
1.Kubernetes的通信需求;
- 集群内:
- 容器与容器之间的通信
- Pod和Pod之间的通信
- Pod和服务之间的通信
- 集群外:
- 外部应用与服务之间的通信
需要注意的是,k8s集群初始化时的service网段,pod网段,网络插件的网段,以及真实服务器的网段,都不能相同,如果相同就会出各种各样奇怪的问题,而且这些问题在集群做好之后是不方便改的,改会导致更多的问题,所以,就在搭建前将其规划好。
1.1同一个Pod中容器之间的通信
这种场景对于Kubernetes来说没有任何问题,根据Kubernetes的架构设计。Kubernetes创建Pod时,首先会创建一个pause容器,为Pod指派一个唯一的IP地址。然后,以pause的网络命名空间为基础,创建同一个Pod内的其它容器(–net=container:xxx)。因此,同一个Pod内的所有容器就会共享同一个网络命名空间,在同一个Pod之间的容器可以直接使用localhost进行通信。
2.2 不同Pod中容器之间的通信
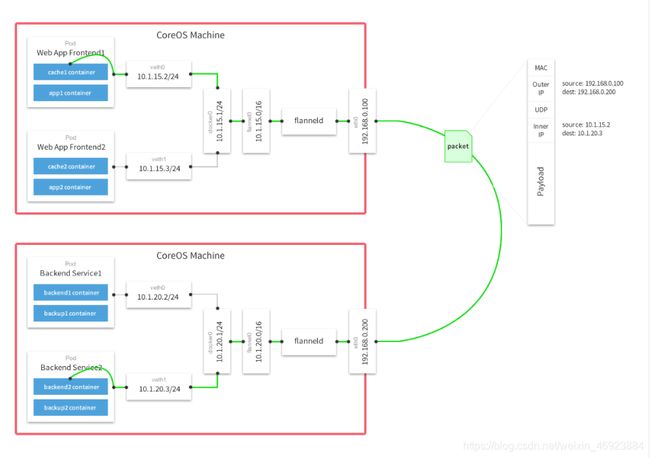
对于此场景,情况现对比较复杂一些,这就需要解决Pod间的通信问题。在Kubernetes通过flannel、calic等网络插件解决Pod间的通信问题。本文以flannel为例说明在Kubernetes中网络模型,flannel是kubernetes默认提供网络插件。Flannel是由CoreOs团队开发社交的网络工具,CoreOS团队采用L3 Overlay模式设计flannel, 规定宿主机下各个Pod属于同一个子网,不同宿主机下的Pod属于不同的子网。
flannel会在每一个宿主机上运行名为flanneld代理,其负责为宿主机预先分配一个子网,并为Pod分配IP地址。Flannel使用Kubernetes或etcd来存储网络配置、分配的子网和主机公共IP等信息。数据包则通过VXLAN、UDP或host-gw这些类型的后端机制进行转发。
CNI(容器网络接口):
这是K8s中提供的一种通用网络标准规范,因为k8s本身不提供网络解决方案。
目前比较知名的网络解决方案有:
flannel
calico
canel
kube-router
.......
等等,目前比较常用的时flannel和calico,flannel的功能比较简单,不具备复杂网络的配置能力,calico是比较出色的网络管理插件,单具备复杂网络配置能力的同时,往往意味着本身的配置比较复杂,所以相对而言,比较小而简单的集群使用flannel,考虑到日后扩容,未来网络可能需要加入更多设备,配置更多策略,则使用calico更好
所有的网络解决方案,它们的共通性:
1. 虚拟网桥
2. 多路复用:MacVLAN
3. 硬件交换:SR-IOV(单根-I/O虚拟网络):它是一种物理网卡的硬件虚拟化技术,它通过输出VF(虚拟功能)来将网卡虚拟为多个虚拟子接口,每个VF绑定给一个VM后,该VM就可以直接操纵该物理网卡。
kubelet来调CNI插件时,会到 /etc/cni/net.d/目录下去找插件的配置文件,并读取它,来加载该插件,并让该网络插件来为Pod提供网络服务。
flannel网络插件要部署方式?
1. flannel部署到那个节点上?
因为kubelet是用来管理Pod的,而Pod运行需要网络,因此凡是部署kubelet的节点,都需要部署flannel来提供网络,因为kubelet正是通过调用flannel来实现为Pod配置网络的(如:添加网络,配置网络,激活网络等)。
2. flannel自身要如何部署?
1》它支持直接运行为宿主机上的一个守护进程。
2》它也支持运行为一个Pod
对于运行为一个Pod这种方式:就必须将flannel配置为共享当前宿主机的网络名称空间的Pod,若flannel作为控制器控制的Pod来运行的话,它的控制器必须是DaemonSet,在每一个节点上都控制它仅能运行一个Pod副本,而且该副本必须直接共享宿主机的网络名称空间,因为只有这样,此Pod才能设置宿主机的网络名称空间,因为flannel要在当前宿主机的网络名称空间中创建CNI虚拟接口,还要将其他Pod的另一半veth桥接到虚拟网桥上,若不共享宿主机的网络名称空间,这是没法做到的。
3. flannel的工作方式有3种:
1) VxLAN:
而VxLAN有两种工作方式:
a. VxLAN: 这是原生的VxLAN,即直接封装VxLAN首部,UDP首部,IP,MAC首部这种的。
b. DirectRouting: 这种是混合自适应的方式, 即它会自动判断,若当前是相同二层网络
(即:不垮路由器,二层广播可直达),则直接使用Host-GW方式工作,若发现目标是需要跨网段
(即:跨路由器)则自动转变为使用VxLAN的方式。
2) host-GW: 这种方式是宿主机内Pod通过虚拟网桥互联,然后将宿主机的物理网卡作为网关,当需要访问其它Node上的Pod时,只需要将报文发给宿主机的物理网卡,由宿主机通过查询本地路由表,来做路由转发,实现跨主机的Pod通信,这种模式带来的问题时,当k8s集群非常大时,会导致宿主机上的路由表变得非常巨大,而且这种方式,要求所有Node必须在同一个二层网络中,否则将无法转发路由,这也很容易理解,因为如果Node之间是跨路由的,那中间的路由器就必须知道Pod网络的存在,它才能实现路由转发,但实际上,宿主机是无法将Pod网络通告给中间的路由器,因此它也就无法转发理由。
3) UDP: 这种方式性能最差的方式,这源于早期flannel刚出现时,Linux内核还不支持VxLAN,即没有VxLAN核心模块,因此flannel采用了这种方式,来实现隧道封装,其效率可想而知,因此也给很多人一种印象,flannel的性能很差,其实说的是这种工作模式,若flannel工作在host-GW模式下,其效率是非常高的,因为几乎没有网络开销。
Calico:
Calico为容器和虚拟机工作负载提供一个安全的网络连接。
Calico可以创建并管理一个3层平面网络,为每个工作负载分配一个完全可路由的IP地址。 工作负载可以在没有IP封装或网络地址转换的情况下进行通信,以实现裸机性能,简化故障排除和提供更好的互操作性。 在需要使用overlay网络的环境中,Calico提供了IP-in-IP隧道技术,或者也可以与flannel等其他overlay网络配合使用。
Calico还提供网络安全规则的动态配置。 使用Calico的简单策略语言,就可以实现对容器、虚拟机工作负载和裸机主机各节点之间通信的细粒度控制。
Calico是一种非常复杂的网络组件,它需要自己的etcd数据库集群来存储自己通过BGP协议获取的路由等各种所需要持久保存的网络数据信息,因此在部署Calico时,早期是需要单独为Calico部署etcd集群的,因为在k8s中,访问etcd集群只有APIServer可以对etcd进行读写,其它所有组件都必须通过APIServer作为入口,将请求发给APIServer,由APIServer来从etcd获取必要信息来返回给请求者,但Caclico需要自己写,因此就有两种部署Calico网络插件的方式,一种是部署两套etcd,另一种就是Calico不直接写,而是通过APIServer做为代理,来存储自己需要存储的数据。通常第二种使用的较多,这样可降低系统复杂度。
当然由于Calico本身很复杂,但由于很多k8s系统可能存在的问题是,早期由于各种原因使用了flannel来作为网络插件,但后期发现需要使用网络策略的需求,怎么办?
目前比较成熟的解决方案是:flannel + Calico, 即使用flannel来提供简单的网络管理功能,而使用Calico提供的网络策略功能。
Calico网络策略:
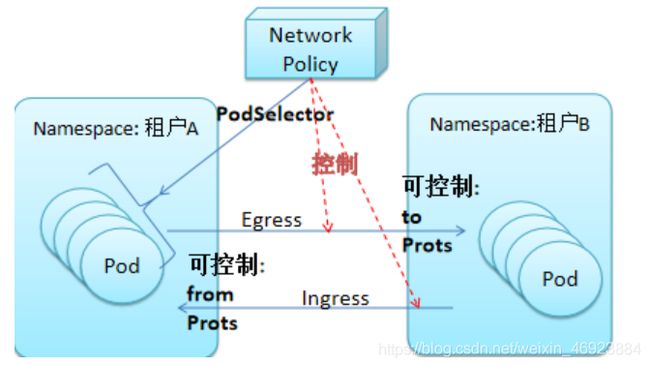
Egress:是出站的流量,即自己是源,远端为服务端,因此我自己的源IP可确定,但端口不可预知, 目标的端口和IP都是确定的,因此to 和 ports都是指目标的IP和端口。
Ingress:是入站的流量,即自己为目标,而远端是客户端,因此要做控制,就只能对自己的端口 和 客户端的地址 做控制。
我们通过Ingress 和 Egress定义的网络策略是对一个Pod生效 还是 对一组Pod生效?
这个就要通过podSelector来实现了。
而且在定义网络策略时,可以很灵活,如:入站都拒绝,仅允许出站的; 或 仅允许指定入站的,出站都允许等等。
另外,在定义网络策略时,也可定义 在同一名称空间中的Pod都可以自由通信,但跨名称空间就都拒绝。
网络策略的生效顺序:
越具体的规则越靠前,越靠前,越优先匹配
网络策略的定义:
kubectl explain networkpolicy
spec:
egress: <[]Object> :定义出站规则
ingress: <[]Object>: 定义入站规则
podSelector: 如论是入站还是出站,这些规则要应用到那些Pod上。
policyType:[Ingress|Egress| Ingress,Egress] :
它用于定义若同时定义了egress和ingress,到底那个生效?若仅给了ingress,则仅ingress生效,若设置为Ingress,Egress则两个都生效。
注意:policyType在使用时,若不指定,则当前你定义了egress就egress生效,若egress,ingress都定义了,则两个都生效!!
还有,若你定义了egress, 但policyType: ingress, egress ; egress定义了,但ingress没有定义,这种要会怎样?
其实,这时ingress的默认规则会生效,即:若ingress的默认规则为拒绝,则会拒绝所有入站请求,若为允许,则会允许所有入站请求,
所以,若你只想定义egress规则,就明确写egress !!
egress:<[]Object>
ports: <[]Object> :因为ports是有端口号 和 协议类型的,因此它也是对象列表
port :
protocol: 这两个就是用来定义目标端口和协议的。
to :<[]Object>
podSelector:
Kubernetes生产环境下的Calico网络插件安装指南
注释:占时没有测试这个文件(在官方文档中查到没有测试)
curl https://docs.projectcalico.org/v3.4/getting-started/kubernetes/installation/hosted/calico.yaml -O
床装calico rbac的yaml文件
[root@master01 addons]# cat calico-rbac-kdd.yaml
# Calico Version v3.1.3
# https://docs.projectcalico.org/v3.1/releases#v3.1.3
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: calico-node
rules:
- apiGroups: [""]
resources:
- namespaces
verbs:
- get
- list
- watch
- apiGroups: [""]
resources:
- pods/status
verbs:
- update
- apiGroups: [""]
resources:
- pods
verbs:
- get
- list
- watch
- patch
- apiGroups: [""]
resources:
- services
verbs:
- get
- apiGroups: [""]
resources:
- endpoints
verbs:
- get
- apiGroups: [""]
resources:
- nodes
verbs:
- get
- list
- update
- watch
- apiGroups: ["extensions"]
resources:
- networkpolicies
verbs:
- get
- list
- watch
- apiGroups: ["networking.k8s.io"]
resources:
- networkpolicies
verbs:
- watch
- list
- apiGroups: ["crd.projectcalico.org"]
resources:
- globalfelixconfigs
- felixconfigurations
- bgppeers
- globalbgpconfigs
- bgpconfigurations
- ippools
- globalnetworkpolicies
- globalnetworksets
- networkpolicies
- clusterinformations
- hostendpoints
verbs:
- create
- get
- list
- update
- watch
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: calico-node
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: calico-node
subjects:
- kind: ServiceAccount
name: calico-node
namespace: kube-system
制作calico.yaml文件
[root@master01 addons]# cat calico.yaml
# Calico Version v3.1.3
# https://docs.projectcalico.org/v3.1/releases#v3.1.3
# This manifest includes the following component versions:
# calico/node:v3.1.3
# calico/cni:v3.1.3
# This ConfigMap is used to configure a self-hosted Calico installation.
kind: ConfigMap
apiVersion: v1
metadata:
name: calico-config
namespace: kube-system
data:
# To enable Typha, set this to "calico-typha" *and* set a non-zero value for Typha replicas
# below. We recommend using Typha if you have more than 50 nodes. Above 100 nodes it is
# essential.
typha_service_name: "calico-typha"
# The CNI network configuration to install on each node.
cni_network_config: |-
{
"name": "k8s-pod-network",
"cniVersion": "0.3.0",
"plugins": [
{
"type": "calico",
"log_level": "info",
"datastore_type": "kubernetes",
"nodename": "__KUBERNETES_NODE_NAME__",
"mtu": 1500,
"ipam": {
"type": "host-local",
"subnet": "usePodCidr"
},
"policy": {
"type": "k8s"
},
"kubernetes": {
"kubeconfig": "__KUBECONFIG_FILEPATH__"
}
},
{
"type": "portmap",
"snat": true,
"capabilities": {"portMappings": true}
}
]
}
---
# This manifest creates a Service, which will be backed by Calico's Typha daemon.
# Typha sits in between Felix and the API server, reducing Calico's load on the API server.
apiVersion: v1
kind: Service
metadata:
name: calico-typha
namespace: kube-system
labels:
k8s-app: calico-typha
spec:
ports:
- port: 5473
protocol: TCP
targetPort: calico-typha
name: calico-typha
selector:
k8s-app: calico-typha
---
# This manifest creates a Deployment of Typha to back the above service.
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: calico-typha
namespace: kube-system
labels:
k8s-app: calico-typha
spec:
# Number of Typha replicas. To enable Typha, set this to a non-zero value *and* set the
# typha_service_name variable in the calico-config ConfigMap above.
#
# We recommend using Typha if you have more than 50 nodes. Above 100 nodes it is essential
# (when using the Kubernetes datastore). Use one replica for every 100-200 nodes. In
# production, we recommend running at least 3 replicas to reduce the impact of rolling upgrade.
replicas: 1
revisionHistoryLimit: 2
template:
metadata:
labels:
k8s-app: calico-typha
annotations:
# This, along with the CriticalAddonsOnly toleration below, marks the pod as a critical
# add-on, ensuring it gets priority scheduling and that its resources are reserved
# if it ever gets evicted.
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
hostNetwork: true
tolerations:
# Mark the pod as a critical add-on for rescheduling.
- key: CriticalAddonsOnly
operator: Exists
# Since Calico can't network a pod until Typha is up, we need to run Typha itself
# as a host-networked pod.
serviceAccountName: calico-node
containers:
- image: quay.io/calico/typha:v0.7.4
name: calico-typha
ports:
- containerPort: 5473
name: calico-typha
protocol: TCP
env:
# Enable "info" logging by default. Can be set to "debug" to increase verbosity.
- name: TYPHA_LOGSEVERITYSCREEN
value: "info"
# Disable logging to file and syslog since those don't make sense in Kubernetes.
- name: TYPHA_LOGFILEPATH
value: "none"
- name: TYPHA_LOGSEVERITYSYS
value: "none"
# Monitor the Kubernetes API to find the number of running instances and rebalance
# connections.
- name: TYPHA_CONNECTIONREBALANCINGMODE
value: "kubernetes"
- name: TYPHA_DATASTORETYPE
value: "kubernetes"
- name: TYPHA_HEALTHENABLED
value: "true"
# Uncomment these lines to enable prometheus metrics. Since Typha is host-networked,
# this opens a port on the host, which may need to be secured.
#- name: TYPHA_PROMETHEUSMETRICSENABLED
# value: "true"
#- name: TYPHA_PROMETHEUSMETRICSPORT
# value: "9093"
livenessProbe:
httpGet:
path: /liveness
port: 9098
periodSeconds: 30
initialDelaySeconds: 30
readinessProbe:
httpGet:
path: /readiness
port: 9098
periodSeconds: 10
---
# This manifest installs the calico/node container, as well
# as the Calico CNI plugins and network config on
# each master and worker node in a Kubernetes cluster.
kind: DaemonSet
apiVersion: extensions/v1beta1
metadata:
name: calico-node
namespace: kube-system
labels:
k8s-app: calico-node
spec:
selector:
matchLabels:
k8s-app: calico-node
updateStrategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
template:
metadata:
labels:
k8s-app: calico-node
annotations:
# This, along with the CriticalAddonsOnly toleration below,
# marks the pod as a critical add-on, ensuring it gets
# priority scheduling and that its resources are reserved
# if it ever gets evicted.
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
hostNetwork: true
tolerations:
# Make sure calico/node gets scheduled on all nodes.
- effect: NoSchedule
operator: Exists
# Mark the pod as a critical add-on for rescheduling.
- key: CriticalAddonsOnly
operator: Exists
- effect: NoExecute
operator: Exists
serviceAccountName: calico-node
# Minimize downtime during a rolling upgrade or deletion; tell Kubernetes to do a "force
# deletion": https://kubernetes.io/docs/concepts/workloads/pods/pod/#termination-of-pods.
terminationGracePeriodSeconds: 0
containers:
# Runs calico/node container on each Kubernetes node. This
# container programs network policy and routes on each
# host.
- name: calico-node
image: quay.io/calico/node:v3.1.3
env:
# Use Kubernetes API as the backing datastore.
- name: DATASTORE_TYPE
value: "kubernetes"
# Enable felix info logging.
- name: FELIX_LOGSEVERITYSCREEN
value: "info"
# Cluster type to identify the deployment type
- name: CLUSTER_TYPE
value: "k8s,bgp"
- name: IP_AUTODETECTION_METHOD
value: "interface=ens33"
# Disable file logging so `kubectl logs` works.
- name: CALICO_DISABLE_FILE_LOGGING
value: "true"
# Set Felix endpoint to host default action to ACCEPT.
- name: FELIX_DEFAULTENDPOINTTOHOSTACTION
value: "ACCEPT"
# Disable IPV6 on Kubernetes.
- name: FELIX_IPV6SUPPORT
value: "false"
# Set MTU for tunnel device used if ipip is enabled
- name: FELIX_IPINIPMTU
value: "1440"
# Wait for the datastore.
- name: WAIT_FOR_DATASTORE
value: "true"
# The default IPv4 pool to create on startup if none exists. Pod IPs will be
# chosen from this range. Changing this value after installation will have
# no effect. This should fall within `--cluster-cidr`.
- name: CALICO_IPV4POOL_CIDR
value: "172.22.0.0/16"
# Enable IPIP
- name: CALICO_IPV4POOL_IPIP
value: "Always"
# Enable IP-in-IP within Felix.
- name: FELIX_IPINIPENABLED
value: "true"
# Typha support: controlled by the ConfigMap.
- name: FELIX_TYPHAK8SSERVICENAME
valueFrom:
configMapKeyRef:
name: calico-config
key: typha_service_name
# Set based on the k8s node name.
- name: NODENAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
# Auto-detect the BGP IP address.
- name: IP
value: "autodetect"
- name: FELIX_HEALTHENABLED
value: "true"
securityContext:
privileged: true
resources:
requests:
cpu: 250m
livenessProbe:
httpGet:
path: /liveness
port: 9099
periodSeconds: 10
initialDelaySeconds: 10
failureThreshold: 6
readinessProbe:
httpGet:
path: /readiness
port: 9099
periodSeconds: 10
volumeMounts:
- mountPath: /lib/modules
name: lib-modules
readOnly: true
- mountPath: /var/run/calico
name: var-run-calico
readOnly: false
- mountPath: /var/lib/calico
name: var-lib-calico
readOnly: false
# This container installs the Calico CNI binaries
# and CNI network config file on each node.
- name: install-cni
image: quay.io/calico/cni:v3.1.3
command: ["/install-cni.sh"]
env:
# Name of the CNI config file to create.
- name: CNI_CONF_NAME
value: "10-calico.conflist"
# The CNI network config to install on each node.
- name: CNI_NETWORK_CONFIG
valueFrom:
configMapKeyRef:
name: calico-config
key: cni_network_config
# Set the hostname based on the k8s node name.
- name: KUBERNETES_NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
volumeMounts:
- mountPath: /host/opt/cni/bin
name: cni-bin-dir
- mountPath: /host/etc/cni/net.d
name: cni-net-dir
volumes:
# Used by calico/node.
- name: lib-modules
hostPath:
path: /lib/modules
- name: var-run-calico
hostPath:
path: /var/run/calico
- name: var-lib-calico
hostPath:
path: /var/lib/calico
# Used to install CNI.
- name: cni-bin-dir
hostPath:
path: /opt/cni/bin
- name: cni-net-dir
hostPath:
path: /etc/cni/net.d
# Create all the CustomResourceDefinitions needed for
# Calico policy and networking mode.
---
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: felixconfigurations.crd.projectcalico.org
spec:
scope: Cluster
group: crd.projectcalico.org
version: v1
names:
kind: FelixConfiguration
plural: felixconfigurations
singular: felixconfiguration
---
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: bgppeers.crd.projectcalico.org
spec:
scope: Cluster
group: crd.projectcalico.org
version: v1
names:
kind: BGPPeer
plural: bgppeers
singular: bgppeer
---
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: bgpconfigurations.crd.projectcalico.org
spec:
scope: Cluster
group: crd.projectcalico.org
version: v1
names:
kind: BGPConfiguration
plural: bgpconfigurations
singular: bgpconfiguration
---
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: ippools.crd.projectcalico.org
spec:
scope: Cluster
group: crd.projectcalico.org
version: v1
names:
kind: IPPool
plural: ippools
singular: ippool
---
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: hostendpoints.crd.projectcalico.org
spec:
scope: Cluster
group: crd.projectcalico.org
version: v1
names:
kind: HostEndpoint
plural: hostendpoints
singular: hostendpoint
---
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: clusterinformations.crd.projectcalico.org
spec:
scope: Cluster
group: crd.projectcalico.org
version: v1
names:
kind: ClusterInformation
plural: clusterinformations
singular: clusterinformation
---
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: globalnetworkpolicies.crd.projectcalico.org
spec:
scope: Cluster
group: crd.projectcalico.org
version: v1
names:
kind: GlobalNetworkPolicy
plural: globalnetworkpolicies
singular: globalnetworkpolicy
---
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: globalnetworksets.crd.projectcalico.org
spec:
scope: Cluster
group: crd.projectcalico.org
version: v1
names:
kind: GlobalNetworkSet
plural: globalnetworksets
singular: globalnetworkset
---
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: networkpolicies.crd.projectcalico.org
spec:
scope: Namespaced
group: crd.projectcalico.org
version: v1
names:
kind: NetworkPolicy
plural: networkpolicies
singular: networkpolicy
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: calico-node
namespace: kube-system
根据实际环境参数定制calico.yaml文件中的配置信息
calico.yaml用于创建出以下的资源对象:
创建名为calico-config的ConfigMap,包含Calico服务运行所需的配置信息。
创建名为calico-etcd-secrets的Secret,用于使用TLS方式连接etcd。
在每个Node上运行名为calico-node容器,部署为DaemonSet, Calico服务程序,用于设置Pod的网络资源,保证Pod的网络与各Node互联互通,它还需要以hostNetwork模式运行,直接使用宿主机网络。
通过创建一个名为install-cni的容器,在每个Node上部署Calico CNI二进制文件和网络配置相关的文件。
创建名为calico-node的ServiceAccount。
部署一个名为calico-kube-controllers的Deployment,部署一个Calico Kubernetes控制器,只允许创建出一个容器实例,用于对接k8s集群中为Pod设置的Network Policy。
创建名为calico-kube-controllers的ServiceAccount。
一般需要修改以下配置项的内容:
- 在名为calico-config的ConfigMap中,将etcd_endpoints的值设置为etcd服务器的IP地址和端口。如果你是通过https访问etcd服务的,还需要在data部分配置证书和密钥的参数。
- 在名为calico-etcd-secrets的Secret中,如果是通过https访问etcd服务的,需要配置为正确的证书和密钥信息。
- 在名为calico-node的DaemonSet中,评估是否需要按k8s集群的实际网络地址资源规划,修改CALICO_IPV4POOL_CIDR这个容器环境变量的值,该环境变量所定义的是集群网络服务将会分配使用的Pod IPs网段资源。
calico-node服务的主要参数如下:
- CALICO_IPV4POOL_CIDR:Calico IPAM的IP地址池,Pod的IP地址将从该池中进行分配。
- CALICO_IPV4POOL_IPIP:是否启用IPIP模式。启用IPIP模式时,Calico将在Node上创建一个名为”tunl0″的虚拟隧道。使用IPIP模式,设置CALICO_IPV4POOL_IPIP=“always”,不使用IPIP模式时,设置CALICO_IPV4POOL_IPIP=”off”,此时将使用BGP模式。
- FELIX_IPV6SUPPORT:是否启用IPV6。
- FELIX_LOGSEVERITYSCREEN:日志级别。
创建按calico
# kubectl create -f /etc/kubernetes/addons/calico-rbac-kdd.yaml
# kubectl create -f /etc/kubernetes/addons/calico.yaml
# kubectl get pods -n kube-system
九、测试第一个kubernetes应用
到此为止,我们已经完成了一个最基础的k8s集群搭建完成,我们来通过简单的nginx应用部署来做个测试:
1、Deployment
# 编写nginx-deployment.yaml文件
# 由文件可以看到该deployment创建了3个装有nginx的pod
root@linux-node1:~# vim nginx-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
lables:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
# 创建
root@linux-node1:~# kubectl create -f nginx-deployment.yaml --validate=false
# 查看deployment
root@linux-node1:~# kubectl get deployment
![]()
# 查看pod
root@linux-node1:~# kubectl get pod -o wide
- 1
- 2
![]()
(注意:刚开始这里的status不一定显示running,因为pod中拉取镜像需要下载时间,这取决于你的网速,有时未必能拉取成功,耐心等待,只要最后running就可以了)
2、Service
# 编写nginx-service.yaml文件
# 因为我们要通过service来映射刚刚那个deployment,即访问nginx的pod
root@linux-node1:~# vim nginx-service.yaml
kind: Service
apiVersion: v1
metadata:
name: nginx-service
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
# 创建
root@linux-node1:~# kubectl create -f nginx-service.yaml
# 查看
root@linux-node1:~# kubectl get service
- 1
![]()
红线处是这个服务的名字和虚拟访问地址。
3、测试访问nginx
因为主节点上并没有启动kube-proxy,所以你可以去任意一个子节点测试访问 nginx service,比如在node2上:
root@linux-node2:~# curl --head 10.1.196.117
- 1
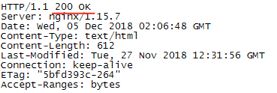
Ok,搞定!
十、ingress的安装
安装版本:ingress 0.30.0
1. 下载两个文件
https://github.com/kubernetes/ingress-nginx/blob/nginx-0.30.0/deploy/static/mandatory.yaml
https://github.com/kubernetes/ingress-nginx/blob/nginx-0.30.0/deploy/baremetal/service-nodeport.yaml
2. 在k8smaster节点执行
kubectl apply -f mandatory.yaml
kubectl apply -f service-nodeport.yaml
注释:
镜像下载可能会比较慢,请使用更快下镜像源。
可以使用以下命令修改为更快的源:
curl -sSL https://get.daocloud.io/daotools/set_mirror.sh | sh -s http://f1361db2.m.daocloud.io
修改后可以使用docker pull 命令下载好镜像再在k8s上安装ingress,在mandatory.yaml中可以找到镜像地址:
quay.io/kubernetes-ingress-controller/nginx-ingress-controller:0.30.0
耐心等待。。。
3 完成
安装完成后k8s上会新增一个命名空间 ingress-nginx, 空间里有一个pods : nginx-ingress-controller
十一、部署CoreDNS
在Kubernetes集群中,推荐使用Service Name作为服务的访问地址。因此需要一个Kubernetes集群范围的DNS服务实现从Service Name到Cluster Ip的解析,这就是Kubernetes基于DNS的服务发现功能。Kubernetes推荐使用CoreDNS作为集群内的DNS服务,所以本章我们要来部署CoreDNS。
[root@master01 addons]# cat coredns.yaml
# __MACHINE_GENERATED_WARNING__
apiVersion: v1
kind: ServiceAccount
metadata:
name: coredns
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
kubernetes.io/bootstrapping: rbac-defaults
addonmanager.kubernetes.io/mode: Reconcile
name: system:coredns
rules:
- apiGroups:
- ""
resources:
- endpoints
- services
- pods
- namespaces
verbs:
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
labels:
kubernetes.io/bootstrapping: rbac-defaults
addonmanager.kubernetes.io/mode: EnsureExists
name: system:coredns
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:coredns
subjects:
- kind: ServiceAccount
name: coredns
namespace: kube-system
---
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
labels:
addonmanager.kubernetes.io/mode: EnsureExists
data:
Corefile: |
.:53 {
errors
health
kubernetes cluster.local. in-addr.arpa ip6.arpa {
pods insecure
upstream
fallthrough in-addr.arpa ip6.arpa
}
prometheus :9153
proxy . /etc/resolv.conf
cache 30
reload
}
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: coredns
namespace: kube-system
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "CoreDNS"
spec:
# replicas: not specified here:
# 1. In order to make Addon Manager do not reconcile this replicas parameter.
# 2. Default is 1.
# 3. Will be tuned in real time if DNS horizontal auto-scaling is turned on.
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
selector:
matchLabels:
k8s-app: kube-dns
template:
metadata:
labels:
k8s-app: kube-dns
annotations:
seccomp.security.alpha.kubernetes.io/pod: 'docker/default'
spec:
serviceAccountName: coredns
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
- key: "CriticalAddonsOnly"
operator: "Exists"
containers:
- name: coredns
image: k8s.gcr.io/coredns:1.1.3
imagePullPolicy: IfNotPresent
resources:
limits:
memory: 170Mi
requests:
cpu: 100m
memory: 70Mi
args: [ "-conf", "/etc/coredns/Corefile" ]
volumeMounts:
- name: config-volume
mountPath: /etc/coredns
readOnly: true
ports:
- containerPort: 53
name: dns
protocol: UDP
- containerPort: 53
name: dns-tcp
protocol: TCP
- containerPort: 9153
name: metrics
protocol: TCP
livenessProbe:
httpGet:
path: /health
port: 8080
scheme: HTTP
initialDelaySeconds: 60
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 5
securityContext:
allowPrivilegeEscalation: false
capabilities:
add:
- NET_BIND_SERVICE
drop:
- all
readOnlyRootFilesystem: true
dnsPolicy: Default
volumes:
- name: config-volume
configMap:
name: coredns
items:
- key: Corefile
path: Corefile
---
apiVersion: v1
kind: Service
metadata:
name: kube-dns
namespace: kube-system
annotations:
prometheus.io/port: "9153"
prometheus.io/scrape: "true"
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "CoreDNS"
spec:
selector:
k8s-app: kube-dns
clusterIP: 10.254.0.2
ports:
- name: dns
port: 53
protocol: UDP
- name: dns-tcp
port: 53
protocol: TCP
# 创建
[root@master01 addons]# kubectl create -f coredns.yaml
# 查看(命令后面 “-n kube-system”意思是在系统命名空间下)
Ok,搞定!
十二、部署可视化界面:Dashboard
Kubernetes Dashboard就是k8s集群的webui,集合了所有命令行可以操作的所有命令。
准备yaml文件;
[root@master01 dashboard]# ls
admin-user-sa-rbac.yaml kubernetes-dashboard.yaml ui-admin-rbac.yaml ui-read-rbac.yaml
[root@master01 dashboard]#
[root@master01 dashboard]# kubectl create -f .
查看;
[root@master01 dashboard]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
calico-node-kzfct 2/2 Running 2 8h
calico-node-zmwnf 2/2 Running 2 8h
calico-typha-666749994b-pszxd 1/1 Running 1 8h
coredns-588555fc6b-dtkcb 1/1 Running 1 8h
kubernetes-dashboard-6f75588d94-vvrz8 1/1 Running 0 14s
tiller-deploy-6656ff698d-tlwnv 1/1 Running 0 70m
这样的话在自己主机上就可以访问dashboard可视化界面
(注意因为是要通过kube-proxy才能访问我们集群内的目标服务,我们master节点并没有启动kube-proxy,
所以我们要通过“子节点ip+服务端口号”来访问,例如:https://192.168.0.25:24424)
首次登录会出现下面这个界面:
K8S关于Dashboard浏览器访问填坑
1. 查看dashboard安装成功,访问方式nodeport的方式访问,nodeip+端口在浏览器中访问失败
2. 关于问题点关于dashboard可视化界面
然而Goole浏览器访问失败,IE也是如如此。。。
还好火狐有不安全访问模式,点击进入,瞬间感觉眼前一亮,不过kubeconfig、令牌什么鬼。。。
去后端查看token输入到web界面的token中:
按照搜罗网上方法,敲两条命令获取token粘贴复制到令牌,点击登录
kubectl get secret -n kube-system|grep dashboard-token
kubectl describe secret kubernetes-dashboard-token-c7bp9 -n kube-system
注释:kubernetes-dashboard-token-c7bp9 这个值查看的是多少就是多少id好不一样。
新问题:
部署完K8sWeb UI后,在Web上部署Pod、Service、RS、RC等资源报错
报错信息: pods is forbidden: User "system:serviceaccount:kube-system:namespace-controller" cannot create resource "pods" in API group "" in the namespace "default"
问题分析: API组中用户不能在默认命名空间创建Pod,也就是说使用原token认证登录的用户是无权操作
解决方案:
1.创建kubernetes-dashboard管理员角色
[root@k8s-master ~]# vi k8s-admin.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: dashboard-admin
namespace: kube-system
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: dashboard-admin
subjects:
- kind: ServiceAccount
name: dashboard-admin
namespace: kube-system
roleRef:
kind: ClusterRole
name: cluster-admin
apiGroup: rbac.authorization.k8s.io
[root@k8s-master ~]# kubectl create -f k8s-admin.yaml
2.获取dashboard管理员角色token
[root@k8s-master ~]# kubectl get secret -n kube-system|grep dashboard-admin
获得角色的的名字+id
[root@k8s-master ~]# kubectl describe secret dashboard-admin-token-7z6zm -n kube-system
把新的token输入到web页面的token中。搞定!!!
总结
Ok !!! 到此为止我们所有步骤都完成了!!!
欢迎参考,本文档亲测无坑,如果在参考中有什么问题欢迎骚扰,可以多多交流。
以上就是本博客《centos7.5手动搭建Kubernetes集群过程完整详细步骤(一步步入门K8s云平台架构)》的全部内容了。搭建过程中可能会遇到些小问题,不要紧张不要急,多查多看,一定要耐心操作一遍,相信你一定对K8s云平台会慢慢入门了,加油!