Redis——Redis的进阶使用(管道/发布订阅/事务/布隆过滤器)
Redis的进阶使用
文章目录
- Redis的进阶使用
-
- 一、管道(pipelining)
- 二、发布订阅(Pub/Sub)
- 三、Redis 事务
- 四、布隆过滤器
在上一篇文章中我们详解 Redis的 key-value 键值对模型中 value 的细节点,重点在于理解 value 支持的五种数据结构,对于每种数据结构的基本用法(即常用命令),我们还要对每种数据结构的优劣势,以及常用业务场景要做到心中有数
作为缓存之王,Redis 绝对不可能只有这么一点儿功能,下面我们就来学习一下 Redis 的进阶使用
其实从 Redis 官网我们即可学习到所有的用法:http://redis.cn/documentation.html
一、管道(pipelining)
官网:http://redis.cn/topics/pipelining.html
管道是什么概念呢?
如果客户端对 redis 服务进程发出一连串的命令,其实每发一次命令都要走一次数据的传输,执行完返回,返回结果之后才能线性执行第二个命令。这意味着通常情况下一个请求会遵循以下步骤:
- 客户端向服务端发送一个查询请求,并监听Socket返回,通常是以阻塞模式,等待服务端响应。
- 服务端处理命令,并将结果返回给客户端。
因此,例如下面是4个命令序列执行情况:
- Client: INCR X
- Server: 1
- Client: INCR X
- Server: 2
- Client: INCR X
- Server: 3
- Client: INCR X
- Server: 4
客户端和服务器通过 TCP 网络进行连接,无论网络延如何延时,数据包总是能从客户端到达服务器,并从服务器返回数据回复客户端。这个时间被称之为 RTT (Round Trip Time - 往返时间),毫无疑问这种单次发送一个命令会带来大量的往返时间消耗,影响系统性能
此时我们自然而然就想到了一种优化方法——buffer 缓冲区,一次能够传输一批命令,对应在 Redis 中的实现就是管道
一次请求/响应服务器能实现处理新的请求,即使旧的请求还未被响应。这样就可以将多个命令发送到服务器,而不用等待回复,最后在一个步骤中读取该答复,这就是管道(pipelining)
管道使用案例:
$ (printf "PING\r\nPING\r\nPING\r\n"; sleep 1) | nc localhost 6379
+PONG
+PONG
+PONG
这一次我们没有为每个命令都花费了RTT开销,而是只用了一个命令的开销时间。
非常明确的,用管道顺序操作的第一个例子如下:
- Client: INCR X
- Client: INCR X
- Client: INCR X
- Client: INCR X
- Server: 1
- Server: 2
- Server: 3
- Server: 4
注意:使用管道发送命令时,服务器将被迫回复一个队列答复,占用很多内存。所以,如果你需要发送大量的命令,最好是把他们按照合理数量分批次的处理,例如10K的命令,读回复,然后再发送另一个10k的命令,等等。这样速度几乎是相同的,但是在回复这10k命令队列需要非常大量的内存用来组织返回数据内容。
经典应用场景——Redis 冷启动:Redis 服务进程起来的时候是空的,没有任何数据,我们一般期望服务进程起来的时候能够预加载一些准备好的热数据到缓存,使其能够尽快的、高效的提供缓存服务。一般热数据的量也不会太小,可能达数十G,此时使用管道来把数据加载到缓存,就能够提升效率。
示例:
cat data.txt | redis-cli --pipe
把文件 data.txt 内容预加载到 Redis 缓存
总结:管道其实就是做了一件事情——让通信的成本变低一点,仅此而已
二、发布订阅(Pub/Sub)
官网:http://redis.cn/topics/pubsub.html
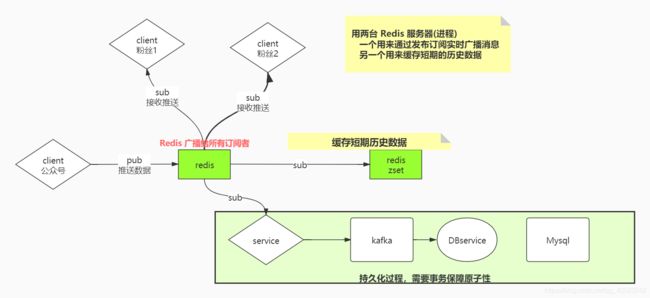
发布订阅概念:我们在观看英雄联盟直播的时候,右侧会有一个聊天室,当有人在刷飞机、刷火箭、聊天打屁的时候,所有人都能够看到,而且看到的内容都是一致的,如果要实现这样的一个聊天室功能,就能够使用 Redis 的发布订阅功能
我们在学习五种数据结构中的 list 的时候,知道基于 list 能够实现阻塞单播对列,而阻塞单播对列就是实现发布订阅模式的基础
基本示例:推送端推送数据 PUBLISH message hello,订阅方能够接收到推送的数据 SUBSCRIBE message
发布订阅模式对数据的处理是分为不同情况的,即实时数据和历史数据,而历史数据又分为短期历史和长期历史。比如QQ群消息或者订阅公众号,我们进入聊天群能够实时看到所有人的聊天内容,进入公众号能够看到最近的推文。但是我们也经常往上扒,拉取看一些历史数据,你有可能看最近三天的所有推送(聊天消息),也有可能看最近一周的所有推送,如果为了查询某个数据甚至有可能看一月之前的推送
Redis 是针对大量用户访问的基于内存的缓存,内存空间有限,不可能会把所有数据加载到 Redis,它有可能缓存最近一天的消息,也可以缓存三天或者一周的历史消息,是根据业务来进行设置的
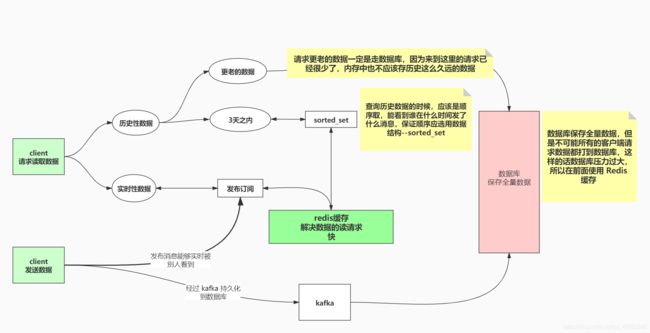
请求读取数据的客户端请求,根据数据的时效性,应该存储在不同的位置:
- 实时性数据:公众号发布文章,应该通过发布订阅模式,实时推送给所有接收者
- 历史性数据
- 短期历史数据:大概率会被频繁访问,应该保存在 Redis 缓存中,以便快速返回给用户,减少数据库压力。一般这些数据需要保持先后顺序,所以应该使用数据结构 sorted_set 来保存
- 长期历史数据:只有少量请求,应该保存在数据库,减少内存压力
发送数据的客户端请求
- 实时数据:QQ群中一个人发送数据,应该被其他人即时接收,使用发布订阅模式
- 历史数据:其他人向上翻应该很快的看到最近几天的发言记录,这些数据应该保存在 redis 缓存中,聊天记录应该保证顺序,所以使用 sorted_set 来存储
- 持久化到数据库:所有的数据都应该保存到数据库,可以通过 kafka 慢慢持久化到数据库
三、Redis 事务
官网:http://redis.cn/topics/transactions.html
当发布订阅模式中发布消息的时候会先缓存到 Redis,实时推送给所有订阅者。与此同时,消息记录也必须要保存到数据库,否则会出现你看到了公众号文章,三天之后你再看却发现没有这篇文章了。然而数据如果需要持久化到数据库,需要经过一系列操作,一旦其中出错(比如断电),需要保证数据一致性,最基本的方式就是事务
选用 Redis 的时候,永远记住一句话:Redis 速度快,所以你才会选用它。如果你把它速度快的特征给抹杀掉了,让它的速度不是那么快了,那么还不如不用 Redis
因为要保证 Redis 速度快这个特征,Redis 使用了事务,但是为了追求速度,并没有一个所谓的回滚的过程
关于事务的命令:
- MULTI:开启事务; MULTI 执行之后, 客户端可以继续向服务器发送任意多条命令, 这些命令不会立即被执行, 而是被放到一个队列中, 当 EXEC命令被调用时, 所有队列中的命令才会被执行
- EXEC:当 Redis 接收到 EXEC 指令的时候,才会将在 MULTI 之后的所有指令顺序执行;如果出现错误,将会回滚
- DISCARD:取消事务
- WATCH:通过乐观锁(optimistic lock)实现 CAS (check-and-set)操作。被 WATCH 的键会被监视,并会发觉这些键是否被改动过了。 如果有至少一个被监视的键在 EXEC 执行之前被修改了, 那么整个事务都会被取消, EXEC 返回nil-reply来表示事务已经失败。
下面以案例来理解 Redis 中的事务控制
常识:两个客户端请求的事务彼此透明,相互之间不会干扰彼此的事务执行
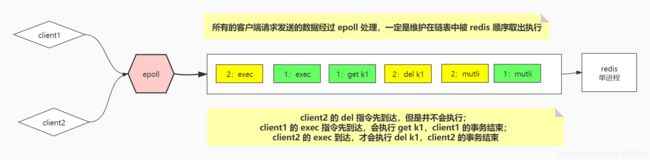
这种场景下的执行情况:正常执行
- client2 的 del 指令先到达,但是并不会执行;
- 由于client1 的 exec 指令先到达,会执行 get k1,能够得到 k1 数据,client1 的事务结束;
- client2 的 exec 到达,才会执行 del k1,client2 的事务结束
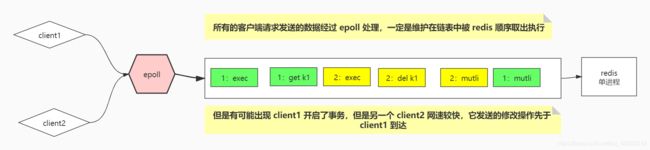
这种场景下的执行情况:Client1 异常结束
- 由于 client2 的 exec 指令先到达,会先执行 client2 的事务中的指令,将会删除 k1
- 此后 client1 的 exec 指令到达,执行 get k1 ,由于不存在 k1 ,就会报错
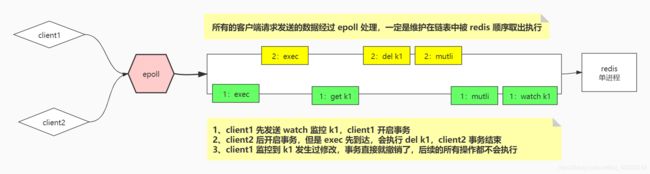
这种场景下的执行情况:Client2正常结束,Client1 撤销事务操作
- client1 先发送 watch 监控 k1,client1 开启事务
- client2 后开启事务,但是 exec 先到达,会执行 del k1,client2 事务结束
- client1 监控到 k1 发生过修改,事务直接就撤销了,后续的所有操作都不会执行
watch 监控到的 key 发生变化后,事务直接撤销,后续的操作都不会执行,Redis 就只能帮你到这种地步了。
key 发生变化会抛出异常,客户端需要捕获到这个异常,怎么处理是你开发人员的事情,要么重提,要么回滚,要么进行其他处理。总之客户端要修复这个问题造成的后果,而不是由 Redis 来帮你完成
为什么 Redis 不支持回滚(roll back)?
如果你有使用关系式数据库的经验, 那么 “Redis 在事务失败时不进行回滚,而是继续执行余下的命令”这种做法可能会让你觉得有点奇怪。
以下是这种做法的优点:
- Redis 命令只会因为错误的语法而失败(并且这些问题不能在入队时发现),或是命令用在了错误类型的键上面:这也就是说,从实用性的角度来说,失败的命令是由编程错误造成的,而这些错误应该在开发的过程中被发现,而不应该出现在生产环境中。
- 因为不需要对回滚进行支持,所以 Redis 的内部可以保持简单且快速。
有种观点认为 Redis 处理事务的做法会产生 bug , 然而需要注意的是, 在通常情况下, 回滚并不能解决编程错误带来的问题。 举个例子, 如果你本来想通过 INCR 命令将键的值加上 1 , 却不小心加上了 2 , 又或者对错误类型的键执行了 INCR , 回滚是没有办法处理这些情况的。
四、布隆过滤器
Redis 除了自己的功能之外,还可以通过向里面增加扩展库集成其他的外部模块功能。比如常用的布隆过滤器——解决缓存穿透
参考英文官方网站:https://redis.io/modules
首先需要知道什么是缓存穿透?发生缓存穿透会造成什么问题?
我们建立一个网站,比如当当图书,里面只出售书籍。这样的大型网站都会使用 Redis 缓存来提升系统性能,Redis 中会存储我们商城中的所有商品的关键信息,当用户进行查询我们有的东西,就应该直接走 Redis 缓存查询,就不用访问数据库,防止给数据库带来更多的压力
但是用户偏偏要在当当图书中查找毛巾、牙刷这些东西的时候,Redis 缓存中是没有的,此时如果不加以筛选和过滤,就会走数据库查询,数据库就需要白白的建立连接、处理搜索。这就叫做缓存穿透
当 Redis 中没有数据的时候,数据库中也必然没有这样的数据,这种的查询就是无效的查询,如果任由这样的查询大量的打到数据库(比如黑客用大量肉鸡恶意攻击),就会造成数据库压力过大。我们应该尽量避免这种无效查询打到数据库。实际的常用操作就是在 Redis 中集成布隆过滤器进行过滤
布隆过滤器是怎样解决缓存穿透的?
布隆过滤器是这样一个思路:首先你网站里有什么商品,把所有商品的名字都拿出来放在一个集合里,用户搜索的时候先拿商品名字和集合中元素比对,如果没找到就说明数据库中一定没有,就没必要走数据库了;如果找到了,就可以直接返回,或者再去数据库查询具体的详细信息
那么我们会条件反射的发现一个问题——那么多数据放在数据库中都需要分库分表,建立集群分而治之,这么大的数据量怎么可能加载到内存呢?布隆过滤器就是解决这个问题——如何用小的空间解决大量的数据匹配过程
我们在前面五种数据结构中学习了二进制位图(bitmap),如果每一个商品都能够用几个二进制位表示的话,整体的体积会变的很小。示意图如下:
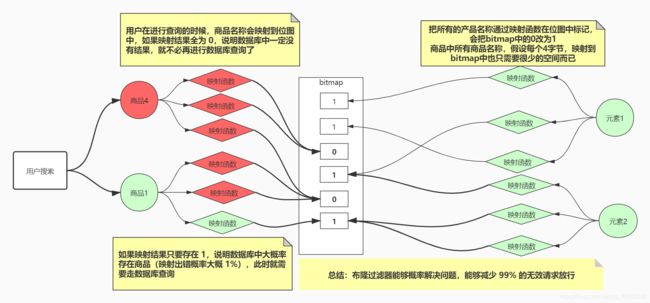
总结:
- 使用位图–bitmap,只需要很少的空间,即可代表所有的数据库商品字段,成本很低
- 大概率解决问题,并非百分百解决问题,缓存穿透概率降为不到 1%。核心思想就是拿空间换时间,减少时间复杂度
面试官问:如果使用布隆过滤器还是发生了低概率的缓存穿透,有没有什么优化方式?
- client端发送的请求穿透了redis,进行数据库查询但是没有查询到结果,可以增加 redis 中的key,value 标记为 null,下次进行同样的查询就会被过滤,不会打到数据库
- 数据库增加了元素,需要进行映射,在位图 bitmap 中标记为 1
- 如果增加商品,需要完成元素对 bloom 的添加(此时就出现了双写的问题——数据既要添加数据库,又需要添加布隆过滤器,怎么保证这两个操作的原子性?)
关联文章:
Redis入门–万字长文详解epoll
Redis——详解五种数据结构