2、【网络编程】TCP报文段/网络字节序/主机字节序/网-主字节序转换函数
一、TCP报文段格式
TCP虽然是面向字节流的,但TCP传送的数据单元却是报文段。一个TCP报文段分为首部和数据两个部分。TCP报文段首部的前20个字节是固定的,后面有4n字节是根据需要增加的选项。TCP首部的最小长度是20字节,最大长度是60字节。
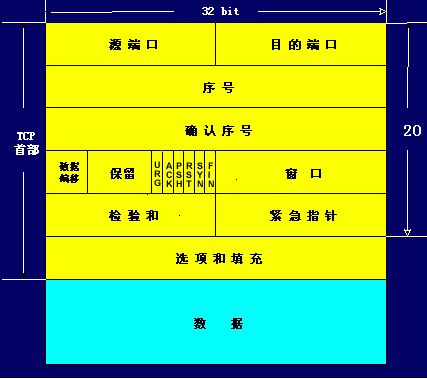
1、端口号
(1)源端口:源端口和IP地址的作用是标识报文的返回地址,占16位。
(2)目的端口:目的端口指明接收方计算机上的应用程序接口,占16位。
TCP报头中的源端口号和目的端口号同IP数据报中的源IP与目的IP唯一确定一条TCP连接。
2、序号和确认序号
序号和确认号:各占32位,是TCP可靠传输的关键部分。序号是本报文段发送的数据组的第一个字节的序号。在TCP传送的流中,每一个字节一个序号。
e.g:一个报文段的序号为300,此报文段数据部分共有100字节,则下一个报文段的序号为400。所以序号确保了TCP传输的有序性。确认号,即ACK,指明下一个期待收到的字节序号,表明该序号之前的所有数据已经正确无误的收到。确认号只有当ACK标志为1时才有效。比如建立连接时,SYN报文的ACK标志位为0。
3、数据偏移(首部长度)
占4位,由于首部可能含有可选项内容,因此TCP报头的长度是不确定的,报头不包含任何任选字段则长度为20字节,4位首部长度字段所能表示的最大值为1111,转化为10进制为15,15*32/8 = 60,故报头最大长度为60字节。首部长度也叫数据偏移,是因为首部长度实际上指示了数据区在报文段中的起始偏移值。
4、保留
占6位,为将来定义新的用途保留,现在一般置0。
5、控制标志位
URG ACK PSH RST SYN FIN,共6个,每个标志位占1位,每一个标志位表示一个控制功能。
(1)URG:紧急指针标志,为1时表示紧急指针有效,为0时则忽略紧急指针。
(2)ACK:确认序号标志,为1时表示确认号有效,为0表示报文中不含确认信息,忽略确认号字段。
(3)PSH:push标志,为1表示是带有push标志的数据,指示接收方在接收到该报文段以后,应尽快将这个报文段交给应用程序,而不是在缓冲区排队。
(4)RST:重置连接标志,用于重置由于主机崩溃或其他原因而出现错误的连接。或者用于拒绝非法的报文段和拒绝连接请求。
(5)SYN:同步序号,用于建立连接过程,在连接请求中,SYN=1和ACK=0表示该数据段没有使用捎带的确认域,而连接应答捎带一个确认,即SYN=1和ACK=1。
(6)FIN:finish标志,用于释放连接,为1时表示发送方已经没有数据发送了,即关闭本方数据流。
6、窗口
滑动窗口大小,用来告知发送端接受端的缓存大小,以此控制发送端发送数据的速率,从而达到流量控制。窗口大小时一个16bit字段,因而窗口大小最大为65535。
7、校验和
奇偶校验,此校验和是对整个的 TCP 报文段,包括 TCP 头部和 TCP 数据,以 16 位字进行计算所得。由发送端计算和存储,并由接收端进行验证。
8、紧急指针
只有当 URG 标志置 1 时紧急指针才有效。紧急指针是一个正的偏移量,和顺序号字段中的值相加表示紧急数据最后一个字节的序号。 TCP 的紧急方式是发送端向另一端发送紧急数据的一种方式。
9、选项和填充
最常见的可选字段是最长报文大小,又称为MSS(Maximum Segment Size),每个连接方通常都在通信的第一个报文段(为建立连接而设置SYN标志为1的那个段)中指明这个选项,它表示本端所能接受的最大报文段的长度。选项长度不一定是32位的整数倍,所以要加填充位,即在这个字段中加入额外的零,以保证TCP头是32的整数倍。
10、数据部分
TCP 报文段中的数据部分是可选的。在一个连接建立和一个连接终止时,双方交换的报文段仅有 TCP 首部。如果一方没有数据要发送,也使用没有任何数据的首部来确认收到的数据。在处理超时的许多情况中,也会发送不带任何数据的报文段。
二、主机字节序/网络字节序及之间的转换函数
1、主机字节序(HBO,Host Byte Order)
就是我们平常说的大端和小端模式:不同的CPU有不同的字节序类型,这些字节序是指整数在内存中保存的顺序,这个叫做主机序。l例如:intel x86结构采用小端模式,IBM power PC(非NT)采用的是大端模式。
引用标准的大端和小端的定义如下:
(1)小端就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。小端模式是最符合人的思维的字节序。
(2)大端就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。大端模式是最直观的字节序,只需要把内存地址从左到右按照由低到高的顺序写出。
【示例】
我们要将0x12345678这个数据放入以0x0000开始的内存中,则结果为:
内存地址 大端模式 小端模式
0x0000 0x12 0x78
0x0001 0x34 0x56
0x0002 0x56 0x34
0x0003 0x78 0x12
2、网络字节序(NBO,Network Byte Order)
TCP/IP协议规定,网络数据流u应该采用大端字节序,即低地址—高字节。例如:4个字节的32 bit值以下面的次序传输:首先是0~7bit,其次8~15bit,然后16~23bit,最后是24~31bit。
字节序,顾名思义字节的顺序,就是大于一个字节类型的数据在内存中的存放顺序,一个字节的数据没有顺序的问题了。所以:在将一个地址绑定到socket的时候,请先将主机字节序转换成为网络字节序,而不要假定主机字节序跟网络字节序一样使用的是Big-Endian。
【示例】
#include <stdio.h>
#include <arpa/inet.h>
int main()
{
unsigned long a = 0x12345678;
unsigned char *p = (unsigned char *)(&a);
printf("主机字节序:%0x %0x %0x %0x\n", p[0], p[1], p[2], p[3]);
unsigned long b = htonl(a); //将主机字节序转化成了网络字节序
p = (unsigned char *)(&b);
printf("网络字节序:%0x %0x %0x %0x\n", p[0], p[1], p[2], p[3]);
return 0;
}
3、IP地址、端口号的主机字节序、网络字节序之间的转换关系
以IP地址127.0.0.1为例,看看两者之间是如何转换的:
//第一步:把IP地址每一部分转换为8位的二进制数。
IP地址:127.0.0.1=01111111.00000000.00000000.00000001
//第二步:把获取的二进制数转换为十进制数作为主机字节序
主机字节序:01111111.00000000.00000000.00000001=2130706433
//第三步:然后把上面的四部分二进制数从右往左按部分重新排列,
//排列后转换为十进制数,作为网络字节序
网络字节序:00000001.00000000.00000000.01111111=16777343
以6000端口为例,看看端口号的主机字节序与网络字节序间的转换:
//端口号本身其实就已经是主机字节序了
//第一步:将端口号写为16位的二进制数,分为前8位和后8位
主机字节序:00010111 01110000 = 6000
//然后把主机字节序的前八位与后八位调换位置组成新的16位二进制数,
//这新的16位二进制数就是网络字节序的二进制表示了。
网络字节序:01110000 00010111 = 28695
4、相关函数
(1)网络字节序与主机字节序之间的转换函数
能够完成主机字节序和网络字节序转换的函数有:htonl()、htons()、ntohl()、ntohs()。其中h表示“host”,n表示“net”,l表示“long”,s表示“short”。
htonl()/htons()函数:将主机字节序转换为网络字节序,函数原型如下:
u_long PASCAL FAR htonl (u_long hostlong);
u_short PASCAL FAR htons (u_short hostshort);
ntohs()/ntohs()函数:将网络字节序转换为主机字节序,函数原型如下:
u_long PASCAL FAR ntohl (u_long netlong);
u_short PASCAL FAR ntohs (u_short netshort);
(2)其他相关函数
inet_ntoa()函数:接受一个in_addr结构体类型的参数并返回一个以点分十进制格式表示的IP地址字符串。函数原型如下:
#includeinet_aton()函数:接受一个以点分十进制格式表示的IP地址字符串转换成in_addr结构体类型的值,并存入该结构体。函数原型如下:
//利用in_addr结构体,转换完的IP字符直接存入结构体中
#includeinet_addr()函数:需要一个字符串作为其参数,该字符串指定了以点分十进制格式表示的IP地址(例如:192.168.0.16)。而且inet_addr函数会返回一个适合分配给S_addr的u_long类型的数值(即将IP地址的字符串转换为主机字节序)。函数原型如下:
#include