RAID在SQL Server中的应用(RAID几种级别)
企业级的数据库应用大多部署在RAID磁盘阵列的服务器上,这样能提高磁盘的访问性能,并能够实现容错/容灾。
RAID(冗余磁盘阵列),简单理解,就是拿一些廉价的硬盘来做成阵列。其目的无非是为了扩展存储容量,提升读写性能,实现数据冗余(备份容灾)。就像很早就有老外拿N台旧PC,做成一个强大的“服务器集群”。RAID技术诞生于1987年,由美国加州大学伯克利分校提出。
主流的大概可以分为几个级别:RAID 0,RAID 1,RAID 5,RAID 10 。配置起来也不是很复杂,有兴趣和条件的朋友可以找相关的资料,自己动手实践。
SQL Server 2005常用的有几个级别0,1,5,10 下面我来简单说说这个几个级别的区别及其应用。
RAID 0 简称磁盘条带化,它可以提供最好的读写性能,如果你把两块磁盘做成了RAID0,那么在写入数据的时候,就可以同时对A磁盘和B磁盘执行写入操作。这里我必须说明的是:“可以同时...写入操作”,并不是意味着将文件的相同内容“在同一时间内完全写入”A磁盘和B磁盘中。打个比方:有一个100M的文件需要写入磁盘中,假设单个磁盘的写入速度是10M/S,那么需要10秒钟才能完成写入工作。但如果在具有A、B两块磁盘的 RAID 0阵列环境中,(以秒/S为最小单位的)单时间内,可以将10M内容写入A磁盘中,并同时将紧随的10M内容写入B磁盘中,这样算起来,写入速度变成了 20M/S,只需要5秒钟就能搞定了,而且每块磁盘中只需存储50M的文件内容,不会造成硬盘存储压力。当然,上诉例子也许不恰当,也只是指的理论环境下,实际环境中会有很多其他因素,效率肯定不能达到。
毋庸置疑的是,这样肯定是能提高读写性能的,但是这样也带来了一个问题就是,如果其中的一部分数据丢失了,你的全部数据都不会找回来的,因为RAID0没有提供冗余恢复数据的策略。所以RAID0可以用在只读的数据库数据表,或者是经过复制过来的数据库上,如果你对数据丢失不敏感的话,也可以使用RAID 0,总之这个level下是高性能、无冗余。

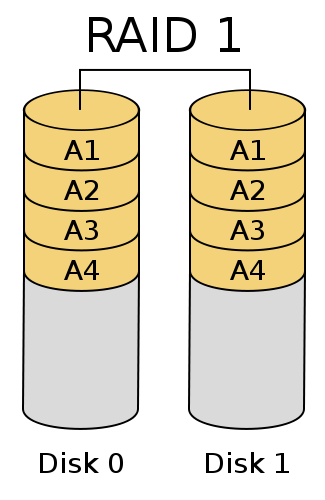
RAID 1 磁盘镜像 它对读没有什么影响,如果有两块磁盘它只对写有影响,因为它采用了一块磁盘做冗余备份的方法,这样如果你有两块50G的磁盘,那么加起来就是100G,但是在RAID 1下,那么你只能使用50G ,这种方法会影响磁盘的空间使用,降低了I/O 写的性能。通俗点来讲:你将一个100M的文件写入RAID 1时,讲内容写入A磁盘的同时,也会将相同的内容写入B磁盘中。 这样一来,两块磁盘的内容是完全一致的(这就传说中的”冗余“,并不是什么高深的东西)。本来只需要写入1块硬盘的,可是现在要写入到两块硬盘去,效率肯 定会变低。至于“读”操作,RAID 1环境下,读取时候只使用到了一块硬盘,所以和普通的环境下没啥区别(如果两块硬盘都能够同时工作,那么还可以分摊压力的)。只是当第一个硬盘数据损坏或 者挂掉了,就启动第二块硬盘。当然,两块硬盘都挂了,那就真的崩溃了。哈哈。值得一提的是,有些书或者文章上讲,RAID 1是在将第一块硬盘写入完成后,才将数据完整复制到第二块磁盘中做为镜像备份的这种说法有待考证,按我的理解,是同时复制写入的。
RAID 5 与RAID1 不同之处就是多了奇偶校验,所有的奇偶校验的信息会遍布各个磁盘,性能上要比RAID1高些,但是一旦发生磁盘I/O失败,就会造成性能急剧下降,同时这 种方法也在RAID0 与RAID1间折了中,是比较通用的做法。 用简单的语言来表示,至少使用3块硬盘(也可以更多)组建RAID5阵列,当有数据写入硬盘的时候,按照1块硬盘的方式就是直接写入这块硬盘的,如果是 RAID5的话这次数据写入会分根据算法分成3部分,然后写入这3块硬盘,写入的同时还会在这3块硬盘上写入校验信息,当读取写入的数据的时候会分别从3 块硬盘上读取数据内容,再通过检验信息进行校验。当其中有1块硬盘出现损坏的时候,就从另外2块硬盘上存储的数据可以计算出第3块硬盘的数据内容。也就是说RAID5这种存储方式只允许有一块硬盘出现故障,出现故障时需要尽快更换。当更换故障硬盘后,在故障期间写入的数据会进行重新校验。 如果在未解决故障又坏1块,那就是灾难性的了。

RAID 10 (也叫RAID 0+1 )就是RAID0 与 RAID1的组合,它提供了高性能,高可用性, 性能上要比RAID5好,特别适合大量写入的应用程序,但是就是成本比较高无论是多少块磁盘你都是将损失一半的磁盘存储。按照我的理解,至少需要4块硬盘 才能完成,A和B做数据分割,分别存储一半的数据,C和D分别对应做A和B的镜像备份。这样一来,可真是完美了,也是我理想中的最佳状态。也不需要 RAID 5的奇偶校验。很显然,这样子成本也会高一些。还有一点很遗憾的就是性能的”短板效应“,这个似乎不那么容易改善,除非有类似于”负载均衡”设备的控制器和合理的控制算法。

当然,这就和我们经常说的“负载均衡、 高可用集群,横向扩展,纵向扩展”的目的其实很类似。都是为了实现不间断的工作,保证数据安全性,而且还要分摊压力。