菜鸟同事贵我2k,原是背了涨薪秘籍?(赶紧收藏!)
文章目录
-
- 一 如何优化首次加载时的白屏时间?
-
- 1.1 尽量减少文件大小
- 1.2 减少关键资源个数
- 1.3 CDN 来减少每次 RTT 时长
- 二 怎样避免布局抖动?
- 三 虚拟DOM和实际的DOM有何不同?
- 四 从输入URL到页面展示,这中间发生了什么?
- 五 DOM 树是如何生成的?
- 六 DOM解析过程中style与script标签处理有何不同?CSS会阻塞页面吗?
无意间知道菜鸟同事工资比我高2k,百思不得其解,严刑拷打(推杯换盏)间,终于套出其秘诀,原来是面试前背了这些
面试官直呼高手,当即录用。
酸呐!
现呕心整理如下,花费巨资套来的情报在此,赶紧收藏!!!
一 如何优化首次加载时的白屏时间?

通常情况下的优化主要体现在下载 CSS 文件、下载 JavaScript 文件这些关键资源,和执行 JavaScript造成的阻塞问题。
1.1 尽量减少文件大小
尽量减少文件大小,比如通过 webpack 等工具移除一些不必要的注释,对 CSS 和 JavaScript 资源进行压缩等。
1.2 减少关键资源个数
将一些不需要在解析 HTML 阶段使用的 JavaScript 标记上 async 或者 defer,使得js与html并行下载。
大的 CSS 文件,可以通过媒体查询属性,将其拆分为多个不同用途的 CSS 文件,这样只有在特定的场景下才会加载特定的 CSS 文件。
1.3 CDN 来减少每次 RTT 时长
CDN是构建在现有网络基础之上的智能虚拟网络,依靠部署在各地的边缘服务器,通过中心平台的负载均衡、内容分发、调度等功能模块,使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。
RTT 就是FTP请求往返时延。它是网络中一个重要的性能指标,表示从发送端发送数据开始,到发送端收到来自接收端的确认,总共经历的时延。
二 怎样避免布局抖动?
在代码中反复进行dom操作会引发重排重绘,导致布局抖动,对此可以将所有的元素挂载到一个dom碎片上,集体挂载。
在vue等现代框架中一般已通过虚拟dom树解决了此问题。
此时面试官渐入佳境啊,一看你小子懂得挺多,赶紧追问。
三 虚拟DOM和实际的DOM有何不同?
这问题属于隐藏彩蛋啊,需要上个回答的铺垫,叭叭一张嘴,又多200块,煎饼果子有了吧。
虚拟 DOM,通过减少对真实DOM 树的修改,进而减少重排重绘。
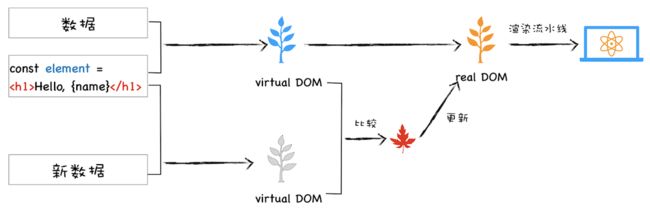
页面改变的内容先应用到虚拟 DOM 上,虚拟 DOM 收集到足够的改变时,再把这些变化一次性应用到真实的 DOM 上。
可以看到,虚拟DOM树类似一个缓存区。
当模型数据改变后,生成新的虚拟 DOM,与之前的虚拟 DOM 进行比较,找出变化的节点,将变化的虚拟节点应用到 DOM 上,触发 DOM 节点更新。
四 从输入URL到页面展示,这中间发生了什么?

- 浏览器进程接收到用户输入的 URL 请求后,将 URL 转发给网络进程。网络进程中发起真正的 URL 请求。
- 网络进程发出请求,TCP请求获得响应,收到了响应头数据,解析响应头数据,并将数据转发给浏览器进程。
- 浏览器进程收到响应头,发送“提交导航 (CommitNavigation)”消息到渲染进程。
- 渲染进程收到消息,开始做接收 HTML 数据的准备,接收数据的方式是直接和网络进程建立数据管道。
- 渲染进程会向浏览器进程返回消息,告诉浏览器进程:“已经准备好接受和解析页面数据了”。。
- 浏览器进程将网络进程接收到的 HTML 数据提交给渲染进程。
- 渲染进程渲染完成后返回消息到浏览器进程。
- 浏览器进程接收到消息之,便开始移除之前旧的文档,然后更新浏览器进程中的页面状态。
五 DOM 树是如何生成的?
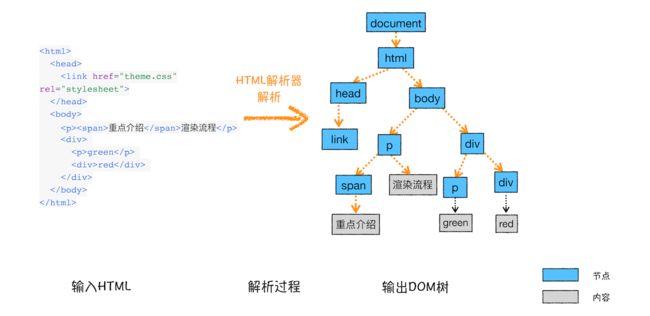
在渲染引擎内部,有一个叫 HTML 解析器(HTMLParser)的模块,它的职责就是负责将 HTML 字节流转换为 DOM 结构。
HTML 解析器维护了一个栈结构,该栈主要用来计算节点之间的父子关系,html节点会被按照顺序压到这个栈中。
在解析开始时会自动压入 document 的开始标签节点,在解析结束后压入 document 结束标签节点。
这个过程类似于括号匹配,通过找出栈中的匹配括号来输出一个完整节点。
arr = ['{','(',')','}']
如上。当匹配到’)‘时候找到一个子节点,‘()’是’{}'的子节点。
HTML 解析器并不是等整个文档加载完成之后再解析的,而是网络进程加载了多少数据,HTML 解析器便解析多少数据。
六 DOM解析过程中style与script标签处理有何不同?CSS会阻塞页面吗?
解析到