中配置kylin_kylin+SuperSet实现实时大数据报表的快速开发
本文作者:易小华
最近我的团队将报表计算引擎从阿里的ads迁移到了kylin上,解决了非常多的问题,将一些我们的解决方案分享出来,希望对读者或者在用kylin的人有所帮助。
一、 之前现状和问题
之前我们系统的报表都是基于阿里的rocketmq和ADS开发的,业务系统在业务代码中将数据同步到rocketmq中,然后ads再从rocketmq同步数据,再基于ads提供的api开发查询逻辑,前端还要开发报表展示的代码。这种方式上线以后,随着数据量的不断增长暴露出了很多缺陷。
- 经常会出现消息丢失的情况,或者系统变慢的情况。
- 由于购买的阿里云的服务,rocketmq和ADS服务对我们来说一直是一个黑盒,问题很不好定位和解决,而且很多问题的解决依赖于阿里云,响应时效不是很及时,长此以来积累了大量的报表问题,客户抱怨声不断。
- 开发工作量庞大,产品人员设计好一张报表以后,要上线要苦等一个多月的开发时间,而且遇到问题还无法上线。
基于以上问题我们觉得再继续用阿里的ads作为我们的报表计算引擎,后续问题会越来越多。因此我们尝试使用新的报表引擎,这个报表引擎对我们一定不是一个黑盒。
二、 报表计算引擎的选择(kylin)
基于以上几个问题,在对tidb,druid,kylin,mdrill等各种开源系统进行调研以后,最终选择了kylin作为我们的报表计算引擎,一方面是sql支持度相对来说比其他系统好比如精确distinct功能,一方面是和hadoop的几个组件集成得非常好,tidb和已有hadoop组件集成得不大好,需要重新搭建集群代价很大。还有就是基于java开发很符合团队的技能特点,可以根据业务特点定制我们自己的版本。
三、 数据分钟级延迟问题解决(canal+flume+kafka)
选好了kylin这个报表计算引擎后,还需要解决的就是我们报表计算的数据延迟最大也要到分钟级别,这个可以通过kylin的kafka数据源来实现,配置方式见下面的链接。
http://kylin.apache.org/cn/docs/tutorial/cube_streaming.html
但是使用kafka还有一个问题就是业务系统的数据怎么实时的传输到kafka呢,之前都是在业务系统中编写数据发送逻辑到消息队列中,这种方式和业务系统耦合非常大,随便改点逻辑都需要依赖于业务系统上版本周期很长,沟通成本很大。因此我们采取了用阿里巴巴开源的canal抓取mysql binlog的方式,实时的去抓取mysql的增删改查数据,这种方式要开启mysql的binlog。Canal项目的主页:
https://github.com/alibaba/canal
有了canal抓取并解析binlog以后,还有一个问题要解决的是怎么让canal抓取到的数据可靠的传输到kafka中,基于canal和kafka的api自己开发的方式,成本很大,而且要考虑高可用,容错,扩展性等问题,再者我们的时间和开发资源也非常有限,因此我们基于flume的接口开发了一个canal source,充分利用flume的灵活性,扩展性,高可用,负载均衡和容错等特性,同时也可以和已有的source,channel和sink组件随意组合。
这样通过 canal+flume+kafka 和 kylin的streamingcube 特性,我们就很好的解决了数据分钟级别的延迟问题。
四、 数据实时更新和删除问题
下一个要解决的问题就是数据的更新和删除的问题,这个我们是基于业务逻辑来解决的,当然我们在实现上会考虑好业务场景的通用性,每次更新和删除数据我们都不会去修改原来的数据,而是往kafka中插入新的数据并标记这条数据是删除,还是更新,并记录前后值的变化,同时在接入层面尽可能对数据进行去重处理,降低后续cube构建和sql编写的难度。
由于我们在数据层面和原来的变化了,因此我们还需要在sql层面进行改写,当然改写后的sql肯定要利用上kylin的预计算特性,否则查询速度很慢。
在解决数据实时更新和删除问题上,耗费了我们大量的时间,前后也讨论过很多种方案,而且实现起来需要对kylin的预计算特性有深入的了解,对维度设计要利用kylin的特性充分的进行精简,否则会走弯路。
下面是我们的model和cube界面:

五、 并发查询问题
接下来就是并发查询的问题了,由于kylin本身就带有cache特性,负载均衡而且采用的是预计算模式,因此应付并发上很好办,负载均衡这一块开始准备用nginx做负载均衡,后来觉得自己维护还是很麻烦,而且我们其他系统已经在使用阿里的SLB做负载均衡了,因此最终我们还是用SLB来做负载均衡。
最终我们做到了能够将数据在5分钟以内延迟下,支持实时的删除和更新操作,对报表各个维度的数据进行查询,汇总在1秒以内返回,明细在1到3秒内返回。
六、 使用superset报表开发方式
最后要解决的一个问题就是开发效率的问题了,之前我们的报表开发后台首先要手工编写大量的sql,然后使用spring和mybatis编写大量的业务逻辑,并通过微服务的方式暴露接口,然后前端再根据接口,编写前端展示代码,而且移动端,电脑端都要写一套。
这种方式开发周期长,耗费人力大,而且工作挑战不大也比较枯燥,大家都很痛苦,产品等得痛苦,开发开发得痛苦。
因此我们调研了几个前端的工具,后来发现了airbnb开源的superset这个好东西,操作简单,图表美观,而且单表不支持的情况可以通过自定义sql来支持。最关键的是kylin对它进行了很好的集成,链接如下:
http://kylin.apache.org/blog/2018/01/01/kylin-and-superset/
还有一个关键点是superset的图表可以通过iframe嵌入到网页中数据不是静态的而是随时更新的,还支持在电脑端和手机端展示,对数据和图表的权限控制也做得非常到位。基本满足了自助开发,然后嵌入到页面中展示的要求,可以大大节省我们的报表开发周期和开发工作量,甚至可以做到让产品自助拖拽式开发。
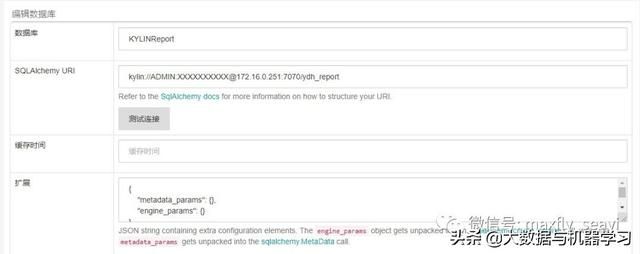
Superset Kylin数据源配置:
图表开发:
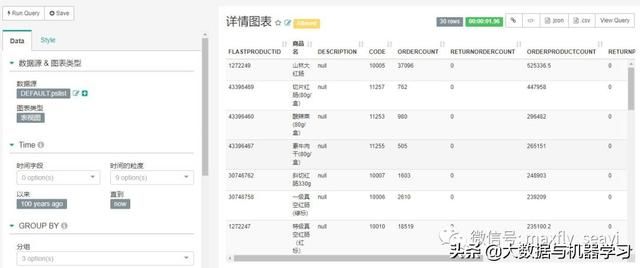
Iframe嵌入:

七、 最终的架构
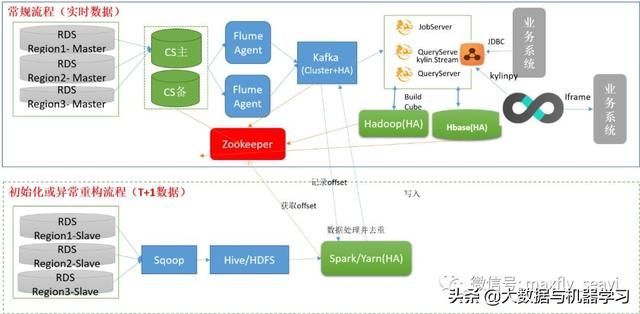
八、 一些实现细节
- canal 主备切换的时候数据会重复,这个问题需要在接入层面或者在canal层面注意,我们是在接入层面监测到切换后对最近数据进行实时去重(自己编写flume source带去重逻辑,会缓存一个可配置时间段的数据,因为canal切换很快所以不需要缓存很长时间,而且用storm里面的timecachmap不会影响到性能)。
- kylin不支持hadoop和habse的高版本,之前我尝试把我们的集群升级到了hdp3.0版本(hive3.1,hadoop3.0,hbase2.1),也尝试修改kylin源码来适配高版本,但是改到后面发现工作量非常大,时间来不及只好又把集群回退到了hdp2.6.4版本,后面把kylin修改好以后再升级集群。
- 查询一定要利用kylin的预计算特性否则时间会很长,尤其是子查询很可能会导致利用不上预计算特性。
- 设计cube的时候维度一定要尽量精简,cube计算时可根据数据量情况选择不同算法,rowkey可根据查询场景做一些优化。
- Kylin的distinct有精确distinct和非精确的,精确的计算要占用非常大的内存。
- steaming表是不能和lookup表进行join的。
- superset支持iframe嵌入要修改一些配置权限配置和跨站访问配置,否则不能展示或者要登录。
跨站访问修改这个配置:
HTTP_HEADERS = {'X-Frame-Options': ' '}
免登录访问加入以下配置:
PUBLIC_ROLE_LIKE_GAMMA = True
Public 角色的permissions里把以下三个加上
can explore on Superset
can explore json on Superset
all database access on all_database_access
8.使用多个kylin实例的时候,会存在多台服务器上session信息不一致问题,,可以通过配置Kylin将Session信息保存到Redis中(或MySQL、MemCache等),实现多个Kylin实例的Session共享。
九、 写在后面
时间仓促,整体方案写出来了,具体细节和遇到的问题写得不够详细或者写得不对的对方,有需要进一步了解的可以留言交流。后续报表这一块我们会进一步做到自定义报表到时的维度挑战是一个更大的问题,肯定需要进一步的优化当前方案。