【源码系列】Java中的数据结构——数组与ArrayList
文章目录
- 前言
- 关于本系列
- 一、指令与二进制数据
- 二、最常用的数据结构——数组
-
- 1.理解数组原理
- 2.数组的优缺点
-
- 优点
-
- 1.支持随机访问
- 2.同类型存储,避免烦人的命名
- 缺点(局限)
-
- 1.数组大小无法改变
- 2.增加删除数组元素操作比较繁琐
- 三、Java中的封装类ArrayList
-
- 源码阅读
-
- 1.源码阅读的方式
- 2.ArrayList源码之旅
-
- 2.1 “迷宫地图”
- 2.2 属性字段
- 2.3 常用方法
-
- 2.3.1 ArrayList构造函数
- 2.3.2 add方法
-
- ①boolean add(E e)
- ②add(int index, E element)
- 2.3.3 remove方法
-
- ①E remove(int index)
- ②boolean remove(Object o)
- 2.3.4 get方法
- 2.3.5 set方法
- 2.3.6 size方法
- 2.3.7 indexOf方法
- 2.3.8 toArray方法
- 2.3.9 removeAll和retainAll方法
-
- ①removeAll(Collection c)
- ②retainAll(Collection c)
- 2.4 迭代器
-
- 2.4.1 普通迭代器Itr
- 2.4.2 迭代器的增强版ListItr
- 2.4.3 干扰检测
-
- ①为什么要有干扰检测
- ②干扰检测原理
- 2.4.4 ArrayListSpliterator拆分迭代器
- 2.4.5 迭代器总结
- 四、总结
前言
自从上次字节面试凉了之后,我就一直有这个想法,想写个源码系列的博客。无奈最近事情太多,无法真正静下心来写。原本是想暑假来好好写这个系列,但因为下周要由我来负责协会授课,所以只能在这周写完。也好,毕竟只有ddl才有效率嘛(笑哭)。
关于本系列
作为本系列的第一篇文章,我想讲讲我的对于此系列的想法。
首先作为源码系列的文章,我肯定会讲讲源码,当然我也只能是作为一个菜鸟的身份,带着大家一起阅读源码,顺便说说我自己的理解。
当然了,我也不想仅限于源码,我更希望达到一种效果——让概念与实践融合。
所以在讲源码之前,我会把这个数据结构的概念通讲一遍,在这个过程中我也会尽量抛出一些问题,来帮助大家思考理解。
当然,本人技术水平有限,大佬勿喷。
注:本系列的jdk版本为1.8
一、指令与二进制数据
在正式介绍今天的数据结构之前,我想让大家切换一下视角,来到硬件底层来看看我们的程序。
相信大家也都听过,数据结构和算法课上老师一定会说的一句话——“程序就是算法和数据结构”,当然我也相信听了这话的你一定是云里雾里的,感觉很高深,很对,但又说不来怎么个对法。
其实从硬件层面上来看就不难理解了。
在硬件层面,算法对应的就是cpu的一条条指令,数据结构便是对应内存中二进制数字(的存储方式),而计算机最核心的操作不就是拿着二进制数据去执行一条条指令吗?
那么问题来了,我们该如何去拿到内存中的数据呢?
这么多的数据我们又该如何确定数据存储的位置呢?
我们自然而然想到需要有个类似地址的东西来描述内存中数据的位置,这样数据才能被准确访问。
而这个位置便叫做物理地址。
由此引出指针这个概念,指针存储的就是数据的地址,当然这个地址和上面说的物理地址还是有些不同的,指针存储的一般是虚拟地址。
不过呢,现在你只需要知道两件事——
1.数据是通过地址来进行访问的
2.指针存储的就是数据的地址,计算机可以通过指针的地址访问该地址的数据
为什么要讲上面这些内容呢,这是为了让你更好的理解下面的内容。
二、最常用的数据结构——数组
1.理解数组原理
首先,我们来看看数组的声明与创建:
int[] nums=new int[5];
这是一条最简单的用Java写的数组声明与创建。
它主要干了两件事:
1. 声明了一个int类型的一维数组
2. 给这个数组分配了五个int长度的存储空间
那如果我想访问数组中第3个元素怎么办呢?
你只需要写上
nums[2]
即可访问。
那我们来仔细思考一个问题——为什么它就能访问到该数组的第三个元素呢?
换句话说,我们为什么只写nums[2]就能确定第二个元素的确切地址呢?
其实啊,nums数组本身便是一个指针(PS:Java中没有指针这个概念,但实际上除了基本类型外,处处都是指针,具体可以看这篇Java中有没有指针。当然官方叫做句柄,但是我觉得指针更为贴切一点),它指向数组0号元素的地址,而我们之前又声明了数组的类型,再加上数组下标,我们不难算出第三个元素地址为
nums地址+int字节数*2。
专业描述就是:
a[i]_address = base_address + i * data_type_size

(图片来源于极客时间数据结构与算法之美)
而我们常说的——数组支持随机访问,根据下标随机访问的时间复杂度为 O(1),相信大家也就不难理解了吧。
有了数组,我们可以方便的存储同种类型元素,而不用为每个元素进行烦人的命名。
但数组有没有什么不方便的地方呢?
2.数组的优缺点
优点
1.支持随机访问
由于数组顺序存储,所以知道下标即可算出地址,这样根据下标访问数据的时间复杂度就为O(1)
2.同类型存储,避免烦人的命名
当然这个也是所有集合通用的优点
缺点(局限)
1.数组大小无法改变
由于数组元素在内存中的存储方式是连续存储,而大小在一开始便已经确定(这个也很好理解,不确定你怎么知道它之后的空间能不能分配给其他人),所以数组无法扩容。
而很多时候我们无法一开始就确定准确的数组大小,所以这对于某些情况就不太友好。
2.增加删除数组元素操作比较繁琐
除了在数组最后增加删除元素,其他时候增删数组元素都会牵扯到数组元素的移动,因为数组是顺序存储的,当中间的元素增加或删除时,后面的元素需要后移或前移。
总的来说,顺序存储的方式让数组支持随机访问,但也因此造成一些其他的局限。
三、Java中的封装类ArrayList
在理解完数组的原理和特点后,我们再来看看今天的主角——ArrayList。
它是Java对数组这个数据结构的封装,它封装了一些数组常用的操作,让操作更加简便,同时让数组看起来可以自动扩容。
好了,接下来开始我们的源码之旅。
源码阅读
1.源码阅读的方式
当然,在开始源码之前,我想啰嗦几句我关于源码研读的看法。
源码,在我看来就像一个巨大的迷宫,这对于体型庞大的jdk库更是如此。任何一个类都会牵扯到很多父类和接口,类中、类间方法的调用随处可见。如果你从头到尾阅读,那么你很容易迷失在这巨大的迷宫中。
读懂源码,走出迷宫的最好方式便是有一张地图(这个后面会讲)。然后根据地图,我们选择从我们熟悉的方法入手,慢慢研读,遇到不会的可以看看注释。如果还是不懂可以先跳过。很多时候我们首先要做的不是抓住每一个细节,而是看懂这个方法,看懂这个类大概是做什么的,做到心中有数,而很多时候方法的意思也能从方法名称中看出一二。
等你大致阅读了一遍明白了大概的框架后,再着眼细处也不迟。
所以接下来的源码之旅我也会据此展开。
2.ArrayList源码之旅
2.1 “迷宫地图”
ArrayList位于jdk的util包中,所以我们先打开ArrayList的源码。
打开idea,随便输个ArrayList,然后ctrl+点击,这样就进入了ArrayList的源码处,鼠标放置util处,右键选择图,选择第一个
这样我们就生成了第一张地图——继承关系图
是不是有点头晕,别急,这里你只需要大概记住继承关系即可。
然后返回ArrayList源码处,点击左侧的结构
这样我们就有了第二张地图,它也是我们本次的向导,将带领我们此次的源码之旅。
2.2 属性字段
首先我们要看的是属性字段
//版本号,这个可以忽略
private static final long serialVersionUID = 8683452581122892189L;
//默认容量,这里为10,后面会提到
private static final int DEFAULT_CAPACITY = 10;
//一个空的对象数组
private static final Object[] EMPTY_ELEMENTDATA = {
};
//另一个空的对象数组,为什么有两个呢?主要是为了区分后面的用法
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {
};
//真正存储数据的数据,整个ArrayList就是围绕它展开的,transient表示该属性无法被序列化
transient Object[] elementData;
//当前的元素数量
private int size;
有人可能会觉得这会占很多空间,其实不是的,前面几个属性都是static final,即静态常量,它们并不会占用对象的内存空间,当你创建ArrayList时,真正占空间的是elementData数组和size属性。
2.3 常用方法
这里我们主要探究List接口的方法
2.3.1 ArrayList构造函数
/**
* 构造一个初始容量为10的空列表。
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
/**
* 构造一个具有指定初始容量的空列表。
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
/**
* 构造一个列表,该列表包含指定集合的元素,其顺序由集合的迭代器返回。
*/
public ArrayList(Collection<? extends E> c) {
Object[] a = c.toArray();
if ((size = a.length) != 0) {
if (c.getClass() == java.util.ArrayList.class) {
elementData = a;
} else {
elementData = Arrays.copyOf(a, size, Object[].class);
}
} else {
// replace with empty array.
elementData = EMPTY_ELEMENTDATA;
}
}
这里我们看到ArrayList有三种构造方法:
-
ArrayList():创建一个默认ArrayList对象。
这里有个很有意思的地方——它一开始并没有创建一个对象数组,而是把默认的空对象数组的指针赋给了它,至于注释里为什么说它是一个初始容量为10的地址呢,这个奥妙在于之后要讲的add方法。现在你只需要知道这里运用懒加载的技巧,所谓初始化并非给这个elementData 数组创建一个默认大小的对象数组,而是把一个空的对象数组指针赋给了它。尽管它这里是个空数组,但实际上你可以把它认为一个默认容量为10的对象数组。 -
ArrayList(int initialCapacity):这里创建一个大小为initialCapacity的ArrayList对象,这里有个细节的地方,当initialCapacity为0时,它是把之前那个空对象数组的指针赋给了它。
-
public ArrayList(Collection c):传入其他集合对象,调用toArray方法返回对象数组初始化一个ArrayList,其顺序由集合的迭代器决定。
2.3.2 add方法
这里有两个add方法,我们逐一来介绍。
①boolean add(E e)
第一个add是我最常用的往队尾添加一个元素,返回值表示添加是否成功、
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
添加一个元素到数组队尾,那么ensureCapacityInternal(size + 1)这句话干了什么呢?
点开方法可以看到
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
calculateCapacity方法作用是计算当前需要的容量大小
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
从上面可以看到,它会判断当前的elementData 数组是不是DEFAULTCAPACITY_EMPTY_ELEMENTDATA,还记得之前说过ArrayList在执行空构造函数时的操作吗?就是让elementData 对象数组指向了DEFAULTCAPACITY_EMPTY_ELEMENTDATA,这时候执行add方法,他就会进入这个if语句中,返回DEFAULT_CAPACITY(默认容量10)和minCapacity(当前数组所需的最小容量)的最大值。
这就是当时为什么说执行无参构造函数时,虽然只是让elementData 指向一个空对象数组,但实际上可以认为它就是默认容量为10的数组的原因。
回到ensureCapacityInternal(int minCapacity)这个方法上来,在计算完所需容量后它会把这个返回值当做参数传入ensureExplicitCapacity(int minCapacity)方法中。
private void ensureExplicitCapacity(int minCapacity) {
//这个暂时不用管它,它是为了防止并发修改时出现错误
modCount++;
// 判断当前所需的容量是否大于elementData数组的长度,即判断是否需要扩容
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
当minCapacity 大于数组的长度时,说明此时的数组已经装不下现在的元素了,这时候就需要扩容,调用grow(int minCapacity)方法。
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
//正常情况是原来的3/2倍。注:这里用>>会比用/快
int newCapacity = oldCapacity + (oldCapacity >> 1);
//当计算好的新容量小于当前所需容量时,直接变成最小所需容量
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//当新容量大于数组最大长度(Integer.MAX_VALUE - 8)时,执行hugeCapacity方法
if (newCapacity - MAX_ARRAY_SIZE > 0)
//这里会对边界情况作出处理,返回数组的边界大小
newCapacity = hugeCapacity(minCapacity);
// 调用Arrays.copyOf(最后会调用一个System.arraycopy方法)来进行数组复制,新数组大小为newCapacity,这样便实现了数组扩容
elementData = Arrays.copyOf(elementData, newCapacity);
}
这个方法就是扩容当前elementData ,它会把之前的elementData 复制并传入一个更大的数组中,并将elementData 的指针更新。而一般情况下扩容后的大小都是原来大小的3/2,除非到了边界或者当前所需的最小大小大于这个3/2,它会做出一些改变。
一句话来讲就是——grow方法会将当前的elementData 对象数组扩容到适合的大小,一般是原来的3/2倍。
回到最开始的问题——ensureCapacityInternal(size + 1)干了什么?
现在我们明白了,它是确保当前的数组容量能装下接下来的元素,如果不够它会选择扩容。
最后再执行
elementData[size++] = e;
即size自增1,然后将最后一个元素赋值为e。
这样add方法便完成了!
②add(int index, E element)
这个方法和上面类似,所以重复的部分我就不赘述了。
public void add(int index, E element) {
//检查该index下标是否合法
rangeCheckForAdd(index);
//确保数组容量足够,如果不够则扩容
ensureCapacityInternal(size + 1);
//调用arraycopy方法,让index后面的元素全部后移一位,好让新的元素加进来
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
//赋值
elementData[index] = element;
//size自增1
size++;
}
和之前类似,做了以下几步:
- 检查index下标是否合法
- 确保数组容量足够,如果不够则扩容
- 调用arraycopy方法,让index后面的元素全部后移一位,好让新的元素加进来
- 给index下标出的元素赋值
- size++
这里我们看到每次插入需要做的便是将index下标后面的元素全部后移,所以效率不是特别高,比较麻烦。
2.3.3 remove方法
remove方法也有两种,一种是根据下标删除,一种是根据对象删除。
①E remove(int index)
根据数组下标删除元素
public E remove(int index) {
//检查下标是否合法
rangeCheck(index);
//用于检查并发错误的标记变量++
modCount++;
//获取index下标的元素
E oldValue = elementData(index);
//index离最后一个元素的距离
int numMoved = size - index - 1;
//如果index后面存在元素则将index后面的元素前移一位
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
//将之前最后一位元素指向null
elementData[--size] = null;
//返回删除的对象
return oldValue;
}
这个方法说明看注释吧,注释说的很清楚了。
②boolean remove(Object o)
根据对象删除元素
public boolean remove(Object o) {
//因为对象的判断需要调用equals方法,所以需要判断一下o是否为null
if (o == null) {
//遍历所有元素
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
//快速删除index下标的元素
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
这里就是一次遍历所有元素,如果找到该对象就删除。
不过可以看看这个fastRemove方法,
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null;
}
可以看到这里和前面非常类似,只不过它这里没有进行边界检查。
2.3.4 get方法
我们知道ArrayList实际上就是数组的封装,所以对于具有随机访问的数组而言,根据下标访问元素实在太简单不过了。
public E get(int index) {
//下标安全检查
rangeCheck(index);
return elementData(index);
}
2.3.5 set方法
修改index下标的元素为element
public E set(int index, E element) {
//下标检查
rangeCheck(index);
//旧的值
E oldValue = elementData(index);
//更新值
elementData[index] = element;
//返回旧的值
return oldValue;
}
2.3.6 size方法
public int size() {
return size;
}
其实就是把size返回,但这里要注意的是size的意义,它不是指当前ArrayList的容量有多少,而是指当前ArrayList中有多少元素。
2.3.7 indexOf方法
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
该方法就是遍历查找是否有对象o,如果找到则返回下标。
2.3.8 toArray方法
public Object[] toArray() {
return Arrays.copyOf(elementData, size);
}
需要注意的是该方法是将其elementData对象数组从内存中复制了一份,而且长度就是元素的数量。所以不必担心修改toArray方法的得到的数组会影响原ArrayList对象。
2.3.9 removeAll和retainAll方法
①removeAll(Collection c)
删除ArrayList中所有和集合中相同的元素
public boolean removeAll(Collection<?> c) {
//检查该集合是否为空
Objects.requireNonNull(c);
return batchRemove(c, false);
}
该方法的核心在于boolean batchRemove(Collection c, boolean complement)方法,我们点进去看一下,
private boolean batchRemove(Collection<?> c, boolean complement) {
final Object[] elementData = this.elementData;
//r为快指针,w为慢指针
int r = 0, w = 0;
boolean modified = false;
try {
for (; r < size; r++)
if (c.contains(elementData[r]) == complement)
//只有符合条件时,w才自增
elementData[w++] = elementData[r];
} finally {
// 这里正常情况都是r=size,只有在程序遇到异常时,才可能会遇到r!=size的情况。
if (r != size) {
System.arraycopy(elementData, r,
elementData, w,
size - r);
w += size - r;
}
//当w!=size时,即有元素被抛弃了,这时需要把后面无用的元素值置为null
if (w != size) {
// 将后面的元素值置为null
for (int i = w; i < size; i++)
elementData[i] = null;
//modcount加上修改过的元素
modCount += size - w;
//更新size
size = w;
//此时已经抛弃了一些元素,所以置为true
modified = true;
}
}
return modified;
}
可以看到这里用了快慢指针的技巧,当遇到要保留的元素时w再自增,最终保留元素的下标便是0到w-1。
在遍历的过程中调用contains方法看看这个元素是否在集合c中。
这里巧妙的地方在于它把contains的返回值complement参数比较。
这样,Boolean类型的complement参数的作用就类似于一个开关,当为true时,这个函数就是保留在集合c中出现过的元素,否则保留未出现过的元素。
②retainAll(Collection c)
而retainAll也类似,只不过它把开关置为false,这样就会保留在集合c中出现过的元素。
public boolean retainAll(Collection<?> c) {
Objects.requireNonNull(c);
return batchRemove(c, true);
}
2.4 迭代器
2.4.1 普通迭代器Itr
private class Itr implements Iterator<E> {
//下一个元素下标
int cursor; // index of next element to return
//上一个元素下标
int lastRet = -1; // index of last element returned; -1 if no such
//期望修改次数(后面会讲,现在不用管)
int expectedModCount = modCount;
Itr() {
}
//判断是否有下一个
public boolean hasNext() {
return cursor != size;
}
//返回当前停留的元素
@SuppressWarnings("unchecked")
public E next() {
//检查是否有修改,这个之后会讲,现在先不管它
checkForComodification();
int i = cursor;
//如果此时下一次超出数组范围,则抛出没有NoSuchElementException异常
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
//如果此时i还能大于等于数组的长度,唯一的可能就是在遍历过程中有程序对其做了修改,所以此时应抛出并发异常ConcurrentModificationException
if (i >= elementData.length)
throw new ConcurrentModificationException();
//下一个元素的下标为i+1
cursor = i + 1;
//返回下标为i的元素
return (E) elementData[lastRet = i];
}
public void remove() {
//如果当前的元素下标小于0,抛出IllegalStateException异常
if (lastRet < 0)
throw new IllegalStateException();
//检查是否有修改
checkForComodification();
try {
//删除上一个元素
ArrayList.this.remove(lastRet);
//指针回退
cursor = lastRet;
//上一个指针回归-1,这个就说明了不能连续调用remove方法
lastRet = -1;
//期望的修改值变为当前的修改值(这些之后会讲)
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
}
这里有个值得注意的地方——它在定义的迭代器的时候加了个private,那我们如何去创建迭代器呢?
其实它有个Iterator()方法,
public Iterator<E> iterator() {
return new Itr();
}
它就返回了一个迭代器的对象。
这样的好处就在于面对不同的集合类只需调用通用的接口方法iterator()便可以返回相应的迭代器。
看完上面的源码我们明白了以下几点:
1. 这个迭代器对象只能使用一次,因为它没有初始化重置的方法
2. 这个迭代器只会往前,因为它只有next方法
3. 不能连续调用remove方法,因为调用了一次后,指向上一个元素下标的lastRet变量便被赋值为-1,连续调用会抛出异常
看完上面这个迭代器的源码,你会发现——初看源码会有一种不知所云的感觉,但是去掉这些让我看起来不知所云的操作和边界条件的检查后,是不是感觉简单了起来?
没错,如果不管这些边界条件,不管并发可能带来的错误,那么我们也能写出ArrayList的迭代器。
这里,为了更好理解代码,我这里放上该迭代器使用简单例子
Iterator<Integer> iterator=list.iterator();
while (iterator.hasNext()){
Integer i=iterator.next();
iterator.remove();
}
看了源码后是不是更有感觉了呢?
2.4.2 迭代器的增强版ListItr
private class ListItr extends Itr implements ListIterator<E> {
ListItr(int index) {
super();
cursor = index;
}
public boolean hasPrevious() {
return cursor != 0;
}
public int nextIndex() {
return cursor;
}
public int previousIndex() {
return cursor - 1;
}
@SuppressWarnings("unchecked")
public E previous() {
//检查是否有修改
checkForComodification();
//cursor前移
int i = cursor - 1;
//检查i是否小于0
if (i < 0)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
//如果此时i还能大于等于数组的长度,唯一的可能就是在遍历过程中有程序对其做了修改,所以此时应抛出并发异常ConcurrentModificationException
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i;
return (E) elementData[lastRet = i];
}
public void set(E e) {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
//修改当前下标的元素值
try {
ArrayList.this.set(lastRet, e);
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
public void add(E e) {
checkForComodification();
try {
int i = cursor;
ArrayList.this.add(i, e);
cursor = i + 1;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
}
可以看到ListItr是Itr的子类,在有Itr的功能的基础上,拓展了前移指针的previous()方法、增加元素的add(E e)方法和修改当前元素的方法set(E e)。源码操作也不难理解,这里就不多介绍了。
2.4.3 干扰检测
①为什么要有干扰检测
在看迭代器的源码,你是不是很疑惑为啥会有执行checkForComodification()检查?
你是不是很疑惑为什么很多地方会有modCount++,expectedModCount = modCount这种操作?
你是不是很疑惑modCount,expectedModCount 是来用来干什么的呢?
带着这些疑问,我们来探究一下这样做的原因和原理。
首先,不知道你在写程序的时候遇到ConcurrentModificationException()这个异常,在我们用迭代器遍历过程中,有没有删除增加过集合。比如下面这样:
for (Integer i:list){
list.add(1);
}
注意:ArrayList的foreach增强遍历本质就是调用了迭代器。
我们在遍历途中不断向集合中添加整数1,这看似好像没有什么问题,可仔细一想,如果不断添加,那么这个迭代器调用的next真的是原来所期望的next吗?看似好像不会影响结果,但实际上这往往会发生一些逻辑上的错误,如果不对这些情况做出一些提示,程序员会非常苦恼,因为他们很难发现这里面的问题。
同时在并发编程中,如果你对共享变量误用了非线程安全的ArrayList,那么有个线程正在遍历ArrayList集合,可以另一个线程对其做了修改,这会不会发生一些错误呢?尽管在这种情况下ArrayList并未做出有效解决方案,但它必须有责任告知你这个情况,所以它会抛出这个ConcurrentModificationException异常。
②干扰检测原理
那么它是如何实现的呢?
核心就modcount和expectedModCount 变量。
还记得我们调用add,remove方法出现modcount++操作吗?
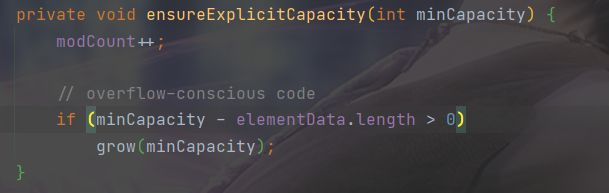

在这里modcount就是累计修改的次数,expectedModCount 就是预期修改的次数。
这里要注意的是modcount是全局的一个属性
protected transient int modCount = 0;
而expectedModCount 是在迭代器内部的一个属性。

言外之意就是该错误检测一定是在迭代器内部实现的。
阅读源码我们发现,在ArrayList每次进程执行add,remove方法时,都会触发一次modcount++。
同时在创建迭代器时,expectedModCount 的初值就被赋值为当时的modcount,
而每次迭代器在进行next和remove方法时都会做一次检测
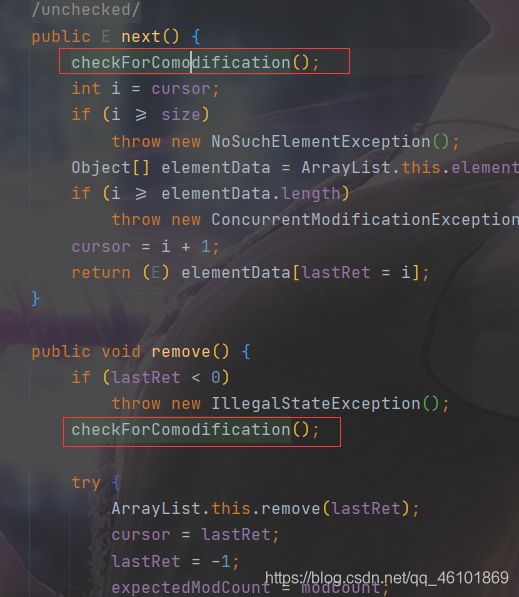
点开方法查看
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
这个方法实质就是在比较modCount和expectedModCount是否相等,如果不相等就抛出ConcurrentModificationException异常。
检查完后,我们对集合进行修改时,如执行remove方法,那么就会modcount++,经过几步操作后在把modcount的值赋值给expectedModCount ,这是就保证了expectedModCount 与modcount是相等的,但是预期之外的修改可不会执行这句话,所以就会造成modCount和expectedModCount值不一致,从而检查出了错误。
到这里我们终于明白了它的核心思路:
在迭代器里的修改(主要是指add和remove方法)是被允许的,因为这是迭代器内可见的。但是在预期之外的修改是不被允许的,一旦迭代器发现了预期之外的修改(执行checkForComodification()方法检查modCount和expectedModCount是否相等),那么迭代器就会抛出ConcurrentModificationException异常告诉工程师——啊,我迭代过程中出现问题了,可能会发生一些逻辑错误。
到现在你也明白了这样做的原因和原理,那么我问你个问题——你觉得这个过程完美吗?
看着很完美是吗?
其实不是的,实际上你仔细看看这段
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
modCount修改到expectedModCount被更新这里中间差了这么多步,那我们假设在这个过程中其他线程修改了集合,这时modcount又被更新了,但是expectedModCount 还没更新啊。当expectedModCount 更新时,它以为它更新的值是预期中的,但是实际上有预期外的修改混了进来,而它却浑然不知。
所以说,ArrayList是个非线程安全的类,即使在迭代过程中,它有着能感知这种意外的机制,但是这种机制并不是那么灵敏,在一些情况下,它检测不出并发错误。(当然啦,这个机制最主要的是检查工程师在遍历过程中误修改操作,对于并发错误的检测也只是顺带的罢了)
当然啦,源码中也有这么一段注释:
/*
* If ArrayLists were immutable, or structurally immutable (no
* adds, removes, etc), we could implement their spliterators
* with Arrays.spliterator. Instead we detect as much
* interference during traversal as practical without
* sacrificing much performance. We rely primarily on
* modCounts. These are not guaranteed to detect concurrency
* violations, and are sometimes overly conservative about
* within-thread interference, but detect enough problems to
* be worthwhile in practice. To carry this out, we (1) lazily
* initialize fence and expectedModCount until the latest
* point that we need to commit to the state we are checking
* against; thus improving precision. (This doesn't apply to
* SubLists, that create spliterators with current non-lazy
* values). (2) We perform only a single
* ConcurrentModificationException check at the end of forEach
* (the most performance-sensitive method). When using forEach
* (as opposed to iterators), we can normally only detect
* interference after actions, not before. Further
* CME-triggering checks apply to all other possible
* violations of assumptions for example null or too-small
* elementData array given its size(), that could only have
* occurred due to interference. This allows the inner loop
* of forEach to run without any further checks, and
* simplifies lambda-resolution. While this does entail a
* number of checks, note that in the common case of
* list.stream().forEach(a), no checks or other computation
* occur anywhere other than inside forEach itself. The other
* less-often-used methods cannot take advantage of most of
* these streamlinings.
*/
翻译过来就是:
如果 ArrayLists 是不可变的,或者结构上不可变的(没有添加、删除等),我们可以使用 Arrays.spliterator 实现它们的拆分器。相反,我们在不牺牲太多性能的情况下,在遍历过程中检测到尽可能多的干扰。我们主要依赖 modCounts。这些不能保证检测到并发冲突,并且有时对线程内干扰过于保守,但是可以检测到足够的问题以值得实践。为了实现这一点,我们(1)延迟初始化fence和expectedModCount,直到我们需要提交到我们正在检查的状态的最新点;从而提高精度。 (这不适用于创建具有当前非惰性值的拆分器的子列表)。 (2) 我们在 forEach 的末尾只执行一个ConcurrentModificationException 检查(对性能最敏感的方法)。当使用 forEach(而不是迭代器)时,我们通常只能在动作之后检测干扰,而不是之前。进一步的 CME触发检查适用于所有其他可能违反假设的情况,例如 null 或给定 size() 的太小的 elementData数组,这可能仅由于干扰而发生。这允许 forEach 的内部循环在没有任何进一步检查的情况下运行,并简化了 lambda解析。虽然这确实需要一些检查,但请注意,在 list.stream().forEach(a) 的常见情况下,除了 forEach本身之外,不会在任何地方进行检查或其他计算。其他不太常用的方法不能利用这些流线化中的大部分。
2.4.4 ArrayListSpliterator拆分迭代器
这个拆分迭代器时jdk8引入的,是为了满足流式编程的需要,用于并行流的拆分,这块我之后再补。(未完待续…)
static final class ArrayListSpliterator<E> implements Spliterator<E> {
/*
* If ArrayLists were immutable, or structurally immutable (no
* adds, removes, etc), we could implement their spliterators
* with Arrays.spliterator. Instead we detect as much
* interference during traversal as practical without
* sacrificing much performance. We rely primarily on
* modCounts. These are not guaranteed to detect concurrency
* violations, and are sometimes overly conservative about
* within-thread interference, but detect enough problems to
* be worthwhile in practice. To carry this out, we (1) lazily
* initialize fence and expectedModCount until the latest
* point that we need to commit to the state we are checking
* against; thus improving precision. (This doesn't apply to
* SubLists, that create spliterators with current non-lazy
* values). (2) We perform only a single
* ConcurrentModificationException check at the end of forEach
* (the most performance-sensitive method). When using forEach
* (as opposed to iterators), we can normally only detect
* interference after actions, not before. Further
* CME-triggering checks apply to all other possible
* violations of assumptions for example null or too-small
* elementData array given its size(), that could only have
* occurred due to interference. This allows the inner loop
* of forEach to run without any further checks, and
* simplifies lambda-resolution. While this does entail a
* number of checks, note that in the common case of
* list.stream().forEach(a), no checks or other computation
* occur anywhere other than inside forEach itself. The other
* less-often-used methods cannot take advantage of most of
* these streamlinings.
*/
private final ArrayList<E> list;
private int index; // current index, modified on advance/split
private int fence; // -1 until used; then one past last index
private int expectedModCount; // initialized when fence set
/** Create new spliterator covering the given range */
ArrayListSpliterator(ArrayList<E> list, int origin, int fence,
int expectedModCount) {
this.list = list; // OK if null unless traversed
this.index = origin;
this.fence = fence;
this.expectedModCount = expectedModCount;
}
private int getFence() {
// initialize fence to size on first use
int hi; // (a specialized variant appears in method forEach)
ArrayList<E> lst;
if ((hi = fence) < 0) {
if ((lst = list) == null)
hi = fence = 0;
else {
expectedModCount = lst.modCount;
hi = fence = lst.size;
}
}
return hi;
}
public ArrayListSpliterator<E> trySplit() {
int hi = getFence(), lo = index, mid = (lo + hi) >>> 1;
return (lo >= mid) ? null : // divide range in half unless too small
new ArrayListSpliterator<E>(list, lo, index = mid,
expectedModCount);
}
public boolean tryAdvance(Consumer<? super E> action) {
if (action == null)
throw new NullPointerException();
int hi = getFence(), i = index;
if (i < hi) {
index = i + 1;
@SuppressWarnings("unchecked") E e = (E)list.elementData[i];
action.accept(e);
if (list.modCount != expectedModCount)
throw new ConcurrentModificationException();
return true;
}
return false;
}
public void forEachRemaining(Consumer<? super E> action) {
int i, hi, mc; // hoist accesses and checks from loop
ArrayList<E> lst; Object[] a;
if (action == null)
throw new NullPointerException();
if ((lst = list) != null && (a = lst.elementData) != null) {
if ((hi = fence) < 0) {
mc = lst.modCount;
hi = lst.size;
}
else
mc = expectedModCount;
if ((i = index) >= 0 && (index = hi) <= a.length) {
for (; i < hi; ++i) {
@SuppressWarnings("unchecked") E e = (E) a[i];
action.accept(e);
}
if (lst.modCount == mc)
return;
}
}
throw new ConcurrentModificationException();
}
public long estimateSize() {
return (long) (getFence() - index);
}
public int characteristics() {
return Spliterator.ORDERED | Spliterator.SIZED | Spliterator.SUBSIZED;
}
}
2.4.5 迭代器总结
除了拆分迭代器,ArrayList中的迭代器其实很简单。
如果没有那些边界检查,没有并发错误检测,就算作为初学者的我们也能出色的完成任务。但是作为jdk类库中最常用的集合类,它必须是可靠的,它必须有着极高的性能,同时拥有较高的安全性。
迭代器作为遍历集合的手段,它可以在遍历的过程中不断遍历同时对元素做出修改。在这个过程中它会尽量避免一些错误的发生。
Itr是普遍的迭代器,它只能单向遍历,同时遍历完后就没用了,也无法连续调用remove方法。
ListItr作为Itr的增强版(也是子类),在其基础上拓展了双向遍历的功能,同时支持增删改的操作。
四、总结
总结一下,
ArrayList是对数据结构中数组的封装,其核心是就是对象数组elementData。它最大的特点就是让数组看起来是可以动态扩容的,并且提供各种方便的操作,极大提升了我们日常开发的效率。
对于ArrayList,你需要记住以下几点:
- ArrayList的核心是对象数组elementData,它是存放数据的地方。
- size并不代表这数组的容量,而是指当前list中元素的数量。
- 由于elementData数组并未对外开放,你无法直接获取elementData数组,除非你用反射,同时容量也无法直接获取。
- ArrayList是看起来支持动态扩容,实际依旧摆脱不了数组的特性——创建容量即确定。扩容原理就是调用System.arrayCopy方法进行数组复制,把原来数组的内容复制到另外一个容量更大的数组里。
- ArrayList创建时最好给它一个初始容量来避免后续的扩容。
- ArrayList适用于查询多,增删操作少的情况。
- 在add方法执行后,如果容量不足它会自动扩容,一般情况下扩容后的容量时原来容量的3/2倍
- 迭代器为了保证迭代过程中不出现预期之外的修改,会进行检查。如果出现了预期之外的修改,会抛出ConcurrentModificationException异常。
整篇源码读下来,其实好处还是很多的,
在对外方法的暴露上,在对内代码的封装和复用上,在方法间的调用上,你可以发现各种设计模式,感叹设计的巧妙。
如此复杂的方法调用在这里被组织的井然有序,这是我们日常开发中需要好好学习的。
好了,这篇的内容到这里就差不多结束了,当然本文也并非讲解所有的源码,只是挑了核心原理的一部分来讲,至于其他方法,个人认为是一些其他方面的封装,这里我就不一一赘述了,感兴趣的同学可以自己去研读。
愿我们以梦为马,不负人生韶华。
与君共勉!