3万6千字爆肝,前端进阶不得不了解的函数式编程开发,含大量实例,手写案例,所有案例均可运行
3w6爆肝,前端进阶不得不了解的函数式编程开发,含大量实例,手写案例,所有案例均可运行
-
- 认识函数式编程
- 函数相关复习
-
- 函数是一等公民
- 高级函数
-
- 函数作为参数
-
- 案例 1,模拟 forEach
- 案例 2,模拟 filter
- 函数作为返回值
-
- 函数作为返回值使用案例
- once 案例
- 高阶函数的意义
- 常用的高阶函数
-
- map
- array
- some
- 闭包
-
- 闭包的概念
- 案例
- 函数式编程基础
-
- lodash
- 纯函数
-
- 纯函数的概念和特点
- 好处
- 副作用
- 柯里化
-
- lodash 中的柯里化方法
- 柯里化方法案例
-
- 柯里化案例 1
- 柯里化案例 2
- 柯里化方法原理模拟
- 柯里化方法总结
- 函数组合
-
- 管道
- 函数组合的概念及初级应用案例
- Lodash 中的组合函数
- 组合函数原理模拟
- 函数组合-结合律
- 函数组合-调试
- Lodash-fp 模块
-
- Lodash-fp 与 Lodash 之间的对比
-
- lodash 会变异数组,而 fp 不会
- map 方法的小问题
- Point-free
-
- Functor(函子)
-
- 函子总结
- Maybe 函子
- Either 函子
- IO 函子
-
- IO 函子的一个问题
- Task 函子
-
- Folktale
- Folktale 中的 Task 函子
- Pointed 函子
- Monad 函子
还不了解React所提倡的,Vue最近也慢慢兼容的函数式编程风格吗?那看看这里,深入理解一下函数式编程及其好处,写出更加优雅的代码吧。
本章内容包含:
理解函数式编程,如为什么要学习函数式编程,函数式编程所带来的好处,高阶函数的意义,以及手写实现一些常见的 Array 函数
柯里化,包括概念讲解、案例以及手写实现柯里化
组合函数,组合函数的讲解和理解,以及手写函数组合的处理方法
Lodash 中 fp 的使用,以及 fp 和 lodash 的一些对比
Point-free 的概念和相关案例
包括 Function 函子,MayBe 函子,Either 函子,IO 函子, of 函子, Monad 函子
以上内容中都或多或少地带了一些 Lodash 的使用
前前后后总共学了差不多一周的时间,笔记零零碎碎地写了两三天。除了视频的内容之外,也结合了一些自己的开发经验补充了一些案例,希望能够共同进步,早日上岸 w
认识函数式编程
函数式编程(Functional Programming) 是一种编程思想,起源于 λ-calculus(Lambda Calculus),在 1930 年的时候就已经被用于功能性应用、定义及递归上。其核心思维就是抽象化过程,关注输入和输出。
应用函数式编程思想的编程语言家族成员有:
- LISP,一个 1960 年就被设计出来的编程语言,至今仍然非常活跃
- Meta Language(ML)
- Scala
- F#
- Erlang
- Haskell
- …
最近随着 React 的流行,函数式编程的思想又再一次流行起来了。
它的特点有以下几个:
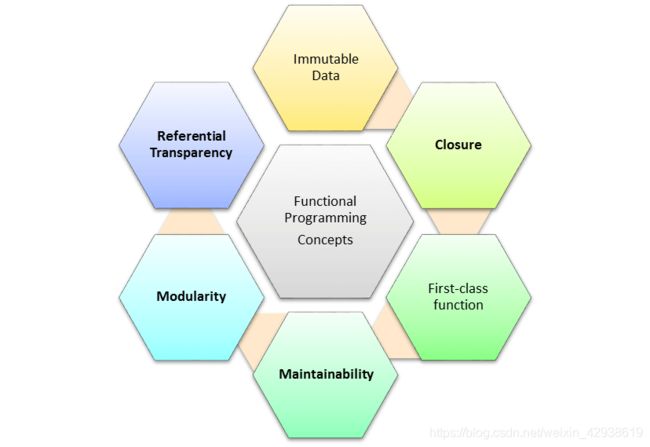
即:
-
不可变数据(Immutable Data)
React 和 Redux 的核心思维,Vue 也引进了这个概念
-
闭包(Closure)
JavaScript 中应用广泛的痛点之一
-
函数是一等公民(First-class function)
函数式编程是一种概念,既然早在编程语言出现之前就有了这种思想,那么这个函数指代的自然不会是编程语言中的函数。
它所指代的是更纯粹的数学中的函数映射关系,如 y = s i n ( x ) y = sin(x) y=sin(x) 中, x x x 和 y y y 的关系
-
维护性(Maintainability)
依赖于其纯函数的特性,即 相同的输入始终会得到相同的输出,这也是数学中幂等性的概念
-
模块化(Modularity)
三大主流框架之中 Angular 不了解,只知道是 MVC 的结构;但是 React 和 Vue 都在走模块化拆分的路线
这么一算就是大半的主流前端框架都在使用模块化的思维进行开发,自然可以说明函数式开发有其自己的优点
-
引用透明性(Referential Transparency)
即函数的返回值只依赖其输入值的思想,这种思想可以使得代码更加模块化和易于测试。
这也代表着函数式编程是用来描述 数据(函数) 之间的映射(关系)
从应用层的角度上来说,函数式编程也有以下几个优点:
-
因为函数的返回值只依赖于其输入值,所以可以抛弃对 this 的依赖
-
可以更好地利用 tree shaking 过滤无用代码
即将不相关的代码「摇」掉,在打包的过程中不将不想关的代码打包的做法
-
方便测试
基于其幂等性,所以每一次给予相同的输入都应该会返回相应的输出。因为可预测性,也就使得测试变得更加简单
-
众多的库可以帮助开发
最常有的有 lodash,还有 underscore, rambda
综上所述,这也是为什么对于前端人员来说,学习和了解函数式编程开发俨然成了一个必修课。
函数相关复习
函数是一等公民
当一门编程语言的函数可以被当作变量一样用时,则称这门语言拥有 头等函数
这是来自 MDN 的定义,MDN 将 first-class function 翻译成了头等函数,本质上是一个东西。
在 JavaScript 中,除了原始值之外的其他值都是对象,包括函数,也因此,函数就可以被存储到变量/数组中去,也可以作为另外一个函数的参数和返回值。
函数作为变量在 JavaScript 是一个比较常见的写法了,也被称之为 函数表达式:
const fn = function () {
console.log('Function expression');
};
fn();
// 更加复杂的应用法
const BlogController = {
index(posts) {
return Views.index(posts);
},
show(post) {
return Views.show(posts);
},
create(attr) {
return DB.create(attrs);
},
update(post, attrs) {
return DB.update(post, attrs);
},
destroy(post) {
return DB.destroy(post);
},
};
// 优化
// 将方法作为值 赋给另一个方法
// 注意,赋的是方法本身,而不是其调用,所以 () 在这里是不需要的
const BlogController = {
index: Views.index,
show: Views.show,
create: DB.create,
update: DB.update,
destroy: DB.destroy,
};
上面的案例已经充分说明了 函数被当作变量一样用 的特性,而这个特性,就是高阶函数和柯里化的基础。
高级函数
高阶函数(Higher-order Function)有以下两个特性:
-
函数可以作为参数
这个特性 React 里面的 HOC 用的贼 6
-
函数可以作为返回值
函数作为参数
这个特点依旧是围绕函数的模块化来实行的,即将函数封装为一个模块。
以 y = f ( x ) y = f(x) y=f(x) 为例,对于 y y y 而说, f ( x ) f(x) f(x) 的具体实现过程是被抽象化的, y y y 只需要得到 f ( x ) f(x) f(x) 返回的结果,并且 f ( x ) f(x) f(x) 返回的结果是正确的即可。
注:函数名必须要有意义,需要自证其用。
案例 1,模拟 forEach
对于 forEach() 来说,这个函数的意义就是 对数组的每个元素执行一次给定的函数。至于函数内部是怎么完成数组的遍历的,调用者并不在乎。
// 接受一个函数去在遍历中执行
/**
* 对数组的每个元素执行一次给定的函数
*
* @param {arr} arr
* @param {func} fn
*/
function forEach(arr, fn) {
for (let i = 0; i < arr.length; i++) {
fn(arr[i]);
}
}
// 测试部分
const arr = [1, 2, 3, 4];
forEach(arr, function (item) {
console.log(item);
});
// 输出为
// 1
// 2
// 3
// 4
案例 2,模拟 filter
同样的,对于 filter() 来说,这个函数的意义就是 新建一个新数组, 其包含通过所提供函数实现的测试的所有元素。至于函数内部是怎么完成数组的遍历的,调用者同样不在乎。
/**
* 新建一个新数组, 其包含通过所提供函数实现的测试的所有元素
* 为了通用性,接受一个函数去在遍历中执行
* @param {array} arr
* @param {fn} fn
* @returns
*/
function filter(arr, fn) {
const results = [];
for (let i = 0; i < arr.length; i++) {
const el = arr[i];
if (fn(el)) {
results.push(el);
}
}
return results;
}
// 测试部分
const arr2 = [10, 15, 20, 25];
const result = filter(arr2, function (item) {
return item % 2 === 0;
}); // 结果为 [ 10, 20 ]
函数作为返回值
函数作为返回值就等于让一个函数生成另一个函数。
函数作为返回值使用案例
下面是一个初级案例,讲的是怎么使用函数去生成另一个函数:
/**
* 用函数生成另外一个函数
* @returns function
*/
function generateFn() {
let msg = 'Hello World';
return function () {
console.log(msg);
};
}
const fn = generateFn();
fn(); // Hello World
// 第二种调用方式
generateFn()(); // Hello World
once 案例
知道了怎么生成函数,接下来就要写一个有意义的案例了。
lodash 中的 once 就是只让函数执行一次,这种其实我觉得使用最多的应该是单例模式了,创建一个变量,然后让全局引用。
使用案例如下:
/**
* 让一个函数只执行一次
* @param {function} fn
*/
function once(fn) {
let done = false;
return function () {
if (!done) {
done = true;
// arguments 是匿名函数中的 artuments
return fn.apply(this, arguments);
}
};
}
const pay = once(function (amount) {
console.log(`Has paid: $${
amount}`);
});
pay(100); // 只会执行一次
pay(100); // 运行到这里的时候,done就已经是false了,所以后面不会再被执行
pay(100);
pay(100);
pay(100);
高阶函数的意义
有两点:
- 对运算过程进行抽象处理通用的问题
- 屏蔽掉抽象的部分,只需要关注目标,即运行结果
这也是函数式编程的核心思想,如上面写的 forEach 和 filter,就是抽象化了内部的实现过程,只关注其运行结果——对 forEach 来说是遍历,对 filter 是过滤。
常用的高阶函数
模拟了一部分部分数组的通用函数,鉴于都已经知道这些函数的目的了,注释就偷下懒了……
map
直接写实现了。
const map = (arr, fn) => {
const results = [];
for (let el of arr) {
results.push(fn(el));
}
return results;
};
const arr = [1, 2, 3, 4];
console.log(map(arr, (el) => el ** 2)); // [ 1, 4, 9, 16 ]
array
直接写实现了。
const arr = [1, 2, 3, 4];
const every = (arr, fn) => {
for (const el of arr) {
if (!fn(el)) {
return false;
}
}
return true;
};
console.log(every(arr, (el) => el > 2)); // false
console.log(every(arr, (el) => el > 0)); // true
some
直接写实现了。
const arr = [1, 2, 3, 4];
const some = (arr, fn) => {
for (const el of arr) {
if (fn(el)) {
return true;
}
}
return false;
};
console.log(some(arr, (el) => el > 2)); // true
console.log(some(arr, (el) => el > 5)); // false
闭包
JavaScript 最大的痛点之一……
闭包的概念
闭包(closure) - 函数和其周围的状态(词法环境)的引用捆绑在一起形成闭包
翻译:可以在另一个作用域中调用一个函数的内部函数,并且访问到该内部函数的作用域中的成员
理解一下,就是,JavaScript 是原型链继承的,所以正常的使用都是下克上——原型链底层调用上层。使用闭包完成了上克下——即调用原型链下层的变量。
以之前的案例来说,generateFn 和 once 都是使用了闭包的概念。例如说他们的调用都是在全局作用域中,可是在全局作用域中,它们能够访问 generateFn 和 once 中的变量。
以 generateFn 为例:
当闭包不存在的时候,因为 ES6 的新特性就是在 {} 之中新构筑了一个作用域,所以当 generateFn 执行完毕后,msg 的引用不存在了,从而被垃圾回收。
function generateFn() {
let msg = 'Hello World';
} // 离开这个作用域之后,msg的引用就消失了
const fn = generateFn();
fn();
但是,当闭包存在滞后,情况就不一样了:
function generateFn() {
let msg = 'Hello World';
return function () {
// 对 msg 还存在引用关系
console.log(msg);
};
} // 匿名函数被作为引用对象返回给了外层的对象,引用依然存在,msg无法被销毁
// 生成了对 generateFn() 中的匿名函数的引用
// 但凡 fn 没有被销毁,generateFn() 中的 msg 就 无法被释放
const fn = generateFn();
案例
案例假设:经常会调用数字的幂,为了减少变量的传输,因此会将 Math.pow(val, nthPow) 进行封装。
function generateNthPow(pow) {
return function (num) {
return Math.pow(num, pow);
};
}
const square = generateNthPow(2);
console.log(square(2));
接下来分析一下上面这个案例的执行过程。
-
当执行到
const square = generateNthPow(2);时:调用
generateNthPow(pow),并且返回 其中的匿名函数此时
square的值为function (num) {...}的引用 -
当执行到
console.log(square(2))时调用其中的匿名函数,并且返回
Math.pow(num, pow)的值,注意一下现在的作用域:
现在的局部作用于是匿名函数的作用域,因此能够看到
num: 2,而下面的闭包(closure),就是跟闭包相关的变量。再回忆一下现在的函数的声明时在
global这个作用域之中,它访问到了一个generateNthPow的内部作用域中的内部函数,并且还能够访问到generateNthPow中的的变量,也就是pow。
适当地使用闭包可以减少函数的重复性,从而减少代码量,写出更加优雅的代码。
函数式编程基础
lodash
一个函数的功能库,提供了对数组、数字、对象、字符串、函数等操作的一些方法。
这里要重点注意 lodash/fp,这是一个 FP 样式友好的模块,它不会长生副作用。
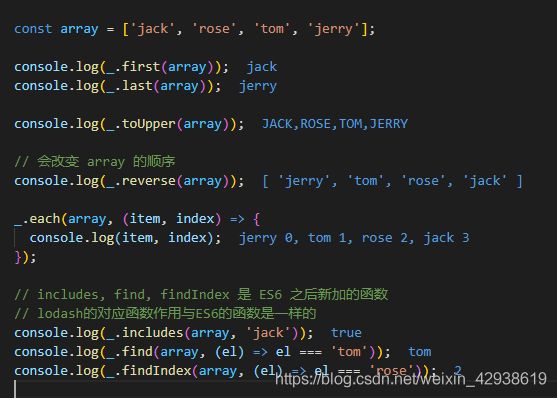
lodash 的一些功能展示如下:
// 演示 lodash
// first / last / toUpper / reverse / each / includes / find / findIndex
const _ = require('lodash');
const array = ['jack', 'rose', 'tom', 'jerry'];
console.log(_.first(array)); // jack
console.log(_.last(array)); // jerry
console.log(_.toUpper(array)); // JACK,ROSE,TOM,JERRY
// 会改变 array 的顺序
console.log(_.reverse(array)); // [ 'jerry', 'tom', 'rose', 'jack' ]
_.each(array, (item, index) => {
console.log(item, index);
});
// jerry 0
// tom 1
// rose 2
// jack 3
// includes, find, findIndex 是 ES6 之后新加的函数
// lodash的对应函数作用与ES6的函数是一样的
console.log(_.includes(array, 'jack')); // true
console.log(_.find(array, (el) => el === 'tom')); // tom
console.log(_.findIndex(array, (el) => el === 'rose')); // 2
效果截图:
纯函数
纯函数的概念和特点
纯函数的概念和特点有以下三点:
-
相同的输入永远会得到相同的输出,并且没有任何可观察的副作用。即,保持了函数的幂等性.
纯函数就像是数学中的函数,可以用 y = f ( x ) y = f(x) y=f(x) 来描述 输入 x x x 与 输出 y y y 之间的关系。
数组中
slice和splice分别对应了纯函数和不纯函数:-
slice: 方法返回一个新的数组对象,这一对象是一个由 begin 和 end 决定的原数组的浅拷贝(包括 begin,不包括 end)。原始数组不会被改变。 -
splice: 方法通过删除或替换现有元素或者原地添加新的元素来修改数组,并以数组形式返回被修改的内容。此方法会改变原数组。
let array = [1, 2, 3, 4, 5]; console.log(array.slice(0, 3)); // [ 1, 2, 3 ] console.log(array.slice(0, 3)); // [ 1, 2, 3 ] console.log(array.slice(0, 3)); // [ 1, 2, 3 ] // 结果输出相同,证明slice是纯函数 console.log(array.splice(0, 3)); // [ 1, 2, 3 ] console.log(array.splice(0, 3)); // [ 4, 5 ] console.log(array.splice(0, 3)); // [] // 结果输出改变,证明splice不是纯数组 -
-
函数式编程不会保留计算中间的结果,所以状态是不可变的(无状态的)
-
刻意把一个函数的执行结果交给另一个函数去处理(高阶函数)
好处
-
可缓存
因为纯函数对相同的输入始终有相同的结果,所以可以吧纯函数的结果缓存起来
如:若是一个函数执行起来非常耗时,并且又是一个纯函数,那么再知道给予相同的输入会有相同的输出的前提条件下,就可以将这个函数结果存在一个变量里面,等到下次调用时使用。
lodash 同样也提供了一个帮助函数去执行这个操作——
memoize案例使用:
const _ = require('lodash'); function getArea(r) { // 只会打印一遍 console.log(r); return Math.PI * r ** 2; } const areaWithMemoize = _.memoize(getArea); // 结果是从 memoize 中缓存拿出来的 console.log(areaWithMemoize(4)); console.log(areaWithMemoize(4)); console.log(areaWithMemoize(4));-
模拟一个 memoize 函数
注:memoize 是 DP 的关键思想之一。
function getArea(r) { console.log(r); return Math.PI * r ** 2; } // 模拟 memoize 方法的实现 function memoize(pureFunc) { let cache = { }; return function () { // 将 arguments 为字符串作为主键 let key = JSON.stringify(arguments); // 如果 值 已经计算过了,则直接返回值 // 或者返回 调用函数后返回的值 cache[key] = cache[key] || pureFunc.apply(pureFunc, arguments); return cache[key]; }; } const areaWithMemoize = memoize(getArea); console.log(areaWithMemoize(4)); console.log(areaWithMemoize(4)); console.log(areaWithMemoize(4));
-
-
可测试
因为纯函数的结果是可预测的,因此测试起来就很方便
-
并行处理
-
在多线程环境下操作共享的内存可能会出现以外的情况
操作共享内存可能会修改某一共享值,导致同样的函数会产生不同的计算结果
-
纯函数不需要访问共享的内存数据,所以可以在并行环境下任意运行纯函数(Web Worker)
-
副作用
回顾一下纯函数的定义:相同的输入永远会得到相同的输出,并且没有任何可观察的副作用。
上文的 splice 是一个非纯函数的案例,下面也提供一个比较常见的非纯函数的写法:
let minAge = 18;
// 非纯函数
function checkAge(age) {
return age >= minAge;
}
checkAge(18); // true
minAge = 50;
checkAge(20); // false
checkAge() 依赖于外部的状态,尽管调用 checkAge() 时所提供的参数是一样的,但是因为修改了 minAge,所以第二次调用的结果与第一次就不一致了。
这就不满足纯函数的定义:相同的输入永远会得到相同的输出。
因此,会让函数变为非纯函数的因素,就是副作用。
将其改造成纯函数也很简单:
// 纯函数,硬代码(hard code) 后续会通过柯里化解决
function checkAge(age) {
let minAge = 18;
return age >= minAge;
}
checkAge(18); // true
checkAge(20); // true
副作用的来源:
- 配置文件
- 数据库
- 获取用户的输入
- …
所有外部的交互都有可能产生副作用,副作用会带来以下隐患:
- 使函数通用性、扩展性和重用性下降
- 给程序中带来安全隐患
- 从而给程序带来不确定性
但是,副作用是不可能完全禁止的,只能尽可能地在可控范围内发生。
柯里化
柯里化可以用来解决 硬编码(hard code) 的问题。
首先,先对上一个模块中的 checkAge 进行重构
-
将 硬代码 改为形参,将函数改为普通的纯函数
// 此时函数已经变成了纯函数 function checkAge(min, age) { return age >= min; } console.log(checkAge(18, 20)); // true console.log(checkAge(18, 24)); // true console.log(checkAge(22, 24)); // true虽然这时的函数已经变成了纯函数,不过也带来了代码重复性的问题。
回顾一下之前闭包的案例,这里可以用闭包的思维解决这个问题。
-
使用闭包的思想解决问题
// 理由闭包暂时存储 min // 这也是使用了 函数的柯里化 这一概念 function checkAge(min) { return function (age) { return min <= age; }; } const checkAge18 = checkAge(18); const checkAge22 = checkAge(22); console.log(checkAge18(20)); // true console.log(checkAge18(24)); // true console.log(checkAge22(24)); // true -
总结
函数的 柯里化(Currying)的定义是:
- 当一个函数有多个参数的时候,先传第一部分的参数去调用它(这部分的函数永远不会变)
- 然后返回一个函数,去接受剩余的参数,并返回结果
lodash 中的柯里化方法
即 _.curry(func)。
-
功能
创建一个函数,该函数接收一个或多个 func 的参数。
如果 func 所需要的参数都被提供,则执行 func 并返回执行结果。否则继续返回该函数,并等待接受剩余的参数
-
参数
需要柯里化的函数
-
返回值
柯里化后的函数,最终是一个一元函数
例子:
const _ = require('lodash');
function getSum(a, b, c) {
return a + b + c;
}
// 将多元函数转化为一个一元函数
const curried = _.curry(getSum);
console.log(curried(1, 2, 3)); // 6
console.log(curried(1)(2, 3)); // 6
console.log(curried(1, 2)(3)); // 6
console.log(curried(1)(2)(3)); // 6
首先先了解一下,上文的案例中,curried(1, 2) 和 curried(1) 的返回值——是一个新的函数去准备接受新的参数。因此,它可以逐次地将函数扁平化,从多元函数最终转为一元函数。
柯里化方法案例
一个视频中的,一个自己结合之前的开发总结的
柯里化案例 1
即复用 Regex,随后利用复用的 Regex 进行再一次的封装,最终的封装出来的一个函数是寻找数组中是否有空的字符串:
// ''.match(/s+/g);
// 封装 match 方法
const _ = require('lodash');
// 封装正则和字符串的 match
const match = _.curry(function (reg, str) {
return str.match(reg);
});
// 生成两个正则表达式的封装函数,一个找到是否有空字符串,一个找到是否有数字
const haveSpace = match(/s+/g);
const haveNumber = match(/\d+/g);
console.log(haveSpace('helloworld')); // false
console.log(haveNumber('abc')); // false
// 进行进一步的组装,这次将过滤器和正则结合起来,组合出来的功能是找到某些符合特定需求的元素
const filter = _.curry(function (func, array) {
return array.filter(func);
});
// 这里已经能够看到复用性了
console.log(filter(haveSpace, ['john', '']));
// 再进一步组装
const findSpace = filter(haveSpace);
console.log(findSpace(['john', '']));
柯里化案例 2
对于前端来说,验证也是蛮重要的,我觉得函数柯里化对于写多重验证来说也挺方便的:
// 有一个const文件存储所有的正则表达式
const VALID_DATE =
/^(?:(?:31(\/|-|\.)(?:0?[13578]|1[02]))\1|(?:(?:29|30)(\/|-|\.)(?:0?[13-9]|1[0-2])\2))(?:(?:1[6-9]|[2-9]\d)?\d{2})$|^(?:29(\/|-|\.)0?2\3(?:(?:(?:1[6-9]|[2-9]\d)?(?:0[48]|[2468][048]|[13579][26])|(?:(?:16|[2468][048]|[3579][26])00))))$|^(?:0?[1-9]|1\d|2[0-8])(\/|-|\.)(?:(?:0?[1-9])|(?:1[0-2]))\4(?:(?:1[6-9]|[2-9]\d)?\d{2})$/g;
const VALID_EMAIL = /^([a-zA-Z0-9._%-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,6})*$/;
const VALID_PWD =
/(?=(.*[0-9]))((?=.*[A-Za-z0-9])(?=.*[A-Z])(?=.*[a-z]))^.{8,}$/;
const VALID_USRNAME = /^[a-z0-9_-]{3,16}$/;
// 其他的验证正则...
// 以前常见的写法
// function validUsrname (usrname) {
// return usrname.match(VALID_USRNAME);
// }
// 对于其他更多的验证,即返回更多的 var.match(regex) 的语法
const _ = require('lodash');
// 使用 柯里化函数的写法
const match = _.curry(function (reg, str) {
return reg.test(str);
});
// 作为测试的函数就只需要一行,传入合适的正则即可,确实能够减少以部分的代码量
// dd/mm/yyyy, dd-mm-yyyy or dd.mm.yyyy
const verifyDate = match(VALID_DATE);
// 1 小写字母, 1 大写字母, 1 数字, 至少 8 个字符长度
const verifyPwd = match(VALID_PWD);
// 允许有 - 和 _,3-16长度
const verifyUsername = match(VALID_USRNAME);
const verifyEmail = match(VALID_EMAIL);
// 其他的验证,例如说 validInput,validNumber,validLocation,validCountry 等,这些都是可以根据业务需求扩展的
console.error(verifyDate('02-11-2021'));
console.error(verifyEmail('[email protected]'));
console.error(verifyPwd('1ABbcde23'));
console.error(verifyUsername('goldena_archer'));
通过两个案例已经能明显感知到,柯里化最大的用途在于有一个固定的 Base 的前提下,可以声明一个函数存储这个 base function,随后再去调用 base function 进行计算。
柯里化方法原理模拟
通过上面的学习,我们知道了柯里化有以下的特点:
-
接收一个 需要被柯里化处理的函数 作为参数
-
返回一个新的函数
至此,基础的骨架就有了:
function curry(func) { return function () { }; }顺着这个思路,继续往里面填充血肉
-
返回的函数需要在调用的时候接收参数,而这个参数的数量是不固定的
所以,在函数的内部需要判断一下获取的参数与被柯里化的函数中的形参数量是否一致
展开参数可以用 ES6 的新语法:spread operator & rest parameters(
...) 去实现,即:function(...args) {}这时候就会出现两种情况:
-
当 实参的个数 >= 形参的个数时
直接执行原函数,并且返回值
-
当 实参的个数 < 形参的个数时
这里面又存在两个情况:当 实参的个数 >= 形参的个数时 和 当 实参的个数 < 形参的个数时
这个看起来是不是有点眼熟?
回顾一下递归的原理:一个函数重复调用自己。
所以,柯里化也是递归的一个应用案例
这里的 base case 就是 实参的个数 >= 形参,所以 当 实参的个数 < 形参的个数时 就会继续调用自己。
其中需要注意的就是
curriedFn()中,参数的传递方法。这里是用(...args.concat(Array.from(arguments)))实现的,现在来逐步分解。arguments是当前调用传进来的参数,是伪数组类型,所以需要是用Array.from()转化为数组args是之前传进来存储在起来的参数,是数组类型,可以使用concat()函数去合并另一个数组后,返回一个新的数组args.concat(Array.from(arguments)是数组类型,而curriedFn()接收的是具体的值,所以需要用 展开操作符(...) 去展开数组
实现代码:
function getSum(a, b, c) { return a + b + c; } function curry(func) { // 为了方便递归,这里将匿名函数改为常规函数,用来自我调用 return function curriedFn(...args) { // args 这里是实际调用匿名函数是传来的实参 // func.length 属性指明函数的形参个数 if (args.length < func.length) { // 返回一个新的函数让 之后的调用去使用 return function () { // 首先,它需要调用外部的匿名函数,如果调用匿名函数时的 形参与实参 数量相等,则跳直接执行被柯里化的函数 // 其次,如果数量不相等的话,则需要返回一个柯里化的函数,该柯里化的函数需要将之前传进来的参数与现在传进来的参数相加 // 等待下一次的调用 return curriedFn(...args.concat(Array.from(arguments))); }; } // 实参的数量大于等于形参,直接调用 func 进行操作,并且返回对应的值 // 也是递归中的 base case return func(...args); }; } const curried = curry(getSum); console.log(curried(1, 2)(3)); // 6 -
柯里化方法总结
-
柯里化可以让我们给一个函数传递比较少的参数,就能够得到一个已经记住了某些固定参数的新函数
回忆一下,
match是怎么和其他的参数搭配并返回了一个新的函数的:const match = _.curry(function (reg, str) { return reg.test(str); }); const verifyDate = match(VALID_DATE); const verifyPwd = match(VALID_PWD); // 其他 verify 函数 -
一种对函数参数的 「缓存」
-
让函数变得更灵活,让函数的粒度更小
-
将多远函数转化成一元函数,可以组合使用函数,增强复用性,并且结合产生新的、功能更强大的函数
函数组合
纯函数和柯里化很容易写出洋葱代码,即层层包裹的代码,如 h ( g ( f ( x ) ) ) h(g(f(x))) h(g(f(x)))。更加直观的例子就是,如果想要从数组中获取最后一个元素,再将其转换成大写字母,那么它的调用是这样的:_.toUpper(_.first(_.reverse(array)))。
函数组合就可以解决这个问题——它可以将细粒度的函数重新组合,生成一个新的函数。
管道
即进行连续传参,实现了内存节省、代码优化的需求。
我之前在 JavaScript 中 reduce 及 6 个使用案例 中也列举过 pipeline 的案例,当时是用 reduce() 实现的:
function increment(input) {
return input + 1;
}
function decrement(input) {
return input - 1;
}
function double(input) {
return input * 2;
}
function halve(input) {
return input / 2;
}
// 其他的文件里面可以将 pipeline 作为一个常量进行抽离
const pipeline = [increment, double, decrement];
// 另一个函数中返回 pipeline 的操作值,以前可能要用 arguments 去获取一个伪数组,然后再通过循环去调用 pipeline 里的函数,通过 reduce 代码就能简洁很多
function processPipeline(pipeline, initialValue) {
return pipeline.reduce((accumulator, currentFunc) => {
return currentFunc(accumulator);
}, initialValue);
}
// 某处有数据需要进入 pipeline
const fakeData = [1, 3, 5, 7, 9];
// 处理数据
fakeData.map((val) => processPipeline(pipeline, val)); // [1.5, 3.5, 5.5, 7.5, 9.5]
其逻辑就是将一个复杂的函数拆分成多个易于理解的函数,从而可以完成拼装、组合、提高复用性。
这也就是函数组合的概念。
函数组合的概念及初级应用案例
函数组合(compose)——如果一个函数要经过多个函数处理才能得到最终值,这个时候就可以把中间过程的函数合并成一个函数。
对于单独的函数来说,它就像是一个个的管道,每个数据经过一节管道被处理后就得到了最终的结果。
需要注意的是,与 reduce() 中的案例,即 从左往右 执行不一样,函数组合的默认是 从右往左 执行的。
以下是一个基本引用的演示:
// compose 演示
function compose(f, g) {
return function (val) {
// 此刻依旧是洋葱代码
return f(g(val));
};
}
// 新建两个管道函数
function reverse(arr) {
return arr.reverse();
}
function first(arr) {
return arr[0];
}
// 顺序要求是:先执行 reverse,再执行 first
// 这样才能获得 last——翻转后数组中第一个元素,就是原数组最后一个元素
const last = compose(first, reverse);
console.log(last([1, 2, 3, 4, 5])); // 5
这个时候的确会觉得很麻烦,如果只是想要获得数组中最后一个元素,那么直接用 arr[arr.length - 1] 比写这么多组合要方便很多。
但是这里只是一个基础的案例,更加复杂的应用可以想象一下要对用户的数据进行过滤、处理、清洗。有些业务需求的顺序可能是药先过滤再处理,也有一些可能要先处理,再过滤。如果依旧针对功能单独写函数的话,势必会造成代码的冗余以及增加后期维护的困难。
刨除其他的处理逻辑,先写好过滤和处理的函数,最后根据需求重新组合,代码能够干净很多,开发和维护的效率都可以进一步的提升。
Lodash 中的组合函数
lodash 中有两个组合函数,flow() 和 flowRight(),两个函数都可以用来组合多个函数,其最大区别就在于执行的方向——其实 reduce() 也有 reduceRight()。
两组函数中的第一个都是默认从左到右执行,而 xxxRight() 则是从右到左执行。数组中的reduce() 用的比较多,而函数组合中 flowRight() 用的比较多。
以下是 flowRight() 使用的案例:
// lodash 中 _.flowRight() 的案例
const _ = require('lodash');
const reverse = (arr) => arr.reverse();
const first = (arr) => arr[0];
const toUpper = (str) => str.toUpperCase();
// 获取数组中最后一个函数,并将其转化成大写
const f = _.flowRight(toUpper, first, reverse);
console.log(f(['hello', 'world', 'jack']));
是不是比上一个演示案例要简单干净很多了,看起来就不再是洋葱式地嵌套函数了。
组合函数原理模拟
首先,flowRight 有以下几个特性:
- 参数不固定
- 参数都是纯函数
- 返回值也是一个函数
- 返回值需要接受一个参数
根据以上要求,先写出第一个版本的代码
// 参数不固定,所以用 ... 展开args
function compose(...args) {
// 返回值也是一个函数,并且需要接受一个参数
return function (value) {
return args.reverse().reduce((accum, func) => {
return func(accum);
}, value);
};
}
const reverse = (arr) => arr.reverse();
const first = (arr) => arr[0];
const toUpper = (str) => str.toUpperCase();
// 获取数组中最后一个函数,并将其转化成大写
const f = compose(toUpper, first, reverse);
console.log(f(['hello', 'world', 'jack'])); // jack
实现的效果是一样的,不过这样的代码结构看起来有点乱。下面用箭头函数和 reduceRight 来重新实现,清理一下代码:
const reverse = (arr) => arr.reverse();
const first = (arr) => arr[0];
const toUpper = (str) => str.toUpperCase();
// 自动格式化后成这样了,应该也是不难理解的
const compose =
(...args) =>
(value) =>
args.reduceRight((accum, func) => func(accum), value);
const f = compose(toUpper, first, reverse);
console.log(f(['hello', 'world', 'jack']));
注意,箭头函数不能在申明前被调用,所以总是需要写在被调用的上方。即,先定义,再调用。
函数组合-结合律
结合律(associativity): ( x × y ) × z = x × ( y × z ) (x \times y) \times z = x \times (y \times z) (x×y)×z=x×(y×z),意指在一个包含有二个以上的可结合运算子的表示式,只要算子的位置没有改变,其运算的顺序就不会对运算出来的值有影响。
依旧以上面的函数为例:
const _ = require('lodash');
// 使用lodash里面的函数
const f = _.flowRight(_.toUpper, _.first, _.reverse);
// 以下输出结果都是 JACK
// const f = _.flowRight(_.flowRight(_.toUpper, _.first), _.reverse);
// const f = _.flowRight(_.toUpper, _.flowRight(_.first, _.reverse));
console.log(f(['hello', 'world', 'jack'])); // JACK
函数组合-调试
如果函数出问题了,应该如何进行调试?
以下面的代码为例:
const _ = require('lodash');
// 目标:
// NEVER SAY DIE --> never-say-die
// 需要函数:
// 大写转小写
// ' ' 转 '_'
// 柯里化函数以便调用
// 注意:原生的函数需要两个值,而在 flowRight 中,上一个函数会返回 1 个值给下一个函数去操作
const split = _.curry((sep, str) => _.split(str, sep));
const join = _.curry((sep, array) => _.join(array, sep));
// split(' ') 已经被柯里化了,所以会返回结果给 _.toLower 去调用
const f = _.flowRight(join('-'), _.toLower, split(' '));
console.log(f('NEVER SAY DIE')); // n-e-v-e-r-,-s-a-y-,-d-i-e
这时候就会发现实际结果 n-e-v-e-r-,-s-a-y-,-d-i-e 和 预期结果 never-say-die 是不一样的,那就需要一个能够排错的方法。
-
实现一个可以打印结果的日志功能
回顾一下
flowRight的调用的实现:调用一个函数,将运行结果返回给另一个函数去调用。现在先简单的将返回值输出,看一下究竟是哪里出错了。const _ = require('lodash'); const split = _.curry((sep, str) => _.split(str, sep)); const join = _.curry((sep, array) => _.join(array, sep)); // 新增加的 log 日志 const log = (val) => { console.log(val); // 需要把数据传递给下一个数据 return val; }; // 在调用 split 后输出 const f1 = _.flowRight(join('-'), _.toLower, log, split(' ')); // 在调用 toLower 后输出 const f2 = _.flowRight(join('-'), log, _.toLower, split(' ')); f1('NEVER SAY DIE'); // [ 'NEVER', 'SAY', 'DIE' ] f2('NEVER SAY DIE'); // never,say,die可以看出,
f1('NEVER SAY DIE');的返回值[ 'NEVER', 'SAY', 'DIE' ]是没有问题的,问题出在了f2('NEVER SAY DIE');的返回值上。 -
调试并修改代码
never,say,die是一个字符串,对字符串使用join(-),就在每个字符之间加入分隔符-,就会产生上文输出的结果:n-e-v-e-r-,-s-a-y-,-d-i-e。这个问题可以通过调用
map来解决,因为map调用后会返回一个数组。但是因为map同样会接收两个参数,所以也需要对map进行柯里化操作。并且在调用的时候,将_.toLower作为map所需要的参数传进去:const _ = require('lodash'); const split = _.curry((sep, str) => _.split(str, sep)); const join = _.curry((sep, array) => _.join(array, sep)); const map = _.curry((fn, arr) => _.map(arr, fn)); // log代码先隐藏 const f = _.flowRight(join('-'), _.map(_.toLower), split(' ')); // NEVER-SAY-DIE此时已经获得了正确的结果,但是又有了一个新的问题,如果一直都打日志的话,那么就难以分辨究竟是在哪个函数之后调用的,所以下一步,要对日志进行优化。
-
日志函数的优化
对此,在基础的应用之中,依旧可以使用柯里化的概念,在调度的时候传进一个参数指示当前对象在哪里被调用的。
// 基础函数与上面一致 // 重命名 log 为 trace const log = _.curry((tag, val) => { console.log(tag, val); return val; }); const f = _.flowRight( join('-'), trace(' map 之后'), // map 之后 [ 'never', 'say', 'die' ] map(_.toLower), trace(' split 之后'), // split 之后 [ 'NEVER', 'SAY', 'DIE' ] split(' ') ); //never-say-die这样,从日志上就能够获取执行的函数所在的位置了。
Lodash-fp 模块
Lodash 中的 fp 模块提供了使用的对 函数式编程友好 的方法:包括提供了有以下三个特性的不可变方法:
-
auto-curried,自动柯里化
-
iteratee-first
iteratee 是一个可组合的,对可被连续执行的函数执行的抽象,像是
flowRight()中可传输的部分,这一个流程就是 iteratee如果英文比较好的话可以试着理解这一段:
In functional programming, an iteratee is a composable abstraction for incrementally processing sequentially presented chunks of input data in a purely functional fashion.
-
data-last(数据最后)
另外,根据 Lodash 的官方文档:
Reverses array so that the first element becomes the last, the second element becomes the second to last, and so on.
Note: This method mutates array and is based on Array#reverse.
翻译内容大概为:
翻转函数的定义,以及 注意 当前函数会改变数组本身,并且是根据
Array.prototype.reverse()而实现的
所以,Lodash 的函数并不能保证它是一个纯函数,但是 Lodash/fp 中的函数是纯函数。
Lodash-fp 与 Lodash 之间的对比
-
data-last
lodash 与 lodash/fp 的参数方法是相反的:
lodash 的传参顺序以 数据为先,操作为后
lodash/fp 的传参顺序以 操作为先,数据为后
如:

案例代码:
const _ = require('lodash'); const fp = require('lodash/fp'); const testArr = ['a', 'b', 'c', 'd']; const lodashMapResult = _.map(testArr, _.toUpper); lodashMapResult; // [ 'A', 'B', 'C', 'D' ] const fpMapResult = fp.map(fp.toUpper, testArr); fpMapResult; // [ 'A', 'B', 'C', 'D' ] -
auto-curried
柯里化的定义就是将多元函数降解到一元函数,之前也是用过很多次了:
const split = _.curry((sep, str) => _.split(str, sep));。但是,_.split没有办法自动被柯里化,以柯里化的方式调用会报错: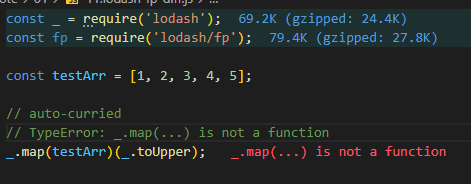 s
s另一方面,
lodash/fp中的函数就会被自动柯里化: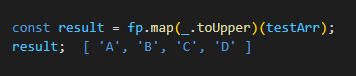
案例代码:
const _ = require('lodash'); const fp = require('lodash/fp'); const testArr = ['a', 'b', 'c', 'd']; // TypeError: _.map(...) is not a function // _.map(testArr)(_.toUpper); // auto-curried const result = fp.map(_.toUpper)(testArr); result; -
iteratee-first
感觉就是上面一直用的函数组合
-
案例
这里将上面实现的
NEVER SAY DIE转为never-say-die的案例重新实现一遍,这是源代码:const _ = require('lodash'); const split = _.curry((sep, str) => _.split(str, sep)); const join = _.curry((sep, array) => _.join(array, sep)); const map = _.curry((fn, arr) => _.map(arr, fn)); const f = _.flowRight(join('-'), map(_.toLower), split(' ')); console.log(f('NEVER SAY DIE'));下面是使用 lodash/fp 进行的实现。其中,因为 split, join, map 在 fp 之中的调用顺序是在最后的,并且 fp 中的函数都是自动柯里化的,因此 3 个手动实现的 split, join, map 函数都可以删掉了
const fp = require('lodash/fp'); const f = fp.flowRight(fp.join('-'), fp.map(fp.toLower), fp.split(' ')); console.log(f('NEVER SAY DIE'));
由此可以看出,在使用 lodash 已经有的函数的前提下,用 fp 进行逻辑的实现会比用原生 lodash 更加的简洁
lodash 会变异数组,而 fp 不会
之前已经提到了 lodash 的官方文档说使用 reverse 会变异数组,接下来还是以翻转数组为例,更加直观的了解一下这个特性
const fp = require('lodash/fp');
const _ = require('lodash');
const testArr = ['a', 'b', 'c', 'd'];
console.log(fp.reverse(testArr)); // [ 'd', 'c', 'b', 'a' ]
testArr; // [ 'a', 'b', 'c', 'd' ]
console.log(_.reverse(testArr)); // [ 'd', 'c', 'b', 'a' ]
testArr; // [ 'd', 'c', 'b', 'a' ]

map 方法的小问题
先用 map 完成一个将字符串转为整形的功能:
const numArray = ['50', '22', '10'];
const lodashNums = _.map(numArray, parseInt);
lodashNums; // [ 50, NaN, 2 ]
会造成这个异常的原因需要看一下 map 函数的使用:

第三段,由 Creates 这个单词开始的这段话:
Creates an array of values by running each element in collection thru iteratee. The iteratee is invoked with three arguments:
(value, index|key, collection).
也就是说,lodash 中的 map 实际上是会需要传 3 个参数给对应的迭代函数(iteratee):
- value,值
- index|key,索引或(数组) 是 键(对象)
- collection,被迭代的集合
按照这三个参数,显示调用 parseInt 的方法为:
// 以数组为参照物:
// const numArray = ['50', '22', '10'];
parseInt('50', 0, array);
parseInt('22', 1, array);
parseInt('10', 2, array);
通过查看 MDN 中 parseInt() 的介绍我们可以知道,parseInt 最多可以接受两个参数:
parseInt(string)
parseInt(string, radix)
其中,radix 指的就是进制,根据文档中说明,它的值必须要在 2 与 36 之间。传 0 似乎是特殊案例,就是不做处理,依旧返回 10 进制的值,但是对于不在 2 到 36 之间的数值就会返回一个 NaN。
使用 fp 中的 map 就不会产生这个问题,因为它只接受一个参数,也就是当前要处理的数据:

所以使用 fp 就不会造成这个问题。
完整的演示代码在这里:
const fp = require('lodash/fp');
const _ = require('lodash');
const numArray = ['50', '22', '10'];
const lodashNums = _.map(numArray, parseInt);
lodashNums; // [ 50, NaN, 2 ]
const fpMap = fp.map(parseInt, numArray);
fpMap; // [ 50, 22, 10 ]
Point-free
Point Free 是一种编程风格,也是关于函数的组合,概念是 把数据处理的过程,定义成一种与参数无关的合成运算。不需要用到代表数据的那个参数,只要把一些简单的运算步骤合成在一起即可。
总结一下就是:不使用所要处理的值,只合成运算过程。
以上概念定义来自 阮一峰的网络日志-Pointfree 编程风格指南
之前大部分的案例都是应用这种变成风格,例如说用了很多次的 flowRight:
const f = fp.flowRight(fp.join('-'), fp.map(fp.toLower), fp.split(' '));
-
案例 1
都是为了将字符串从
Hello World转化为hello_world// 非 point free 模式 function convertStr(str) { return str.toLowerCase().replace(/\s+/g, '_'); } const nonfpStr = convertStr(sampleStr); nonfpStr; // point free 模式 // 合成过程中没有使用要处理的值——没有传进来字符串 // 只合成了运算过程——组合 replace 和 toLower const fp = require('lodash/fp'); const f = fp.flowRight(fp.replace(/\s+/g, '_'), fp.toLower); const fpStr = f(sampleStr); fpStr;
-
案例 2
注意:函数名需要自证其用,不要取无意义的名字。
这个函数的目的是将一个字符串中的首字母提取出来,并转化成大写,用
.作为分隔符。即:world wide web -> W.W.W要执行的步骤:
- 先用空格去分割字符串
- 将所有的单词转化为大写
- 获取所有单词的第一个字符
- 使用
.连接字符
这里依旧会使用
flowRight去执行,所以执行顺序是从右往左的。const www = 'world wide web'; const firstLetterToUpper = fp.flowRight( fp.join('.'), fp.map(fp.first), fp.map(fp.toUpper), fp.split(' ') ); const result = firstLetterToUpper(www); result; // W.W.W注意,这里调用了两次循环,那么就会造成一些性能上的损耗。所以下一步是想办法将结合起来:使用
flowRight去结合first和toUpper优化后的代码:
const firstLetterToUpper = fp.flowRight( fp.join('.'), fp.map(fp.flowRight(fp.first, fp.toUpper)), fp.split(' ') );
Functor(函子)
学习函子的目的是为了将副作用局选在一个可控的范围之内,也可以利用函子去处理异常处理、异步操作等。
函子是一个通过普通的对象来实现的,特殊的容器(包含值与值的变形关系,即函数)。该对象具有 map 方法,map 方法可以运行一个函数,对值进行处理(变形关系)。
-
一个基础的函子
这是一个基础的函子:
// functor class Container { constructor(val) { // 以 _ 开头的变量,其定义都是私有函数,永远也不对外暴露 this._val = val; } // 暴露一个map方法 map(fn) { return new Container(fn(this._val)); } } // 先执行 x+1 // 再执行 x**2 const functor = new Container(5).map((x) => x + 1).map((x) => x ** 2); // 返回值为一个新的函子对象 functor; // Container { _val: 36 }这时候就会发现,每一次对函子操作都要做一次
new Container()的操作,有些麻烦又容易与面向对象混淆。因此,下一步就对构造函数进行优化。对此,可以创建一个静态函数去返回一个新的 Container 对象,同时,在 map 函数中也可以使用新创建的静态方法去进行返回。
-
优化 map 函数和对构造函数的调用
class Container { // 返回一个函子对象 static of(val) { return new Container(val); } constructor(val) { // 以 _ 开头的变量,其定义都是私有函数 this._val = val; } // 暴露一个map方法 map(fn) { return Container.of(fn(this._val)); } } const functor = Container.of(6) .map((x) => x + 1) .map((x) => x ** 2); functor; // Container { _val: 49 }因为 map 函数返回了一个新的函子对象,所以可以不停的使用链式调用去执行。
这个时候就又出现一个问题了,如果传递的是一个不合法的值,会发生什么事情?
const functor = Container.of(null).map((x) => x.toUpperCase()); // TypeError: Cannot read property 'toUpperCase' of null这就破坏了纯函数的特性——当传进去的参数为 null 的时候,程序抛出了一场,没有继续执行,也因此就没有办法返回一个值。
函子总结
- 函数式编程的运算不直接操作值,而是由函子完成
- 函子就是一个实现了 map 契约的对象
- 我们可以吧函子想象成一个盒子,这个盒子里封装了一个值
- 想要处理盒子中的值,我们要给盒子的 map 方法传递一个处理之的函数(纯函数),由这个函数来对值进行处理最终 map 方法返回一个包含新值的盒子(函子)
Maybe 函子
如上一个案例所示,在编程的过程中可能会遇到很多的错误,因此也需要对这些错误进行相印的处理。而 Maybe 函子的左右,就是处理空值异常,将副作用降低到可控的范围之内。
接下来,就按照函子的逻辑,对 Maybe 函子进行功能增强:
- 需要增加一个判断空值的函数
- 当值传进来是空的时候,返回一个值为
null的 Maybe 函子
通过这样的实现,就可以将副作用降低到最小的程度——传进来的值可能依旧是不合法的 null 或 undefined,但是返回值是一个可预计的,值为 null 的 Maybe 函子。
class Maybe {
static of(val) {
return new Maybe(val);
}
constructor(val) {
this._val = val;
}
map(fn) {
return this.isNothing() ? Maybe.of(null) : Maybe.of(fn(this._val));
}
isNothing() {
return this._val === null || this._val === undefined;
}
}
// 测试代码
const maybe1 = Maybe.of('hello world').map((x) => x.toUpperCase());
maybe1; // Maybe { _val: 'HELLO WORLD' }
const maybe2 = Maybe.of(null).map((x) => x.toUpperCase());
maybe2; // Maybe { _val: null }
到这一步,其实还没有结束。
虽然对不合法的空值已经进行了处理,但是目前是没有办法准确判断究竟是在什么地方传进了空值:
const maybe = Maybe.of('hello world')
.map((x) => x.toUpperCase())
.map((x) => null)
.map((x) => x.split(' '));
maybe; // Maybe { _val: null }
这个问题,就可以被 Either 函子所解决。
Either 函子
Either 顾名思义,就是两者中的一个情况,类似于 if...else... 的处理,它的作用是进一步减少异常处理对函数造成的不可控性,将副作用局限在一个可控的范围。
Either 函子是二选一的结构,所以需要定义一个 Left 和一个 Right 去做判断。
-
Either 函子的实现
第一步先从这两个函子开始实现。
-
Left 函子
注意,这个函子的 map 函数不太一样,它是直接返回
thisclass Left { static of(val) { return new Left(val); } constructor(val) { this._val = val; } // 这个 map 函数有些特殊 map(fn) { return this; } } -
Right 函子
几乎与 Left 函子一样,不过有一些细微之处需要修改
class Right { static of(val) { return new Right(val); } constructor(val) { this._val = val; } // 这个 map 函数有些特殊 map(fn) { return Right.of(fn(this._val)); } }
Left 函子与 Right 函子的结构与最基础的 Container 一致,上面是出于方便理解的方法重新写了两遍,但是实际上用
extends关键字进行继承能够更加的高效:class Container { static of(val) { return new Container(val); } constructor(val) { this._val = val; } map(fn) { return Container.of(fn(this._val)); } } class Left extends Container { static of(val) { return new Left(val); } map(fn) { return this; } } class Right extends Container { static of(val) { return new Right(val); } map(fn) { return Right.of(fn(this._val)); } }此时测试的结果是:
const r = Right.of(12).map((val) => val ** 2); r; // Right { _val: 144 } const l = Left.of(12).map((val) => val ** 2); l; // Left { _val: 12 }这因为 Left 返回了自身的值。
-
-
Either 函子的应用
假设现在有一个任务是需要将一个字符串转化为 JSON,所以第一步先实现对 JSON 的转换。
其中,Right 函子会返回正确的值,Left 函子则用来处理错误信息
function parseJson(str) { try { return Right.of(JSON.parse(str)); } catch (e) { return Left.of({ error: e.message, }); } }则最后的调用结果如下:
const result = parseJson("{name: '张三'}"); result; // Left { _val: { error: 'Unexpected token n in JSON at position 1' } }
IO 函子
对于之前的函子来说,_value 的值是一个具体的数值,但是对于 IO 函子来说,也可以将函数作为值来处理。也就是说,将会引起副作用的函数存储到 _value 之中进行延迟处理,从而继续控制副作用,提纯函数。
-
IO 函子的基础结构
const fp = require('lodash/fp'); class IO { static of(x) { return new IO(function () { return x; }); } constructor(fn) { this._val = fn; } map(fn) { return new IO(fp.flowRight(fn, this._val)); } }在这个范例中,能够看到静态函数和 map 函数都进行了重写了。这是因为对于 IO 函子来说,需要将函数作为值来处理,将其延后操作。同样的逻辑也应用在 map 函数上,需要先运行存储在
this._val中的函数,再将其返回。 -
IO 函子的应用案例
IO 类的结构与上面一样,接下来开始案例演示:
// IO结构与上文一致 // 这里的 p 指代是 process // 这里的组合字仍然是纯函数 const io = IO.of(process).map((p) => execPath); io; // IO { _val: [λ] } // 如果有报错,会在这里执行时才会出现 console.log(io._val()); // C:\Program Files\nodejs\node.exe可以看到,这个 IO 函子返回的就是一个函数。
步骤分解:
-
IO.of(process)这里就将 process 对象用函数进行包裹后,保存到了构造函数之中。因此在调用了
_val后,它返回的就是一个 process 对象。这么做我的理解是为了方便链式调用,以一个更安全的方法去提供一个包装函数(wrapper)。
-
IO.of(process).map((p) => execPath)map 函数是一个 flowRight 的组合子了,它会先行执行构造函数里的函数,将返回的值传到下一个函数里去使用。
最终返回的就是调用后的值,被函数包装后的结果。
其显式调用如下:
const processFunc = function () { return process; }; console.log(processFunc().execPath); // C:\Program Files\nodejs\node.exe第 1 点提到了,IO 函子构造函数实际上就是将 process 这个对象进行了包装,实际上返回的还是一个对象。也因此,在 map 中传递进去的函数是进行了取值操作——获取 process 中有的 execPath 属性。
-
IO 函子运用的最多的地方还是异步操作,Stack Overflow 上有一个 Haskell 的问题:「Haskell - How can I use pure functions inside IO functions?」就是关于这个问题的讨论,而且 IO 这个名字本社也挺自证其用了。
另外,其实会引起报错的地方不在组合子这里,而是实际调用的阶段。以上面的案例来说,也就是 console.log(io._val()); 这里。
因此可以做到在定义完 io 后,执行其他操作,等到要执行时再去调用 io(),这也可以进一步做到模块的分离。
IO 函子的一个问题
IO 函子最大的问题还在于嵌套,假设想模拟一个 Linux 环境中的 cat 命令——获取文件随后打印在控制台上的命令。以 IO 函子实现的方法如下:
-
实现 读取文件 和 打印函数
const readFile = function (filename) { return new IO(function () { return fs.readFileSync(filename, 'utf-8'); }); }; const print = function (val) { return new IO(function () { console.log(val); return val; }); };两个函数都返回来对应的 IO 函子,以方便后面进行连环嵌套。
-
调用函数
从理论上来说,cat 的实现是读取文件,并且将文件输出,这一点用 flowRight 实现起来非常方便。
问题就在于,应该怎么从返回的函子中获取到想要的值。
const cat = fp.flowRight(print, readFile); const res = cat('../../package.json')._val(); console.log(res); // [Function (anonymous)]这一次按照之前的套路,使用
func._val却没有办法返回一个数值,而是获得了一个函数。 -
问题解析
回顾一下 readFile 和 print 二者的调用关系:readFile 返回了一个 IO 函子给 print,随后 print 再一次返回了一个 IO 函子。
它的调用类似于:
IO(IO(value)),是一个双重嵌套。所以想要获值也需要进行双重解构:const res = cat('../../package.json')._val()._val(); console.log(res); // 一串json文件 `
在层级结构比较复杂的情况下,使用 IO 函子不可避免的就会造成取值上的困难。最后一个函子 Monad 函子可以有效地解决这个问题,可以扁平化函子解构。
Task 函子
Task 函子可以用来解决异步的回调地狱的问题,鉴于异步操作的执行比较麻烦,所以案例中使用了 Folktale 中的 task 去进行演示。
Folktale
Folktale 是一个支持函数式编程的库,其介绍中说使用 Folktale 的最大优点有三个:
- 组合性
- 更好的错误处理
- 更安全的同步,即通过 Task 来实现
它没有提供很多功能性函数,更多注重的是函数式处理的操作,如 compose, curry, Task Functor, Either Functor, Maybe Functor。
案例演示:
-
柯里化
注意,folktale 中的 curry 和 lodash 中的 curry 所接受的参数不一样,它的第一个参数是被柯里化的函数所需要的变量数量,第二个才是要被柯里化的参数。
const { curry } = require('folktale/core/lambda'); // 第一个参数是后面的函数会接受几个参数 const curried = curry(2, (x, y) => x + y); console.log(curried(1)(2)); -
compose/flowRight
起名不一样,作用是一样的,使用方法也是一样的。
const { compose } = require('folktale/core/lambda'); const { toUpper, first } = require('lodash/fp'); const composeFn = compose(toUpper, first); console.log(composeFn(['one', 'two'])); // ONE
Folktale 中的 Task 函子
现在重新回到 Task 函子,下面是案例——通过 Task 处理异步任务——进行学习。
-
实现一个阅读文件的功能的函数
会返回一个通过 task 函数调用生成的函子,这个 task 函子会接受一个
resolver作为参数,而这个resolver参数会包含运行调用 task 函子所必须的函数。// 1.0 中返回的是一个类 // 2.0 中返回的是一个函数 const { task } = require('folktale/concurrency/task'); const fs = require('fs'); const { split, find } = require('lodash/fp'); function readFile(filename) { return task((resolver) => { fs.readFile(filename, 'utf-8', (err, data) => { // 执行失败后调用的函数 if (err) resolver.reject(err); // 执行成功后调用的方法 resolver.resolve(data); }); }); }函数本身不能算是非常的困难,实质上就是返回一个 task 函数,其中 task 函数的参数是
resolver对象 ,而resolver对象包含两个属性:-
当这个函数执行成功时调用的
resolver.resolve() -
当这个函数执行失败后调用的的
resolver.reject()
-
-
调用函子去读取文件
当前函数打印的是 package.json 这个文件,这里文件夹有嵌套,不直接在根目录下,路径因此有些不同。
// 我的文件目录是这样的 // 当调用 readFile 后会返回一个 task函子,而不是直接调用 readFile('../../package.json') .run() // 执行 .listen({ // 监听当前事件状态 onRejected: (err) => { console.log(err); }, onResolved: (val) => { console.log(val); }, });函数的执行步骤分解:
-
执行读取文件的函数
也就是这行代码:
readFile('../../package.json')当调度完了
readFile之后,task 函数不会立即去执行文件的读取,而是会返回一个 task 的函子对象等待被运行 -
执行 task 函子
也就是这样代码:.run()run 才是 task 函子的指示器(indicator),告诉 task 函子应该运行写进函子中的函数了
-
处理获取
也就是下面这段代码:
.listen({ // 监听当前事件状态 onRejected: (err) => { console.log(err); }, onResolved: (val) => { console.log(val); }, });当 task 函子执行完毕之后,它会返回执行完毕后获得的数据,并且等待监听器事件传来对数据的处理。
在这里,对数据的处理是将接收到的数据输出到命令行中
这时候,命令行输出的数据就是我的整个 package.json 文件了,这里截取部分的内容:
{ "name": "personalprogress", "version": "1.0.0", "description": "A project to record personal progress.", "main": "index.js", "directories": { "example": "examples" } // ... } -
数据处理
在上一步,数据就已经全都获取了,直接在
onResolved中处理数据也可以,但是这样就不符合函数式编程的思维了。毕竟,学到现在所有的内容都是以函数优先,数据置后为核心思想。
复习回顾一下 Functor 函子的基本结构:
class Container { static of(val) { return new Container(val); } constructor(val) { this._val = val; } map(fn) { return Container.of(fn(this._val)); } }重点在于其中的 map 函数,这是我们能够执行链式调用的关键所在。作为一个函子,task 也是具有 map 函数可以被调用。
完整的调用如下:
readFile('../../package.json') .map(split('\n')) .map(find((x) => x.includes('version'))) .run() .listen({ onRejected: (err) => { console.log(err); }, onResolved: (val) => { console.log(val); }, });最终的输出结果为
"version": "1.0.0",
-
Pointed 函子
Pointed 函子 是实现了 of 静态方法的函子,上文使用的所有函子,从最基础的 Container 都实现了静态的 of 方法,所以他们都是 Pointed 函子。
of 的作用有两个:
-
避免使用 new 来创建对象
这点上文已经提到过了
-
把值放到上下文 Context 中
这就是说将值放到容器中,利用 map 来处理。
利用 map 来处理数据的概念在上一个案例,也就是 task 案例中应该已经被强调了,执行上下文又是另一个概念,这个我之前在 JavaScript 高级程序设计第四章学习笔记 笔记中也有做到,这里简述一下概念:
The execution context is the environment of a function which includes its own scope.
执行上下文 就是 一个函数包括它自己作用域的环境。
也就是说,每次调用 map 函数——每次调用 map 函数都会调用 of——创造了一个新的作用域,从而通过作用域链能够找到最近的函数去执行。
这也是 of 最主要的作用。
Monad 函子
如上文在 IO 函子的问题中提到的,一旦 IO 函子出现层级化的嵌套,对于取值来说就会造成一定程度上的困难。而 Monand 函子就是可以扁平化复杂结构的 Pointed 函子。
Monad 函子是一个函子具有 join 和 of 两个方法,并遵守一些定律的函子。
接下来就要对 IO 函子进行重构,使其能够扁平化。
之前的 IO 函子的实现代码为:
const fp = require('lodash/fp');
const fs = require('fs');
class IO {
static of(x) {
return new IO(function () {
return x;
});
}
constructor(fn) {
this._val = fn;
}
map(fn) {
return new IO(fp.flowRight(fn, this._val));
}
}
const readFile = function (filename) {
return new IO(function () {
return fs.readFileSync(filename, 'utf-8');
});
};
const print = function (val) {
return new IO(function () {
console.log(val);
return val;
});
};
接下来,在 IO 函子中实现 join 和 flatMap 函数
class IO {
// 其余部分相同
// 直接返回函子调用后的值
join() {
return this._val();
}
// 调用 map 返回一个新的IO函子,再调用 join,直接返回函子的值 而非IO函子
flatMap(fn) {
return this.map(fn).join();
}
}
join 和 flatMap 的作用在注释中已经有了,这里不再赘述。之后,只需要修改一下 cat 的调用即可:
最后的测试结果:
const cat = readFile('../../package.json').flatMap(print);
console.log(cat._val()); // 一串json文件
最后,升级版的完整案例是一个实现了和 Task 任务相似功能,当然,因为我偷懒没有实现柯里化,所以函数部分就写死了:
const fp = require('lodash/fp');
const fs = require('fs');
class IO {
static of(x) {
return new IO(function () {
return x;
});
}
constructor(fn) {
this._val = fn;
}
map(fn) {
return new IO(fp.flowRight(fn, this._val));
}
join() {
return this._val();
}
flatMap(fn) {
return this.map(fn).join();
}
}
const readFile = function (filename) {
return new IO(function () {
return fs.readFileSync(filename, 'utf-8');
});
};
const print = function (val) {
return new IO(function () {
return val;
});
};
const split = function (val) {
return new IO(function () {
return val.split('\n');
});
};
const includes = function (val) {
return new IO(function () {
return val.find((val) => val.includes('version'));
});
};
const cat = readFile('../../package.json')
.flatMap(split)
.flatMap(includes)
.flatMap(print);
console.log(cat._val()); // "version": "1.0.0",
这就是这期上了视频课后总结下来的笔记,询问了下官方可以放出来,但是必须要加来源(合十感谢)。
上完这部分的内容觉得还是学到了很多,例如说上面分享的一些来自自己之前开发经验的案例,也是在摸爬滚打之中慢慢摸到了函数式编程的门槛。本来以为自己的理解还不错了,上完课之后发现还有更好的方法,是我格局小了.jpg
一部分的内容还是源于自己的开发经验和理解,并不一定是最优解,如果你有什么不同的见解,欢迎留评,一起讨论。
课程来源:拉勾大前端高薪训练营