嵌入式linux之高级c语言专题--指针1
嵌入式linux高级c--指针
(观看朱有鹏老师高级c时视频总结的笔记)
1.指针到底是什么?
2.指针带来的一些符号的理解
3.野指针问题
4.const关键字与指针
5.深入学习一下数组
6.指针与数组的天生姻缘
7.指针与强制类型转换
8.指针、数组与sizeof运算符
9.指针与函数传参
10.输入型参数与输出型参数
1.1指针变量和普通变量的区别
指针的实质就是一个变量,其完整的名称是指针变量,与普通的变量没什么区别。指针存储的是地址,而普通变量存储的是数值。
1.2指针使用三部曲:定义指针变量、关联指针变量、解引用
1.2.1定义指针变量:类型名 * 指针变量
定义指针时的星号的位置不一样从而有三种定义:(1)int * a; (2)int* a; (3)int *a;
我编写了一下代码来验证以上的三种情况:
#include
int main(void)
{
int a=5;
int *p1;
int* p2;
int * p3;
p1 = &a;
p2 = &a;
p3 = &a;
printf("*p1 = %d\n",*p1);
printf("*p2 = %d\n",*p2);
printf("*p3 = %d\n",*p3);
return 0;
}
在linux系统中利用terminal中的gcc交叉编译工具来编译和运行c代码,运行结果如下图所示:

结论:三种定义的运行结果一样,故三种定义等价
1.2.2关联指针变量
关联指针变量的两种方法:(1)在定义指针时,初始化指针变量 (2)指针变量= &变量
通过以上的两种方法,可以将指针指向应该访问的地方,如果没对指针进行关联,就访问指针指向地址中的变量,会导致系统出现不可预料的严重后果。
1.2.3解引用
星号在用于指针相关功能的时候有2种用法:第一种是指针定义时,*结合前面的类型用于表明要定义的指针的类型;第二种功能是指针解引用,解引用时*p表示p指向的变量本身
1.3指针中的一些符号的理解
1.3.1星号*
(1)C语言中*可以表示乘号,也可以表示指针符号。这两个用法是毫无关联的,只是恰好用了同一个符号而已。
(2)星号在用于指针相关功能的时候有2种用法:第一种是指针定义时,*结合前面的类型用于表明要定义的指针的类型;第二种功能是指针解引用,解引用时*p表示p指向的变量本身
1.3.2取地址符
取地址符使用时直接加在一个变量的前面,然后取地址符和变量加起来构成一个新的符号,这个符号表示这个变量的地址。
1.3.3 NULL是什么?
NULL在C/C++中定义为:
#ifdef _cplusplus // 定义这个符号就表示当前是C++环境
#define NULL 0 // 在C++中NULL就是0
#else
#define NULL (void *)0 // 在C中NULL是强制类型转换为void *的0
#endif
1.4左值与右值
(1)放在赋值运算符左边的就叫左值,右边的就叫右值。所以赋值操作其实就是:左值=右值;
(2)当一个变量做左值时,编译器认为这个变量符号的真实含义是这个变量所对应的那个内存空间;当一个变量做右值时,编译器认为这个变量符号的真实含义是这个变量的值,也就是这个变量所对应的内存空间中存储的那个数。
(3)左值与右值的区别,就好象现实生活中“家”这个字的含义。譬如“我回家了”,这里面的家指的是你家的房子(类似于左值);但是说“家比事业重要”,这时候的家指的是家人(家人就是住在家所对应的那个房子里面的人,类似于右值)
1.5野指针问题
1.5.1野指针的相关概念
(1)因为指针变量在定义时如果未初始化,值也是随机的。指针变量的值其实就是别的变量(指针所指向的那个变量)的地址,所以意味着这个指针指向了一个地址是不确定的变量,这时候去解引用就是去访问这个地址不确定的变量,所以结果是不可知的。
(2)因为野指针指向地址是不可预知的,所以有3种情况:
第一种是指向不可访问(操作系统不允许访问的敏感地址,譬如内核空间)的地址,结果是触发段错误,这种算是最好的情况了;
第二种是指向一个可用的、而且没什么特别意义的空间(譬如我们曾经使用过但是已经不用的栈空间或堆空间),这时候程序运行不会出错,也不会对当前程序造成损害,这种情况下会掩盖你的程序错误,让你以为程序没问题,其实是有问题的;
第三种情况就是指向了一个可用的空间,而且这个空间其实在程序中正在被使用(譬如说是程序的一个变量x),那么野指针的解引用就会刚好修改这个变量x的值,导致这个变量莫名其妙的被改变,程序出现离奇的错误。一般最终都会导致程序崩溃,或者数据被损害。这种危害是最大的。
1.5.2避免野指针的技巧(很有价值的方法)
(1)野指针的错误来源就是指针定义了以后没有初始化,也没有赋值(总之就是指针没有明确的指向一个可用的内存空间),然后去解引用。故在指针的解引用之前,一定确保指针指向一个绝对可用的空间。
(2)常规的做法是:
第一点:定义指针时,同时初始化为NULL
第二点:在指针使用之前,将其赋值绑定给一个可用地址空间
第三点:在指针解引用之前,先去判断这个指针是不是NULL
第四点:指针使用完之后,将其赋值为NULL
#include
int main(void)
{
int a;
int *p = NULL;//第一点:定义指针时,同时初始化为NULL
*p = &a; //第二点:在指针使用之前,将其赋值绑定给一个可用地址空间
if(NULL!=p)//第三点:在指针解引用之前,先去判断这个指针是不是NULL
{
.....
p = NULL; //第四点:指针使用完之后,将其赋值为NULL
}
return 0;
}
1.5.3 const关键字与指针
1. const修饰指针的4种形式
第一种:const int *p;
第二种:int const *p;
第三种:int * const p;
第四种:const int * const p;
指针变量涉及到2个变量:第一个是指针变量p本身,第二个是p指向的那个变量(*p)。一个const关键字只能修饰一个变量,所以弄清楚这4个表达式的关键就是搞清楚const放在某个位置是修饰谁的。
(1)const int *p 或者int const *p
p指向的变量是const常量
(2)int * const p 或者 const int * const p
p本身是const常量,p指向的变量也是const常量
1.6深入学习一下数组
1.6.1从内存角度来理解数组
(1)从内存角度讲,数组变量就是一次分配多个变量,而且这多个变量在内存中的存储单元是依次相连接的。
(2)我们分开定义多个变量(譬如int a, b, c, d;)和一次定义一个数组(int a[4]);这两种定义方法相同点是都定义了4个int型变量,而且这4个变量都是独立的单个使用的;不同点是单独定义时a、b、c、d在内存中的地址不一定相连,但是定义成数组后,数组中的4个元素地址肯定是依次相连的。
(3)数组中多个变量虽然必须单独访问,但是因为他们的地址彼此相连,因此很适合用指针来操作,因此数组和指针天生就叫纠结在一起。
1.6.2数组中几个关键符号(a a[0] &a &a[0])的理解
(1)a就是数组名。
l a做左值时表示整个数组的所有空间,又因为C语言规定数组操作时要独立单个操作,不能整体操作数组,所以a不能做左值;
l a做右值表示数组首元素(数组的第0个元素,也就是a[0])的首地址(首地址就是起始地址,就是最开始第一个字节的地址)。a做右值等同于&a[0];
(2)a[0]表示数组的首元素,也就是数组的第0个元素。
l a[0]做左值时表示数组第0个元素对应的内存空间(连续4字节);
l a[0]做右值时表示数组第0个元素的值(也就是数组第0个元素对应的内存空间中存储的那个数)
(3)&a就是数组名a取地址,字面意思来看就应该是数组的地址。
l &a不能做左值(&a实质是一个常量,不是变量因此不能赋值,所以自然不能做左值。);
l &a做右值时表示整个数组的首地址。
(4)&a[0]字面意思就是数组第0个元素的首地址(搞清楚[]和&的优先级,[]的优先级要高于&,所以a先和[]结合再取地址)。
l 做左值时表示数组首元素对应的内存空间,做右值时表示数组首元素的值(也就是数组首元素对应的内存空间中存储的那个数值)。
l 做右值时&a[0]等同于a。
总结:
1:&a和a做右值时的区别:&a是整个数组的首地址,而a是数组首元素的首地址。这两个在数字上是相等的,但是意义不相同。意义不相同会导致他们在参与运算的时候有不同的表现。
2:a和&a[0]做右值时意义和数值完全相同,完全可以互相替代。
3:&a是常量,不能做左值。
4:a做左值代表整个数组所有空间,所以a不能做左值。
1.6.3为什么数组的地址是常量?
因为数组是编译器在内存中自动分配的。当我们每次执行程序时,运行时都会帮我们分配一块内存给这个数组,只要完成了分配,这个数组的地址就定好了,本次程序运行直到终止都无法再改了。那么我们在程序中只能通过&a来获取这个分配的地址,却不能去用赋值运算符修改它。
1.6.4指针与数组的天生姻缘
1.以指针方式来访问数组元素
(1)数组元素使用时不能整体访问,只能单个访问。访问方式有2种:数组形式和指针形式:
l 数组格式访问数组元素是:数组名[下标]; (注意下标从0开始)
l 指针格式访问数组元素是:*(指针+偏移量);
注:如果指针是数组首元素地址(a或者&a[0]),那么偏移量就是下标;指针也可以不是首元素地址而是其他哪个元素的地址,这时候偏移量就要考虑叠加了。
数组下标方式和指针方式均可以访问数组元素,两者的实质其实是一样的。在编译器内部都是用指针方式来访问数组元素的,数组下标方式只是编译器提供给编程者一种壳(语法糖)而已。所以用指针方式来访问数组才是本质的做法。
1.6.5指针和数组类型的匹配问题
int *p; int a[5];p = a;//类型匹配
int *p; int a[5];p = &a;//类型不匹配。p是int *,&a是整个数组的指针,也就是一个数组指针类型,不是int指针类型,所以不匹配
总结:&a、a、&a[0]从数值上来看是完全相等的,但是意义来看就不同了。
l 从意义来看,a和&a[0]是数组首元素首地址,而&a是整个数组的首地址
l 从类型来看,a和&a[0]是元素的指针,也就是int *类型;而&a是数组指针,是int (*)[常量]类型。
1.6.6指针类型决定了指针如何参与运算
(1)指针参与运算时,因为指针变量本身存储的数值是表示地址的,所以运算也是地址的运算。
(2)指针参与运算的特点是,指针变量+1,并不是真的加1,而是加1*sizeof(指针类型);如果是int *指针,则+1就实际表示地址+4,如果是char *指针,则+1就表示地址+1;如果是double *指针,则+1就表示地址+8.
1.7指针与强制类型转换
1.7.1变量的数据类型的含义
(1)所有的类型的数据存储在内存中,都是按照二进制格式存储的,即内存中只保存0和1。但是他们的存储方式(数转换成二进制往内存中放的方式)不一定相同。
(2)int、char、short等属于整形,他们的存储方式是相同的,只是占用的内存大小不同(所以这几种整形就彼此叫二进制兼容格式);而float和double的存储方式彼此不同,和整形更不同。
(3)当编译代码int a = 5;时,编译器给a分配4字节空间,并且将5按照int类型的存储方式转成二进制存到a所对应的内存空间中去(a此时做左值);我们printf去打印a的时候(a此时做右值),采用%d或者%f的方式解析内存中二进制数值时,如果解析方式与存储的方式相同,则能输出正确的数值,如下面的代码运行结果所示:
#include
int main(void)
{
int a = 5;
printf("a = %d\n",a);
printf("a = %f\n",a);
return 0;
}
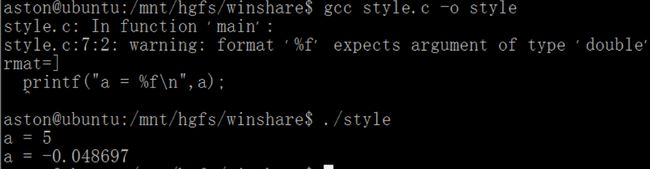
分析几个题目:
* 按照int类型存却按照float类型取一定会出错
* 按照int类型存却按照char类型取有可能出错也有可能不出错
* 按照short类型存却按照int类型取有可能出错也有可能不出错
* 按照float类型存却按照double取一定会出错
int和char类型都是整形,类型兼容的。int和char的不同在于char只有1个字节而int有4个字节,所以int的范围比char大。在char所表示的范围之内int和char是可以互转的不会出错;但是超过了char的范围后char转成int不会错(向大方向转就不会错,就好比拿小瓶子的水往大瓶子倒不会漏掉不会丢掉),而从int到char转就会出错(就好象拿大瓶子水往小瓶子倒一样)。
1.7.2指针的数据类型的含义
(1)指针的本质是:变量,指针就是指针变量
(2)一个指针涉及2个变量:一个是指针变量自己本身,一个是指针变量指向的那个变量
(3)int *p;定义指针变量时,p(指针变量本身)是int *类型,*p(指针指向的那个变量)是int类型的。
(4)int *类型说白了就是指针类型,只要是指针类型就都是占4字节,解析方式都是按照地址的方式来解析(意思是里面存的32个二进制加起来表示一个内存地址)的。结论就是:所有的指针类型(不管是int * 还是char *还是double *)的解析方式是相同的,都是地址。
(5)指针所指向的那个变量的类型(它所对应的内存空间的解析方法)要取决于指针类型。譬如指针是int *的,那么指针所指向的变量就是int类型的。
----------------文章未完,待后续更新----------------