【Python爬虫】获取淘宝商品信息
程序语言:Python
开发平台:PyCharm【2017版本以上】
文章目标
使用Python语言基于PyCharm开发平台对淘宝商品信息进行爬虫爬取,并写入文件用于存储信息。本文以淘宝商品-凹凸曼为爬取对象。建议有Python 基础,以及对HTML有一定了解为前提下阅读本文。【如图示为淘宝爬取网站】

一、认识工具包
用Python爬取网站数据,需要以下2个重要库。
| Python库 | 用途 | 是否重要 |
|---|---|---|
| requests库 | 模拟浏览器 提供对互联网网站访问的功能 | 是 |
| re库 | 分割文本内容,这里主用于对HTML源码的数据提取 | 是 |
| time库 | 计时器 | 否 |
二、流程解析
文字流程:
1.获取一个url
2.向url发送请求,并获取响应(需要http协议)
3.如果从响应中提取url,则继续发送请求获取响应
4.如果从响应中提取数据,则将数据进行保存
5.如图示为爬取网站信息流程。通常情况下,爬虫

三、代码解析
3.1 导入库
爬取淘宝商品信息是基于以下两个库来实现。
import requests # 重要
import re # 重要
# import time # 非重要
3.2 模拟浏览器,响应URL页面
# 定义获取HTML内容的方法
# URL 爬取网站地址
def getHtmlText(URL):
try:
r = requests.get(url=URL, timeout=30)
# 检查响应
r.raise_for_status()
print("...网页响应成功 200")
# time.sleep(2)
# 检查是否乱码
if r.encoding == 'utf-8':
print("...网页源码为utf-8 无乱码")
else:
print(r.encoding)
return
# time.sleep(2)
print("...获取HTML页面完成")
return r.text
except:
return ""
爬取网页的第一步是成功访问对象网页,来获取其网页HTML源码信息,这是我们后面爬取网页商品信息的重要起步,无法越过。
第一步是检查网页是否响应。确定网页源码为UTF-8后,访问将为接下来的操作。访问能否成功将尤为关键,因为我们的访问是网页背后的HTML源码,通常访问成功会返回200。访问不成功属常见的404。
第二步是检查网页源码格式。只有看得懂,才能去做。国内网页源码通常为UTF-8格式,不是非UTF-8格式,也被称为乱码。因为乱码内容均为奇怪特异字符组成,是不便于去人为理解并用于爬取解析。确定网页源码是至关重要一步。
3.3 获取页面HTML源码,解析数据信息
# 定义解析数据的方法
# uList 数组类型,用于存放爬取信息
# html 获取网页的源码,基于GetHtmlText(URL)方法结果
def fillUnivList(uList, html):
try:
names = re.findall(r'\', html)
prices = re.findall(r'\[\d\.]*<\/strong\>' , html)
print("...页面数据解析完成")
# time.sleep(2)
print("...开始数据清洗")
for i in range(len(names)):
name = names[i].split('"')[3] # 以"为切割标识,取第4段
price = re.split(">|<", prices[i])[2] # 以>或<为切割标识。取第2段
uList.append([name, price])
except:
print("解析出错")
这里使用re库中的findall方法,由于获取淘宝页面的商品信息是通过读取网页源代码来分割与商品信息相关的HTML代码片。如下图所示:

我们选择如图片左侧的“正版奥特曼初代赛文…”所示,右侧为网页源码位置。如选中位置为该商品在淘宝页面的标价-【65元】。本段Python方法用于获取该页面的HTML源码,寻找与标价相关的数据信息。
3.4 存储数据
由【No.3】解析出需要的商品名称和商品价格后,我们需要将数据转存至文本或其他格式的文件进行数据存储。
# 定义格式化输出的方法
# uList为解析后获得的商品信息数据
# Path为存储数据信息的路径地址
def printUnivList(uList, Path):
# 读写
with open(Path, 'a', encoding="utf-8") as f:
f.write("商品\t价格\n")
for i in range(len(uList)):
u = uList[i]
f.write(u[0] + "\t") # 写入商品名称
f.write(u[1] + "\n") # 写入商品价格
f.close() # 关闭文件,避免长时间占用系统资源
print("成功存储到文件")
3.5 运行爬虫
def main():
uinfo = [] # 定义用于存储信息的数组
good = "奥特曼" # 定义需要搜索的商品名称
page = 1 # 设置浏览页面数——因为商品数量众多,这里仅设置浏览1页的所有商品信息
path = "D:\\" + good + ".txt" # 设置数据存储路径
# 遍历要浏览的商品页数
for i in range(page):
# 淘宝的商品地址,通过解析URL地址,其内容格式可简化为 【淘宝地址-搜索物品名称-当前页数】
URL = "https://re.taobao.com/search_ou?keyword=" + good + "&page=" + str(i)
html = getHtmlText(URL) # 调用方法
# time.sleep(2)
fillUnivList(uinfo, html) # 调用方法
# time.sleep(2)
print("共搜索了", len(uinfo), "条结果")
# time.sleep(2)
printUnivList(uinfo, path) # 调用方法
if __name__ == "__main__":
main()
3.6 运行结果

如上图所示为PyCharm运行结果。
3.7 返回存储路径地址,查看结果
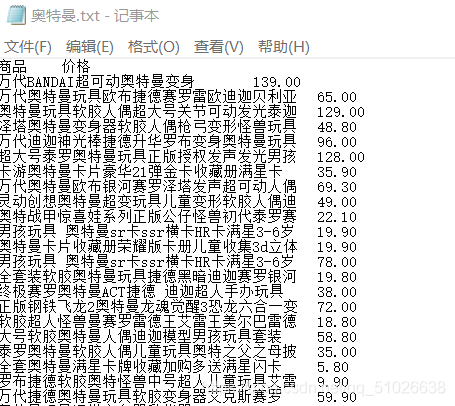
如上图所示为我们从淘宝网爬取的商品信息。
四、后记
由于对网站页面进行爬虫信息,需要一定基础的HTML网页知识。且多数网站为防止第三方爬取自身运行的网站信息,通常会有反爬虫对我们的爬虫行为进行反制。切勿频繁访问爬取网站信息,否则会被禁止访问该网站。或许购买IP池伪装爬取,但一切以不触犯法律为基础进行,否则后果自负。