李宏毅2020机器学习深度学习(3) CNN卷积神经网络 笔记+作业
目录
- 1. 背景知识
-
- 1.1 CNN(卷积神经网络)结构介绍
- 1.2 卷积层
- 1.3 Pooling池化层
- 1.4 经过一次卷积与池化的结果
- 1.5 Flatten
- 1.6 注意Filter的维度
- 1.7 补充:1x1卷积
- 1.8 CNN学到了什么
- 2. 作业描述
- 3. 数据预处理
- 4. 在train set 上训练,参考val set上的结果调参
- 5. 在总的训练集上训练
1. 背景知识
1.1 CNN(卷积神经网络)结构介绍
整体结构图如下所示:

输入数据(如一张图片)会经过许多卷积运算和Pooling池化层,最后拉平为一维再送给一个全连接的神经网络。
首先确定卷积网络中的一些术语:
- Kernel size(核的大小),核的大小定义了卷积的视图。
- Stride(步长):它定义了在图像中滑动时,Kernels的步长。Stride=1表示Kernels逐像素滑动通过图像。Stride=2表示Kernels通过每步移动2个像素(即跳过1个像素)在图像中滑动。我们可以使用Stride >= 2对图像进行下采样。
- Padding(填充):Padding定义了图像边框的处理方式。
1.2 卷积层
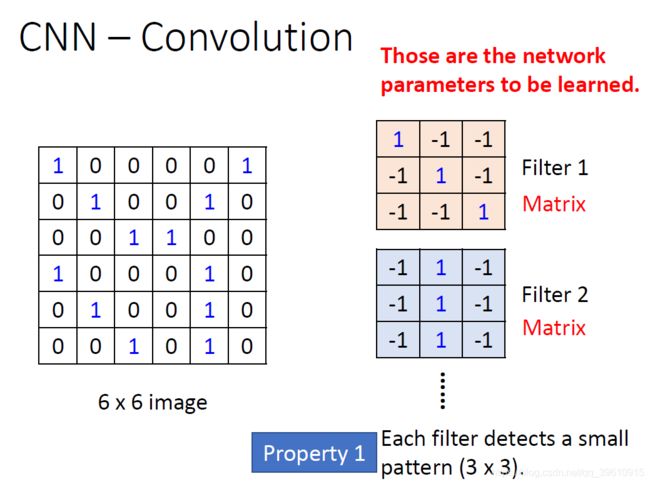
用不同的Filter去检测图片中是否有特定的pattern。
将Filter在原图像中滑动,与相应区域作对应元素相乘并求和。
注明一下,这里做的其实是互相关函数运算,而不是真正意义上的二维卷积。
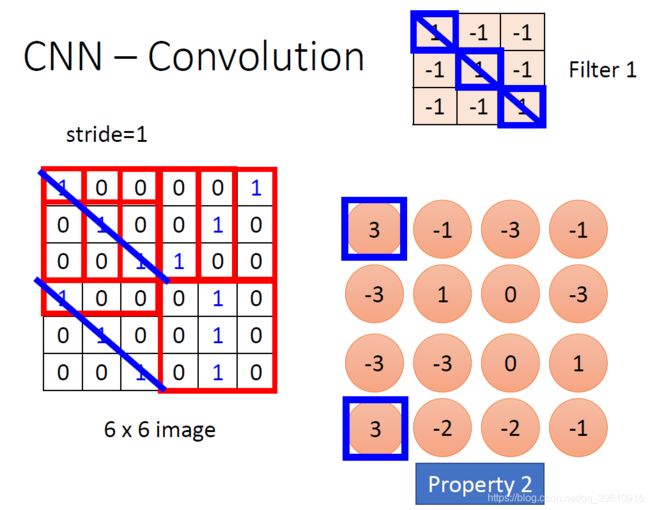
6x6的图像,用3x3的Filter处理后,变为4x4的图像(未填充边界)。feature map是每一个feature从原始图像中提取出来的“特征”。其中的值,越大表示对应位置和feature的匹配越完整,越小表示对应位置和feature的反面匹配越完整,而值接近0的表示对应位置没有任何匹配或者说没有什么关联。
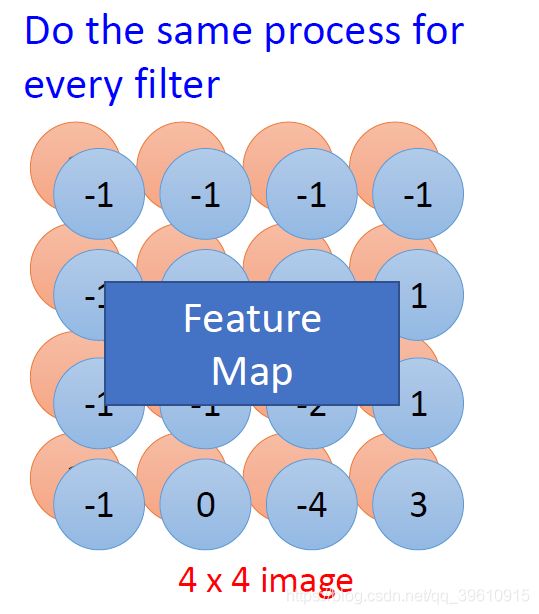
每个Filter,都会生成一个新的图像。
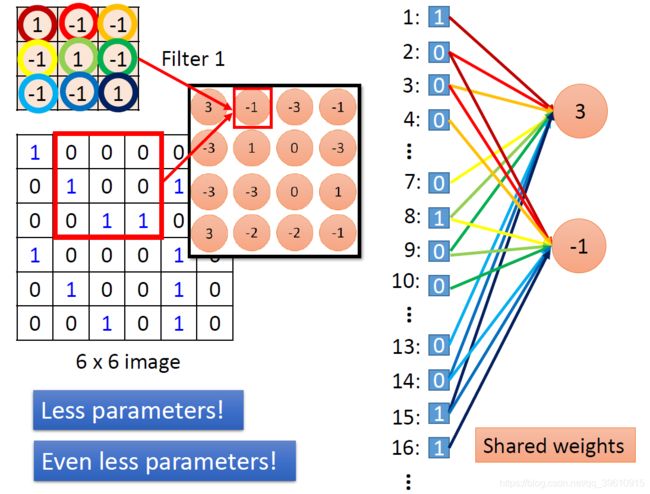
可以将Filter中的值看作神经网络中的权重。
1.3 Pooling池化层
卷积操作后,我们得到了一张张有着不同值的feature map,尽管数据量比原图少了很多,但还是过于庞大(比较深度学习动不动就几十万张训练图片),因此接下来的池化操作就可以发挥作用了,它最大的目标就是减少数据量。
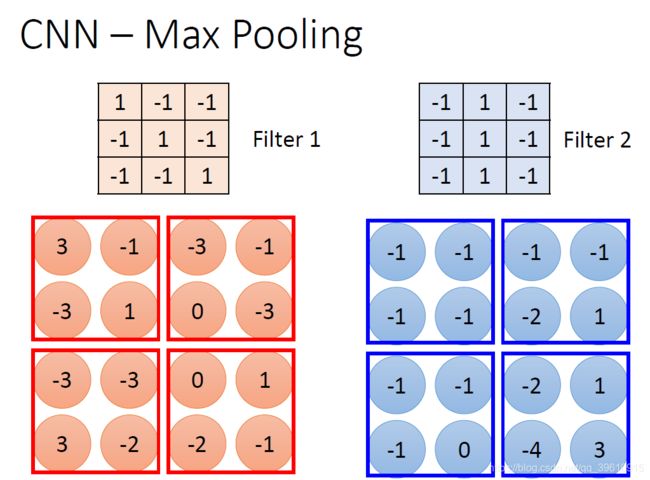
池化分为两种,Max Pooling 最大池化、Average Pooling平均池化。
以最大池化为例,选择池化尺寸为2x2,在其内选出最大值写入新的feature map。
1.4 经过一次卷积与池化的结果
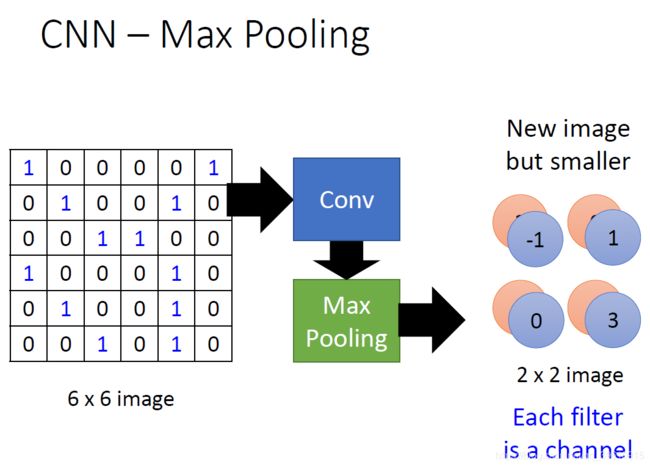
生成了一个比原始图像要小的新图像,他的channel数量等于filter的数量。
1.5 Flatten
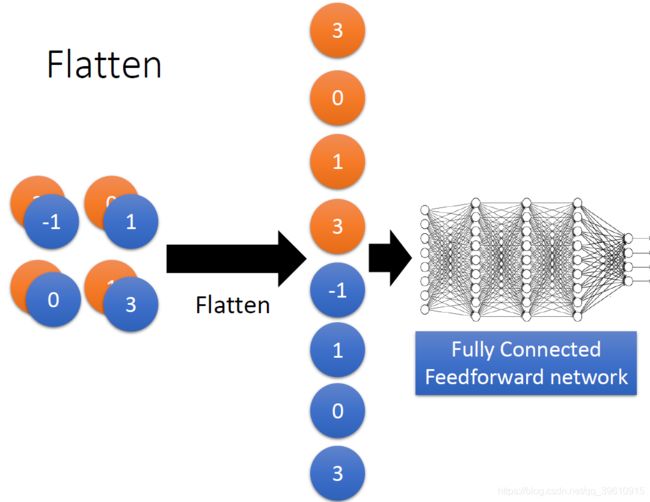
就是将原本的数据拉成一维,送入一个全连接神经网络。
1.6 注意Filter的维度
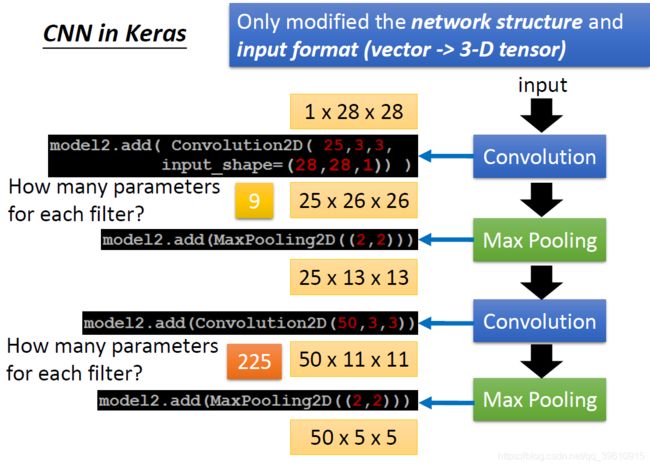
假设输入一个1x28x28的二维平面图像。
第一个卷积层有25个3x3的Fliter,每个Filter的参数有9个。
经过第一次卷积操作以后,输出图像维度变为25x26x26。(有多少个filter,就生成多少个新图像)
经过第一次Max Pooling后,输出图像维度变为25x13x13(是个立体的)。
第二个卷积层有50个3x3的Fliter,每个Filter的参数有25x3x3 = 225个。
现在每个Filter要处理的图像不再是平面的了!

1.7 补充:1x1卷积
可以用来控制降维和升维

1.8 CNN学到了什么
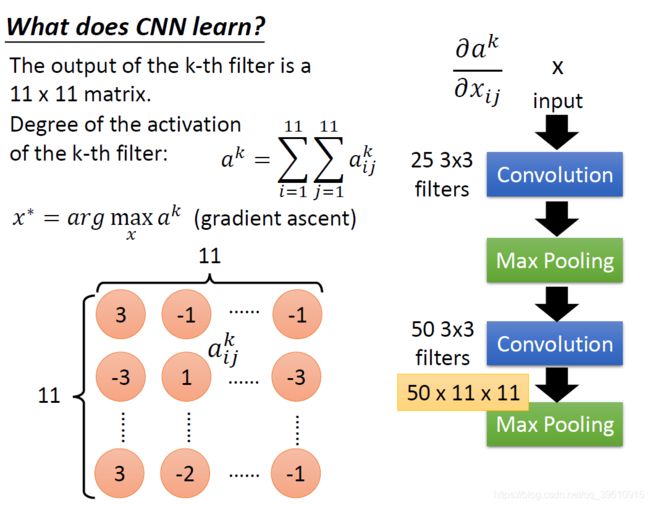
将第k个filter的输出求和,记为 a k a^{k} ak,为激活度。现在要求一个输入数据x,能使激活值最大,也就是找到和这个filter对应的pattern最相似的图像。取前12个图像如下,则这些filter就是要在图像中寻找这样的特征。

CNN能够发现图像中是否具有某种特征,而不用在意到底在哪里具有这种特征,这样就不用死板地逐一像素匹配。
2. 作业描述
通过CNN卷积神经网络对食物图片进行分类

训练集与验证集中图片格式为 ‘[类别]_[编号].jpg’

3. 数据预处理
主要是根据图片的文件名切分出图片所属类别,用以计算loss和分类正确率acc
对图片的操作在注释里写得比较详细了,这里不再赘述
# Read image 利用OpenCV(cv2)读入照片并存放在numpy array中
# label 是一个布尔变量,代表需不需要回传y值
def readfile(path, label):
image_dir = sorted(os.listdir(path))
# 图像大小为128X128,有RGB三个通道
x = np.zeros((len(image_dir), 128, 128, 3), dtype=np.uint8)
y = np.zeros((len(image_dir)), dtype=np.uint8)
for i, file in enumerate(image_dir):
img = cv2.imread(os.path.join(path, file))
x[i, :, :] = cv2.resize(img,(128, 128))
if label:
# 训练集图像命名方式为"[类别](数字)_[该类第几张图片](数字).jpg
# 这里是从图片名称中取出其类别
y[i] = int(file.split("_")[0])
if label:
return x, y
else:
return x
4. 在train set 上训练,参考val set上的结果调参
train set和val set中的数据都有标签,我们先在train set上训练模型,并对比模型在train set和val set上预测的正确率。
如果模型在val set上的正确率不高,说明模型的泛化性能不好。
需要调整cnn的参数
5. 在总的训练集上训练
在确保val set,train set上正确率都不错后
将两个训练集合为一个总的训练集
这里优化的就是权重w了
根据训练出的模型为testing data中的图片打标签
感觉识别的结果还是挺不错的~Amazing!

最后放上完整代码:
# -*- coding: utf-8 -*-
# import需要的模组
import os
import numpy as np
import cv2
import torch
import torch.nn as nn
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, Dataset
import time
# 自定义图片加载
class ImgDataset(Dataset):
def __init__(self, x, y=None, transform = None):
self.x = x
# label is required to be a longTensor
self.y = y
if y is not None:
self.y = torch.LongTensor(y)
self.transform = transform
def __len__(self):
return len(self.x)
def __getitem__(self,index):
X = self.x[index]
if self.transform is not None:
X = self.transform(X)
if self.y is not None:
Y = self.y[index]
return X, Y
else:
return X
# 自己定义一个子类
class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__()
# torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
## in_channels: 输入数据的通道数,例如RGB图片通道数为3
## out_channels: 输出数据的通道数,就是filter的数量
## kernel_size: 卷积核大小
## stride:步长,stride=(2,3),则左右扫描步长为2,上下为3
## padding: 零填充
# torch.nn.MaxPool2d(kernel_size, stride, padding)
# input 維度 [3, 128, 128]
# 卷积网络
self.cnn = nn.Sequential(
nn.Conv2d(3, 64, 3, 1, 1), # [64, 128, 128]
nn.BatchNorm2d(64), # 归一化
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [64, 64, 64]
# 经过一次卷积层后,通道数 = filter的数目
nn.Conv2d(64, 128, 3, 1, 1), # [128, 64, 64]
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [128, 32, 32]
nn.Conv2d(128, 256, 3, 1, 1), # [256, 32, 32]
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [256, 16, 16]
nn.Conv2d(256, 512, 3, 1, 1), # [512, 16, 16]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [512, 8, 8]
nn.Conv2d(512, 512, 3, 1, 1), # [512, 8, 8]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [512, 4, 4]
)
# 将卷积输出flatten之后,送入普通的全连接神经网络
self.fc = nn.Sequential(
nn.Linear(512*4*4, 1024),
nn.ReLU(),
nn.Linear(1024, 512),
nn.ReLU(),
nn.Linear(512, 11) # 结果分为11类
)
def forward(self, x):
out = self.cnn(x)
# flatten view()相当于numpy中resize()的功能
out = out.view(out.size()[0], -1)
return self.fc(out)
# Read image 利用OpenCV(cv2)读入照片并存放在numpy array中
# label 是一个布尔变量,代表需不需要回传y值
def readfile(path, label):
image_dir = sorted(os.listdir(path))
# 图像大小为128X128,有RGB三个通道
x = np.zeros((len(image_dir), 128, 128, 3), dtype=np.uint8)
y = np.zeros((len(image_dir)), dtype=np.uint8)
for i, file in enumerate(image_dir):
img = cv2.imread(os.path.join(path, file))
x[i, :, :] = cv2.resize(img,(128, 128))
if label:
# 训练集图像命名方式为"[类别](数字)_[该类第几张图片](数字).jpg
# 这里是从图片名称中取出其类别
y[i] = int(file.split("_")[0])
if label:
return x, y
else:
return x
# 此函数将testing set预测结果转换为真实食物类别名称
# 0-Bread, 1-Dairy product, 2-Dessert, 3-Egg
# 4-Fried food 5-Meat, 6-Noodles/Pasta, 7-Rice
# 8-Seafood 9-Soup, 10-Vegetable/Fruit.
def my_rename(class_num):
foodname = ['Bread',
'Dairy product',
'Dessert','Egg',
'Fried food',
'Meat',
'NoodlesOrPasta',
'Rice',
'Seafood',
'Soup',
'VegetableOrFruit']
class_name = foodname[int(class_num)]
return class_name
# 此函数为测试集图片打上标签
def tag_pic(rename_path, prediction):
# 获取该目录下所有文件,存入列表中
# 确保此处顺序与预测输出一致
fileList=sorted(os.listdir(rename_path))
try:
if len(fileList) == len(prediction):
for i, y in enumerate(prediction):
classname = my_rename(prediction[i])
# 设置旧文件名(就是路径+文件名)
# os.sep添加系统分隔符
oldname = rename_path + os.sep + fileList[i]
# 设置新文件名
newname = rename_path + os.sep + classname + '_' + fileList[i]
# 用os模块中的rename方法对文件改名
os.rename(oldname,newname)
except Exception as error:
print('图片打标签发生错误')
print(error)
with open(os.path.join(rename_path,"predict.csv"), 'w') as f:
f.write('Id,Category\n')
for i, y in enumerate(prediction):
f.write('{},{}\n'.format(i, y))
if __name__ == "__main__":
# 用readfile函数读取training set, validation srt, testing set
workspace_dir = 'D:/workspace/lhy_data/hw3/food-11'
path_model = 'D:/workspace/lhy_DL_Hw_me/Hw3/'
train_x, train_y = readfile(os.path.join(workspace_dir,"training"), True)
print("Size of training data = {}".format(len(train_x)))
val_x, val_y = readfile(os.path.join(workspace_dir, "validation"), True)
print("Size of validation data = {}".format(len(val_x)))
test_x = readfile(os.path.join(workspace_dir, "testing"), False)
print("Size of Testing data = {}".format(len(test_x)))
# 在 Pytorch 中,我們可以利用 torch.utils.data 的 Dataset 及 DataLoader 來"包装" data
# 使后续的 training 及 testing 更为方便。
# Dataset 需要重载两个函数:__len__ 及 __getitem__
# __len__ 必須要回传 dataset 的大小,而 __getitem__ 則定义了当程式利用取值時,dataset 应该要怎么回传资料
# training 时做data augmentation
train_transform = transforms.Compose([
transforms.ToPILImage(),
transforms.RandomHorizontalFlip(), # 随机将图片水平翻转
transforms.RandomRotation(15), # 随机旋转图片
transforms.ToTensor(), # 将图片转成Tensor,并把数值normalize到[0,1]
])
# testing 时不需要做data augmentation
test_transform = transforms.Compose([
transforms.ToPILImage(),
transforms.ToTensor(),
])
batch_size = 128
train_set = ImgDataset(train_x, train_y, train_transform)
val_set = ImgDataset(val_x, val_y, test_transform)
# torch中的DataLoader主要是用来将给定数据集中的样本打包成一个一个batch的
train_loader = DataLoader(train_set, batch_size = batch_size, shuffle=True)
val_loader = DataLoader(val_set, batch_size=batch_size, shuffle=False)
# 训练部分
# 使用training set训练,并使用validation set寻找最好的参数
model = Classifier().cuda()
loss = nn.CrossEntropyLoss() # 因为是分类任务,损失函数使用交叉熵
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 优化器选择adam
num_epoch = 30
for epoch in range(num_epoch):
epoch_start_time = time.time()
train_acc = 0.0
train_loss = 0.0
val_acc = 0.0
val_loss = 0.0
model.train() # 确保model是在train model(开启dropout等...)
# 每次训练batch_size大小的数据
for i, data in enumerate(train_loader):
# data[0]:data;data[1]:label
optimizer.zero_grad()
train_pred = model(data[0].cuda()) # 调用model的forward函数
batch_loss = loss(train_pred, data[1].cuda()) # 计算loss,注意prediction和label必须同时在CPU和GPU上
batch_loss.backward() # 反向传播求导
optimizer.step() # 优化器更新参数
train_acc += np.sum(np.argmax(train_pred.cpu().data.numpy(),axis = 1) == data[1].numpy())
train_loss += batch_loss.item() # item是得到一个元素张量里面的元素值
# 固定BN和dropout层
model.eval()
with torch.no_grad():
for i, data in enumerate(val_loader):
val_pred = model(data[0].cuda())
batch_loss = loss(val_pred, data[1].cuda())
val_acc += np.sum(np.argmax(val_pred.cpu().data.numpy(),axis = 1) == data[1].numpy())
val_loss += batch_loss.item()
# 完成一轮训练后,打印训练结果
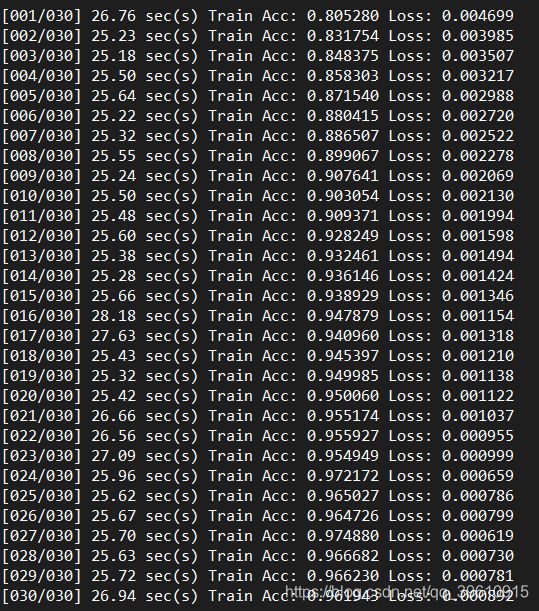
print('[%03d/%03d] %2.2f sec(s) Train Acc: %3.6f Loss: %3.6f | Val Acc: %3.6f loss: %3.6f' % (epoch + 1, num_epoch, time.time()-epoch_start_time, train_acc/train_set.__len__(), train_loss/train_set.__len__(), val_acc/val_set.__len__(), val_loss/val_set.__len__()))
# 得到好的参数后,我们使用training set和validation set 共同训练
# 因为数据变多,模型效果较好
# 合并数据
train_val_x = np.concatenate((train_x, val_x), axis = 0)
train_val_y = np.concatenate((train_y, val_y), axis = 0)
train_val_set = ImgDataset(train_val_x, train_val_y, train_transform)
train_val_loader = DataLoader(train_val_set, batch_size = batch_size, shuffle=True)
# 最好的参数是怎么选择的?
# 不断运行上面的代码,根据val_set中的表现,调整Classifier()中cnn的结构,提高模型的泛化性能
model_best = Classifier().cuda()
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model_best.parameters(), lr=0.001) # optimizer 使用 Adam
num_epoch = 30
for epoch in range(num_epoch):
epoch_start_time = time.time()
train_acc = 0.0
train_loss = 0.0
model_best.train()
for i, data in enumerate(train_val_loader):
optimizer.zero_grad()
train_pred = model_best(data[0].cuda())
batch_loss = loss(train_pred, data[1].cuda())
batch_loss.backward()
optimizer.step()
train_acc += np.sum(np.argmax(train_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
train_loss += batch_loss.item()
#將結果 print 出來
print('[%03d/%03d] %2.2f sec(s) Train Acc: %3.6f Loss: %3.6f' % (epoch + 1, num_epoch, time.time()-epoch_start_time, train_acc/train_val_set.__len__(), train_loss/train_val_set.__len__()))
# 在测试集上利用训练好的模型进行预测
test_set = ImgDataset(test_x, transform = test_transform)
test_loader = DataLoader(test_set, batch_size = batch_size, shuffle=False) # 这里随机打乱了,还能正确给test文件夹中的图片打标签吗?(答:显然不能)
model_best.eval()
prediction = []
with torch.no_grad():
for i, data in enumerate(test_loader):
test_pred = model_best(data.cuda())
test_label = np.argmax(test_pred.cpu().data.numpy(), axis=1)
for y in test_label:
prediction.append(y)
# 将testing_tagged文件夹里的图片进行命名
rename_path = 'D:/workspace/lhy_data/hw3/food-11/testing_tagged'
tag_pic(rename_path, prediction)
# # 模型的加载与保存
# state_sict = model_best.state_dict()
# torch.save(model_best, path_model + 'model.pkl')
# torch.save(state_sict, path_model + 'model_state_dict.pkl.pkl')
# net_load = torch.load(path_model + 'model.pkl')
# model_best = net_load