最新美团点评Java团队面试题:java进阶培训班
其实互联网职业可以大致分两个阶段,在毕业后的3到5年内主要都是以学习、积累为主,从一开始啥都不懂的校园“新鲜人”向“职业人”转变。如果你是Java开发者,在这个阶段你会学习:
1、基础的Java知识,多线程、集合类、JVM
2、进阶知识,设计模式、系统设计和方法论
3、主流框架,Spring、Spring Boot、MyBatis……
4、微服务,Dubbo、ETCD、Spring Cloud……
5、数据库,Redis、ES、MySQL、分库分表
分享一下我的学习之路
2017从杭州师范大学(也是马云的母校)毕业后,我就留在了杭州,因为家庭原因,从大三开始已经没了考研的想法,只想快点工作,能稍微减轻父母身上的重担。计算机科班毕业,当时因为简历的原因在加上自己学的不是很好,投入大厂的简历全部石沉大海,没有丝毫音讯。最终来到了一家上市公司,浑浑噩噩的渡过的两年,除了CRUD啥都不懂,每月拿着9K+的薪水,日子过得紧张而又无趣。
今年年初,疫情覆盖全国,造成了大小型互联网公司全面缩水裁员,我们公司也不例外(公司不养闲人这个上班族都是明白的)毫无意外我被裁掉。本来感觉生活很无趣又惨遭下岗,这样的打击差点让我崩溃。(不过后来我知道,这是个提升自己的契机)
正文
作为后端开发,日常操作数据库最常用的是写操作和读操作。读操作我们下边会讲,这个分类里我们主要来看看写操作时为什么会导致 SQL 变慢。
刷脏页
脏页的定义是这样的:内存数据页和磁盘数据页不一致时,那么称这个内存数据页为脏页。
那为什么会出现脏页,刷脏页又怎么会导致 SQL 变慢呢?那就需要我们来看看写操作时的流程是什么样的。
对于一条写操作的 SQL 来说,执行的过程中涉及到写日志,内存及同步磁盘这几种情况。

这里要提到一个日志文件,那就是 redo log,位于存储引擎层,用来存储物理日志。在写操作的时候,存储引擎(这里讨论的是 Innodb)会将记录写入到 redo log 中,并更新缓存,这样更新操作就算完成了。后续操作存储引擎会在适当的时候把操作记录同步到磁盘里。
看到这里你可能会有个疑问,redo log 不是日志文件吗,日志文件就存储在磁盘上,那写的时候岂不很慢吗?
其实,写redo log 的过程是顺序写磁盘的,磁盘顺序写减少了寻道等时间,速度比随机写要快很多( 类似Kafka存储原理),因此写 redo log 速度是很快的。
好了,让我们回到开始时候的问题,为什么会出现脏页,并且脏页为什么会使 SQL 变慢。你想想,redo log 大小是一定的,且是循环写入的。在高并发场景下,redo log 很快被写满了,但是数据来不及同步到磁盘里,这时候就会产生脏页,并且还会阻塞后续的写入操作。SQL 执行自然会变慢。
锁
写操作时 SQL 慢的另一种情况是可能遇到了锁,这个很容易理解。举个例子,你和别人合租了一间屋子,只有一个卫生间,你们俩同时都想去,但对方比你早了一丢丢。那么此时你只能等对方出来后才能进去。
对应到 Mysql 中,当某一条 SQL 所要更改的行刚好被加了锁,那么此时只有等锁释放了后才能进行后续操作。
但是还有一种极端情况,你的室友一直占用着卫生间,那么此时你该怎么整,总不能尿裤子吧,多丢人。对应到Mysql 里就是遇到了死锁或是锁等待的情况。这时候该如何处理呢?
Mysql 中提供了查看当前锁情况的方式:

通过在命令行执行图中的语句,可以查看当前运行的事务情况,这里介绍几个查询结果中重要的参数:
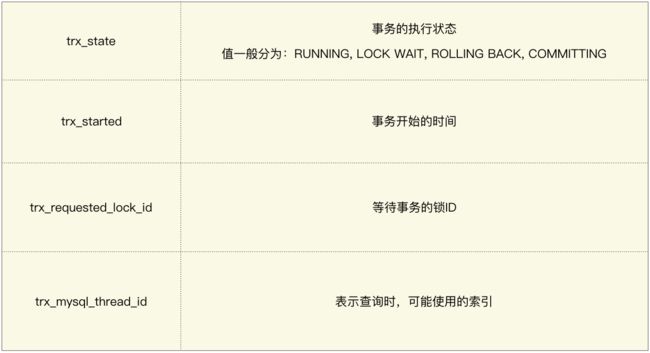
当前事务如果等待时间过长或出现死锁的情况,可以通过 「kill 线程ID」 的方式释放当前的锁。
这里的线程 ID 指表中 trx_mysql_thread_id 参数。
读操作
说完了写操作,读操作大家可能相对来说更熟悉一些。SQL 慢导致读操作变慢的问题在工作中是经常会被涉及到的。
慢查询
在讲读操作变慢的原因之前我们先来看看是如何定位慢 SQL 的。Mysql 中有一个叫作慢查询日志的东西,它是用来记录超过指定时间的 SQL 语句的。默认情况下是关闭的,通过手动配置才能开启慢查询日志进行定位。
具体的配置方式是这样的:
- 查看当前慢查询日志的开启情况:
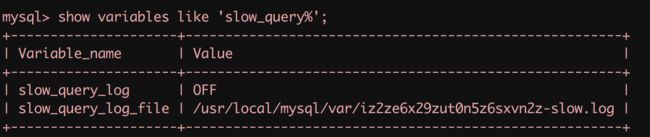
- 开启慢查询日志(临时):
![]()
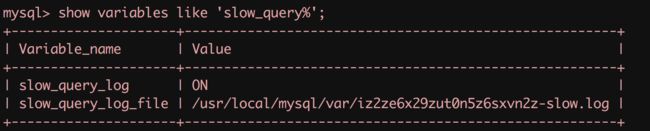
注意这里只是临时开启了慢查询日志,如果 mysql 重启后则会失效。可以 my.cnf 中进行配置使其永久生效。
存在原因
知道了如何查看执行慢的 SQL 了,那么我们接着看读操作时为什么会导致慢查询。
(1)未命中索引
SQL 查询慢的原因之一是可能未命中索引,关于使用索引为什么能使查询变快以及使用时的注意事项,网上已经很多了,这里就不多赘述了。
(2)脏页问题
另一种还是我们上边所提到的刷脏页情况,只不过和写操作不同的是,是在读时候进行刷脏页的。
是不是有点懵逼,别急,听我娓娓道来:
为了避免每次在读写数据时访问磁盘增加 IO 开销,Innodb 存储引擎通过把相应的数据页和索引页加载到内存的缓冲池(buffer pool)中来提高读写速度。然后按照最近最少使用原则来保留缓冲池中的缓存数据。
那么当要读入的数据页不在内存中时,就需要到缓冲池中申请一个数据页,但缓冲池中数据页是一定的,当数据页达到上限时此时就需要把最久不使用的数据页从内存中淘汰掉。但如果淘汰的是脏页呢,那么就需要把脏页刷到磁盘里才能进行复用。
你看,又回到了刷脏页的情况,读操作时变慢你也能理解了吧?
防患于未然
知道了原因,我们如何来避免或缓解这种情况呢?
首先来看未命中索引的情况:
不知道大家有没有使用 Mysql 中 explain 的习惯,反正我是每次都会用它来查看下当前 SQL 命中索引的情况。避免其带来一些未知的隐患。
这里简单介绍下其使用方式,通过在所执行的 SQL 前加上 explain 就可以来分析当前 SQL 的执行计划:

执行后的结果对应的字段概要描述如下图所示:
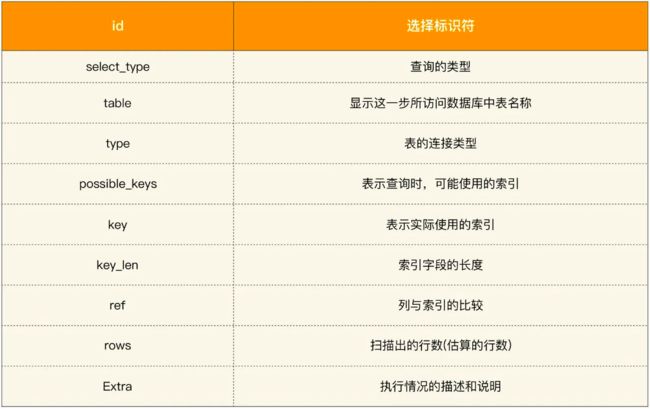
这里需要重点关注以下几个字段:
1、type
表示 MySQL 在表中找到所需行的方式。其中常用的类型有:ALL、index、range、 ref、eq_ref、const、system、NULL 这些类型从左到右,性能逐渐变好。
-
ALL:Mysql 遍历全表来找到匹配的行;
-
index:与 ALL 区别为 index 类型只遍历索引树;
-
range:只检索给定范围的行,使用一个索引来选择行;
-
ref:表示上述表的连接匹配条件,哪些列或常量被用于查找索引列上的值;
-
eq_ref:类似ref,区别在于使用的是否为唯一索引。对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用 primary key 或者 unique key作为关联条件;
-
const、system:当 Mysql 对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于 where 列表中,Mysql 就能将该查询转换为一个常量,system 是 const类型的特例,当查询的表只有一行的情况下,使用system;
-
NULL:Mysql 在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成。
2、possible_keys
查询时可能使用到的索引(但不一定会被使用,没有任何索引时显示为 NULL)。
3、key
实际使用到的索引。
4、rows
估算查找到对应的记录所需要的行数。
5、Extra
比较常见的是下面几种:
-
Useing index:表明使用了覆盖索引,无需进行回表;
-
Using where:不用读取表中所有信息,仅通过索引就可以获取所需数据,这发生在对表的全部的请求列都是同一个索引的部分的时候,表示mysql服务器将在存储引擎检索行后再进行过滤;
-
Using temporary:表示MySQL需要使用临时表来存储结果集,常见于排序和分组查询,常见 group by,order by;
-
Using filesort:当Query中包含 order by 操作,而且无法利用索引完成的排序操作称为“文件排序”。
对于刷脏页的情况,我们需要控制脏页的比例,不要让它经常接近 75%。同时还要控制 redo log 的写盘速度,并且通过设置 innodb_io_capacity 参数告诉 InnoDB 你的磁盘能力。
最后
俗话说,好学者临池学书,不过网络时代,对于大多数的我们来说,我倒是觉得学习意识的觉醒很重要,这是开始学习的转折点,比如看到对自己方向发展有用的信息,先收藏一波是一波,比如如果你觉得我这篇文章ok,先点赞收藏一波。这样,等真的沉下心来学习,不至于被找资料分散了心神。慢慢来,先从点赞收藏做起,加油吧!
好啦,由于文章篇幅限制,面试题答案详解我就不在这里展示出来了,如果你需要这份完整版的面试题答案详解资料点击这里免费领取
另外,给大家安排了一波学习面试资料:


面试题答案详解资料点击这里免费领取](https://docs.qq.com/doc/DSmxTbFJ1cmN1R2dB)**
另外,给大家安排了一波学习面试资料:
[外链图片转存中…(img-NATJG42C-1621868754786)]
[外链图片转存中…(img-lFxifNgx-1621868754787)]
以上就是本文的全部内容,希望对大家的面试有所帮助,祝大家早日升职加薪迎娶白富美走上人生巅峰!