xgboost参数_Xgboost小结与调参
从0到1Python数据科学之旅(博主录制)
http://dwz.date/cqpw

1、Xgboost对GBDT的优化
算法层面
1.XGB增加了正则项,能够防止过拟合。正则项为树模型复杂度,通过叶子节点数量和叶节点的值定义树模型复杂度。

T为叶子节点的数量,这T个叶子节点的值,组成了T维向量ω。
2.XGB损失函数是误差部分是二阶泰勒展开,GBDT 是一阶泰勒展开。因此损失函数近似的更精准。
3. XGB对每颗子树增加一个参数,使得每颗子树的权重降低,防止过拟合,这个参数叫shrinkage,对特征进行降采样,灵感来源于随机森林,除了能降低计算量外,还能防止过拟合。
4.采用百分位数法,计算特征的最佳分裂点。在寻找最佳分割点时,考虑传统的枚举每个特征的所有可能分割点的贪心法效率太低,xgboost实现了一种近似的算法。大致的思想是根据百分位法列举几个可能成为分割点的候选者,然后从候选者中根据上面求分割点的公式计算找出最佳的分割点。
5.增加处理缺失值的方案(通过枚举所有缺失值在当前节点是进入左子树,还是进入右子树更优来决定一个处理缺失值默认的方向)。
6.交叉验证,early stop,当预测结果已经很好的时候可以提前停止建树,加快训练速度。
7.Shrinkage,你可以是几个回归树的叶子节点之和为预测值,也可以是加权,比如第一棵树预测值为3.3,label为4.0,第二棵树才学0.7,….再后面的树还学个鬼,所以给他打个折扣,比如3折,那么第二棵树训练的残差为4.0-3.3*0.3=3.01,这就可以发挥了啦,以此类推,作用是啥,防止过拟合,如果对于“伪残差”学习,那更像梯度下降里面的学习率;
8.支持并行化,这是XGB的闪光点,虽然树与树之间是串行关系,但是同层级节点可并行。具体的对于某个节点,节点内选择最佳分裂点,候选分裂点计算增益用多线程并行。训练速度快。
系统层面
1.对每个特征进行分块(block)并排序,使得在寻找最佳分裂点的时候能够并行化计算。这是xgboost比一般GBDT更快的一个重要原因。
2.通过设置合理的block的大小,充分利用了CPU缓存进行读取加速(cache-aware access)。使得数据读取的速度更快。因为太小的block的尺寸使得多线程中每个线程负载太小降低了并行效率。太大的block尺寸会导致CPU的缓存获取miss掉。
3.out-of-core 通过将block压缩(block compressoin)并存储到硬盘上,并且通过将block分区到多个硬盘上(block Sharding)实现了更大的IO 读写速度,因此,因为加入了硬盘存储block读写的部分不仅仅使得xgboost处理大数据量的能力有所提升,并且通过提高IO的吞吐量使得xgboost相比一般实利用这种技术实现大数据计算的框架更快。
2、Xgboost训练时长
(图片来自 机器之心)
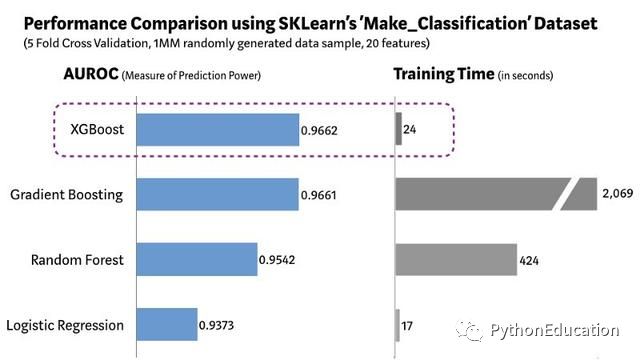
XGBoost全称是eXtreme Gradient Boosting,由陈天奇所设计,和传统的梯度提升算法相比,XGBoost进行了许多改进,它能够比其他使用梯度提升的集成算法更加快速。
本文主要介绍xgb算法的调参过程,xgb本质上是boosting方法,即通过在数据上逐一构建多个弱评估器,经过多次迭代逐渐累积多个弱评估器的方法。xgb中的每个分类器是cart树,因此树模型对变量交叉会有较好的效果,但因此也容易产生过拟合。调参的步骤网上有很多教程,参数搜索的过程可以用网格搜索和贝叶斯优化(有空研究)。下面采用波士顿房产数据集,对xgb中调参做简单的学习介绍。
首先,建模并查看各类参数。
'''python金融风控评分卡模型和数据分析微专业课(博主录制视频):http://dwz.date/b9vv'''from xgboost import XGBRegressor as XGBRfrom sklearn.ensemble import RandomForestRegressor as RFRfrom sklearn.linear_model import LinearRegression as LinearRfrom sklearn.datasets import load_bostonfrom sklearn.model_selection import KFold, cross_val_score as CVS, train_test_split as TTSfrom sklearn.metrics import mean_squared_error as MSEimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom time import timeimport datetimedata = load_boston()X = data.datay = data.targetXtrain,Xtest,Ytrain,Ytest = TTS(X,y,test_size=0.3,random_state=420)#写明参数param = {
'silent':True #默认为False,通常要手动把它关闭掉 ,'objective':'reg:linear' ,"eta":0.1}num_round = 180 #n_estimators#类train,可以直接导入的参数是训练数据,树的数量,其他参数都需要通过params来导入bst = xgb.train(param, dtrain, num_round)#接口predictxgb建模可以使用xgboost库,或者是使用sklearnAPI调用。实际情况中xgboost库本身训练模型效果会更优秀,且本身调参也方便许多。Xgboost自身有xgboost.cv()方法调参,如果是skleanAPI的话有GridSearchCV()方法进行调参。下面就用xgboost库建模,用xgboost.cv()的方法进行调参。
首先从设定默认参数开始,观察默认参数下交叉验证曲线的形状。
dfull = xgb.DMatrix(X,y)param1 = {'silent':True ,'obj':'reg:linear' ,"subsample":1 ,"max_depth":6 ,"eta":0.3 ,"gamma":0 ,"lambda":1 ,"alpha":0 ,"colsample_bytree":1 ,"colsample_bylevel":1 ,"colsample_bynode":1 ,"nfold":5}num_round = 200cvresult1 = xgb.cv(param1, dfull, num_round)fig,ax = plt.subplots(1,figsize=(15,8))ax.set_ylim(top=5)ax.grid()ax.plot(range(1,201),cvresult1.iloc[:,0],c="red",label="train,original")ax.plot(range(1,201),cvresult1.iloc[:,2],c="orange",label="test,original")ax.legend(fontsize="xx-large")plt.show()外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FgBINfyj-1598229157502)(https://imgkr2.cn-bj.ufileos.com/bd1f050b-54dd-4ae4-b16c-34d52612d26e.png?UCloudPublicKey=TOKEN_8d8b72be-579a-4e83-bfd0-5f6ce1546f13&Signature=6NaIiGfVLWbLu%252BiFTwTX0k2ti58%253D&Expires=1598275140)]
从曲线上可以看出模型处于过拟合状态,需要进行剪枝。剪枝的目的是训练集和测试集的结果尽量接近,即上图中训练集的曲线上升,测试集的曲线下降。
下面用三组曲线展示调参结果,一组是原始数据的结果,一组是上一个参数调节结束的结果,还有一组是现在在调节参数的结果。
param1 = {
'silent':True ,'obj':'reg:linear' ,"subsample":1 ,"max_depth":6 ,"eta":0.3 ,"gamma":0 ,"lambda":1 ,"alpha":0 ,"colsample_bytree":1 ,"colsample_bylevel":1 ,"colsample_bynode":1 ,"nfold":5}num_round = 200cvresult1 = xgb.cv(param1, dfull, num_round)fig,ax = plt.subplots(1,figsize=(15,8))ax.set_ylim(top=5)ax.grid()ax.plot(range(1,201),cvresult1.iloc[:,0],c="red",label="train,original")ax.plot(range(1,201),cvresult1.iloc[:,2],c="orange",label="test,original")param2 = {
'silent':True ,'obj':'reg:linear' ,"max_depth":2 ,"eta":0.05 ,"gamma":0 ,"lambda":1 ,"alpha":0 ,"colsample_bytree":1 ,"colsample_bylevel":0.4 ,"colsample_bynode":1 ,"nfold":5}param3 = {
'silent':True ,'obj':'reg:linear' ,"subsample":1 ,"eta":0.05 ,"gamma":20 ,"lambda":3.5 ,"alpha":0.2 ,"max_depth":4 ,"colsample_bytree":0.4 ,"colsample_bylevel":0.6 ,"colsample_bynode":1 ,"nfold":5}cvresult2 = xgb.cv(param2, dfull, num_round)cvresult3 = xgb.cv(param3, dfull, num_round)ax.plot(range(1,201),cvresult2.iloc[:,0],c="green",label="train,last")ax.plot(range(1,201),cvresult2.iloc[:,2],c="blue",label="test,last")ax.plot(range(1,201),cvresult3.iloc[:,0],c="gray",label="train,this")ax.plot(range(1,201),cvresult3.iloc[:,2],c="pink",label="test,this")ax.legend(fontsize="xx-large")plt.show()[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3kzqOeBb-1598229157506)(https://imgkr2.cn-bj.ufileos.com/e8777aae-82d2-4862-8684-347ce59e2bec.png?UCloudPublicKey=TOKEN_8d8b72be-579a-4e83-bfd0-5f6ce1546f13&Signature=3OIgIAOk26JtFx%252BRX6h0NtRxp6M%253D&Expires=1598275152)]
这里用到的是手动调参的方法,需要一定的调参经验结合损失函数的变化。网格搜索需要足够的计算机资源,且往往运行速度很慢,建议先用xgboost.cv()来确认参数的范围,而且调参过程中用np.linespace()还是np.arange()也会影响调参结果。
调参顺序也会会影响调参结果。所以一般会优先调对模型影响较大的参数。一般先n_estimators和eta共同调节,然后gamma和max_depth,再是采样和抽样参数,最后是正则化的两个参数。
调参常用参数介绍
附上之前学习xgboost时的笔记,记录了各个参数的含义及调参步骤。
1.n_estimators
n_estimators是集成中弱估计器的数量,即树的个数。使用参数学习曲线观察n_estimators对模型的影响。
axisx = range(10,1010,50)rs = []for i in axisx: reg = XGBR(n_estimators=i,random_state=420) rs.append(CVS(reg,Xtrain,Ytrain,cv=cv).mean())print(axisx[rs.index(max(rs))],max(rs))plt.figure(figsize=(20,5))plt.plot(axisx,rs,c="red",label="XGB")plt.legend()plt.show()
从上图看出n_estimators在80附近的时候准确率已达到最高,这里无需选择准确率达到最高的n_estiamtors。
在机器学习中,我们用来衡量模型在未知数据上的准确率的指标,叫做泛化误差。泛化误差由方差、偏差和噪声共同决定。其中,偏差是指模型的拟合程度,方差是指模型的稳定性,噪音则是随机因素。在绘制学习曲线时,不仅要考虑偏差的大小,还要考虑方差的大小。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-idEjxluH-1598229157521)(https://imgkr2.cn-bj.ufileos.com/047b4e8c-336b-4f42-a238-ee0eac212ac0.png?UCloudPublicKey=TOKEN_8d8b72be-579a-4e83-bfd0-5f6ce1546f13&Signature=6Sz4B%252Fnlg8xNBZi9beT77BTDA74%253D&Expires=1598275197)]
基于这种思路,来改进学习曲线:
axisx = range(50,1050,50)rs = []var = []ge = []for i in axisx: reg = XGBR(n_estimators=i,random_state=420) cvresult = CVS(reg,Xtrain,Ytrain,cv=cv) #记录1-偏差 rs.append(cvresult.mean()) #记录方差 var.append(cvresult.var()) #计算泛化误差的可控部分 ge.append((1 - cvresult.mean())**2+cvresult.var())#打印R2最高所对应的参数取值,并打印这个参数下的方差print(axisx[rs.index(max(rs))],max(rs),var[rs.index(max(rs))])#打印方差最低时对应的参数取值,并打印这个参数下的R2print(axisx[var.index(min(var))],rs[var.index(min(var))],min(var))#打印泛化误差可控部分的参数取值,并打印这个参数下的R2,方差以及泛化误差的可控部分print(axisx[ge.index(min(ge))],rs[ge.index(min(ge))],var[ge.index(min(ge))],min(ge))plt.figure(figsize=(20,5))plt.plot(axisx,rs,c="red",label="XGB")plt.legend()plt.show()由上图可知,泛化误差可控制的部分在n_estimators取150的时候最小。将模型的方差、偏差、泛化误差中可控部分绘制在一张图上:
axisx = range(100,300,10)rs = []var = []ge = []for i in axisx: reg = XGBR(n_estimators=i,random_state=420) cvresult = CVS(reg,Xtrain,Ytrain,cv=cv) rs.append(cvresult.mean()) var.append(cvresult.var()) ge.append((1 - cvresult.mean())**2+cvresult.var())print(axisx[rs.index(max(rs))],max(rs),var[rs.index(max(rs))])print(axisx[var.index(min(var))],rs[var.index(min(var))],min(var))print(axisx[ge.index(min(ge))],rs[ge.index(min(ge))],var[ge.index(min(ge))],min(ge))rs = np.array(rs)var = np.array(var)*0.01plt.figure(figsize=(20,5))plt.plot(axisx,rs,c="black",label="XGB")#添加方差线plt.plot(axisx,rs+var,c="red",linestyle='-.')plt.plot(axisx,rs-var,c="red",linestyle='-.')plt.legend()plt.show()可以看到n_estimators在180时的时候模型效果最优,n_estimators是xgb中一般调整的第一个参数,300以下为佳。其它单个参数的调节方法可以以此类推。
2.subsample
确认了树的数目之后,对每一颗树如果都使用全量数据进行训练的话,会导致计算非常缓慢。因此需要对训练数据集进行抽样。有放回的抽样每次只能抽取一个样本,若我们需要总共N个样本,就需要抽取N次。每次抽取一个样本的过程是独立的。实际应用中,每次抽取50%左右的数据就能够有不错的效果。
在梯度提升树中,每一次迭代都要建立一棵新的树,因此每次迭代中,都要有放回抽取一个新的训练样本。为了保证每次建新树后,集成的效果都比之前要好。因此在梯度提升树中,每构建一个评估器,都让模型更加集中于数据集中容易被判错的那些样本。
3.eta
迭代决策树时的步长,又叫学习率。eta越大,迭代的速度越快,算法的极限很快被达到,有可能无法收敛到真正的最佳。越小,越有可能找到更精确的最佳值,更多的空间被留给了后面建立的树,但迭代速度会比较缓慢。
eta默认值为0.1,而且更小的步长更利于现在的数据,但由于无
法确定对于其他数据会有怎么样的效果,所以通常对eta不做调整 ,即便调整,一般只会在[0.01,0.2]之间变动。
4.Gamma
gamma是用来防止过拟合的重要参数,是梯度提升树影响最大的参数之一,同时也是停止树生长的重要参数之一。
gamma是每增加一片叶子就会被减去的惩罚项,增加的叶子越多,结构分数之差Gain就会惩罚越重,因此gamma又被称作复杂性控制。只要Gain大于0,即只要目标函数还能够继续减小,树就可以进行继续分枝。所以gamma可以定义为在树的节点上进行进一步分支所需要的最小目标函数减少量。
param1 = {
'silent':True,'obj':'reg:linear',"gamma":0}param2 = {
'silent':True,'obj':'reg:linear',"gamma":20}num_round = 180n_fold=5cvresult1 = xgb.cv(param1, dfull, num_round,n_fold)cvresult2 = xgb.cv(param2, dfull, num_round,n_fold)plt.figure(figsize=(20,5))plt.grid()plt.plot(range(1,181),cvresult1.iloc[:,0],c="red",label="train,gamma=0")plt.plot(range(1,181),cvresult1.iloc[:,2],c="orange",label="test,gamma=0")plt.plot(range(1,181),cvresult2.iloc[:,0],c="green",label="train,gamma=20")plt.plot(range(1,181),cvresult2.iloc[:,2],c="blue",label="test,gamma=20")plt.legend()plt.show()这里的评价函数用的是RMASE,当gamma越小算法越复杂,相应的RMSE就会越低。在上图中表现就是gamma为0的曲线(红色)要低于gamma为20的曲线。在树增加到10棵之后,评价函数就不再有明显的下降趋势了。
作为天生过拟合的模型,XGBoost应用的核心之一就是减轻过拟合带来的影响。作为树模型,减轻过拟合的方式主要是靠对决策树剪枝来降低模型的复杂度,以求降低方差。用来防止过拟合的参数,有复杂度控制gamma ,正则化的两个参数lambda和alpha,控制迭代速度的参数eta以及随机有放回抽样的参数subsample。所有的这些参数都可以用来减轻过拟合。除此之外,还有几个影响重大的,专用于剪枝的参数:
1.这些参数中,树的最大深度是决策树中的剪枝法宝,算是最常用的剪枝参数,不过在XGBoost中,最大深度的功能与参数gamma相似,因此如果先调节了gamma,则最大深度可能无法展示出巨大的效果。通常来说,这两个参数中只使用一个。
2.三个随机抽样特征的参数中,前两个比较常用。在建立树时对特征进行抽样其实是决策树和随机森林中比较常见的一种方法,但是在XGBoost之前,这种方法并没有被使用到boosting算法当中过。Boosting算法一直以抽取样本(横向抽样)来调整模型过拟合的程度,而实践证明其实纵向抽样(抽取特征)更能够防止过拟合。
3.参数min_child_weight不太常用,它是一篇叶子上的二阶导数 之和,当样本所对应的二阶导数很小时,比如说为
0.01,min_child_weight若设定为1,则说明一片叶子上至少需要100个样本。本质上来说,这个参数其实是在控制叶子上所需的最小样本量,因此对于样本量很大的数据会比较有效。如果样本量很小则这个参数效用不大。
python金融风控评分卡模型和数据分析微专业课(博主亲自录制视频):http://dwz.date/b9vv
