Python爬虫:基于MySQL的个人ip代理池(ip pool)的搭建
Python爬虫:基于MySQL的个人ip代理池(ip pool)的搭建
使用到的部分技术:Python bs4,MySQL数据库
开发环境:PyCharm 2019.2.4
第一部分:从指定网址爬取相关ip
这里选定的是西拉代理,个人试过爬取其他代理网站的公开代理ip,要不就是质量不高,一千个ip中基本只有几个能用的,并且有的网站如http://www.goubanjia.com/公开代理ip的table标签还设定了反爬机制,要不就是连http/https或者是否高匿的类型都不给,效率太低。首先需要确保自己能获取网页上展示的代理ip(这里使用的是bs4模块的BeautifulSoup类)。
1、先确定网站的目标网页结构
进入http://www.xiladaili.com/gaoni/,可以看到每条代理ip的信息都是位于一个class名为fl-table的table表格内的:
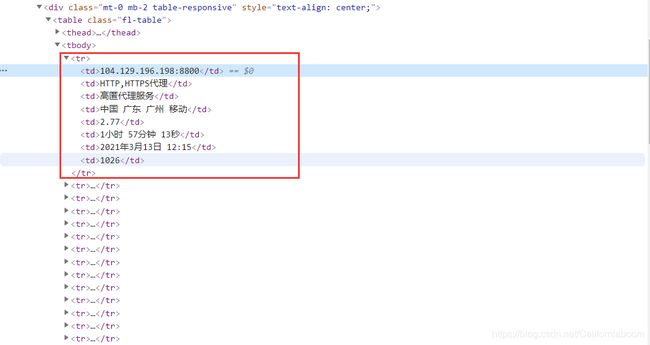
因此可以选取table中的所有tr标签进行遍历,这个fl-table中的每个tr标签就包含了一条代理ip的全部信息。
2、爬取到相应的代理ip
# @Author csu_cangkui
# @Time 2021/3/6 15:48
# @File getip_xila.py
import requests
from bs4 import BeautifulSoup
# utils.py的代码用于获取伪装UA以及判定代理ip是否符合要求
from getip_websget.utils import getheaders, isvalid_http, isvalid_https
# mysql_operate.py的代码属于Python与MySQL数据库交互的部分
from getip_websget.mysql_operate import insertmany_http_mysql, insertmany_https_mysql,\
delete_samehttps_mysql, delete_samehttp_mysql, random_http_mysql
# 这里选定的是西拉代理的高匿代理ip页面,由于数据是时刻更新的,因此每次只需爬取第一页就够了
url = 'http://www.xiladaili.com/gaoni/'
# UA伪装
header = getheaders()
# 这里可以使用自建的ip池随机选取ip-http对,如果只是少次爬取直接用现成的某个代理ip即可
# ip_http = random_http_mysql()
proxy = {
'http': '218.59.139.238:80'
}
ip_list_https = []
ip_list_http = []
if __name__ == '__main__':
# 使用代理ip:proxy和UA伪装:header发起request请求
response = requests.get(url=url, headers=header, proxies=proxy, timeout=5)
# 设定爬取的内容的编码格式一致,某些网页不设置的话结果容易出现乱码
response.encoding = response.apparent_encoding
page_text = response.text
# 及时关闭连接
response.close()
print('begin')
# 使用BeautifulSoup的lxml解析器载入爬取的内容
soup = BeautifulSoup(page_text, 'lxml')
# ip都是集中在一个table中所有tr中的,获取表格中的所有tr标签
tr_list = soup.select('.fl-table tbody tr')
for tr in tr_list:
td_list = tr.select('td')
# 这里ip_port获取的内容格式是xx.xx.xx.xx:xx,即ip和port端口混杂在一起
ip_port = td_list[0].text
ip_type = td_list[1].text
# 分割获取单独的ip和port端口
ip = ip_port.split(':', 1)[0]
port = ip_port.split(':', 1)[1]
# 类型中出现HTTPS的不论是否可以供给HTTP使用,一律视作HTTPS类型是代理ip处理
if 'HTTPS' in ip_type:
# 判定函数在另外的文件中
if isvalid_https(ip, port) is True:
print(ip + ' of https is valid')
# 制作成一个个的元组填进list
ip_list_https.append((ip, port))
else:
if isvalid_http(ip, port) is True:
print(ip + ' of http is valid')
ip_list_http.append((ip, port))
len_http = len(ip_list_http)
len_https = len(ip_list_https)
print(f'http total: {len_http}')
print('http has: ')
for ip_http in ip_list_http:
print(ip_http)
print(f'https total: {len_https}')
print('https has: ')
for ip_https in ip_list_https:
print(ip_https)
print('end')
通过上述代码,我们已经可以获取该代理网站高匿名代理第一页的可用的代理ip及其端口,并且可以将获取的内容分类存放进两个元组列表ip_list_http和ip_list_https。
第二部分:utils.py的编写
utils.py的主要作用分为三个函数:UA伪装函数getheaders()和ip判定函数isvalid_https(ip, port)与isvalid_http(ip, port)
# @Author csu_cangkui
# @Time 2021/3/4 21:54
# @File utils.py
import requests
import random
# 测试专用url
url_https = 'https://httpbin.org/ip'
url_http = 'http://httpbin.org/ip'
# 获取随机user_agent (header)
def getheaders():
user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
# 随机选取一个作为user-agent
useragent = random.choice(user_agent_list)
headers = {
'User-Agent': useragent}
return headers
# IP可用性测试
def isvalid_http(ip, port):
proxy = {
'http': ip + ':' + port
}
num = 1
# 进行多次测试防止偶然
while num <= 4:
if judge(proxy, url_http) is True:
return True
num = num + 1
return False
def isvalid_https(ip, port):
proxy = {
'https': ip + ':' + port
}
num = 1
while num <= 4:
if judge(proxy, url_https) is True:
return True
num = num + 1
return False
def judge(proxy, url):
header = getheaders()
try:
# 设定3秒内未完成响应为超时
response = requests.get(url=url, headers=header, proxies=proxy, timeout=3)
# 获取响应码
code = response.status_code
response.close()
# 响应码为200时为正常响应
if code == 200:
return True
else:
return False
except:
return False
值得注意的是,不同类型的ip应该分不同的url来测试,不同类型的网页请求对应不同类型的代理ip,如果不对应(比如拿http类型的代理ip去请求https类型的网页),结果将是ip伪装失效,即没有匿名,服务器接收到的就是你原本的ip,这一点是致命的。
第三部分:Python与MySQL数据库的交互操作
主要是编写mysql_operate.py文件。先使用Navicat建表ip_http、ip_https(当然代码中搭建也可以),表的结构如下:
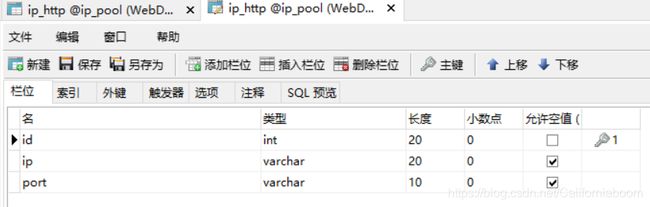
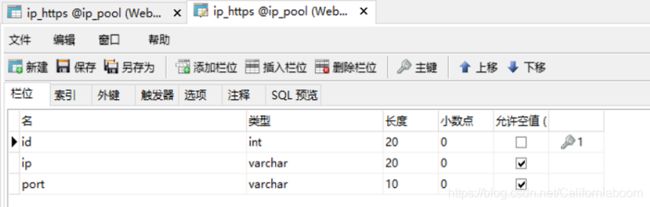
这里设置字段(主键)id的目的是为了能够删除重复的记录,之后的文件中会提到。
为了提高效率,减少数据库操作时间,设计每次查询将结果一次性插入MySQL的函数,即每挖出一条符合要求的代理ip,不当即进行数据库操作,而是保存进入列表,在程序末尾进行数据库操作,保证只打开一次数据库连接。
数据库相关函数如下(mysql_operate.py):
# @Author csu_cangkui
# @Time 2021/3/5 21:19
# @File mysql_operate.py
import pymysql
import random
from getip_websget.utils import isvalid_https, isvalid_http
# 根据ip删除指定数据库中的指定记录
def delete_http_mysql(ip):
if len(ip) != 0:
# 打开数据库连接,这里根据自己的MySQL用户、数据库名自行变更
conn = pymysql.connect(user='root', passwd='123456789', db='ip_pool')
# 获取游标cursor
cursor = conn.cursor()
sql = "DELETE FROM ip_http WHERE ip=%s"
delete = cursor.execute(sql, (ip,))
print(ip + ' of http delete successful')
# 关闭连接、游标并提交
cursor.close()
conn.commit()
conn.close()
if delete == 1:
return True
else:
return False
else:
return False
def delete_https_mysql(ip):
if len(ip) != 0:
# 打开数据库连接
conn = pymysql.connect(user='root', passwd='123456789', db='ip_pool')
# 获取游标cursor
cursor = conn.cursor()
sql = "DELETE FROM ip_https WHERE ip=%s"
delete = cursor.execute(sql, (ip,))
print(ip + ' of https delete successful')
# 关闭连接、游标并提交
cursor.close()
conn.commit()
conn.close()
if delete == 1:
return True
else:
return False
else:
return False
# 随机取出一条http代理ip
def random_http_mysql():
# 打开数据库连接
conn = pymysql.connect(user='root', passwd='123456789', db='ip_pool')
# 获取游标cursor
cursor = conn.cursor()
sql = "SELECT * FROM ip_http"
try:
# 执行SQL语句
cursor.execute(sql)
# 获取所有记录列表
results = cursor.fetchall()
# 关闭连接、游标并提交
cursor.close()
conn.commit()
conn.close()
# 随机返回一个id、ip、port组成的元组(一条完整的记录)
return random.choice(results)
except:
print("Error: unable to fecth data")
# 随机取出一条https代理ip
def random_https_mysql():
# 打开数据库连接
conn = pymysql.connect(user='root', passwd='123456789', db='ip_pool')
# 获取游标cursor
cursor = conn.cursor()
sql = "SELECT * FROM ip_https"
try:
# 执行SQL语句
cursor.execute(sql)
# 获取所有记录列表
results = cursor.fetchall()
# 关闭连接、游标并提交
cursor.close()
conn.commit()
conn.close()
return random.choice(results)
except:
print("Error: unable to fecth data")
# 根据传入的ip-port元组列表批量插入数据
def insertmany_http_mysql(ip_list):
# 打开数据库连接
conn = pymysql.connect(user='root', passwd='123456789', db='ip_pool')
# 获取游标cursor
cursor = conn.cursor()
sql = "INSERT into ip_http(ip, port) values(%s, %s)"
# 获取被影响的行数
insert = cursor.executemany(sql, ip_list)
# 关闭连接、游标并提交
cursor.close()
conn.commit()
conn.close()
if insert == len(ip_list):
return True
else:
return False
def insertmany_https_mysql(ip_list):
# 打开数据库连接
conn = pymysql.connect(user='root', passwd='123456789', db='ip_pool')
# 获取游标cursor
cursor = conn.cursor()
sql = "INSERT into ip_https(ip, port) values(%s, %s)"
insert = cursor.executemany(sql, ip_list)
# 关闭连接、游标并提交
cursor.close()
conn.commit()
conn.close()
if insert == len(ip_list):
return True
else:
return False
# 部分清洗函数
# 删除相同https代理ip
def delete_samehttps_mysql():
# 打开数据库连接
conn = pymysql.connect(user='root', passwd='123456789', db='ip_pool')
# 获取游标cursor
cursor = conn.cursor()
sql = "delete from ip_https where ip in (" \
" select pname from (" \
" select ip as pname from ip_https group by ip having count(ip) > 1)" \
" a)" \
" and id not in (" \
" select pid from (" \
" select min(id) as pid from ip_https group by ip having count(ip) > 1)" \
" b)"
cursor.execute(sql)
# 关闭连接、游标并提交
cursor.close()
conn.commit()
conn.close()
# 删除相同http代理ip
def delete_samehttp_mysql():
# 打开数据库连接
conn = pymysql.connect(user='root', passwd='123456789', db='ip_pool')
# 获取游标cursor
cursor = conn.cursor()
# 利用一个主键id来删除其他重复行并只留下一条记录
sql = "delete from ip_http where ip in (" \
" select pname from (" \
" select ip as pname from ip_http group by ip having count(ip) > 1)" \
" a)" \
" and id not in (" \
" select pid from (" \
" select min(id) as pid from ip_http group by ip having count(ip) > 1)" \
" b)"
cursor.execute(sql)
# 关闭连接、游标并提交
cursor.close()
conn.commit()
conn.close()
# 删除无用的http代理ip,慎用
def delete_abandonedhttp_mysql():
# 打开数据库连接
conn = pymysql.connect(user='root', passwd='123456789', db='ip_pool')
# 获取游标cursor
cursor = conn.cursor()
sql = "SELECT * FROM ip_http"
try:
# 执行SQL语句
cursor.execute(sql)
# 获取所有记录列表
results = cursor.fetchall()
# 关闭连接、游标并提交
cursor.close()
conn.commit()
conn.close()
for ip_port in results:
ip = ip_port[1]
port = ip_port[2]
if isvalid_http(ip, port) is False:
delete_http_mysql(ip)
except:
print("Error: unable to delete abandoned http data")
# 关闭连接、游标并提交
cursor.close()
conn.commit()
conn.close()
# 删除无用的http代理ip,慎用
def delete_abandonedhttps_mysql():
# 打开数据库连接
conn = pymysql.connect(user='root', passwd='123456789', db='ip_pool')
# 获取游标cursor
cursor = conn.cursor()
sql = "SELECT * FROM ip_https"
try:
# 执行SQL语句
cursor.execute(sql)
# 获取所有记录列表
results = cursor.fetchall()
# 关闭连接、游标并提交
cursor.close()
conn.commit()
conn.close()
for ip_port in results:
ip = ip_port[1]
port = ip_port[2]
if isvalid_https(ip, port) is False:
delete_https_mysql(ip)
except:
print("Error: unable to delete abandoned https data")
# 关闭连接、游标并提交
cursor.close()
conn.commit()
conn.close()
最后两个函数慎用的原因在于,部分ip需要多次测试才能通过,这部分ip质量不高,但是在ip量很少的时候一般不会进行丢弃处理,如果检测函数没设计好可能会损失相当一部分ip;另一方面如果希望获取的都是高质量ip的话可以提高检测门槛(比如减少响应超时时间timeout,或是减少检测次数等),那么使用这两个函数也是不需要担心的。
第四部分:回改ip爬取代码
上述第三部分完成之后,我们就可以把爬取的合格的代理ip及其端口进行持久化存储了,最后一部分的修改部分如下:
len_http = len(ip_list_http)
len_https = len(ip_list_https)
print(f'http total: {len_http}')
print(f'https total: {len_https}')
if len_http != 0:
insertmany_http_mysql(ip_list_http)
if len_https != 0:
insertmany_https_mysql(ip_list_https)
print('end')
# 删除失效的http、https类型的ip
delete_samehttps_mysql()
delete_samehttp_mysql()