10.1 意境级讲解关系抽取
文章目录
-
- 1.前言
- 2.关系抽取基本概念
-
- 2.1 现存在加粗样式的关加粗样式系重叠问题
- 3.关系抽取方法分类
-
- 3.1 根据训练数据的标记程度分类
- 3.2 根据使用的机器学习方法分类
- 3.3 根据是否同时进行实体抽取和关系分类子过程进行分类
-
- 3.3.1 Pipeline方法有哪些缺点
- 3.3.2 联合学习方法有哪些缺点
-
- 3.3.2.1 参数共享方法与联合解码方法
- 3.4 按解码方式进行分类
-
- 3.4.1 softmax 和 CRF
-
- 针对 重叠实体问题 提出 的改进方法
- 3.4.2 Span抽取:指针网络
-
- 注意
- 3.4.3 片段排列+分类
-
- 注意
- 3.4.4 Seq2Seq
- 3.5 根据是否限定关系抽取领域和关系类别分类
- 4、关系信息抽取常用数据集
- 5、评测方法
- 6、面向关系抽取的深度学习模型构建
-
- 6.1、流水线方式因果关系抽取
-
- 6.1.1、事件检测模型
-
- DMCNN
- HNN
- DLRNN
- DEEB-RNN
- PLMEE
- 6.1.2、关系分类模型
-
- 循环神经网络关系的抽取
- Att-BiLSTM
- 多级循环神经网络
- 多通道框架
- BiLSTM-CRF
- BERT进行关系分类
- 6.2、联合抽取方式因果关系抽取
-
- 6.2.1、参数共享方法
-
- 混合神经网络
- Copy机制+seq2seq+指针网络
- HDP混合双指针网络+seq2seq
- end to end双指针网络
- 6.2.2、文本标注方法
-
- end to end 序列标注
- 位置查询标注序列
- 自我关注的 BiLSTM-CRF
- 分层二进制标注
- 表格标注
- TPLinker:表格标注
- 参考
1.前言
**信息抽取(information extraction),简称IE,即从自然语言文本中,抽取出特定的事件或事实信息,帮助我们将海量内容自动分类、提取和重构。这些信息通常包括实体(entity)、关系(relation)、事件(event)。**例如从新闻中抽取时间、地点、关键人物,或者从技术文档中抽取产品名称、开发时间、性能指标等。能从自然语言中抽取用户感兴趣的事实信息,无论是在知识图谱、信息检索、问答系统还是在情感分析、文本挖掘中,信息抽取都有广泛应用。
信息抽取主要包括三个子任务:
关系抽取:通常我们说的三元组(triple)抽取,主要用于抽取实体间的关系。
实体抽取与链指:也就是命名实体识别。
事件抽取:相当于一种多元关系的抽取。
关系抽取(RE)是为了抽取文本中包含的关系,是信息抽取(IE)的重要组成部分。主要负责从无结构文本中识别出实体,并抽取实体之间的语义关系,被广泛用在信息检索、问答系统中。本文从关系抽取的基本概念出发,依据不同的视角对关系抽取方法进行了类别划分;最后分享了基于深度学习的关系抽取方法常用的数据集,并总结出基于深度学习的关系抽取框架。
2.关系抽取基本概念
实体的关系可被形式化描述为关系三元组 ⟨ e 1 , r , e 2 ⟩ , \left\langle e_{1}, r, e_{2}\right\rangle, ⟨e1,r,e2⟩, 其中, e 1 e_{1} e1 和 e 2 e_{2} e2 是实体 , r , r ,r 属于目标关系集 R { r 1 , r 2 , R\left\{r_{1}, r_{2},\right. R{ r1,r2, r 3 , … , r i } \left.r_{3}, \ldots, r_{i}\right\} r3,…,ri}.关系抽取的任务是从文本中抽取出三元组 ⟨ e 1 , r , e 2 ⟩ \left\langle e_{1}, r, e_{2}\right\rangle ⟨e1,r,e2⟩,从而提取文本信息.
完整的关系抽取包括实体抽取和关系分类两个子过程。实体抽取子过程也就是命名实体识别,对句子中的实体进行检测和分类;关系分类子过程对给定句子中两个实体之间的语义关系进行判断,属于多类别分类问题。
简单来说就是给定一段文本,要抽出其中的(subject, predicate, object)三元组,其中subject代表主语,Predicate是谓词,object指宾语:
{
'text': '胡歌是一位有流量的明星, 而且《琅琊榜》里给大众留下好印象',
'relation_list': [
{
'subject': '胡歌',
'object': '明星',
'predicate': '角色'
},
]
}
2.1 现存在加粗样式的关加粗样式系重叠问题
句子中的关系事实常常很复杂,不同的关系三元组在句子中可能有重叠。如果一个句子的三元组都没有重叠的实体,则该句子属于Normal类;如果一个句子的某些三元组中的某些实体对重叠,则该句子属于EntityPairOverlap(EPO)类;如果一个句子的某些三元组中有一个重叠的实体,而这些三元组中没有重叠的实体对,则该句子属于SingleEntityOverlap(SEO)类。
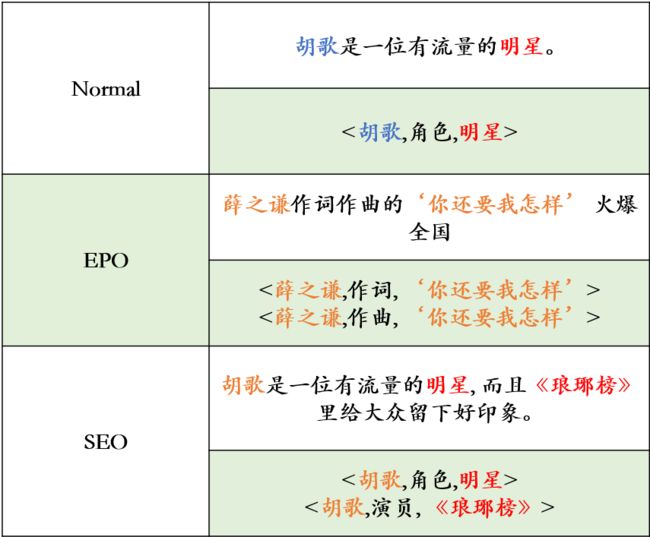
图2.1:正常、实体对重叠、单实体重叠的例子。重叠的实体被标注为黄色。
后来提出的一些方法已经可以解决重叠问题,如 CopyRE 、CopyMTL 、CasRel(HBT)等,但它们在**训练和推理阶段存在曝光偏差。**即在训练阶段,使用了 golden truth 作为已知信息对训练过程进行引导,而在推理阶段只能依赖于预测结果。这导致中间步骤的输入信息来源于两个不同的分布,对性能有一定的影响。
虽然这些方法都是在一个模型中对实体和关系进行了联合抽取,但从某种意义上它们“退化”成了“pipeline”的方法,即在解码阶段需要分多步进行。这也是它们存在曝光偏差的本质原因。
部分关系的实体存在嵌套,请看以下两个例子:
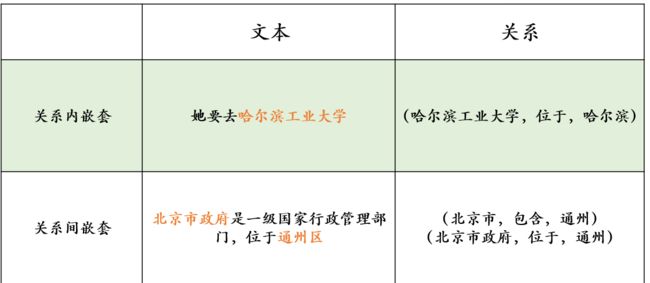
虽然当前已经有很多方法可以专门用于识别嵌套实体,但是把它们直接融合到关系抽取中也并不是那么容易。
3.关系抽取方法分类
目前,常用的关系抽取方法有5类,分别是基于模式匹配、基于词典驱动、基于机器学习、基于本体和混合的方法。基于模式匹配和词典驱动的方法依靠人工制定规则,耗时耗力,而且可移植性较差,基于本体的方法构造比较复杂,理论尚不成熟。基于机器学习的方法以自然语言处理技术为基础,结合统计语言模型进行关系抽取,方法相对简单,并具有不错的性能,成为当下关系抽取的主流方法,下文提到的关系抽取方法均为机器学习的方法。
关于信息关系抽取,可以从训练数据的标记程度、使用的机器学习方法、是否同时进行实体抽取和关系分类子过程以及是否限定关系抽取领域和关系专制四个角度对机器学习的关系抽取方法进行分类。
3.1 根据训练数据的标记程度分类
根据训练数据的标记程度可以将关系抽取方法分为有监督、半监督和无监督三类。
有监督学习,处理的基本单位是包含特定实体对的句子,每一个句子都有类别标注。优点:取能够有效利用样本的标记信息,准确率和召回率都比较高。缺点:需要大量的人工标记训练语料,代价较高。
半监督学习,句子作为训练数据的基本单位,只有部分是有类别标注的。此类方法让学习器不依赖外界交互,自动地利用未标记样本来提升学习性能。
无监督学习,完全不需要对训练数据进行标注,此类方法包含实体对标记、关系聚类和关系词选择三个过程。
3.2 根据使用的机器学习方法分类
根据使用机器学习方法不同,可以将关系抽取划分为三类:基于特征向量的方法、基于核函数的方法以及基于神经网络的方法。
基于特征向量的方法,通过从包含特定实体对的句子中提取出语义特征,构造特征向量,然后通过使用支持向量机、最大熵、条件随机场等模型进行关系抽取。
基于核函数的方法,其重点是巧妙地设计核函数来计算不同关系实例特定表示之间的相似度。缺点:而如何设计核函数需要大量的人类工作,不适用于大规模语料上的关系抽取任务。
基于神经网络的方法,通过构造不同的神经网络模型来自动学习句子的特征,减少了复杂的特征工程以及领域专家知识,具有很强的泛化能力。
3.3 根据是否同时进行实体抽取和关系分类子过程进行分类
根据是否在同一个模型里开展实体抽取和关系分类,可以将关系抽取方法分为流水线(pipeline)学习和联合(joint)学习两种。
流水线学习是指先对输入的句子进行实体抽取,将识别出的实体分别组合,然后再进行关系分类,这两个子过程是前后串联的,完全分离。
联合学习是指在一个模型中实现实体抽取和关系分类子过程。该方法通过使两个子过程共享网络底层参数以及设计特定的标记策略来解决上述问题,其中使用特定的标记策略可以看作是一种序列标注问题。而联合模型又可以细分为基于参数共享的联合模型和基于文本标注的联合模型。
3.3.1 Pipeline方法有哪些缺点
Pipeline方法指先抽取实体、再抽取关系。虽然Pipeline方法易于实现,这两个抽取模型的灵活性高,实体模型和关系模型可以使用独立的数据集,并不需要同时标注实体和关系的数据集。但存在以下缺点:
- 误差积累:实体抽取的误差会影响到关系分类的准确度;
- 信息冗余:在实体抽取过后,需要对实体两两配对并进行关系分类,对于不存在关系的候选实体地会造成大量冗余信息,增加了计算复杂度,造成计算资源的浪费;
- 交互缺失:流水线方式的关系抽取忽略了两个子任务之间的内在联系和依赖关系
(基于共享参数的联合抽取方法仍然存在训练和推断时的gap,推断时仍然存在误差积累问题,可以说只是缓解了误差积累问题。)
3.3.2 联合学习方法有哪些缺点
联合学习方法中存在的共性问题
联合学习方法包括基于参数共享的实体关系抽取方法和基于新序列标注的实体关系抽取方法:前者很好地改善了流水线方法中存在的错误累积传播问题和忽视两个子任务间关系依赖的问题;而后者不仅解决了这两个问题,还解决了流水线方法中存在的冗余实体的问题.但这两种方法对于现今有监督领域存在的重叠实体关系识别问题,并未能给出相关的解决方案.
3.3.2.1 参数共享方法与联合解码方法
下图是参数共享方法和联合解码方法的对比。使用参数共享的联合模型和管道模型的结构是非常相似的,它们抽取spo三元组的过程都是分成多步完成的,主要的不同在于基于参数共享的联合模型的loss是各个子过程的loss之和,在求梯度和反向更新参数时会更新整个模型所有子过程的参数,而管道模型各子过程之间则没有联系。使用联合解码的联合模型则更符合“联合”的思想,主语,宾语和关系类型是在同一个步骤中进行识别然后得出的。
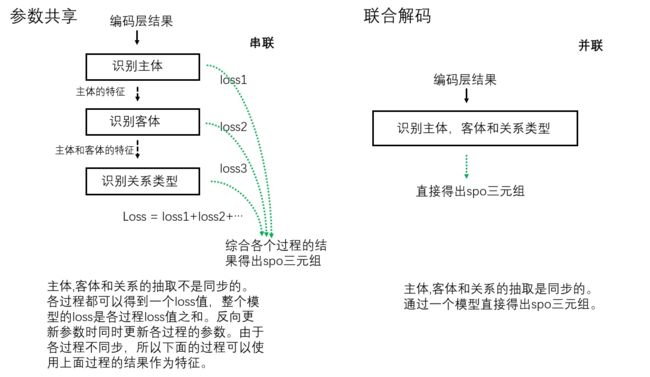
3.4 按解码方式进行分类
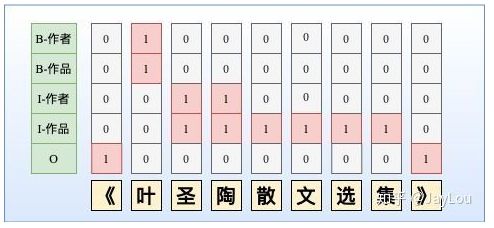
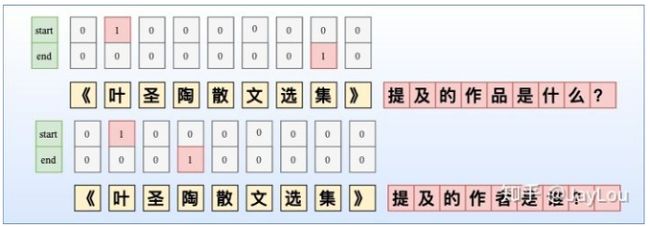
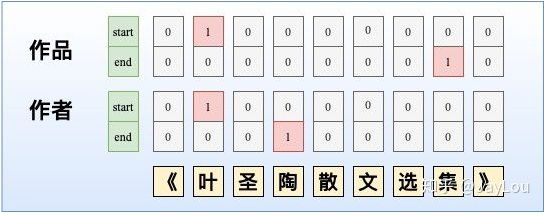
虽然NER是一个比较常见的NLP任务,通常采用LSTM+CRF处理一些简单NER任务。NER还存在嵌套实体问题(实体重叠问题),如「《叶圣陶散文选集》」中会出现两个实体「叶圣陶」和「叶圣陶散文选集」分别代表「作者」和「作品」两个实体。而传统做法由于每一个token只能属于一种Tag,无法解决这类问题。
3.4.1 softmax 和 CRF
本质上是token-level 的多分类问题,通常采用CNNs/RNNs/BERT+CRF处理这类问题。与SoftMax相比,CRF进了标签约束。
- 针对CRF解码慢的问题,LAN 提出了一种逐层改进的基于标签注意力机制的网络,在保证效果的前提下比 CRF 解码速度更快。文中也发现BiLSTM-CRF在复杂类别情况下相比BiLSTM-softmax并没有显著优势。
- 由于分词边界错误会导致实体抽取错误,基于LatticeLSTM+CRF的方法可引入词汇信息并避免分词错误(若当前字符与之前字符构成词汇,则从这些词汇中提取信息,联合更新记忆状态)。
针对 重叠实体问题 提出 的改进方法
但由于这种序列标注采取BILOU标注框架,每一个token只能属于一种,不能解决重叠实体问题,如图所示。

- 改进方法1
采取token-level 的多label分类,将SoftMax替换为Sigmoid,如图所示。当然这种方式可能会导致label之间依赖关系的缺失,可采取后处理规则进行约束。
- 改进方法2
依然采用CRF,但设置多个标签层,对于每一个token给出其所有的label,然后将所有标签层合并。显然这可能会增加label数量,导致label不平衡问题。基于这种方式,文献也采取先验图的方式去解决重叠实体问题。

3.4.2 Span抽取:指针网络
指针网络(PointerNet)最早应用于MRC中,而MRC中通常根据1个question从passage中抽取1个答案片段,转化为2个n元SoftMax分类预测头指针和尾指针。对于NER可能会存在多个实体Span,因此需要转化为n个2元Sigmoid分类预测头指针和尾指针。
第一种:MRC-QA+单层指针网络。在ShannonAI的文章中,构建query问题指代所要抽取的实体类型,同时也引入了先验语义知识。如图所示,由于构建query问题已经指代了实体类型,所以使用单层指针网络即可;除了使用指针网络预测实体开始位置、结束位置外,还基于开始和结束位置对构成的所有实体Span预测实体概率。此外,这种方法也适合于给定事件类型下的事件主体抽取,可以将事件类型当作query,也可以将单层指针网络替换为CRF。
第二种:多层label指针网络。由于只使用单层指针网络时,无法抽取多类型的实体,我们可以构建多层指针网络,每一层都对应一个实体类型。
注意
- MRC-QA会引入query进行实体类型编码,这会导致需要对愿文本重复编码输入,以构造不同的实体类型query,这会提升计算量。
- 笔者在实践中发现,n个2元Sigmoid分类的指针网络,会导致样本Tag空间稀疏,同时收敛速度会较慢,特别是对于实体span长度较长的情况。
3.4.3 片段排列+分类
上述序列标注和Span抽取的方法都是停留在token-level进行NER,间接去提取span-level的特征。而基于片段排列的方式,显示的提取所有可能的片段排列,由于选择的每一个片段都是独立的,因此可以直接提取span-level的特征去解决重叠实体问题。
对于含T个token的文本,理论上共有 N = T ( T + 1 ) / 2 N=T(T+1)/2 N=T(T+1)/2 种片段排列。如果文本过长,会产生大量的负样本,在实际中需要限制span长度并合理削减负样本。
注意
- 实体span的编码表示:在span范围内采取注意力机制与基于原始输入的LSTM编码进行交互。然后所有的实体span表示并行的喂入SoftMax进行实体分类。
- 这种片段排列的方式对于长文本复杂度是较高的。
3.4.4 Seq2Seq
ACL2019的一篇paper中采取Seq2Seq方法[3],encoder部分输入的原文tokens,而decoder部分采取hard attention方式one-by-one预测当前token所有可能的tag label,直至输出 (end of word) label,然后转入下一个token再进行解码。
3.5 根据是否限定关系抽取领域和关系类别分类
根据是否限定抽取领域和关系类别,关系抽取方法可以划分为预定义抽取和开放域抽取两类。
预定义关系抽取是指在一个或者多个固定领域内对实体间关系进行抽取,语料结构单一,这些领域内的目标关系类型也是预先定义的。
开放域关系抽取不限定领域的范围和关系的类别。现阶段,基于深度学习的关系抽取研究集中于预定义关系抽取。
4、关系信息抽取常用数据集
基于深度学习的关系抽取方法常用的数据集有ACE关系抽取任务数据集、SemEval2010 Task 8数据集、NYT2010数据集等.
ACE关系抽取任务数据集:ACE2005关系抽取数据集包含599篇与新闻和邮件相关的文档,其数据集内包含7大类25小类关系。
SemEval2010 Task 8数据集:该数据集包含9种关系类型,分别是Compoent-Whole、Instrument-Agency、Member-Collection、Cause-Effect、Entity-Destination、Content-Container、Message-Topic、Product-Producer和Entity-Origin。 考虑到实体之间关系的方向以及不属于前面9种关系的“Other”关系,共生成19类实体关系。其中训练数据 8000个,测试数据2717个。
MPQA 2.0 语料库:包含来自各种新闻源的新闻文章和社论,数据集中共有 482 个文档,包含 9 471 个带有短语级别注释的句子.数据集中包含观点实体的黄金标准注释,如观点表达、观点目标和观点持有者;还包含观点关系的注释,如观点持有者和观点表达之间的 IS-FROM 关系、观点目标和观点表达之间的 IS-ABOUT 关系;
BioNLP-ST 2016 的 BB 任务:此任务是针对细菌/位置实体抽取和两者间 Lives_In 关系抽取而设立的一个标准竞赛,数据集由来自 PubMed 的 161 个科学论文摘要组成,数据集中包含 3 种类型的实体:细菌、栖息地和地理位置;包含一种关系:Lives_In,指由细菌-栖息地构成的 Lives_In 关系或由细菌-地理位置构成的 Lives_In 关系.
NYT2010数据集**:**是Riedel等人在2010年将Freebase知识库中的知识“三元组”对齐到“纽约时报”新闻中得到的训练数据。该数据集中,数据的单位是句包,一个句包由包含该实体对的若干句子构成。其中,训练数据集从《纽约时报》2005—2006年语料库中获取,测试集从2007年语料库中获取。
5、评测方法
关系抽取领域有 3 项基本评价指标:准确率(precision)、召回率(recall)和 F 值(F measure).
(一) 准确率
准确率是从查准率的角度对实体关系抽取效果进行评估,其计算公式为
Precision R = 被正确抽取的属于关系R的实体对个数 所有被抽取为关系R的实体对个数 \text { Precision }_{R}=\frac{\text { 被正确抽取的属于关系R的实体对个数 }}{\text { 所有被抽取为关系R的实体对个数 }} Precision R= 所有被抽取为关系R的实体对个数 被正确抽取的属于关系R的实体对个数
(二) 召回率
召回率是从查全率的角度对抽取效果进行评估,其计算公式为
Recall R = 被正确抽取的属于关系R的实体对个数 实际应被抽取的属于关系R的实体对个数 \operatorname{Recall}_{R}=\frac{\text { 被正确抽取的属于关系R的实体对个数 }}{\text { 实际应被抽取的属于关系R的实体对个数 }} RecallR= 实际应被抽取的属于关系R的实体对个数 被正确抽取的属于关系R的实体对个数
(三) F 值
对与关系抽取来说,准确率和召回率是相互影响的,二者存在互补关系,因此,F 值综合了准确率和召回率的信息,其计算公式为
F β = ( β 2 + 1 ) ⋅ Precision ⋅ Recall Precision + Recall F_{\beta}=\frac{\left(\beta^{2}+1\right) \cdot \text { Precision } \cdot \text { Recall }}{\text { Precision }+\text { Recall }} Fβ= Precision + Recall (β2+1)⋅ Precision ⋅ Recall
β是一个调节准确率与召回率比重的参数,实际测试中,一般认为准确率与召回率同等重要,因此,β值一般设置成 1.因此,上式可以表示
F 1 = 2 ⋅ Precision ⋅ Recall Precision + Recall F_{1}=\frac{2 \cdot \text { Precision } \cdot \text { Recall }}{\text { Precision }+\text { Recall }} F1= Precision + Recall 2⋅ Precision ⋅ Recall
6、面向关系抽取的深度学习模型构建
因果关系抽取是自然语言处理( Natural Language Processing,NLP)的重要任务,当前主要有两类框架来完成此任务。一种是流水线方法,一种是联合抽取方法。流水线方法中,因果关系抽取任务被划分为两个步骤:确定句子中的事件触发词及相关论元,根据触发词构造候选事件对并进行因果关系判别。这两个步骤分别定义为两个相关的任务:事件检测 (Event Detection , ED) 和关系分类 (Relation Classification,RC)。如果只需要对已标注事件对进行分类,则因果关系抽取可以简化为因果关系分类,联合抽取模型则是将两个子任务统一构建成一个模型,在建模时进一步利用两个任务间的潜在关联,缓解错误传播问题。
6.1、流水线方式因果关系抽取
流水线方法将关系抽取任务分为两个子任务:事件检测和关系分类。事件检测任务是自然语言处理中信息获取的一个常见任务,从非结构化的信息中抽取出事件触发词和相关角色的触发词论元;关系分类任务则是依据标注好的语料进行事件对间的相关类型判别。下面是对当前主流的事件检测任务和关系分类任务模型的详细介绍。
6.1.1、事件检测模型
事件检测的主要工作是识别语料中的事件触发词和相关论元。CNN 通过捕捉句子中重要特征从而获得句子表示,传统的 CNN 模型在池化操作后获得的向量表示会错过有价值线索。为了解决这一问题,Chen 等1提出了动态多池卷积神经 网 络 ( Dynamic Multi-pooling Convolutional Neural Network,DMCNN)来提取句子级特征,如图 1 所示。DMCNN使用一个动态的多池层来获取句子各部分的最大值,句子表示的各部分依据事件的触发词和论元进行分割。与传统 CNN模型相比,DMCNN 无需借助 NLP 工具的帮助,能够捕获更多有价值的特征。但 DMCNN 模型中的语料需要预先标记好触发词和相关论元,可以将其简单的理解成对触发词和论元之间的角色进行分类。
ED形式化为一个多类分类问题。给定一个句子,将其中的每个单词都视为一个触发词候选者,并将每个候选者分类为特定的事件类型。在ACE-2005数据集中,有33个子类型,和一个“不适用”(NA)”类型。在不失一般性的情况下,将33个子类型视为33个事件类型。
DMCNN
图1给出了我们提出的DEEB-RNN模型的原理图,该模型包含两个主要模块:
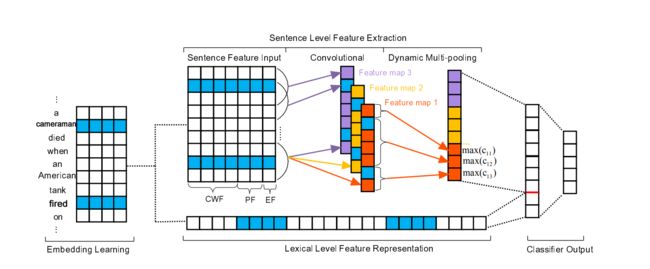
它主要涉及以下四个部分:(i)word-embedding学习, (ii)词汇级特征表示,直接使用词的embedding向量来捕获词汇线索; (iii)句子级特征提取,提出DMCNN来学习句子的组成语义特征; (iv)论元分类器输出,它计算每个候选论元角色的置信度分数。
-
输入
预测的触发词和 候选论元之间的语义交互对于论元分类是至关重要的,使用三种类型的输入来捕捉这些重要的线索:
上下文单词特征(CWF)
位置特征(PF):当前单词与预测的触发词或候选论元的相对距离,由embedding 表示。
事件类型特征(EF):当前触发词的事件类型对于论元分类很有价值
图1假设字嵌入的大小为dw = 4 , =4, =4, 位置嵌入的大小为dp = 1 , =1, =1, 事件类型嵌入的大小为de = 1. =1 . =1. 令 x i ∈ R d x_i \in {R^d} xi∈Rd第 i i i个单词, 其中 d = d ω + d p ∗ 2 + d e d=d_{\omega}+d_{p} * 2+d_{e} d=dω+dp∗2+de 。长度为 n n n的句子表示如下:
x 1 : n = x 1 ⨁ x 2 ⨁ ⋯ ⨁ x n x_{1: n}=x_{1} \bigoplus x_{2} \bigoplus \cdots \bigoplus x_{n} x1:n=x1⨁x2⨁⋯⨁xn
其中 ⊕ \oplus ⊕是连接运算符。 因此转换为一个矩阵 X ∈ R n × d X\in \mathbb{R}^{n \times d} X∈Rn×d 。然后, X X X被输入到卷积层。 -
卷积层
x i : i + j x_{i: i+j} xi:i+j : 单词 x i , x i + 1 , … , x i + j x_{i}, x_{i+1}, \ldots, x_{i+j} xi,xi+1,…,xi+j 的串联 ,卷积核 w ∈ R h × d w \in \mathbb{R}^{h \times d} w∈Rh×d, 窗口大小为 h h h . 由一个窗口的单词 x i : i + h − 1 x_{i: i+h-1} xi:i+h−1生成特征 c i c_{i} ci:
c i = f ( w ⋅ x i : i + h − 1 + b ) c_{i}=f\left(w \cdot x_{i: i+h-1}+b\right) ci=f(w⋅xi:i+h−1+b)
b ∈ R b \in R b∈R 是偏置项, f f f :激活函数。 该过滤器应用于句子 x 1 : h , x 2 : h + 1 , … , x n − h + 1 : n x_{1: h}, x_{2: h+1}, \ldots, x_{n-h+1: n} x1:h,x2:h+1,…,xn−h+1:n 中的每个可能的单词窗口,以产生特征 c i c_{i} ci 。为了捕获不同的特征,通常在卷积中使用多个卷积核。假设使用m个卷积核 W = w 1 , w 2 , … , w m , W=w_{1}, w_{2}, \ldots, w_{m}, W=w1,w2,…,wm, 卷积运算可以表示为:
c j i = f ( w j ⋅ x i : i + h − 1 + b j ) c_{j i}=f\left(w_{j} \cdot x_{i: i+h-1}+b_{j}\right) cji=f(wj⋅xi:i+h−1+bj)
j from 1 to m m m. 卷积结果是矩阵 C ∈ R m × ( n − h + 1 ) C \in \mathbb{R}^{m \times(n-h+1)} C∈Rm×(n−h+1). -
动态多池
在抽取的任务中,一个句子可能包含两个或两个以上的事件,一个论元候选词可能在不同的触发词中扮演不同的角色。为了做出准确的预测,有必要获取与候选词的变化有关的最有价值的信息。因此根据论元分类阶段中的候选论元和预测触发词将每个特征映射分成三个部分。保留每个拆分部分的最大值,而不是使用整个特征映射的一个最大值来表示句子,并将其称为动态多池。
图1特征映射输出 c j c_{j} cj 被“cameraman”和“fired”分成三个部分 c j 1 , c j 2 , c j 3 c_{j 1}, c_{j 2}, c_{j 3} cj1,cj2,cj3 ,表示为如下公式。其中 1 ≤ j ≤ m 1 \leq j \leq m 1≤j≤m , 1 ≤ i ≤ 3 1 \leq i \leq 3 1≤i≤3
p j i = max ( c j i ) p_{j i}=\max \left(c_{j i}\right) pji=max(cji)
通过动态多池层,获得每个特征映射的 p j i p_{j i} pji . 将所有 p j i p_{j i} pji 连接起来形成一个向量 P ∈ R 3 m P \in \mathbb{R}^{3 m} P∈R3m, ,它可以被认为是更高级别的特征(句子级特征)。 -
输出
上面自动学习的词汇和句子水平特征被连接成一个单一的向量 F = [ L , P ] . F=[L, P] . F=[L,P].为了计算每个论元角色的置信度,特征向量 F ∈ R 3 m + d l F \in \mathbb{R}^{3 m+d_{l}} F∈R3m+dl, m m m 是特征映射的数量, d l d_{l} dl 是词汇级别特征的维度,被馈送到分类器中。
O = W s F + b s O=W_{s} F+b_{s} O=WsF+bs
W s ∈ R n 1 × ( 3 m + d l ) W_{s} \in \mathbb{R}^{n_{1} \times\left(3 m+d_{l}\right)} Ws∈Rn1×(3m+dl) 是变换矩阵, O ∈ R n 1 O \in \mathbb{R}^{n_{1}} O∈Rn1 是网络的最终输出, n 1 n_{1} n1 等于论元角色的数量,包括在事件中不扮演任何角色的候选论元的“None role”标签。正则化,还在倒数第二层采用了dropout。
- 训练
论元 分类阶段的所有参数定义为 θ = \theta= θ= ( E , P F 1 , P F 2 , E F , W , b , W S , b s ) . \left(E, P F_{1}, P F_{2}, E F, W, b, W_{S}, b_{s}\right) . (E,PF1,PF2,EF,W,b,WS,bs). E \mathrm{E} E:word embedding, P F 1 P F_{1} PF1, P F 2 P F_{2} PF2 :position embedding, E F E F EF是事件类型embedding。 W W W , b b b 是卷积的参数, W s W_{s} Ws , b s b_{s} bs 输出层参数 。 给定输入示例 s, 具有参数 θ \theta θ 的网络输出向量 O O O, 第 i i i 个分量 O i O_{i} Oi 包含论元角色i的分数。为了获得条件概率 p ( i ∣ x , θ ) p(i \mid x, \theta) p(i∣x,θ),我们对所有论元角色类型应用softmax操作:
p ( i ∣ x , θ ) = e o i ∑ k = 1 n 1 e o k p(i \mid x, \theta)=\frac{e^{o_{i}}}{\sum_{k=1}^{n_{1}} e^{o_{k}}} p(i∣x,θ)=∑k=1n1eokeoi
给定训练样例 ( x i ; y i ) , \left(x_{i} ; y_{i}\right), (xi;yi),定义目标函数如下:
J ( θ ) = ∑ i = 1 T log p ( y ( i ) ∣ x ( i ) , θ ) J(\theta)=\sum_{i=1}^{T} \log p\left(y^{(i)} \mid x^{(i)}, \theta\right) J(θ)=i=1∑Tlogp(y(i)∣x(i),θ)
使用Adadelta 更新规则,通过随机梯度下降对小批量洗牌 ,最大化对数似然 J ( θ ) J(\theta) J(θ) 。
大量研究希望通过使用循环神经网络进行事件触发词的抽取,但起初只关注单一的事件触发词提及。使用双向循环神经网络来检测可以是单词或短语的事件,为了在上下文中对单词语义进行编码,摆脱特定于语言的知识和已有的自然语言处理工具,Feng 等2提出了一种混合神经网络(Hybrid Neural Network,HNN),如图 2 所示。该模型同时使用了 LSTM 和 CNN 来训练每个字的特征,并将其拼接作为字的表示,同时传入到softmax 层进行事件触发词的预测。双向LSTMs和卷积神经网络相结合,捕获来自特定上下文的序列和结构语义信息,对触发词提取非常有效。
HNN
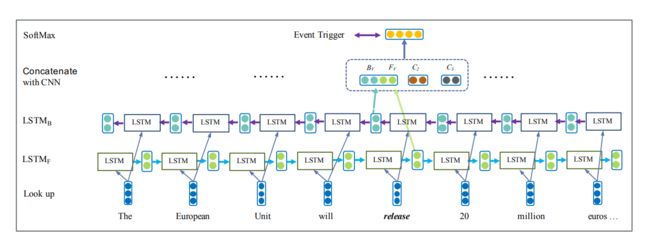
图 2:事件触发词提取模型的说明(此处触发词候选是“release”)。 Fv和Bv是Bi-LSTM的输出,C2,C3是CNN的输出,具有宽度为2和3的卷积核输出。使用具有不同宽度的多个卷积CNN来捕获一些局部特征,能够捕获各种粒度的n-gram的局部语义,CNN结构如下:
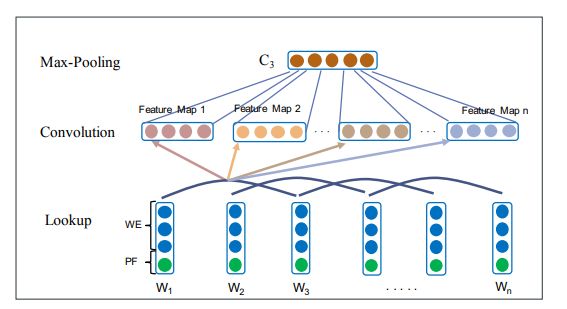
n个单词组成的句子 { w 1 , w 2 , … w i , … w n } , \left\{w_{1}, w_{2}, \ldots w_{i}, \ldots w_{n}\right\}, { w1,w2,…wi,…wn}, 每个单词 w i w_{i} wi 映射到embedding e i ∈ R d e_{i} \in \mathbb{R}^{d} ei∈Rd. 添加位置特征(PF), 卷积的输出送到MaxPooling层,获得具有固定长度的输出向量。最后,从Bi-LSTM中学习到双向序列特征:F和B,CNN的局部上下文特征:C2和C3,拼接成O = [F, B, C2, C3]。利用softmax方法来识别 候选触发词并将每个候选触发词分类为特定事件类型。
然而研究者考虑到句子的局部上下文不足以解决特定事件类型识别中的歧义问题,Duan 等3提出了一种新的文档级循环神经网络(Document Level Recurrent Neural Networks,DLRNN)模型,该模型可以在不设计复杂推理规则的情况下自动提取跨句线索,提高句子级事件检测的效率。Zhao 等4引入文档特征来丰富词的信息,加入到原本的事件检测任务中,通过设计注意力机制,从单词和句子两个层次学习文档的分布式表示(DEEB-RNN)。为了提高事件抽取的效率,Yang 等5首次指出事件抽取模型中的角色存在重叠问题。基于此,Yang 提出的一种基于预训练语言模型的事件抽取器(PLMEE)将事件抽取分为两个阶段包括触发词提取和论元提取,实验性能超过了大多数抽取方法。
事件抽取的两个挑战
(1)角色重叠问题
例如,在句子 “The explosion killed the bomber and three shoppers” 中,"killed"是Attack类型事件的触发词,论元 “the bomber” 既扮演了 “Attacker” 的角色,也是 “Vitctim”角色。ACE 2005数据集中大约有10%的事件有角色重叠问题。角色的概率分布差异很大 ,图 4,损伤类型事件中出现的角色频率。
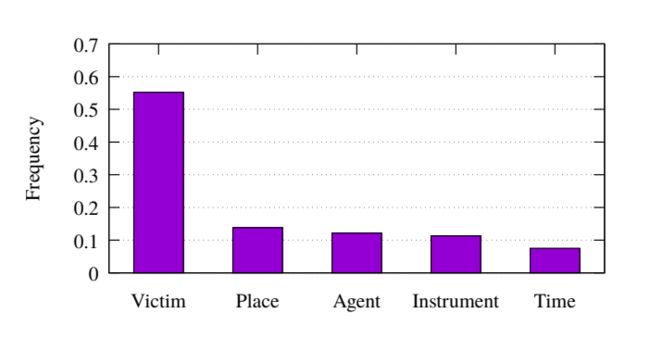
(2)标签数据不足问题
监督学习下的事件抽取依赖于大量人工标注的数据集,而ACE数据集当中给出的事件标签数量有限。为了解决这一问题,已经有一些相关研究:采用事件生成方法来为训练生成事件数据;使用远程监督,利用外部语料库进行标注。但是使用远程监督生成事件的质量和数量过度依赖于源数据。
实际上,也可以使用预训练语言模型生成句子,实现对外部语料库的利用。作者使用了预训练语言模型,利用大规模语料库的知识,实现事件生成。
DLRNN
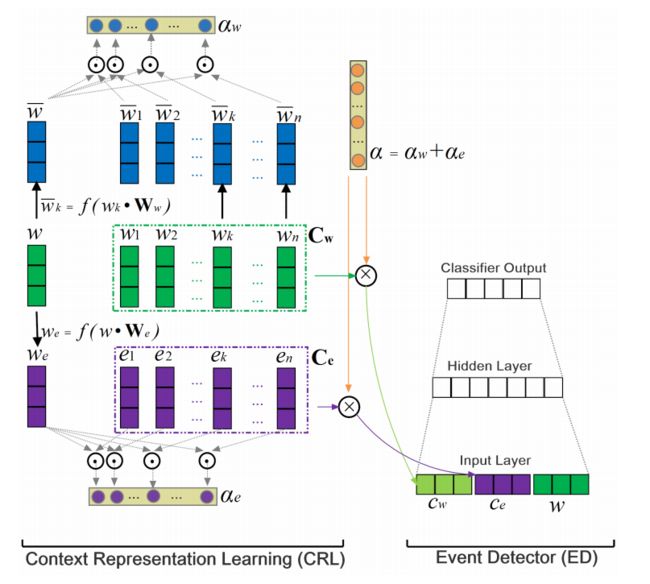
图 4DLRNN包含两部分:(1)Context Representation Learning (CRL):这揭示了上下文词汇和实体通过注意机制的表示(2)Event Detector (ED):它根据所学的上下文表示为每个候选对象分配一个事件类型(包括NA类型)。
-
CRL
将句子固定长度为 n n n , w 0 w_{0} w0 是当前候选触发词,然后 w 0 w_{0} w0 的上下文 C w \mathrm{C}_{\mathrm{w}} Cw = [ w − n 2 , w − n 2 + 1 , … , w − 1 , w 1 , … , w n 2 − 1 , w n 2 ] \left[w_{-\frac{n}{2}}, w_{-\frac{n}{2}+1}, \ldots, w_{-1}, w_{1}, \ldots, w_{\frac{n}{2}-1}, w_{\frac{n}{2}}\right] [w−2n,w−2n+1,…,w−1,w1,…,w2n−1,w2n] 和它的上下文实体 C e , \mathrm{C}_{\mathrm{e}}, Ce,即对应的实体类型(包括NA类型)为 [ e − n 2 , e − n 2 + 1 , ⋯ , e − 1 , e 1 , … , e n 2 − 1 , e n 2 ] \left[e_{-\frac{n}{2}}, e_{-\frac{n}{2}}+1, \cdots, e_{-1}, e_{1}, \ldots, e_{\frac{n}{2}-1}, e_{\frac{n}{2}}\right] [e−2n,e−2n+1,⋯,e−1,e1,…,e2n−1,e2n]
为了方便,图 4使用 w w w 表示当前候选触发词, [ w 1 , w 2 , … , w n ] \left[w_{1}, w_{2}, \ldots, w_{n}\right] [w1,w2,…,wn] 表示上下文相关的词 C w \mathrm{C}_{\mathrm{w}} Cw , [ e 1 , e 2 , … , e n ] \left[e_{1}, e_{2}, \ldots, e_{n}\right] [e1,e2,…,en] 表示上下文实体 C e \mathrm{C}_{\mathrm{e}} Ce .图 4中 w , C w w, \mathrm{C}_{\mathrm{w}} w,Cw , C e \mathrm{C}_{\mathrm{e}} Ce 用Embedding向量表示。 然后,通过在当前单词 w w w与其上下文之间执行操作来计算上下文单词和实体的注意向量。最后,上下文词表示 c w c_{w} cw和上下文实体表示 c e c_{e} ce分别由每个词 C w \mathrm{C}_{\mathrm{w}} Cw 和实体 C e \mathrm{C}_{\mathrm{e}} Ce中相应的embedding的加权和组成,作为下一个事件检测器组件的输入。数学描述如下:
随机初始化每种实体类型(包括NA类型)的Embedding向量,并在训练过程中对其进行更新。
上下文词的注意向量 α w \alpha_{w} αw 是基于当前的单词 w w w和它的上下文单词 C w \mathrm{C}_{\mathrm{w}} Cw计算的。首先将每个单词 w k w_{k} wk( w w w 和 C w \mathrm{C}_{\mathrm{w}} Cw) 转化为一个隐藏的表示 w ˉ k \bar{w}_{k} wˉk:
w ˉ k = f ( w k ⋅ W w ) \bar{w}_{k}=f\left(w_{k} \cdot W_{w}\right) wˉk=f(wk⋅Ww)
f ( ⋅ ) f(\cdot) f(⋅) 是双曲正切等非线性函数, W w W_{w} Ww是变换矩阵。 然后使用隐藏表示来计算每一个词的注意值:
α w k = exp ( w ˉ ⋅ w ˉ k T ) ∑ i exp ( w ˉ ⋅ w ˉ i T ) \alpha_{w}^{k}=\frac{\exp \left(\bar{w} \cdot \bar{w}_{k}^{\mathrm{T}}\right)}{\sum_{i} \exp \left(\bar{w} \cdot \bar{w}_{i}^{\mathrm{T}}\right)} αwk=∑iexp(wˉ⋅wˉiT)exp(wˉ⋅wˉkT)
上下文实体的注意向量 α e \alpha_{e} αe 是用类似的方法计算的:
α e k = exp ( w e ⋅ e k T ) ∑ i exp ( w e ⋅ e i T ) \alpha_{e}^{k}=\frac{\exp \left(w_{e} \cdot e_{k}^{\mathrm{T}}\right)}{\sum_{i} \exp \left(w_{e} \cdot e_{i}^{\mathrm{T}}\right)} αek=∑iexp(we⋅eiT)exp(we⋅ekT)
注意, 不使用当前候选实体信息来计算注意向量,原因是只有一小部分真正的事件触发词是实体。因此,候选触发词的实体类型对于ED来说是没有意义的。我们使用we作为注意源,我们将w从单词空间转化为实体类型空间计算最后注意向量, α = α w + α e . \alpha=\alpha_{w}+\alpha_{e} . α=αw+αe. 最后,上下文词表示 c w c_{w} cw , 上下文实体表示 c e c_{e} ce 由 C w \mathrm{C}_{\mathrm{w}} Cw和 C e \mathrm{C}_{\mathrm{e}} Ce加权和构成:
c w = C w α T c e = C e α T \begin{array}{l} c_{w}=\mathrm{C}_{\mathrm{w}} \alpha^{\mathrm{T}} \\ c_{e}=\mathrm{C}_{\mathrm{e}} \alpha^{\mathrm{T}} \end{array} cw=CwαTce=CeαT -
ED
图 4ED包含一个三层的人工神经网络ANN(一个输入层,一个隐藏层和一个softmax输出层)。
c w c_{w} cw, c e c_{e} ce和候选触发词 w w w 作为输入。然后 对于给定的输入样本 x , \mathrm{x}, x,,带参数 θ \theta θ ANN输出一个向量 O , \mathrm{O}, O, 其中第i个值 o i o_{i} oi是将 x \mathrm{x} x分类为第 i i i 事件类型的自信分数。为得到条件概率 p ( i ∣ x , θ ) , p(i \mid \mathrm{x}, \theta), p(i∣x,θ), 对所有事件类型应用softmax操作:
p ( i ∣ x , θ ) = e o i ∑ k = 1 m e o k p(i \mid \mathrm{x}, \theta)=\frac{e^{o_{i}}}{\sum_{k=1}^{m} e^{o_{k}}} p(i∣x,θ)=∑k=1meokeoi
训练实例 ( x ( i ) ; y ( i ) ) , \left(\mathrm{x}^{(\mathrm{i})} ; y^{(i)}\right), (x(i);y(i)), 定义负对数似然损失函数:
J ( θ ) = − ∑ i = 1 T log p ( y ( i ) ∣ x ( i ) , θ ) J(\theta)=-\sum_{i=1}^{T} \log p\left(y^{(i)} \mid \mathrm{x}^{(\mathrm{i})}, \theta\right) J(θ)=−i=1∑Tlogp(y(i)∣x(i),θ)
(SGD) Adadelta 规则。 正则化是由 dropout和 L 2 L_{2} L2 组成. -
监督注意
使用注释的论元信息来改善ED。论元词应该比其他词获得更多的注意。
首先使用带注释的论元构造 gold attentions向量。然后, 使用它们作为监督来训练注意机制。
构建gold attentions向量:(1)只对论元词进行注意力。所有的论元词都能获得同样的注意力,而其他词则得不到注意力。使得注意力和为1,如图5所示, α ∗ \alpha^{*} α∗ 是gold attentions向量
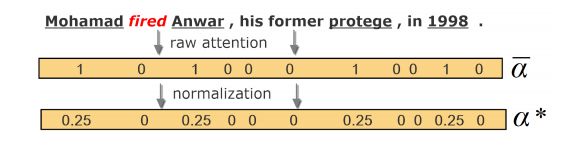
(2)注意这论元和它们周围的词语。一个词越接近论元,它就越应该得到关注。 用高斯分布 g ( ⋅ ) g(\cdot) g(⋅) 来模拟论元周围词语的注意力分布。具体,首先以(1)方式获取原始的注意向量 α ˉ \bar{\alpha} αˉ然后,创建一个所有的点初始化为0的新向量 α ′ \alpha^{\prime} α′ ,对于每一个 α ˉ i = 1 \bar{\alpha}_{i}=1 αˉi=1,我们通过以下算法更新 α ′ \alpha^{\prime} α′:

w w w 是注意机制的窗口大小, μ , σ \mu, \sigma μ,σ 高斯分布的超参数 .最后对 α ′ \alpha^{\prime} α′进行归一化,得到目标注意向量 α ∗ \alpha^{*} α∗。与(1)类似,如果当前候选触发词没有任何带注释的论元(例如负样例),则将上下文中的所有实体都视为论元。
-
联合训练ED和注意力
gold attention α ∗ \alpha^{*} α∗ 和 attention α \alpha α .采用平方误差作为attention的损失函数:
D ( θ ) = ∑ i = 1 T ∑ j = 1 n ( α j ∗ i − α j i ) 2 D(\theta)=\sum_{i=1}^{T} \sum_{j=1}^{n}\left(\alpha_{j}^{* i}-\alpha_{j}^{i}\right)^{2} D(θ)=i=1∑Tj=1∑n(αj∗i−αji)2
将模型的联合损失函数定义为:
J ′ ( θ ) = J ( θ ) + λ D ( θ ) J^{\prime}(\theta)=J(\theta)+\lambda D(\theta) J′(θ)=J(θ)+λD(θ)
DEEB-RNN
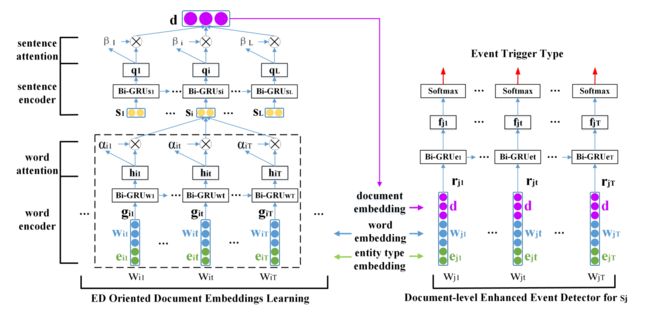
模型包含两部分:(1)The ED Oriented Document Embedding Learning (EDODEL) 该系统通过精心设计的分层监督注意机制,从单词和句子两个层次学习文档的分布式表示。(2)The Document-level Enhanced Event Detector (DEED)它根据学习到的文档embedding为每个候选触发词 标记一个事件类型。
-
EDODEL
Word-level embeddings
给定句子 s i ( i = 1 , 2 , . . . , L ) {s_{i}}(i = 1, 2, ..., L) si(i=1,2,...,L) ,里面有 T T T个词语:
{ w i t ∣ t = 1 , 2 , … , T } \left\{w_{i t} \mid t=1,2, \ldots, T\right\} { wit∣t=1,2,…,T}w i t : \boldsymbol{w}_{i t}: wit: 对每个词的本身进行embedding,得到embedding向量 w i t \boldsymbol{w}_{i t} wit
e i t : e_{i t}: eit: 对每个词的命名实体类型进行embedding,得到 e i t e_{i t} eit 。然后把这俩向量给串到一起, g i t = [ w i t , e i t ] \boldsymbol{g}_{i t}=\left[\boldsymbol{w}_{i t}, \boldsymbol{e}_{i t}\right] git=[wit,eit]
把句子里的单词的嵌入都给送入一个Bi-GRU模型,得到每个单词的正向和反向的各自的输出
h i t = [ G R U w → ( g i t ) , G R U w ← ( g i t ) ] \boldsymbol{h}_{i t}=\left[\overrightarrow{\mathrm{GRU}_{w}}\left(\boldsymbol{g}_{i t}\right), \overleftarrow{\mathrm{GRU}_{w}}\left(\boldsymbol{g}_{i t}\right)\right] hit=[GRUw(git),GRUw(git)]
送入一个全连接层加一个激活函数tanh
u i t = tanh ( W w h i t ) \boldsymbol{u}_{\boldsymbol{i t}}=\tanh \left(W_{w} \boldsymbol{h}_{\boldsymbol{i t}}\right) uit=tanh(Wwhit)
然后乘以一个线性系数,来算出来一个这个词在预测事件触发词方面的权重
α i t = u i t T c w \alpha_{i t}=\boldsymbol{u}_{i t}^{\mathrm{T}} c_{w} αit=uitTcw
那么到底哪些词对预测事件触发词最重要呢?当然是这些触发词本身了,所以我们定义一个触发词的指示器 α i t ∗ , \alpha_{i t}^{*}, αit∗, 如果它是触发词就等于 1 , 1, 1, 否则就是 0 0 0.如图 7(a)所示,“Indicated”是触发词
当然我们希望这个权重和这个触发词指示器越接近越好
Min E w ( α ∗ , α ) = ∑ i = 1 L ∑ t = 1 T ( α i t ∗ − α i t ) 2 \operatorname{Min} E_{w}\left(\boldsymbol{\alpha}^{*}, \boldsymbol{\alpha}\right)=\sum_{i=1}^{L} \sum_{t=1}^{T}\left(\alpha_{i t}^{*}-\alpha_{i t}\right)^{2} MinEw(α∗,α)=i=1∑Lt=1∑T(αit∗−αit)2
有了每个词的权重,我们把所有词加权平均就得到了一个句子的embedding
s i = ∑ t = 1 T α i t h i t s_{i}=\sum_{t=1}^{T} \alpha_{i t} h_{i t} si=t=1∑TαithitSentence-level embeddings
一个文件中, 有很多个句子 { s i ∣ i = 1 , 2 , … , L } \left\{s_{i} \mid i=1,2, \ldots, L\right\} { si∣i=1,2,…,L},还是送入 Bi-GRU 模型
q i = [ G R U s → ( s i ) , G R U s ← ( s i ) ] \boldsymbol{q}_{i}=\left[\overrightarrow{\mathrm{GRU}_{s}}\left(s_{i}\right), \overleftarrow{\mathrm{GRU}_{s}}\left(s_{i}\right)\right] qi=[GRUs(si),GRUs(si)]
接入一个全连接层和激活层
t i = tanh ( W s q i ) \boldsymbol{t}_{\boldsymbol{i}}=\tanh \left(W_{s} \boldsymbol{q}_{\boldsymbol{i}}\right) ti=tanh(Wsqi)
再加上一个线性层得到这个句子在文件中所有句子的权重
β i = t i T c s \beta_{i}=\boldsymbol{t}_{\boldsymbol{i}}^{\mathrm{T}} c_{s} βi=tiTcs
对于这个权重,当然是希望那些含有触发词的句子获得大的权重了, β i ∗ : \beta_{i}^{*}: βi∗: 含有触发词的句子权重为 1 , 1, 1, 否则就为 0, 如图 7(b)所示,紫色是含有触发词句子。希望学习得到的权重可以和 β i ∗ \beta_{i}^{*} βi∗ 越接近越好
Min E s ( β ∗ , β ) = ∑ i = 1 L ( β i ∗ − β i ) 2 \operatorname{Min} E_{s}\left(\boldsymbol{\beta}^{*}, \boldsymbol{\beta}\right)=\sum_{i=1}^{L}\left(\beta_{i}^{*}-\beta_{i}\right)^{2} MinEs(β∗,β)=i=1∑L(βi∗−βi)2有了这个权重,就把所有句子的embedding矢量加权平均得到整个文件的embedding了
d = ∑ i = 1 L β i s i d=\sum_{i=1}^{L} \beta_{i} s_{i} d=i=1∑Lβisi -
DEED
有了整个文件的embedding矢量,我们把它和每个词的embedding矢量合并在一起,作为这个词的新的特征,来预测词是哪个事件的触发词
r j t = [ w j t , e j t , d ] \boldsymbol{r}_{j \boldsymbol{t}}=\left[\boldsymbol{w}_{j t}, e_{j t}, d\right] rjt=[wjt,ejt,d]
然后再进一个 Bi-GRU,
f j t = [ G R U → e ( r j t ) , G R U e ← ( r j t ) ] \boldsymbol{f}_{j t}=\left[\overrightarrow{\mathrm{GRU}}_{e}\left(\boldsymbol{r}_{j t}\right), \overleftarrow{\mathrm{GRU}_{e}}\left(\boldsymbol{r}_{j t}\right)\right] fjt=[GRUe(rjt),GRUe(rjt)]
最后通过一个softmax层来预测这个单词是K个事件的触发词中哪一个,还是哪个都不是
O j t = softmax ( f j t ) , O_{j t}=\operatorname{softmax}\left(f_{j t}\right), \quad Ojt=softmax(fjt),
其中 o j t ( k ) o_{j t}^{(k)} ojt(k) 表示将单词 w j t {w}_{j t} wjt 分到第 k k k 类事件的触发词的概率,而它到底是不是,是由真正的类别标号说了算的。y j t = k y_{j t}=k_{\text { }} yjt=k 就说明了 w j t w_{j t} wjt是第 k \mathrm{k} k 个类别的触发词,我们当然希望 y j t = k y_{j t}=k yjt=k 的时候 o j t ( k ) o_{j t}^{(k)} ojt(k) 越大越好
Min J ( y , o ) = − ∑ j = 1 L ∑ t = 1 T ∑ k = 1 K I ( y j t = k ) log o j t ( k ) \operatorname{Min} J(\boldsymbol{y}, \boldsymbol{o})=-\sum_{j=1}^{L} \sum_{t=1}^{T} \sum_{k=1}^{K} \mathrm{I}\left(y_{j t}=k\right) \log o_{j t}^{(k)} MinJ(y,o)=−j=1∑Lt=1∑Tk=1∑KI(yjt=k)logojt(k)
所有目标函数加起来,就有了最终的学习的问题
Min J ( θ ) = ∑ ∀ d ∈ ϕ ( J ( y , o ) + λ E w ( α ∗ , α ) + μ E s ( β ∗ , β ) ) \operatorname{Min} \mathbb{J}(\theta)=\sum_{\forall d \in \phi}\left(J(\boldsymbol{y}, \boldsymbol{o})+\lambda E_{w}\left(\boldsymbol{\alpha}^{*}, \boldsymbol{\alpha}\right)+\mu E_{s}\left(\boldsymbol{\beta}^{*}, \boldsymbol{\beta}\right)\right) MinJ(θ)=∀d∈ϕ∑(J(y,o)+λEw(α∗,α)+μEs(β∗,β))
PLMEE

图 8 PLMEE架构的说明,包括一个触发词提取器和一个论元提取器。还显示了由单词“killed”触发的事件实例的处理过程。
-
触发词提取器
触发词提取器的目的是预测出触发了事件的token,形式化为token级别的多类别分类任务,分类标签是事件类型。在BERT上添加一个多类分类器就构成了触发词提取器。
输入和BERT的一样,是WordPiece embedding、位置embedding和segment embedding的和。因为输入只有一个句子,所以所有的segment ids设为0。句子首尾的token分别是[CLS]和[SEP]。
触发词有时不是一个单词而是一个词组。因此,作者令连续的tokens共享同一个预测标签,作为一个完整的触发词。
采用交叉熵损失函数用于微调(fine-tune)。
-
论元提取器
给定触发词的条件下,论元提取器的目的是抽取出和触发器所对应事件相关的论元,以及这些论元扮演的角色。
和触发词提取相比较,论元的抽取更加复杂,主要有3个原因:
论元对触发词的依赖;
大多数论元是较长的名词短语;
角色重叠问题。
和触发词提取器一样,论元提取器也需要3种embedding相加作为输入,但还需要知道哪些tokens组成了触发词,因此特征表示输入的segment将触发词所在的span设为1。
为了克服论元抽取面临的后2个问题, 在BERT上添加了多组二类分类器(多组分类器设为所有角色标签的集合,对每个论元判断所有类型角色的概率)。每组分类器服务于一个角色,以确定所有属于它的论元的范围(span:每个span都包括start和end)。
这种方法类似于在SQuAD上的问答任务,只有一个答案是正确的,然而扮演同一角色的多个论元可能在一个事件中同时出现。
由于预测和角色是分离的,一个论元可以扮演多个角色(对一个论元使用一组二类分类器,一组二类分类器中有多个分类器,对应多个角色),一个token可以属于不同的论元。这就缓解了角色重叠问题。
-
论元范围的界定
在PLMEE模型中,一个token t t t 被预测为角色 r r r 的论元的start的概率为:
P s r ( t ) = Softmax ( W s r ⋅ B ( t ) ) P_{s}^ {r}(t)=\operatorname{Softmax }\left(W_{s}^ {r} \cdot \mathcal{B}(t )\right) Psr(t)=Softmax(Wsr⋅B(t))
被项则为end的概率为
P e r ( t ) = Softmax ( W e r ⋅ B ( t ) ) P_{e}^{r}(t)=\operatorname{Softmax}\left(W_{e}^{r} \cdot \mathcal{B}(t)\right) Per(t)=Softmax(Wer⋅B(t))
其中, 下标"s"表示"start", 下标""“表示"end”。 W s r W_{s}^{r} Wsr 是二类分类器的权重, 目的是检测出扮演角色 r r r 的论元的starts, W e r W_{e}^{r} Wer目的是检测出ends。 B \mathcal{B} B 是BERT嵌入。对于每个角色 r , r, r, 我们可以根据 P s r , P e r P_{s}^{r}, P_{e}^{r} Psr,Per 得到两个元素值为0或1的列表 B s r , B e r B_{s}^{r}, B_{e}^{r} Bsr,Ber.它们分别表示句子中的token是否是扮演角色 r r r 的论元的start或end。如下所示的算法1用于检测每个token,来决定扮演角色 r r r的所有论元的spans:

一共有3种状态:(1)既没有检测出start,也没有检测出end;(2)只检测出了start;(3)既检测到了start,也检测到了end。
状态转换的规则如下:(1)当前token为start时,状态1转移到状态2;(2)当前token为end时,状态2转移到状态3;(3)当前token是一个new start时,状态3转移到状态2。
注意,当出现多个start/end时,选择概率更大的那一个。
-
损失权重重置
将所有二分类器检测论元start的损失函数记为 L s \mathcal{L } _ { s } Ls ,检测end的损失函数记为 L e \mathcal{L }_{e } Le 。 C E \mathrm{CE} CE 表示交叉嫡, R \mathcal{R} R 是角色集合, S \mathcal{S } S 是输入的句子。
L s = 1 ∣ R ∣ × ∣ S ∣ ∑ r ∈ R CE ( P s r , y s r ) L e = 1 ∣ R ∣ × ∣ S ∣ ∑ r ∈ R CE ( P e r , y e r ) \begin{array}{l} \mathcal{L }_{s}=\frac{1}{|\mathcal{R}| \times|\mathcal{S}|} \sum_{r \in \mathcal{R}} \operatorname{CE}\left(P_{s}^ {r}, \boldsymbol{y}_{s}^ {r}\right) \\ \mathcal{L}_{e}=\frac{1}{|\mathcal{R}| \times|\mathcal{S}|} \sum_{r \in \mathcal{R}} \operatorname{CE}\left(P_{e}^{r}, \boldsymbol{y}_{e}^ {r}\right) \end{array} Ls=∣R∣×∣S∣1∑r∈RCE(Psr,ysr)Le=∣R∣×∣S∣1∑r∈RCE(Per,yer)
对 L s \mathcal{L }_{s} Ls 和 L e \mathcal{L }_{e } Le 取均值作为论元抽取器最终的损失 L \mathcal{ L } L.但是,如图 6.1.1所示, 不同角色的出现频率有着很大的不同,这就意味着不同的角色在事件中的“重要性”不同。 ( ( ( 这里的“重要性”指的是根据该角色判断出特定类型事件的能力) 。例如, "Victim"比起"Time"更能推断出Die类型的事件。
因此,我们不采用直接对 L s \mathcal{L}_{s } Ls 和 L e \mathcal{L }_{e } Le 求平均的方法来确定损失函数, 而是根据角色的“重要性”对 L s \mathcal{L}_{s } Ls 和 L e \mathcal{L }_{e } Le 的权重进行重置。并使用RF、IEF两个度量 (类似于TF-IDF), 计算角色的“重要性":
(1)Role Frequency (RF)
RF定义为角色 r r r 在类型为 v v v 的事件中出现的频率:
RF ( r , v ) = N v r ∑ k ∈ R N v k \operatorname{RF}( r, v)=\frac{N_{v}^{r}}{\sum_{k \in \mathcal{R}} N_{v } ^ {k}} RF(r,v)=∑k∈RNvkNvr
(2)Inverse Event Frequency (IEF)log内的分母表示有多少类型的事件有角色 r r r
IEF ( r ) = log ∣ V ∣ ∣ { v ∈ V : r ∈ v } ∣ \operatorname{IEF}( r ) = \log \frac{ | \mathcal{V } | } { | \{ v \in \mathcal{V } : r \in v\} |} IEF(r)=log∣{ v∈V:r∈v}∣∣V∣
R F ( r , v ) R F(r, v) RF(r,v) 和 I E F ( r ) I E F(r) IEF(r) 相乘得到 R F − I E F ( r , v ) , R F-I E F(r, v), RF−IEF(r,v), 使用RF-IEF度量角色 r r r 对于 v v v 类型事件
I ( r , v ) = exp R F − I E F ( r , v ) ∑ r ′ ∈ R exp R F − I E F ( r ′ , v ) I(r, v)=\frac{\exp ^{\mathrm{RF}-\mathrm{IEF}(r, v)}}{\sum_{r^{\prime} \in R} \exp ^{\mathrm{RF}-\mathrm{IEF}\left(r^{\prime}, v\right)}} I(r,v)=∑r′∈RexpRF−IEF(r′,v)expRF−IEF(r,v)
给定输入的事件类型 v , v, v, 根据每个角色对于 v v v 类型事件的重要性,计算损失 L s \mathcal{L}_{s} Ls 和 L e , \mathcal{L}_{e}, Le, 将两者取平均就得到最终的损失。
L s = ∑ r ∈ R I ( r , v ) ∣ S ∣ CE ( P s r , y s r ) L e = ∑ r ∈ R I ( r , v ) ∣ S ∣ CE ( P e r , y e r ) \begin{aligned} \mathcal{L}_{s} &=\sum_{r \in \mathcal{R}} \frac{I(r, v)}{|\mathcal{S}|} \operatorname{CE}\left(P_{s}^{r}, \boldsymbol{y}_{s}^{r}\right) \\ \mathcal{L}_{e} &=\sum_{r \in \mathcal{R}} \frac{I(r, v)}{|\mathcal{S}|} \operatorname{CE}\left(P_{e}^{r}, \boldsymbol{y}_{e}^{r}\right) \end{aligned} LsLe=r∈R∑∣S∣I(r,v)CE(Psr,ysr)=r∈R∑∣S∣I(r,v)CE(Per,yer) -
训练数据的生成
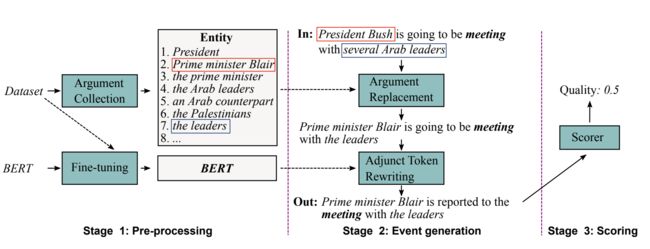
基于预训练语言模型的的事件生成方法,如图 9所示,由3步组成:预处理、事件生成、对事件打分。
定义adjunct tokens为句子中除去触发词和论元之外的tokens,不仅包括单词和数字,还包括标点符号。
adjunct tokens可以调整表达的流畅性和多样性。因此,尝试重写它们以扩展生成结果的多样性,同时保持触发词和论元不变。
- 预处理
收集ACE2005数据集中的论元和它们对应的角色,但是不考虑有角色重叠问题的论元,因为这些论元通常是较长的短语且包括大量的无关信息,将它们纳入考虑可能会带来不必要的错误。
在接下来的步骤中,采用BERT作为目标模型来重写adjunct tokens,并使用BERT的masked语言模型任务在ACE2005数据集上进行微调。
-
事件生成
由两步组成:首先,将原型(prototype)中的论元替换为扮演相同角色的相似论元;然后,使用微调后的BERT重写adjunct tokens。
(1)论元替换
将具有相同角色标签的论元进行替换。替换后标签没有发生变化,仍可以使用原始的标签进行样本生成。
使用余弦相似性作为选择新论元的度量,有以下两点考虑:1)两个有相同角色标签的论元在语义上可能很不同;2)论元对应的角色在很大程度上取决于它的上下文。因此,选取语义相似并且上下文连贯的新论元替换原有论元。
使用可以解决OOV(out of vocabulary)问题的ELMO模型,生成论元的embedding。其中 a a a 表示论元, E \mathcal{E} E表示ELMO生成的embedding。
E ( a ) = 1 ∣ a ∣ ∑ t ∈ a E ( t ) \mathcal{E}(a) = \frac{1}{|a|} \sum_{t \in a} \mathcal{ E}( t ) E(a)=∣a∣1t∈a∑E(t)
选取top 10个最相似的论元作为候选,然后使用softmax计算出概率,取概率最高的作为替换论元。(2)重写adjunct tokens
论元替换的结果已经可以看成是数据生成了,但是固定的上下文可能会增加过拟合的风险。因此,为了平滑数据并扩展其多样性,作者使用微调后的BERT进行adjunct tokens的重写。
重写意味着使用更适合当前上下文的tokens,替换原型中的一些adjunct tokens。可看成是完形填空任务(Cloze task),一些adjunct tokens被mask了,需要使用BERT基于上下文预测出来被mask的部分。
需要重写的adjunct tokens的比率为 m m m 。图9中 m m m 设为了1.0,也就是mask了所有的adjunct tokens。可以看出尽管 m m m为1.0,还是有一些adjunct tokens保留了下来。
-
对事件打分
使用打分函数衡量生成事件的价值,选择出更有价值的生成事件。主要考虑两个因素:1)困惑度(perplexity ,反映了生成数据的合理性);2)距离(评估生成数据和原有数据集间的距离)。
(1)困惑度(Perplexity, PPL)
PPL ( S ′ ) = 1 ∣ A ( S ′ ) ∣ ∑ t ∈ A ( S ′ ) P ( t ) \operatorname{PPL}\left(\mathcal{S}^{\prime}\right)=\frac{1}{\left|A\left(\mathcal{S}^{\prime}\right)\right|} \sum_{t \in A\left(\mathcal{S}^{\prime}\right)} P(t) PPL(S′)=∣A(S′)∣1t∈A(S′)∑P(t)
A A A 表示在句子 中 S ′ \mathcal{S} ^ { ' } S′ 已被重写的adjunct tokens(2)距离(Distance, DIS)
使用余弦相似性:
DIS ( S ′ , D ) = 1 − 1 ∣ D ∣ ∑ S ∈ D B ( S ′ ) ⋅ B ( S ) ∣ B ( S ′ ) ∣ × ∣ B ( S ) ∣ \operatorname{DIS} \left(\mathcal{S}^{\prime}, \mathcal{D}\right){=} 1-\frac{1}{|\mathcal{D}|} \sum_{\mathcal{S} {\in} \mathcal{D}} \frac{\mathcal{B}\left(\mathcal{S}^{\prime}\right) {\cdot} \mathcal{B}(\mathcal{S})}{\left|\mathcal{B}\left(\mathcal{S}^{\prime}\right)\right| \times|\mathcal{B}(\mathcal{S})|} DIS(S′,D)=1−∣D∣1S∈D∑∣B(S′)∣×∣B(S)∣B(S′)⋅B(S)句子 S ′ \mathcal{S} ^ { ' } S′ 的embedding由BERT生成,使用第一个token [CLS]的embedding作为整个句子的embedding。
高质量的生成数据应该有较低的PPL和较高的DIS,打分函数定义如下。选取出高质量的生成样本用于实验。
Q ( S ′ ) = 1 − ( λ PPL ( S ′ ) + ( 1 − λ ) DIS ( S ′ , D ) ) Q\left(\mathcal{S}^{\prime}\right)=1-\left(\lambda \operatorname{PPL}\left(\mathcal{S}^{\prime}\right)+(1-\lambda) \operatorname{DIS}\left(\mathcal{S}^{\prime}, \mathcal{D}\right)\right) Q(S′)=1−(λPPL(S′)+(1−λ)DIS(S′,D))
PLMEE模型的局限性:
(1)同一类型的事件通常具有相似性,并且共现的角色通常有很强的关联,但是PLMEE模型没有考虑不同触发词间的关联以及不同论元间的关联。
(2)尽管生成模型中使用了评分函数对生成的样本进行筛选,但仍面临着和远程监督方法一样的角色偏离问题。(因为adjunct tokens重写之后语义可能会发生很大的变化)
6.1.2、关系分类模型
在流水线方式的因果关系抽取中,关系分类任务使用事件检测阶段标注出的语料,对已标记事件的语料进行因果关系的判别。当前对因果关系抽取的研究相对较少,因果关系分类是特殊的关系分类,关系分类的主要任务是抽取出语料中实体对间存在的关系,与因果关系抽取事件间的关系的任务比较类似。
卷积网络在文本分类或自然语言处理中的应用已有文献进行了探索。研究表明,卷积网络可以直接应用于语料的分布式表示,而不需要对文本的句法或语义结构有任何了解。Liu 等将关系抽取任务分为了实体抽取和关系分类两个部分串行处理,提出了一种结合词汇特征的卷积网络,采用同义词词典对输入词进行编码,将语义知识集成到了神经网络中,解决了词嵌入忽略词汇之间的语义关系的缺陷,但是 Liu提出的卷积模型的结构比较简单,且没有设置池化层,受噪音影响比较明显。Zeng 等首次提出使用位置特征(Position Feature,PF)来编码到目标词的相对距离,用卷积神经网络提取词汇和句子级的特征,将所有的单词标注作为输入(无预处理操作)。 通过词嵌入将单词标记转换为向量,根据给定的词提取出词汇级别的特征,同时使用卷积神经网络学习句子级特征。连接两个层次的特征输入到 softmax 分类器预测两个标记实体的关系。实验结果证明了位置特征在关系抽取中的有效性。
往往输入文本序列的含义与单词的顺序是有联系的,因此使用循环神经网络来进行因果关系的抽取也是可行的。基于循环神经网络的关系抽取使用不同的循环神经网络模型获取文本的信息,进后对每个时序的隐藏状态进行组合,从而获得句子级的特征。在因果关系的抽取任务中,对于每一个时序的输入,模型通常只在序列的最后得到关系的标记特征。Zhang 等6首次利用循环神经网络来进行关系的抽取,提出了双向循环神经网络模型。
循环神经网络关系的抽取
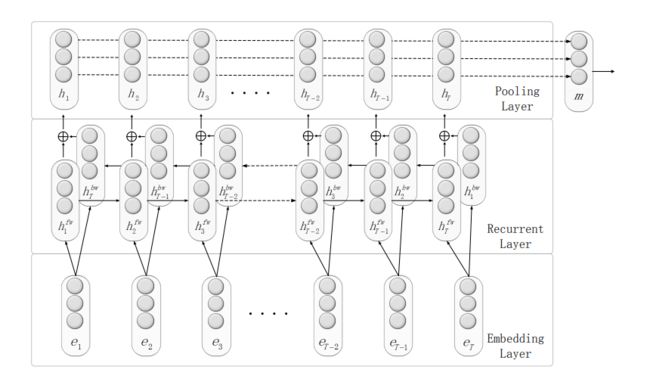
如图 10 所示,模型包含三个组成部分:
- (1)单词embedding层,将句子中的每个单词映射成低维的词向量;
- (2)双向递归层,对单词序列进行建模并生成词级特征(表示);
- (3)一种最大池化层,通过在每个维度的所有单词级特征中选择最大值,将每个时间步(每个单词)的单词级特征合并成句子级特征向量。
最后利用句子级特征向量进行关系分类。双向循环神经网络模型中的每一时刻的输出向量不仅依赖于序列中当前时刻之前的输入,也依赖于后续时间的输入。文中使用更加简单的位置指示器(Position indicator,PI)取代了的位置特征。在不使用任何词汇特征的情况下,结合位置指示器的双向循环神经网络模型与使用外部信息 WordNet 的 Zeng 提出的模型具有相似的性能效果,并证明了词嵌入的维度可以很明显影响 F 值。使用双向循环神经网络模型进行关系抽取,将输入窗口设置到了两个实体的前后固定长度的文本序列,并根据距离远近赋予单词不同的权重。
-
双向递归层
给一句子 X = ( x 1 , x 2 , … , x T ) , X=\left(x_{1}, x_{2}, \ldots, x_{T}\right), X=(x1,x2,…,xT),单词被投影到一个单词向量序列中,表示为 ( e 1 , e 2 , … , e T ) \left(e_{1}, e_{2}, \ldots, e_{T}\right) (e1,e2,…,eT) , T T T 是词数. 在每一步 t , t, t, e t e_{t} et 和前面的输出 h t − 1 f w h_{t-1}^{f w} ht−1fw 作为输入, 并产生当前输出 h t f w h_{t}^{f w} htfw 通过一个线性变换,然后是一个非线性的激活函数:
h t f w = tanh ( W f w e t + U f w h t − 1 f w + b f w ) h_{t}^{f w}=\tanh \left(W_{f w} e_{t}+U_{f w} h_{t-1}^{f w}+b_{f w}\right) htfw=tanh(Wfwet+Ufwht−1fw+bfw)
h t f w ∈ R M h_{t}^{f w} \in R^{M} htfw∈RM :RNN在第 t t t - step的输出,可以看作是词 ( x 1 , … , x t ) \left(x_{1}, \ldots, x_{t}\right) (x1,…,xt)段产生的局部段级特征.*:*注意, M M M是特征向量的维数, W f w ∈ R M × D W_{f w} \in R^{M \times D} Wfw∈RM×D U f w ∈ R M × M , b f w ∈ R M × 1 U_{f w} \in R^{M \times M}, b_{f w} \in R^{M \times 1} Ufw∈RM×M,bfw∈RM×1 是模型参数。双向RNN需将正向RNN和反向RNN的输出相加即可得到第t步的预测,公式如下:
h t = h t f w + h t b w h_{t}=h_{t}^{f w}+h_{t}^{b w} ht=htfw+htbw
h t b w ∈ R M h_{t}^{b w} \in R^{M} htbw∈RM 反向RNN的输出:
h t b w = tanh ( W b w e t + U b w h t + 1 b w + b b w ) h_{t}^{b w}=\tanh \left(W_{b w} e_{t}+U_{b w} h_{t+1}^{b w}+b_{b w}\right) htbw=tanh(Wbwet+Ubwht+1bw+bbw) -
Max-pooling
句子级关系分类需要一个单独的句子级特征向量来表示整个句子。
在RNN结构中,由于句子的语义是逐字学习的,因此在句子末尾产生的段级特征向量实际上代表了整个句子。由于训练数据中存在大量的远程模式,因此积累方法并不十分适合于关系学习。由于梯度消失的恼人问题,重复连接的积累容易使长期信息迅速遗忘,句子末尾的监督很难传播到模型训练的早期阶段。
因此, 采用CNN模型中的最大池方法,句子特征可以通过合并局部特征表示来实现。max-pooling的表达式为:
m i = max t { ( h t ) i } , ∀ i = 1 , … , M m_{i}=\max _{t}\left\{\left(h_{t}\right)_{i}\right\}, \quad \forall i=1, \ldots, M mi=tmax{ (ht)i},∀i=1,…,M
其中, m m m为句子特征向量, i i i为特征维数。假设只有几个关键字和相关的特征对关系分类是重要的,因此最大池化更适合促进信息最丰富的模式。
-
训练
训练目标是,对于给定的句子,输出特征向量h在关系分类任务上表现最好。这里 使用一个简单的逻辑回归模型作为分类器。在形式上,该模型预测输入句子 X X X涉及关系 r r r的后验概率如下:
P ( r ∣ X , θ , W o , b o ) = σ ( W o h ( X ) + b o ) P\left(r \mid X, \theta, W_{o}, b_{o}\right)=\sigma\left(W_{o} h(X)+b_{o}\right) P(r∣X,θ,Wo,bo)=σ(Woh(X)+bo)
σ ( x ) = e x i ∑ j e x j \sigma(x)=\frac{e^{x_{i}}}{\sum_{j} e^{x_{j}}} σ(x)=∑jexjexi 是softmax函数, θ \theta θ RNN模型的参数. 基于logistic回归分类器,自然目标函数是预测和标签之间的交叉熵,给出如下:
L ( θ , W o , b o ) = ∑ n ∈ N − log p ( r ( n ) ∣ X ( n ) , θ , W o , b o ) \mathcal{ L } \left( \theta, W_{o}, b_{o} \right)= \sum_{n \in N} - \log{p} \left(r^ {(n)} \mid X ^ {(n)}, \theta, W_{o}, b_{o}\right) L(θ,Wo,bo)=n∈N∑−logp(r(n)∣X(n),θ,Wo,bo)
其中, n n n是句子在训练数据中的索引, X ( n ) X^{(n)} X(n)和 r ( n ) r^{(n)} r(n)分别是第 n n n句及其关系标号。 -
位置指标
在关系学习中,让算法知道目标名词是至关重要的。在cnn的方法中,在每个单词向量上附加了一个位置特征向量,即单词到名词的距离。对于RNN,由于模型学习了整个词序列,可以在正向或反向递归传播过程中自动获得每个词的相对位置信息。因此,注释单词序列中的目标词就足够了,而不需要更改输入向量。我们选择一个简单的方法,使用四个位置指示器(PI)来指定标号的开始和结束:“ people have been moving back into downtown ”. 注意,people和downtown是关系为“实体-目的地(e1,e2)”的两个名称。PI在训练和测试过程中被视为单词。
循环神经网络模型随着时间会出现权重指数级爆炸或消失的问题,难以捕捉长期时间关联,而 LSTM 可以很好解决这个问题。将 LSTM 模型用于关系抽取任务,LSTM 结合最短依存路径能够有效提取句子级别的关系。Zhou 等在 BiLSTM 的基础上增加了注意力机制7,提出了 Att-BiLSTM 模型。
Att-BiLSTM
模型:
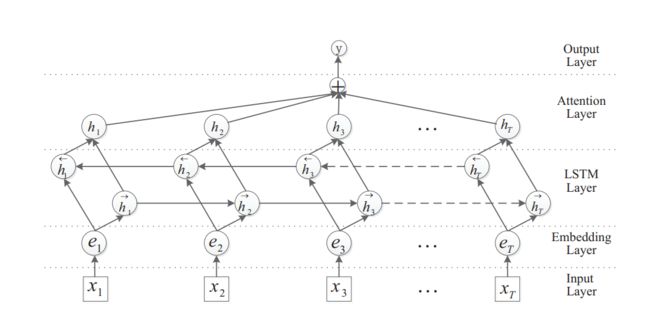
模型包含五个组件:
-
(1)输入层:该模型的输入句;
-
(2)Embedding层:将每个单词映射到一个低维向量;
-
(3)LSTM层:利用BiLSTM从step(2)获得高级特性;
-
(4)注意层:生成一个权值向量,并将每个时间步长的词级特征合并为一个句子级特征向量,通过权值向量相乘;
-
(5)输出层:句子级特征向量最终用于关系分类
-
BiLSTM
通常, lstm 神经网络由三个组成:一个input gate i t i_{t} it, forget gate f t f_{t} ft , output gate o t o_{t} ot ,所有这些门都被设置为产生分数,输入当前 x i x_{i} xi,和上一步产生的状态 h i − 1 h_{i-1} hi−1,和细胞状态 c i − 1 c_{i-1} ci−1 (窥视孔):
i t = σ ( W x i x t + W h i h t − 1 + W c i c t − 1 + b i ) f t = σ ( W x f x t + W h f h t − 1 + W c f c t − 1 + b f ) g t = tanh ( W x c x t + W h c h t − 1 + W c c c t − 1 + b c ) c t = i t g t + f t c t − 1 o t = σ ( W x o x t + W h o h t − 1 + W c o c t + b o ) h t = o t tanh ( c t ) \begin{aligned} i_{t} &=\sigma\left(W_{x i} x_{t}+W_{h i} h_{t-1}+W_{c i} c_{t-1}+b_{i}\right) \\ f_{t} &=\sigma\left(W_{x f} x_{t}+W_{h f} h_{t-1}+W_{c f} c_{t-1}+b_{f}\right) \\ g_{t} &=\tanh \left(W_{x c} x_{t}+W_{h c} h_{t-1}+W_{c c} c_{t-1}+b_{c}\right) \\ c_{t} &=i_{t} g_{t}+f_{t} c_{t-1} \\ o_{t} &=\sigma\left(W_{x o} x_{t}+W_{h o} h_{t-1}+W_{c o} c_{t}+b_{o}\right) \\ h_{t} &=o_{t} \tanh \left(c_{t}\right) \end{aligned} itftgtctotht=σ(Wxixt+Whiht−1+Wcict−1+bi)=σ(Wxfxt+Whfht−1+Wcfct−1+bf)=tanh(Wxcxt+Whcht−1+Wccct−1+bc)=itgt+ftct−1=σ(Wxoxt+Whoht−1+Wcoct+bo)=ottanh(ct)
因此,当前细胞状态 c t c_t ct将使用之前的细胞状态和细胞产生的当前信息计算加权和生成。BLSTM 的 i t h i^{t h} ith 个词输出 为下式:
h i = [ h i → ⊕ h i ← ] h_{i}=\left[\overrightarrow{h_{i}} \oplus \overleftarrow{h_{i}}\right] hi=[hi⊕hi] -
Attention
H H H 是由输出向量 [ h 1 , h 2 , … , h T ] \left[h_{1}, h_{2}, \ldots, h_{T}\right] [h1,h2,…,hT] 组成的矩阵 , T T T 是句子的长度。 句子的表示 r r r由这些输出向量的加权和构成:
M = tanh ( H ) α = softmax ( w T M ) r = H α T \begin{array}{l} M=\tanh (H) \\ \alpha=\operatorname{softmax}\left(w^{T} M\right) \\ r=H \alpha^{T} \end{array} M=tanh(H)α=softmax(wTM)r=HαT
H ∈ R d w × T , d w H \in \mathbb{R}^{d^{w} \times T}, d^{w} H∈Rdw×T,dw 是词向量的维数, w w w 是参数向量 . w , α , r w, \alpha, r w,α,r 的尺寸是 d w , T , d w d^{w}, T, d^{w} dw,T,dw最终用于分类的句子表示:
h ∗ = tanh ( r ) h^{*}=\tanh (r) h∗=tanh(r) -
Classifying
使用softmax分类器从一个离散的类集合 Y Y Y中预测一个句子S的标签 y ^ \hat{y} y^。分类器接受隐藏状态 h ∗ h^{*} h∗作为输入:
p ^ ( y ∣ S ) = softmax ( W ( S ) h ∗ + b ( S ) ) y ^ = arg max y p ^ ( y ∣ S ) \begin{array}{c} \hat{p}(y \mid S)=\operatorname{softmax}\left(W^{(S)} h^{*}+b^{(S)}\right) \\ \hat{y}=\arg \max _{y} \hat{p}(y \mid S) \end{array} p^(y∣S)=softmax(W(S)h∗+b(S))y^=argmaxyp^(y∣S)
代价函数是真实类标签 y ^ \hat{y} y^的负对数似然:
J ( θ ) = − 1 m ∑ i = 1 m t i log ( y i ) + λ ∥ θ ∥ F 2 J(\theta)=-\frac{1}{m} \sum_{i=1}^{m} t_{i} \log \left(y_{i}\right)+\lambda\|\theta\|_{F}^{2} J(θ)=−m1i=1∑mtilog(yi)+λ∥θ∥F2
其中, t ∈ ℜ m t \in \Re^{m} t∈ℜm为one-hot 表示ground truth, y ∈ ℜ m \boldsymbol{y} \in \Re^{m} y∈ℜm 是softmax对每个类别的估计概率 ( m (m (m 目标类的数量)。在Embedding层、LSTM层和倒数第二层中使用了Dropout。
研究证明利用深度神经网络从句子中学习句法语义特征是有效的,但是不可避免地存在信息冗余。Xiao 等8使用多级循环神经网络,并将注意力机制引入其中,选择性的关注句子中的有用信息。根据标记的实体位置将语料分成了五个部分,分别传输到 BiLSTM-Attention 层学习特征表示,之后传输进双向循环神经网络( Bi-directional Recurrent Neural Network,Bi-RNN)层进行三个表示的语义组合,最终 softmax 层进行分类操作。类似的,Chen 等9提出了一个多通道框架,根据两个实体将句子分为多个通道。每个通道都用层次神经网络进行处理。这些通道在循环传播期间不相互作用,这使得神经网络能够学习不同的表示。为了能够更好的抽取语料特征,研究人员将循环神经网络、卷积神经网络、图神经网络等与机器学习的相关方法进行组合,建模语言模型进行因果关系抽取。Huang 等10首次将BiLSTM-CRF 模型应用于 NLP 基准序列标记数据集,其中条件随机场(Conditional Random Field,CRF)使用句子级的标记信息,带来了较高的精度。条件随机场,是一种标注算法,输入一段序列后输出目标序列,在 NLP 的标注任务中,输入序列为一段文本,输出相应的标记序列。由于选择使用双向 LSTM 组件,该模型可以同时使用过去和将来的输入特性。此外,由于 CRF 层的存在,该模型可以使用句子级的标签信息。
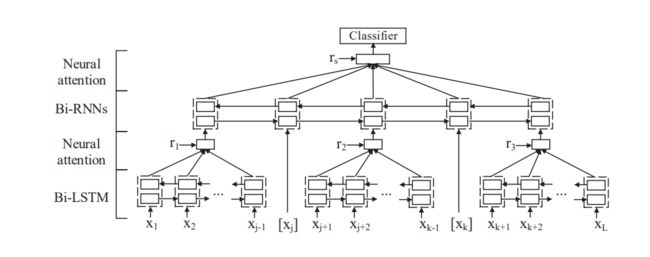
多级循环神经网络
-
分割
图 12 给定一个长度为 L L L 句子 s s s 及其标注的名词e1和e2,首先根据两个标注的名词将句子分为五个部分:左上下文子序列 [ x 1 , … , x j − 1 ] , \left[x_{1}, \ldots, x_{j-1}\right], [x1,…,xj−1], 实体e1 [ x j ] \left[x_{j}\right] [xj]、中间上下文子序列 [ x j + 1 , … , x k − 1 ] \left[x_{j+1}, \ldots, x_{k-1}\right] [xj+1,…,xk−1] 、实体e2 [ x k ] \left[x_{k}\right] [xk]和右上下文子序列 [ x k + 1 , … , x L ] \left[x_{k+1}, \ldots, x_{L}\right] [xk+1,…,xL]。以这种方式预处理句子允许模型独立地对每个上下文子序列进行编码。
-
Bi-LSTM
给定一个句子 s s s分为左上下文子序列 c 1 c_{1} c1,中间上下文子序列 c 2 c_{2} c2,右上下文子序列 c 3 , c_{3}, c3, Bi-LSTM的输入是一个上下文子序列 c i : [ x i 1 , c_{i}:\left[x_{i 1},\right. ci:[xi1, … , x i T i ] \left.\ldots, x_{i T_{i}}\right] …,xiTi] , i ∈ [ 1 , 3 ] . i \in[1,3] . i∈[1,3]. T i T_{i} Ti 个词, x i t x_{i t} xit是词 w i t . w_{i t} . wit. 的 embedding。在时刻步 t t t,编码器产生一个隐藏状态 h i t h_{i t} hit,它以 w i t w_{i t} wit为中心,收集整个上下文子序列 c i c_{i} ci的信息。
h i t → = L S T M → ( x i t ) h i t ← = L S T M ↔ ( x i t ) h i t = concat ( h i t → , h i t ← ) \begin{aligned} \overrightarrow{h_{i t}} &=\overrightarrow{L S T M}\left(x_{i t}\right) \\ \overleftarrow{h_{i t}} &=\overleftrightarrow{L S T M}\left(x_{i t}\right) \\ h_{i t} &=\operatorname{concat}\left(\overrightarrow{h_{i t}}, \overleftarrow{h_{i t}}\right) \end{aligned} hithithit=LSTM(xit)=LSTM (xit)=concat(hit,hit)
h i t = [ h i t → ; h i t ← ] . h_{i t}=\left[\overrightarrow{h_{i t}} ; \overleftarrow{h_{i t}}\right] . hit=[hit;hit]. -
Word-level Attention
关注这些对预测实体之间的关系很重要的词,对这些词多加关注是一个很好的策略。注意机制使模型能够沿着上下文子序列对双lstm的隐藏向量进行不同的关注,并产生它们的加权表示 m i m_i mi,如下所示:
z i t = tanh ( W ( w ) h i t + W ( c ) r i + b ) α i t = exp ( v z ⊤ z i t ) ∑ j = 1 T i exp ( v z ⊤ z i j ) m i = ∑ t = 1 T i α i t h i t \begin{aligned} z_{i t} &=\tanh \left(W^{(w)} h_{i t}+W^{(c)} r_{i}+b\right) \\ \alpha_{i t} &=\frac{\exp \left(v_{z}^{\top} z_{i t}\right)}{\sum_{j=1}^{T_{i}} \exp \left(v_{z}^{\top} z_{i j}\right)} \\ m_{i} &=\sum_{t=1}^{T_{i}} \alpha_{i t} h_{i t} \end{aligned} zitαitmi=tanh(W(w)hit+W(c)ri+b)=∑j=1Tiexp(vz⊤zij)exp(vz⊤zit)=t=1∑Tiαithit
v z v_{z} vz :权重向量, r i r_{i} ri 是在训练过程中随机初始化和联合优化的外部上下文向量外部上下文向量不仅表示上下文子序列 c i c_{i} ci的高级含义,而且允许模型识别单词 w i t w_{i t} wit在上下文子序列$c_{i} 中 。 上 下 文 子 序 列 中。上下文子序列 中。上下文子序列c_{i} 中 第 中 第 中第t$ 个词 w i t w_{i t} wit对应的注意表示形式 z i t z_{i t} zit是通过隐态 h i t h_{i t} hit和外部上下文向量 r i r_{i} ri的非线性组合来计算的。
-
句法成分
Bi-LSTM捕获三个上下文子序列的含义,从而得到三个上下文表示之后,有一个困难是如何进一步获得这些上下文表示加上两个标记名词表示的语义组合。
采用Bi-rnn将三个上下文子序列和两个带注释的名词的句法语义整合到句子表示中,并将其输入到一个分类器中进行关系分类。Bi-rnn能够对这些上下文子序列及其内在关系进行语义建模,这对获取句子的语义意义具有重要意义。
Y Y Y *:*是一个包含五个列向量 [ m 1 , m e 1 , m 2 , m e 2 , m 3 ] \left[m_{1}, m_{e_{1}}, m_{2}, m_{e_{2}}, m_{3}\right] [m1,me1,m2,me2,m3]的矩阵 , m i ( i ∈ [ 1 , 3 ] ) m_{i}(i \in[1,3]) mi(i∈[1,3]) 是上下文子序列的表示 c i c_{i} ci, m e 1 m_{e_{1}} me1 , m e 2 m_{e_{2}} me2 带注释的名词表示。句子的组合向量表示:
h j → = R N N → ( y j ) h j ← = R N N ↔ ( y j ) h j = concat ( h j → , h j ← ) \begin{aligned} \overrightarrow{h_{j}} &=\overrightarrow{R N N}\left(y_{j}\right) \\ \overleftarrow{h_{j}} &=\overleftrightarrow{R N N}\left(y_{j}\right) \\ h_{j} &=\operatorname{concat}\left(\overrightarrow{h_{j}}, \overleftarrow{h_{j}}\right) \end{aligned} hjhjhj=RNN(yj)=RNN (yj)=concat(hj,hj)
y j ∈ Y ( j ∈ [ 1 , 5 ] ) y_{j} \in Y(\mathrm{j} \in[1,5]) yj∈Y(j∈[1,5]) j j j的列向量在 Y \mathrm{Y} Y.里面 -
训练
一个全连接的softmax层作为分类器进行分类。以句子表示形式 s : s: s:为条件,得到关系类型上的概率分布 p p p
p = softmax ( W ( s ) s + b ( s ) ) p=\operatorname{softmax}\left(W^{(s)} s+b^{(s)}\right) p=softmax(W(s)s+b(s))
训练目标是最小化ground truth和预测标签之间的交叉熵误差。 L 2 L_{2} L2 正则。
多通道框架
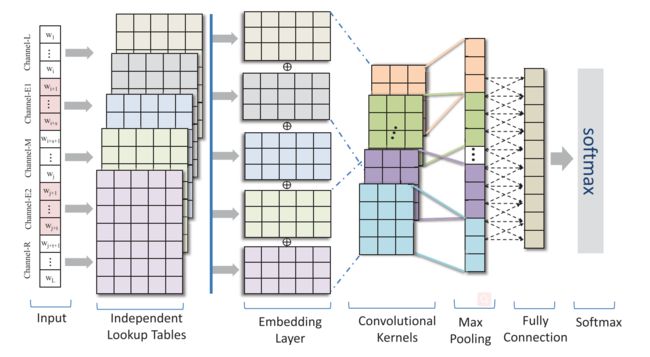
一种多通道的句子结构和语义信息捕获方法,主要优点是它学习不同的词表示一个词来处理词的歧义问题,从而在关系识别任务中捕获句子的结构和语义信息。
-
基础模型
s = w 1 , w 2 , ⋯ s=w_{1}, w_{2}, \cdots s=w1,w2,⋯ 输入关系提及(或简称提及), w i w_{i} wi 是单词。将 s s s中的每个词转换为embedding 形式,通过查找词embedding 表 W e \mathrm{W}_{e} We。因为c nn需要固定长度的输入,较长的提及和较短的提及分别被修整或填充。设 L L L为预定义的句子长度,则将句子 s s s映射成一个向量序列,表示为 x = [ x 1 , x 2 , ⋯ , x L ] . \mathrm{x}=\left[\mathrm{x}_{1}, \mathrm{x}_{2}, \cdots, \mathrm{x}_{L}\right] . x=[x1,x2,⋯,xL].
x = Embedding ( s ) \mathrm{x}=\text { Embedding }(s) x= Embedding (s)
x i ∈ R H \mathrm{x}_{i} \in R^{H} xi∈RH 是 w i w_{i} wi 的embedding ,维度为H . 如果词汇量是 V , V, V, W e ∈ R V × H ^ \mathrm{W}_{e} \in R^{V \times \hat{H}} We∈RV×H^ ,它可以用随机过程或预先训练的词嵌入来初始化。 x i : i + K \mathrm{x}_{i: i+K} xi:i+K 表 [ x i , x i + 1 , ⋯ , x i + K ] \left[\mathrm{x}_{i}, \mathrm{x}_{i+1}, \cdots, \mathrm{x}_{i+K}\right] [xi,xi+1,⋯,xi+K],卷积运算实现为:
c i = f c ( W c ⊤ ⋅ x i : i + K ⊤ + b ) \mathrm{c}_{i}=f_{c}\left(\mathrm{W}_{c}^{\top} \cdot \mathrm{x}_{i: i+K}^{\top}+b\right) ci=fc(Wc⊤⋅xi:i+K⊤+b)
W c ∈ R K × H \mathrm{W}_{c} \in R^{K \times H} Wc∈RK×H 是卷积运算的卷积核 .其中, f c f_{c} fc是非线性函数(如双曲正切), c i \mathrm{c}_{i} ci的维数为 H H H。当卷积操作迭代实现时 [ x 1 , x 2 , ⋯ , x N ] , \left[\mathrm{x}_{1}, \mathrm{x}_{2}, \cdots, \mathrm{x}_{N}\right], [x1,x2,⋯,xN], 它的形式如下: 其中 c ∈ R L − K + 1 : \mathrm{c} \in R^{L-K+1}: c∈RL−K+1:
c = Conv ( x ) \mathrm{c}=\operatorname{Conv}(\mathrm{x}) c=Conv(x)
卷积运算可以有效地捕获局部特征。 将 K-gram [ x i , x i + 1 , ⋯ , x i + K ] \left[\mathrm{x}_{i}, \mathrm{x}_{i+1}, \cdots, \mathrm{x}_{i+K}\right] [xi,xi+1,⋯,xi+K] 转化为高阶特征表示, c i c_{i} ci可以学习 K K K -gram的语义或语法信息。为了获得信息最丰富的特性,在池化层中,通过 c \mathrm{c} c的每个元素实现一个max操作。记为:
p = Pooling ( c ) = Max { c 1 , c 2 , ⋯ , c L − K + 1 } \mathrm{p}=\operatorname{Pooling}(\mathrm{c})=\operatorname{Max}\left\{\mathrm{c}_{1}, \mathrm{c}_{2}, \cdots, \mathrm{c}_{L-K+1}\right\} p=Pooling(c)=Max{ c1,c2,⋯,cL−K+1}
池化层之后,可以采用全连通层给出全局规则,由softmax层输出类上的概率分布。它们表示为:
y = Softmax ( Conn ( p ) ) y=\operatorname{Softmax}(\operatorname{Conn}(\mathrm{p})) y=Softmax(Conn(p))
其中,完全连接的层实现了表示为 W f ⋅ p \mathrm{W}_{f} \cdot \mathrm{p} Wf⋅p。综上所述,给定一个提到的关系 s s s,一个传统的关系识别CNN表示为:
y = Softmax ( Conn ( Pooling ( Conv ( Embed ding ( s ) ) ) ) ) y=\operatorname{Softmax}(\operatorname{Conn}(\operatorname{Pooling}(\operatorname{Conv}(\operatorname{Embed} \operatorname{ding}(s))))) y=Softmax(Conn(Pooling(Conv(Embedding(s)))))
模型参数为 θ = \theta= θ= [ W e , W c , W f , b ] . \left[\mathrm{W}_{e}, \mathrm{W}_{c}, \mathrm{W}_{f}, b\right] . [We,Wc,Wf,b]. -
扩展模型
卷积层和池化层可以多次叠加,生成更高阶特征,表示为:
y = Softmax ( Conn ( Pooling ( Conv ⋯ ( Pooling ( Conv ( Embedding ( s ) ) ) ( ⋯ ) ) ) \begin{array}{r} y=\operatorname{Softmax}(\operatorname{Conn}(\text { Pooling }(\text { Conv } \cdots \\ (\text { Pooling }(\operatorname{Conv}(\text { Embedding }(s)))(\cdots))) \end{array} y=Softmax(Conn( Pooling ( Conv ⋯( Pooling (Conv( Embedding (s)))(⋯)))
残差连接可以用于连接不同级别的高阶特征,它遵循人类根据不同的抽象语义信息来识别句子的直觉。该技术的一个示例如下所示,其中 ⊕ \oplus ⊕表示为连接操作。
y = Softmax ( Conn ( Pooling ( Conv ( R ) ) ) ) R = P o o l i n g ( Conv ( E m b e d d i n g ( s ) ) ) ⊕ E m b e d d i n g ( s ) y=\operatorname{Softmax}(\operatorname{Conn}(\operatorname{Pooling}(\operatorname{Conv}(\mathrm{R}))))\\ \\ \mathrm{R}= Pooling (\operatorname{Conv}( Embedding (s))) \oplus Embedding (s) y=Softmax(Conn(Pooling(Conv(R))))R=Pooling(Conv(Embedding(s)))⊕Embedding(s)
意味着Embedding ( s ) (s) (s)将其卷积和max运算的输出连接起来。还可以在网络中添加LSTM层,以捕获所提到的关系中的依赖项.将LSTM层称为 L S T M ( x ) , L S T M(x), LSTM(x), :
y = Softmax ( Conn ( Pooling ( Conv ( L S T M ( R ) ) ) ⊕ P o o l i n g ( Conv ( LSTM ( R ) ) ) ) ) y=\operatorname{Softmax}(\operatorname{Conn}(\operatorname{Pooling}(\operatorname{Conv}(L S T M(\boldsymbol{R}))) \oplus \\ Pooling (\operatorname{Conv}(\operatorname{LSTM}(\mathrm{R}))))) y=Softmax(Conn(Pooling(Conv(LSTM(R)))⊕Pooling(Conv(LSTM(R)))))
R = \mathrm{R}= R= Embedding ( s ) . (s) . (s).许多研究集中于在嵌入层中结合多源数据,包括词嵌入、词性标签嵌入、位置嵌入或外部资源,例如,设pos, posit分别表示词性标签和位置序列。那么
y = Softmax ( Conn ( Pooling ( Conv ( R ) ) ) ) y=\operatorname{Softmax}(\operatorname{Conn}(\operatorname{Pooling}(\operatorname{Conv}(\mathrm{R})))) y=Softmax(Conn(Pooling(Conv(R))))
其中, R = \mathrm{R}= R= Embedding(s) ⊕ \oplus ⊕ Embedding(pos) ⊕ \oplus ⊕ Embedding(posit). -
改进模型
s = w 1 , w 2 , ⋯ s=w_{1}, w_{2}, \cdots s=w1,w2,⋯ 被提及的关系, 其中 w i + 1 , ⋯ , w i + s w_{i+1}, \cdots, w_{i+s} wi+1,⋯,wi+s 和 w j + 1 , ⋯ , w j + t w_{j+1}, \cdots, w_{j+t} wj+1,⋯,wj+t 是s中的两个命名实体。两个命名实体可以将一个关系提及分为五个parts: { [ w 1 , ⋯ , w i ] , [ w i + 1 , ⋯ , w i + s ] , [ w i + s + 1 , ⋯ , w j ] \left\{\left[w_{1}, \cdots, w_{i}\right],\left[w_{i+1}, \cdots, w_{i+s}\right],\left[w_{i+s+1}, \cdots, w_{j}\right]\right. { [w1,⋯,wi],[wi+1,⋯,wi+s],[wi+s+1,⋯,wj] [ w j + 1 , ⋯ , w j + t ] , [ w j + t + 1 , ⋯ ] } . \left.\left[w_{j+1}, \cdots, w_{j+t}\right],\left[w_{j+t+1}, \cdots\right]\right\} . [wj+1,⋯,wj+t],[wj+t+1,⋯]}. 它们被称为:
Channel − L , -L,