MySQL各种索引算法
Mysql各种索引算法
--洱涷
首先梳理一下当我们在数据库中输入一个SQL进行查询时,DBMS(数据库管理系统)所经历的流程:
- 对sql语法进行校验,看齐是否符合sql语法规则
- 对合法的语句进行语义检查,即根据数据字典中有关模式定义检查数据库对应是否有效
- 查询优化,在DBMS中每一个查询都有许多可以选择的执行策略和操作算法,查询优化即选择其中一个较高效的去执行
- 根据上一步优化器得到的执行策略生成查询执行计划,有代码生成器生成执行这个查询计划的代码,然后执行代码,回送查询结果
在上述步骤的3中的查询算法分为以下两种:
- 全表扫描算法
- 索引扫描算法
全表扫描算法
全表扫描就是对数据库服务器用来搜寻表的每一条记录的过程,直到所有符合给定条件的记录都被返回为止(基本没人用),因为查询一笔数据还是查询多笔数据,查询的数据成本是不变的,如果只想要一条数据,如果表小那还好,如果数据量很大,那么效率将会非常低,所以日常业务不会考虑,针对上述情况,索引查询应运而生
索引扫描算法
索引的思想就是根据表中的某一条属性建立一套算法,每次查询时,在内存中根据该算法得到所需数据的物理存储地址,根据地址直接去内存中获取结果数据,就像查字典时根据偏旁或拼音获得该字的页码然后获取结果
索引的扫描算法有很多种,常见的是B-Tree,B+Tree,hash。MySQL默认建表查询索引为B+tree索引
B-Tree
B-树,这里的 B 表示 balance( 平衡的意思),B-树是一种多路自平衡的搜索树(B树是一颗多路平衡查找树),它类似普通的平衡二叉树,不同的一点是B-树允许每个节点有更多的子节点。下图是 B-树的简化图.
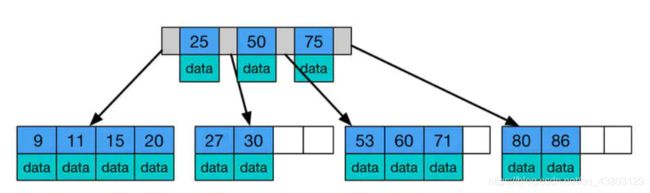
B-树有如下特点:
- 所有键值分布在整颗树中(索引值和具体data都在每个节点里);
- 任何一个关键字出现且只出现在一个结点中;
- 搜索有可能在非叶子结点结束(最好情况O(1)就能找到数据);
- 在关键字全集内做一次查找,性能逼近二分查找;
传统用来搜索的平衡二叉树有很多,如 AVL 树,红黑树等。这些树在一般情况下查询性能非常好,但当数据非常大的时候它们就无能为力了。原因当数据量非常大时,内存不够用,大部分数据只能存放在磁盘上,只有需要的数据才加载到内存中。一般而言内存访问的时间约为 50 ns,而磁盘在 10 ms 左右。速度相差了近 5 个数量级,磁盘读取时间远远超过了数据在内存中比较的时间。这说明程序大部分时间会阻塞在磁盘 IO 上。那么我们如何提高程序性能?减少磁盘 IO 次数,像 AVL 树,红黑树这类平衡二叉树从设计上无法“迎合”磁盘。
平衡二叉树是通过旋转来保持平衡的,而旋转是对整棵树的操作,若部分加载到内存中则无法完成旋转操作。其次平衡二叉树的高度相对较大为 log n(底数为2),这样逻辑上很近的节点实际可能非常远,无法很好的利用磁盘预读(局部性原理),所以这类平衡二叉树在数据库和文件系统上的选择就被 pass 了。
B-树的设计原理
索引的效率依赖于磁盘 IO 的次数,快速索引需要有效的减少磁盘 IO 次数,如何快速索引呢?索引的原理其实是不断的缩小查找范围,就如我们平时用字典查单词一样,先找首字母缩小范围,再第二个字母等等。平衡二叉树是每次将范围分割为两个区间。为了更快,B-树每次将范围分割为多个区间,区间越多,定位数据越快越精确。那么如果节点为区间范围,每个节点就较大了。所以新建节点时,直接申请页大小的空间(磁盘存储单位是按 block 分的,一般为 512 Byte。磁盘 IO 一次读取若干个 block,我们称为一页,具体大小和操作系统有关,一般为 4 k,8 k或 16 k),计算机内存分配是按页对齐的,这样就实现了一个节点只需要一次 IO。
B-树的查找策略
我们来看看B-树的查找,假设每个节点有 n 个 key值,被分割为 n+1 个区间,注意,每个 key 值紧跟着 data 域,这说明B-树的 key 和 data 是聚合在一起的。一般而言,根节点都在内存中,B-树以每个节点为一次磁盘 IO,比如上图中,若搜索 key 为15 节点的 data,首先在根节点进行二分查找(因为 keys 有序,二分最快),判断 key 15 小于 key 25,所以定位到最左侧的节点,此时进行一次磁盘 IO,将该节点从磁盘读入内存,接着继续进行上述过程,直到找到该 key 为止。
B+Tree
B+树是B-树的变体,也是一种多路搜索树,将相关数据构建成一棵B+树,通过索引获取查询想要的的结果。
B+树举例:
B+树不是二叉树,其特征大概分为以下几点:
-
B+树不是二叉树,m阶的B+树其子树最多分m叉
-
所有的叶子节点位于同一层
-
所有的叶子节点包含了全部的元素信息,即包含指向这些元素的指针
-
叶子节点本身依靠关键字的大小从小到大依次顺序链接
-
所有的中间节点只保存索引信息,不保存数据信息(也就是说想找到数据,必须从根节点找到叶子节点)
-
所有中间结点的元素都存在于子节点上,在子节点元素中是最大或者最小的元素
以上特征在图中的体现:
- 首先根节点中的8在第二层左孩子(2,5,8)中是最大的数,在第三层(6,8)中也为最大,根节点中的15在其右子树中也是按照此规律,这样做的好处是划清了界限,下文中会具体解释。
- 所有的叶子节点构成了一个有序链表,链表的构造是将存放数据的存储单元分为两部分,一部分存储数据,一部分存储下个单元的地址信息,这样很多元素通过地址绑定起来,形成链表。
- 卫星数据都存放在叶子节点中,卫星数据就是指索引最终指向的数据记录,而这一行信息的地址一定是存放在叶子节点中的,那么中间这么多节点有何作用呢?中间节点存放的索引信息是为了更快捷的找到对应的叶子节点。
B+树的优势
- 单一节点存放更多的元素(因为中间节点不存放元素,所以节省了很多的空间给存放元素,并且还能减少IO次数)
- 所有查询都需要到叶子节点,查询性能稳定
- 叶子节点中的有序链表便于范围查询
思考:B+树为何如此设计

因为B+树的优点主要在于查询性能,所以我们可以通过单元素查询和范围查询分析一下
单元素查询:如上图所示,如果想要查找到元素36,第一次IO将根节点所在的磁盘块加载进内存,使用二分查找,找到指针P3,根据p3将磁盘块4加载到内存中,这是第二次IO,又根据36<65,找到指针P1,然后进行第三次IO将磁盘块9加载进内存,最终找到数据。
这种查找方式相较于遍历查找效率要高很多,并且时间复杂度更稳定,为什么?举个栗子:假设我们只找一个元素,那么在对所有元素进行遍历的情况下,存在很大的偶然性,最好情况就是第一个就找到,最坏则是最后一个,所以很不稳定。
范围查找:比如我们查找5-15之间的所有元素,因为B+树中维护了叶子结点的链表结构,所以我们只需要找到范围的下限即5,然后通过有序链表往下游遍历即可
(tips:B-树在范围查询时是通过中序遍历不断查找的)
思考:B+树为何能一直保持平衡
这跟B+树的构建与插入有关,B+树插入的时候,会先进行查找,找到该值对应节点,进行插入,如果节点中的关键字不超过M-1(如果为3阶B+树,则不超过2)则直接插入成功,如果超过M-1,则节点进行分裂,将该节点添加到父级节点中,以此类推。
思考:为什么MySQL的索引默认使用B+树,而不是其他,比如B树?
因为B树不管叶子节点还是非叶子节点都会保存数据,这样导致非叶子节点中能保存的指针数量变少(扇出),指针少的情况下若保存大量数据,只能通过增加树的高度,增加IO操作,使得查询性能变低。
Hash
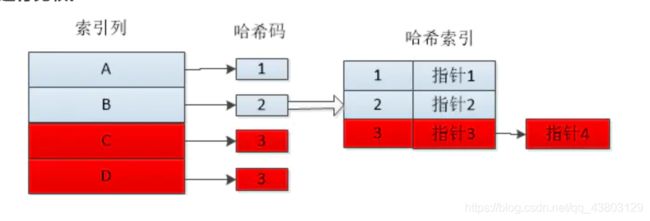
Hash索引基于哈希表实现,只有匹配所有列的查询才有效。对于每一行数据,存储引擎都会对所有索引列计算一个哈希码,哈希码是一个较小的值,不同键值的行计算出的哈希码也不一样。哈希索引将所有的哈希码存储在索引中,同时保存指向每个数据行的指针。

如果多个列的哈希值相同,索引会以链表的方式存放多个记录指针到同一个哈希条目中去。
举例:
CREATE TABLE `testhash` (
`fname` varchar(50) DEFAULT NULL,
`lname` varchar(50) DEFAULT NULL,
KEY `fname` (`fname`) USING HASH
) ENGINE=MEMORY;
为什么用MEMORY存储引擎,因为mysql只有MEMORY存储引擎显示支持哈希索引。
表包含数据:select * from testhash

假设索引使用哈希函数f()来生成哈希码:
f(‘Arjen’)=2323
f(‘Baron’)=7437
f(‘Peter’)=8784
f(‘Vadim’)=2458
则,哈希索引的数据结构是:
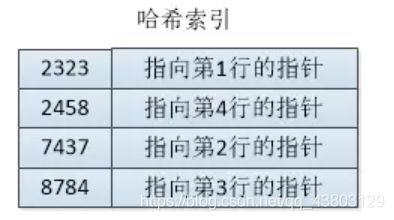
哈希表中哈希码是顺序的,导致对应的数据行是乱序的。看如下查询:
`select lname from testhash where fname ='Peter'`
Mysql首先计算Peter的哈希值是8784,然后到哈希索引中找到对应的行指针,根据指针找到对应的数据行。
索引只存储哈希码及行指针,所以索引的数据结构非常的紧凑,这也让哈希索引查找速度非常快,但是哈希索引也有他的限制。
哈希索引限制
-
哈希索引只保存哈希码和指针,而不存储字段值,所以不能使用索引中的值来避免读取行。不过访问内存中的行速度非常快(因为是MEMORY引擎),所以对性能影响并不大
-
哈希索引数据并不是按照索引值顺序存储的,所以无法用于排序
-
哈希索引不支持部分索引列查找,因为哈希索引始终是使用索引列的全部内容来计算哈希码。如,在数据列(A,B)上建立哈希索引,如果查询只有数据列A,则无法使用该哈希索引。
-
哈希索引只支持等值比较查询,包括=、IN()、<=>,不支持范围查询,如where price > 100。
-
哈希冲突(不同索引列会用相同的哈希码)会影响查询速度,此时需遍历索引中的行指针,逐行进行比较。(比如上面的peter和vadim,如果哈希码相同,那么vadim将会以链表的形式跟在peter的后面,如果想要vadim的lname,那么先找到哈希码所对应的链表,然后遍历链表可得到)
-
如果哈希冲突很多,一些索引维护操作的代价会很高。
总结:哈希索引限制多,只适用于一定的场合。而一旦适合哈希索引,它带来的性能提升将非常显著。(全文搜索引擎的索引主要采用hash的存储结构,因为等值查询哈希索引明显有绝对优势,因为只需要经过一次算法即可找到相应的键值;当然了,这个前提是,键值都是唯一的。如果键值不是唯一的,就需要先找到该键所在位置,然后再根据链表往后扫描,直到找到相应的数据)
自定义哈希索引限制
在InnoDB中,某些索引值被使用的非常频繁的时候,它会在内存中基于B+Tree的基础上再创建一个哈希索引,使其不必要在从根节点就行查找。完全自动的内部行为,用户无法配置或更改。
适用场景:
为超长的键创建哈希索引,列值太长,导致索引体积过大,查询速度也会受到影响。

创建思路:
增加一个额外哈希列,将列值映射成哈希值,对哈希列进行再进行索引。在where条件处手动指定使用哈希函数。

假设使用的是哈希函数hash(),查询语句如下:
select * from table where 列B=
hash('https://blog.csdn.net/qq_26222859/article/details/1')
and 列A=‘https://blog.csdn.net/qq_26222859/article/details/1'
列B还是利用B+Tree索引进行查找,只不过我们是利用哈希值而不是列键本身进行索引。
实例:
CREATE TABLE `url_hash` (
`url` varchar(255) DEFAULT NULL,
`url_crc` bigint(10) DEFAULT NULL,
KEY `HASHINDEX` (`url_crc`) USING BTREE
) ENGINE=InnoDB;
url键查询:
select * from url_hash where url='https://blog.csdn.net/qq_2622285'
使用mysql自带的CRC32函数对url做哈希处理,就可以使用下面的函数查询
select * from url_hash where url_crc=CRC32('https://blog.csdn.net/qq_2622285' ) and url='https://blog.csdn.net/qq_2622285'
mysql优化器会选择性能高且体积小的基于url_crc列的索引来完成查找,即使用多个相同的索引值,查找仍然很快。
但是,我们需要手动维护crc_url哈希列,可通过触发器在插入和更新时实时维护url_crc列,如下:
CREATE DEFINER=`root`@`localhost` TRIGGER `CRC_INS` BEFORE INSERT ON `url_hash` FOR EACH ROW begin
set NEW.url_crc=crc32(NEW.url);
end;
CREATE DEFINER=`root`@`localhost` TRIGGER `CRC_UPD` BEFORE UPDATE ON `url_hash` FOR EACH ROW begin
set NEW.url_crc=crc32(NEW.url);
end;
验证:
insert into url_hash(url) values ('https://blog.csdn.net/qq_2622285')
select * from url_hash
update url_hash set url ='update'
select * from url_hash
select * from url_hash where url='https://blog.csdn.net/qq_2622285' and url_crc=CRC32('https://blog.csdn.net/qq_2622285')
注意:
1、where语句中必须包含url,避免哈希冲突。
2、mysql同时提供了SHA1()、MD5()两个加密函数,不要使用这两个函数做哈希函数,他们是强加密函数,设计目标是最大限度消除冲突,但计算的哈希值很长,浪费空间且有时更慢。哈希冲突只要在一个可接受的范围内对性能影响并不大。
B-Tree和B+Tree的对比
- B+树内节点不存储数据,所有 data 存储在叶节点导致查询时间复杂度固定为 log n。而B-树查询时间复杂度不固定,与 key 在树中的位置有关,最好为O(1)。
- B+树叶子节点构成的链表可大大增加区间访问性,可使用在范围查询等,而B-树每个节点 key 和 data 在一起,则无法区间查找。
- B+树更适合外部存储。由于内节点无 data 域,每个节点能索引的范围更大更精确。由于B-树节点内部每个 key 都带着 data 域,而B+树节点只存储 key 的副本,真实的 key 和 data 域都在叶子节点存储。前面说过磁盘是分 block 的,一次磁盘 IO 会读取若干个 block,具体和操作系统有关,那么由于磁盘 IO 数据大小是固定的,在一次 IO 中,单个元素越小,量就越大。这就意味着B+树单次磁盘 IO 的信息量大于B-树,从这点来看B+树相对B-树磁盘 IO 次数少。
hash和B+Tree的对比
hash索引
-
hash索引进行等值查询更快(一般情况下)但是却无法进行范围查询.因为在hash索引中经过hash函数建立索引之后,索引的顺序与原顺序无法保持一致,不能支持范围查询.
-
hash索引不支持模糊查询以及多列索引的最左前缀匹配,因为hash函数的不可预测,eg:AAAA和AAAAB的索引没有相关性.
-
hash索引任何时候都避免不了回表查询数据.
-
hash索引虽然在等值上查询叫快,但是不稳定,性能不可预测,当某个键值存在大量重复的时候,发生hash碰撞,此时查询效率可能极差.
-
hash索引不支持使用索引进行排序,因为hash函数的不可预测.
B+Tree
-
B+树的所有节点皆遵循(左节点小于父节点,右节点大于父节点,多叉树也类似)自然支持范围查询.
-
在符合某些条件(聚簇索引,覆盖索引等)的时候可以只通过索引完成查询.不需要回表查询.
-
查询效率比较稳定,对于查询都是从根节点到叶子节点,且树的高度较低.