面试官问我HashMap哪里不安全,我支支吾吾的说了这些..
文章目录
-
- 前言
- JDK7 HashMap
- JDK8 HashMap
- 最后
前言
HashMap在JDK7和JDK8是有了一些不同的,具体体现如下:
- JDK7HashMap底层是数组+链表,而JDK8是数组+链表+红黑树
- JDK7扩容采用头插法,而JDK8采用尾插法
- JDK7的rehash是全部rehash,而JDK8是部分rehash。
- JDK8对于key的hash值计算相比于JDK7来说有所优化。
如果还有兴趣的小伙伴可以学习学习我的以下文章,写的十分详细!!
高频考题:手写HashMap
JDK7、8扩容源码级详解
JDK7、8HashMap的get()、put()流程详解
JDK7 HashMap
JDK7HashMap在多线程环境下会出现死循环问题。
假如此时A、B线程同时对一个HashMap进行put操作,且HashMap刚号达到扩容条件需要进行扩容
那么这两个线程都会取对HahsMap进行扩容(JDK7HashMap扩容调用 resize()方法,而resize()方法中需要调用transfer()方法将旧数组元素全部rehash到新数组中去重点:这里在多线程环境下就会出现问题)
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
//对数组的每一条链表遍历rehash
for (Entry<K,V> e : table) {
while(null != e) {
//保留下一个节点
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
//得到对应在新数组中的索引位置
int i = indexFor(e.hash, newCapacity);
//尾插法
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
我们假设现在有一个链表 C——>D,且C、D扩容后计算的索引位置依然不变,那他么还在同一链表中
现在A线程进入到transfer方法拿到A和它的下一个节点B(Entry
B执行完之后,A线程继续去执行
因为A获取到了 e = C,next = D,所以C可以进行rehash,C进行完后拿到D,发现D.next = C,所以D也可以进行rehash,那么此时因为D——>C,此时会再拿到C,发现C.next = null,但C不是null,所以C再进行rehash,此时链表尾 C——> D ——>C,因为此时e = NULL,所以退出循环,此时出现死循环。C——>D——>C。
各位可以好好想想这些话或者自己在草稿纸上画一画再来看下面的图!
图示演示:
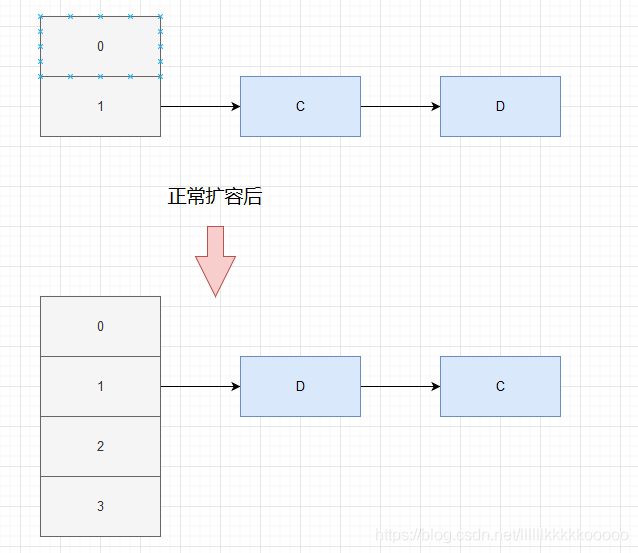
B正常执行完成
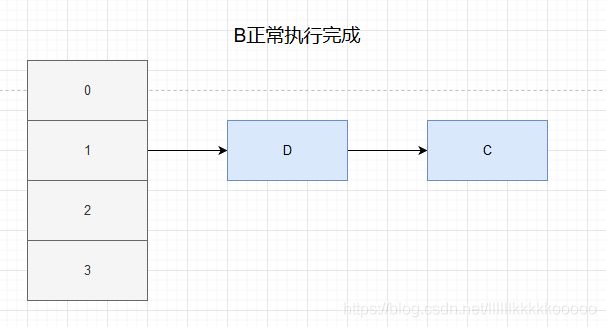
A继续执行
因为A获取到了 e = C,next = D,所以C可以进行rehash
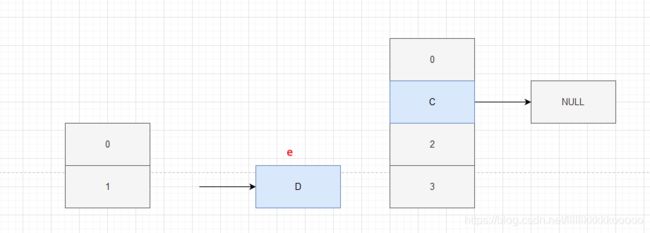
C进行完后拿到e = D,发现D.next = C,所以D也可以进行rehash
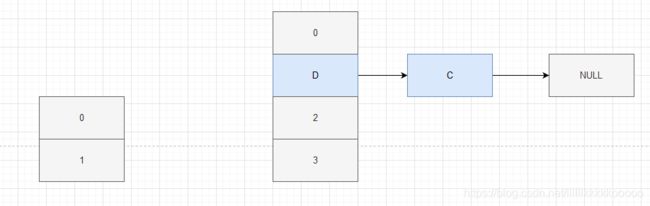
那么此时因为D——>C,此时会再拿到C,发现C.next = null,但C不是null,所以C再进行rehash
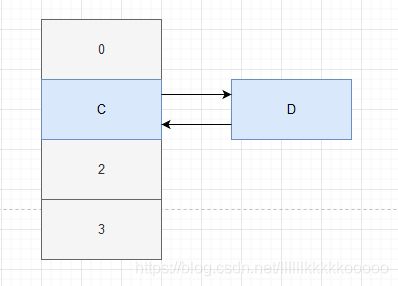
此时e = NULL,所以退出循环,此时出现死循环。C——>D——>C。
JDK8 HashMap
JDK1.8会出现数据覆盖的情况
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) {
// existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
-
第6行代码:假设两个线程A、B都在进行put操作,并且根据key计算出的hash值相同,那么得到得索引下标也相同,当线程A执行完第六行代码后由于时间片耗尽导致被挂起,而线程B得到时间片后在该下标处插入了元素,完成了正常的插入,然后线程A获得时间片,由于之前已经进行了hash碰撞的判断,所有此时不会再进行判断,而是直接进行插入,这就导致了线程B插入的数据被线程A覆盖了,从而线程不安全。
-
第38行代码++size不安全,还是线程A、B,这两个线程同时进行put操作时,假设当前HashMap的zise大小为10,当线程A执行到第38行代码时,从主内存中获得size的值为10后准备进行+1操作,但是由于时间片耗尽只好让出CPU,线程B快乐的拿到CPU还是从主内存中拿到size的值10进行+1操作,完成了put操作并将size=11写回主内存,然后线程A再次拿到CPU并继续执行(此时size的值仍为10),当执行完put操作后,还是将size=11写回内存,此时,线程A、B都执行了一次put操作,但是size的值只增加了1,所有说还是由于数据覆盖又导致了线程不安全。
最后
我是 Code皮皮虾,一个热爱分享知识的 皮皮虾爱好者,未来的日子里会不断更新出对大家有益的博文,期待大家的关注!!!
创作不易,如果这篇博文对各位有帮助,希望各位小伙伴可以一键三连哦!,感谢支持,我们下次再见~~~
分享大纲
大厂面试题专栏
Java从入门到入坟学习路线目录索引
开源爬虫实例教程目录索引
更多精彩内容分享,请点击 Hello World (●’◡’●)
