Python之爬取安居客网二手房小区详情页数据
哈喽,小伙伴们,前两篇博客案例基本上将爬虫基础流程介绍的差不多了,这篇博客开始放重磅炸弹,难度系数上升一些(难度1:涉及二级页面爬取,难度2:共爬取16个字段)。本文的主要内容:以石家庄市为例,爬取安居客网二手房小区的详情页的相关字段信息,关于二手房小区首页信息的爬取这里就不作过多介绍,因为与上一篇博客(Python爬取58同城在售楼盘房源信息)的爬虫步骤基本一致,感兴趣的小伙伴可以去看下呀。好了,废话不多说,开始展开~
首先,我们先打开安居客官方网站,设置好两个筛选条件:石家庄市、二手房小区(这个根据小伙伴们的兴趣自行选择),可以看到筛选出的小区有11688个,每页有25个,所以大概有468页数据,如果把所有小区数据都爬取完的话,耗费时间较多,本文主要以讲解流程为主,所以这里的话,我们主要爬取前500个小区的详情页相关字段数据,下面我们来看一下二手房小区详情页有哪些字段可以爬取?
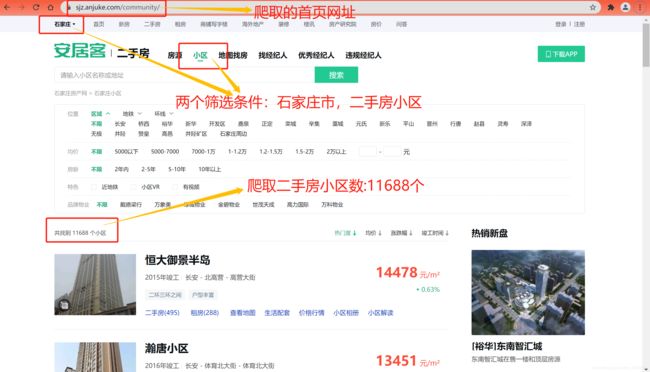
我们以首页的第一个二手房小区恒大御景半岛为例,打开小区详情页如下图,从图中可以看出,有很多字段信息,这次我们的任务就是爬取这些相关字段,主要包括:小区名称、所在区及地址、小区均价、二手房源数、租房房源数、物业类型、物业费、总建面积、总户数、竣工时间、停车位、容积率、绿化率、开发商、物业公司、所属商圈,共有16个字段。
文章开头也提到,相对于前两篇爬虫案例来说,本文爬虫案例难度要有所上升,难点主要集中在两方面:一个是二级页面爬取,另一个是爬取字段较多。不过不要慌,稳住,其实也并不难。这里我把大致的爬取流程简单说下,小伙伴们就明白怎么爬取了。大致流程:先根据小区列表页面的URL爬取每个小区详情页的URL,然后遍历每个小区详情页的URL,在循环的过程中依次爬取其详情页的相关字段信息。基本上就是循环套循环的逻辑!如果小伙伴还是不明白的话,等会直接看代码或许有意外惊喜呢!
1. 获取安居客网石家庄市二手房小区URL
关于如何获取URL,这里就不过多介绍了哈,直接放结果。如果有刚开始接触的小伙伴,可以看下我前两篇爬虫基础案例的博客。
# 首页URL
url = 'https://sjz.anjuke.com/community/p1'
# 多页爬取:为了爬取方便,这里以爬取前500个小区为例,每页25个,共有20页
for i in range(20):
url = 'https://sjz.anjuke.com/community/p{}'.format(i)2. 分析网页html代码,查看各字段信息所在的网页位置
这里的话,涉及到两个页面的html代码,一个是小区列表页面的,一个是每个小区详情页面的,我们分别来看一下:
(1)小区列表页面html代码:
在小区列表页面的话,我们只需要获取两方面内容:一个是每个小区详情页的URL,一个是每个小区的均价;
(2)小区详情页面html代码:
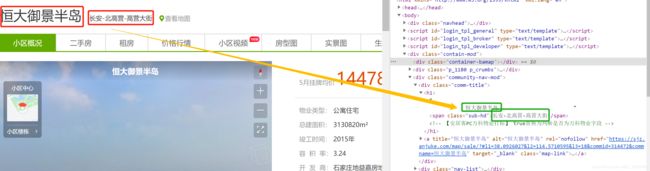
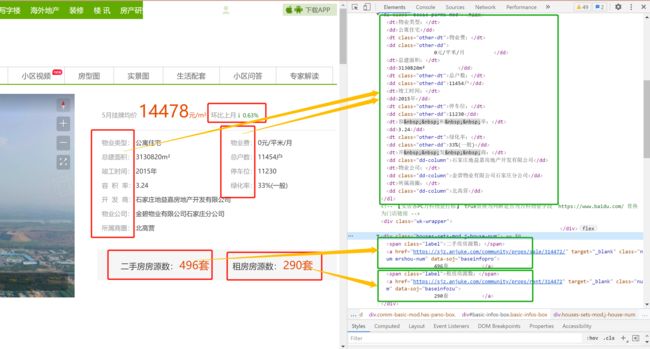
3. 利用Xpath解析网页,获取相应字段的值
(1)小区列表页面:
# 每个小区详情页URL:
link = html.xpath('.//div[@class="list-cell"]/a/@href')
# 小区均价:
price = html.xpath('.//div[@class="list-cell"]/a/div[3]/div/strong/text()')(2)小区详情页面:
dict_result = {'小区名称':'-','价格':'-','小区地址':'-','物业类型':'-','物业费': '-','总建面积': '-','总户数': '-','建造年代': '-','停车位': '-','容积率': '-','绿化率': '-','开发商': '-','物业公司': '-','所属商圈': '-','二手房源数':'-','租房房源数':'-'}
dict_result['小区名称'] = html.xpath('.//div[@class="comm-title"]/h1/text()')
dict_result['小区地址'] = html.xpath('.//div[@class="comm-title"]/h1/span/text()')
dict_result['物业类型'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[1]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[1]/text()')
dict_result['物业费'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[2]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[2]/text()')
dict_result['总建面积'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[3]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[3]/text()')
dict_result['总户数'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[4]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[4]/text()')
dict_result['建造年代'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[5]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[5]/text()')
dict_result['停车位'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[6]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[6]/text()')
dict_result['容积率'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[7]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[7]/text()')
dict_result['绿化率'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[8]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[8]/text()')
dict_result['开发商'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[9]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[9]/text()')
dict_result['物业公司'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[10]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[10]/text()')
dict_result['所属商圈'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[11]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[11]/text()')
dict_result['二手房源数'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/div[3]/a[1]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/div[3]/a[1]/text()')
dict_result['租房房源数'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/div[3]/a[2]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/div[3]/a[2]/text()')4. 首页爬取——25个小区详情页数据
一般情况下,我首先都会考虑爬取首页的内容,当首页内容所有字段信息都爬取无误后,再去加循环爬取多页内容。如果小伙伴有基础的话,可以直接跳过这一章看最后爬取所有数据的完整代码(5. 多页爬取时完整代码解析);
(1)导包以及创建文件对象
## 导入相关程序包
from lxml import etree
import requests
from fake_useragent import UserAgent
import random
import time
import csv
import re
## 创建文件对象
f = open('安居客网石家庄市二手房源信息.csv', 'w', encoding='utf-8-sig', newline="") # 创建文件对象
csv_write = csv.DictWriter(f, fieldnames=['小区名称', '价格', '小区地址', '物业类型','物业费','总建面积','总户数', '建造年代','停车位','容积率','绿化率','开发商','物业公司','所属商圈','二手房源数','租房房源数'])
csv_write.writeheader() # 写入文件头(2)设置反爬
## 设置请求头参数:User-Agent, cookie, referer
ua = UserAgent()
headers = {
# 随机生成User-Agent
"user-agent": ua.random,
# 不同用户不同时间访问,cookie都不一样,根据自己网页的来,获取方法见另一篇博客
"cookie": "sessid=C7103713-BE7D-9BEF-CFB5-6048A637E2DF; aQQ_ajkguid=263AC301-A02C-088D-AE4E-59D4B4D4726A; ctid=28; twe=2; id58=e87rkGCpsF6WHADop0A3Ag==; wmda_uuid=1231c40ad548840be4be3d965bc424de; wmda_new_uuid=1; wmda_session_id_6289197098934=1621733471115-664b82b6-8742-1591; wmda_visited_projects=%3B6289197098934; obtain_by=2; 58tj_uuid=8b1e1b8f-3890-47f7-ba3a-7fc4469ca8c1; new_session=1; init_refer=http%253A%252F%252Flocalhost%253A8888%252F; new_uv=1; _ga=GA1.2.1526033348.1621734712; _gid=GA1.2.876089249.1621734712; als=0; xxzl_cid=7be33aacf08c4431a744d39ca848819a; xzuid=717fc82c-ccb6-4394-9505-36f7da91c8c6",
# 设置从何处跳转过来
"referer": "https://sjz.anjuke.com/community/p1/",
}
## 从代理IP池,随机获取一个IP,比如必须ProxyPool项目在运行中
def get_proxy():
try:
PROXY_POOL_URL = 'http://localhost:5555/random'
response = requests.get(PROXY_POOL_URL)
if response.status_code == 200:
return response.text
except ConnectionError:
return None(3)解析一级页面函数:
主要爬取小区列表中每个小区详情页的URL和每个小区的均价;
## 解析一级页面函数
def get_link(url):
text = requests.get(url=url, headers=headers, proxies={"http": "http://{}".format(get_proxy())}).text
html = etree.HTML(text)
link = html.xpath('.//div[@class="list-cell"]/a/@href')
price = html.xpath('.//div[@class="list-cell"]/a/div[3]/div/strong/text()')
#print(link)
#print(price)
return zip(link, price)(4)解析二级页面函数,也就是小区详情页
## 解析二级页面函数
def parse_message(url, price):
dict_result = {'小区名称': '-','价格': '-','小区地址': '-','物业类型': '-',
'物业费': '-','总建面积': '-','总户数': '-','建造年代': '-',
'停车位': '-','容积率': '-','绿化率': '-','开发商': '-',
'物业公司': '-','所属商圈': '-','二手房源数':'-','租房房源数':'-'}
text = requests.get(url=url, headers=headers,proxies={"http": "http://{}".format(get_proxy())}).text
html = etree.HTML(text)
dict_result['小区名称'] = html.xpath('.//div[@class="comm-title"]/h1/text()')
dict_result['小区地址'] = html.xpath('.//div[@class="comm-title"]/h1/span/text()')
dict_result['物业类型'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[1]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[1]/text()')
dict_result['物业费'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[2]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[2]/text()')
dict_result['总建面积'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[3]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[3]/text()')
dict_result['总户数'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[4]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[4]/text()')
dict_result['建造年代'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[5]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[5]/text()')
dict_result['停车位'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[6]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[6]/text()')
dict_result['容积率'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[7]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[7]/text()')
dict_result['绿化率'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[8]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[8]/text()')
dict_result['开发商'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[9]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[9]/text()')
dict_result['物业公司'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[10]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[10]/text()')
dict_result['所属商圈'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[11]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[11]/text()')
dict_result['二手房源数'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/div[3]/a[1]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/div[3]/a[1]/text()')
dict_result['租房房源数'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/div[3]/a[2]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/div[3]/a[2]/text()')
# 对爬取到的数据进行简单预处理
for key,value in dict_result.items():
value = list(map(lambda item: re.sub('\s+', '', item), value)) # 去掉换行符制表符
dict_result[key] = list(filter(None, value)) # 去掉上一步产生的空元素
if len(dict_result[key]) == 0:
dict_result[key] = ''
else:
dict_result[key] = dict_result[key][0]
dict_result['价格'] = price
return dict_result(5)保存数据到文件save_csv()函数
## 将数据读取到csv文件中
def save_csv(result):
for row in result: # 一个小区数据存放到一个字典中
csv_write.writerow(row)(6)只爬取首页时的主函数
#主函数
C = 1
k = 1 # 爬取房源条数
print("************************第1页开始爬取************************")
# 第一页URL
url = 'https://sjz.anjuke.com/community/p1'
# 解析一级页面函数,函数返回详情页URL和均价
link = get_link(url)
list_result = [] # 将字典数据存入到列表中
for j in link:
try:
# 解析二级页面函数,分别传入详情页URL和均价两个参数
result = parse_message(j[0], j[1])
list_result.append(result)
print("已爬取{}条数据".format(k))
k = k + 1 # 控制爬取的小区数
time.sleep(round(random.randint(5, 10), C)) # 设置睡眠时间间隔
except Exception as err:
print("-----------------------------")
print(err)
# 保存数据到文件中
save_csv(list_result)
print("************************第1页爬取成功************************")5. 多页爬取——完整代码解析
由于代码较长,小伙伴一定要耐心阅读,刚开始学习爬虫的小伙伴,可以先看看上面第4部分,学会爬取首页数据后,再来看爬取多页数据就会轻松很多;
## 导入相关程序包
from lxml import etree
import requests
from fake_useragent import UserAgent
import random
import time
import csv
import re
## 创建文件对象
f = open('安居客网石家庄市二手房源信息.csv', 'w', encoding='utf-8-sig', newline="") # 创建文件对象
csv_write = csv.DictWriter(f, fieldnames=['小区名称', '价格', '小区地址', '物业类型','物业费','总建面积','总户数', '建造年代','停车位','容积率','绿化率','开发商','物业公司','所属商圈','二手房源数','租房房源数'])
csv_write.writeheader() # 写入文件头
## 设置请求头参数:User-Agent, cookie, referer
ua = UserAgent()
headers = {
# 随机生成User-Agent
"user-agent": ua.random,
# 不同用户不同时间访问,cookie都不一样,根据自己网页的来,获取方法见另一篇博客
"cookie": "sessid=C7103713-BE7D-9BEF-CFB5-6048A637E2DF; aQQ_ajkguid=263AC301-A02C-088D-AE4E-59D4B4D4726A; ctid=28; twe=2; id58=e87rkGCpsF6WHADop0A3Ag==; wmda_uuid=1231c40ad548840be4be3d965bc424de; wmda_new_uuid=1; wmda_session_id_6289197098934=1621733471115-664b82b6-8742-1591; wmda_visited_projects=%3B6289197098934; obtain_by=2; 58tj_uuid=8b1e1b8f-3890-47f7-ba3a-7fc4469ca8c1; new_session=1; init_refer=http%253A%252F%252Flocalhost%253A8888%252F; new_uv=1; _ga=GA1.2.1526033348.1621734712; _gid=GA1.2.876089249.1621734712; als=0; xxzl_cid=7be33aacf08c4431a744d39ca848819a; xzuid=717fc82c-ccb6-4394-9505-36f7da91c8c6",
# 设置从何处跳转过来
"referer": "https://sjz.anjuke.com/community/p1/",
}
## 从代理IP池,随机获取一个IP,比如必须ProxyPool项目在运行中
def get_proxy():
try:
PROXY_POOL_URL = 'http://localhost:5555/random'
response = requests.get(PROXY_POOL_URL)
if response.status_code == 200:
return response.text
except ConnectionError:
return None
## 解析一级页面函数
def get_link(url):
text = requests.get(url=url, headers=headers, proxies={"http": "http://{}".format(get_proxy())}).text
html = etree.HTML(text)
link = html.xpath('.//div[@class="list-cell"]/a/@href')
price = html.xpath('.//div[@class="list-cell"]/a/div[3]/div/strong/text()')
#print(link)
#print(price)
return zip(link, price)
## 解析二级页面函数
def parse_message(url, price):
dict_result = {'小区名称': '-','价格': '-','小区地址': '-','物业类型': '-',
'物业费': '-','总建面积': '-','总户数': '-','建造年代': '-',
'停车位': '-','容积率': '-','绿化率': '-','开发商': '-',
'物业公司': '-','所属商圈': '-','二手房源数':'-','租房房源数':'-'}
text = requests.get(url=url, headers=headers,proxies={"http": "http://{}".format(get_proxy())}).text
html = etree.HTML(text)
dict_result['小区名称'] = html.xpath('.//div[@class="comm-title"]/h1/text()')
dict_result['小区地址'] = html.xpath('.//div[@class="comm-title"]/h1/span/text()')
dict_result['物业类型'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[1]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[1]/text()')
dict_result['物业费'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[2]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[2]/text()')
dict_result['总建面积'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[3]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[3]/text()')
dict_result['总户数'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[4]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[4]/text()')
dict_result['建造年代'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[5]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[5]/text()')
dict_result['停车位'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[6]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[6]/text()')
dict_result['容积率'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[7]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[7]/text()')
dict_result['绿化率'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[8]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[8]/text()')
dict_result['开发商'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[9]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[9]/text()')
dict_result['物业公司'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[10]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[10]/text()')
dict_result['所属商圈'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/dl/dd[11]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/dl/dd[11]/text()')
dict_result['二手房源数'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/div[3]/a[1]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/div[3]/a[1]/text()')
dict_result['租房房源数'] = html.xpath('.//div[@class="comm-basic-mod "]/div[2]/div[3]/a[2]/text()|.//div[@class="comm-basic-mod has-pano-box "]/div[2]/div[3]/a[2]/text()')
# 对爬取到的数据进行简单预处理
for key,value in dict_result.items():
value = list(map(lambda item: re.sub('\s+', '', item), value)) # 去掉换行符制表符
dict_result[key] = list(filter(None, value)) # 去掉上一步产生的空元素
if len(dict_result[key]) == 0:
dict_result[key] = ''
else:
dict_result[key] = dict_result[key][0]
dict_result['价格'] = price
return dict_result
## 将数据读取到csv文件中
def save_csv(result):
for row in result:
csv_write.writerow(row)
## 主要代码
C = 1
k = 1 # 爬取房源条数
# 多页爬取,由于时间所限,只爬取前500个小区详情数据,后续感兴趣的小伙伴可以自行爬取
for i in range(1,21): #每页25个小区,前500个就是20页
print("************************" + "第%s页开始爬取" % i + "************************")
url = 'https://sjz.anjuke.com/community/p{}'.format(i)
# 解析一级页面函数,函数返回详情页URL和均价
link = get_link(url)
list_result = [] # 定义一个列表,存放每个小区字典数据
for j in link:
try:
# 解析二级页面函数,分别传入详情页URL和均价两个参数
result = parse_message(j[0], j[1])
list_result.append(result) # 将字典数据存入到列表中
print("已爬取{}条数据".format(k))
k = k + 1 # 控制爬取的小区数
time.sleep(round(random.randint(1,3), C)) # 设置睡眠时间间隔,控制两级页面访问时间
except Exception as err:
print("-----------------------------")
print(err)
# 保存数据到文件中
save_csv(list_result)
time.sleep(random.randint(1,3)) # 设置睡眠时间间隔,控制一级页面访问时间
print("************************" + "第%s页爬取成功" % i + "************************")6. 最终爬取到的数据
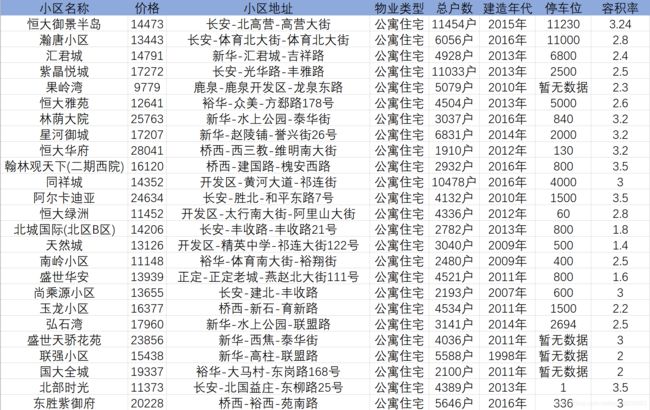
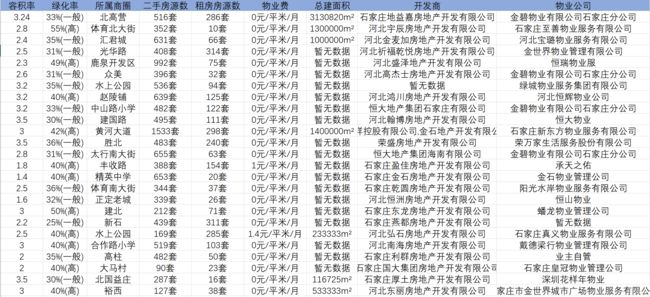
好了,到此第三个爬虫案例就差不多结束了,本文主要利用Xpath爬取安居客网石家庄市二手房小区详情页相关数据,该案例相对于前两个案例来说,难度上升了一个层次,难点主要体现在两方面:一个是涉及到二级页面的爬取,需要从一级页面中获取二级页面的URL;另一个就是爬取的字段较多,需要不断去尝试查看相应字段是否可以爬取成功。总体来说,难度虽然上升了,但是只要小伙伴们能够坚持阅读下来,相信会有不小的收获呢!当初我这个小白学的时候,第一感觉就是爬虫还可以这么玩,还是蛮有意思的!关于后续的博客计划,以前在学习过程中,还爬取过百度地图POI数据、大众点评等,这或许是我下一步要总结的,如果小伙伴感兴趣的话,可以来波关注,嘿嘿!
如果哪里有介绍的不是很全面的地方,欢迎小伙伴在评论区留言,我会不断完善的!
来都来了,确定不留下点什么嘛,嘻嘻~
