Performance and Design
Following up on Antranig’s recent post about performance, I’d like to address the issue of code design and its relationship to performance. Antranig’s article is very comprehensive and well-considered, and it provides us with a number of guidelines for balancing the tradeoffs between code quality and speed. However, I was surprised that he didn’t remind us the C.A.R. Hoare quote made famous by Donald Knuth:
“Premature optimization is the root of all evil.”
Antranig’s performance metrics are intended to help establish a gut feel about the cost of a particular operation. They’re low-level measurements, and as such they can’t take into account a fundamental variable: context. These performance metrics have very different consequences depending on the size, scale, and nature of the application. His examples are apt: intensive, highly recursive, up-front operations like template rendering show the full cost of JavaScript’s weak performance. Indeed, Antranig has used his research to good effect on our nascent client-side template renderer. In a relatively short amount of time, he was able to improve the performance of his low-level parsing algorithms by several orders of magnitude using regular expressions and fast string comparisons. Impressive stuff.
On the other hand, context matters a lot when it comes to user-facing behaviour, where timings may vary significantly based on the user’s choices. Many UI components, such as the Uploader, provide a fairly modal experience for the user. Such components undoubtedly have less stringent performance requirements, and our acceptance criteria should be determined by testing in real-world situations.
The risk with out of context performance measurements is the tendency to optimize prematurely and without accurate data. There’s only so much time in the day. Don’t lose the opportunity to add useful features to your application by starting in on time-intensive performance optimizations too early. Without good data, your hard work may only have a tiny impact on the overall perception of speediness. Worse yet, premature optimization can lead towards architectures that are poorly factored, redundant, and hard to maintain.
So how do we ensure good performance without compromising architectural quality?
- Write code with good design principles in mind
- Continually measure performance in real world situations
- Refine code incrementally to improve performance
Let’s take jQuery as an example. If you look at the first release of jQuery, you’ll find that it was mostly composed of small functions that are clear and easy to read. jQuery’s author, John Resig, has always done a very good job of carefully profiling his code with performance tests, and over time the code base has evolved in certain areas to be faster and, as a concequence, occasionally less readable. He took the time to build something real first, then he optimized strategically. This is exactly the example of how we should all handle performance optimizations: build it cleanly, then identify areas where performance optimizations are necessary. Optimization without real-world numbers is, well, evil.
Building on Antranig’s advice, here are some strategies to help ensure both good performance and a maintainable design in JavaScript:
Avoid deep inheritance hierarchies
Excess use of inheritance tends to be brittle, hard to reuse, and slow. In JavaScript, inheritance is prototypal: an object has a secret prototype link that points to its parent object. When a property isn’t found on an instance directly, the object’s prototype is searched, then the prototype’s prototype, and onwards up the inheritance chain. This can be extremely slow on objects with a long lineage. JavaScript provides more effective strategies for reuse, such as containment and dynamic mix-ins. You’re better off with a very shallow inheritance hierarchy, using these techniques to share code across objects instead.
Break code into small, independent parts
JavaScript is a functional language, and functions serve as the fundamental building block for all programs. Break complicated algorithms up into smaller functions that take only the data necessary to perform a given operation. Small functions are more easily tested, modified, and reused. What about the cost per function call that Antranig mentions? If you need to optimize for speed later, you can easily merge several functions back into one. Analyze frequent code paths and identify specific bottlenecks first, then selectively fold smaller functions into a larger one.
Don’t deeply nest functions
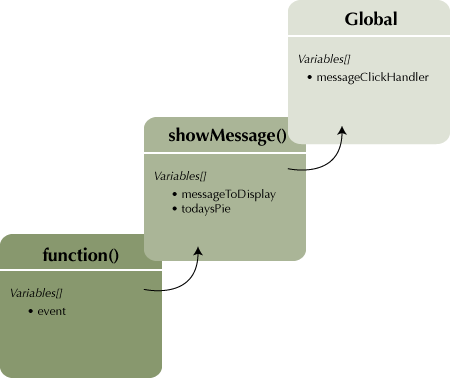
In JavaScript, functions can be nested inside other functions. This is a very powerful technique, since inner functions have access to the variables and scope of the outer function even after the outer function has finished executing. This is called closure, and it’s one of the best ways to encapsulate state and behaviour in JavaScript. The trick is to avoid deep nesting; don’t stick a function inside a function inside a function. Similar to the inheritance chain, each JavaScript function invocation brings with it a scope chain, providing access to variables defined in outer functions. If a reference to a particular variable isn’t found inside a function’s scope, the JavaScript runtime will climb the scope chain, searching each outer scope in turn to find the property. All this searching can get pretty slow. Limit yourself to a couple of layers of closure at the most. Here’s a slight contrived code example and an illustration of the scope chain in action:
Illustrated Code Example: Using a closure for event handling
function showMessage(messageToDisplay) {
var todaysPie = "Banana creme pie";
return function(event) {
alert(messageToDisplay + " " + todaysPie);
showPictureOfPie(event.target, todaysPie);
}
}
var messageClickHandler = showMessage("Welcome to my pie shop. Today's pie is:")
$(element).click(clickHandler);
Identify nameable units of behaviour and encapsulate them
On the client side, it’s really easy to let your application logic get all muddled up with your presentation code. Large, hard to maintain functions are often structured like this: 1) Perform some calculations; 2) fetch some data; 3) update the DOM. These are separate tasks, and your code will be significantly easier to read and reuse if you split these behaviours into independent units. The trick is to look at your code while you’re writing it and recognize “things” that are easily identified and named. Using a closure or an object, you can factor out pieces of the overall behaviour and data into a separate entity. Here’s an example of the various units of behaviour we identified within the Reorderer:
- The Reorderer is responsible for binding events to DOM elements and providing end-user APIs
- A Layout provides an awareness of visual layout and spatial characteristics: grids, lists, portlets within columns, and so on
- The Mover is responsible for moving elements around in the DOM, deferring to the Layout for spatial information
- A Permissions object defines the rules for valid drop targets and operations on a specific element
- Keyboard selections and accessibility is provided by the jQuery keyboard-a11y plugin
- MouseDragAndDrop encapsulates our use of jQuery UI for low-level drag and drop functionality
Use closures to encapsulate data and behaviour
Antranig covered this one really well in his post. Under many circumstances, you’ll pay a significantly lower cost to access data wrapped in a closure than within an object, and functional idioms tend to be more flexible and easier to maintain than object-oriented ones. This is particularly true in JavaScript, where there is no built-in support for namespaces or privacy. Just be careful not to nest your closures too deeply.
Never, ever cut and paste code
It almost feels silly to repeat this one here. One of the foundational principles of programming, regardless of the language you’re using, is DRY: Don’t Repeat Yourself. The bottom line is this: cut and pasted code will come back to bite you. Don’t do it. Antranig’s post hints at the idea that it’s okay to cut and past code in JavaScript. For all but the most extreme cases, I don’t buy it. If you find yourself tempted to cut and paste something, take the time to factor it into a function. It will be easier to update later, and much easier to test. Duplicate code hurts!