1.Spark的应用执行机制
用户提交一个Application到Spark集群执行的基础流程如下图所示:

(1)Driver进程启动,构建Spark Application的运行环境(启动SparkContext),SparkContext向资源管理器(可以是Standalone、Mesos或YARN)注册并申请运行Executor资源;
(2)资源管理器接到SparkContext申请后,根据与woker之间心跳信息,决定在哪些worker上启动Executor;
(3)Worker的Executor启动后,会向SparkContext注册。与此同时,SparkContext解析Application,划分job构建成DAG图,将DAG图分解成Stage,并把Taskset发送给Task Scheduler。
(4)Task Scheduler将Task发放给Executor运行同时SparkContext将应用程序代码发放给Executor。
(5)Task在Executor上运行,运行完毕释放所有资源。
2.Spark 作业提交运行详细流程

通过SparkSubmit提交job后,Client就开始构建 spark context,即 application 的运行环境(使用本地的Client类的main函数来创建spark context并初始化它)
client模式下提交任务,Driver在客户端本地运行;cluster模式下提交任务的时候,Driver是运行在集群上
SparkContext连接到ClusterManager(Master),向资源管理器注册并申请运行Executor的资源(内核和内存)
Master根据SparkContext提出的申请,根据worker的心跳报告,来决定到底在那个worker上启动executor
Worker节点收到请求后会启动executor
executor向SparkContext注册,这样driver就知道哪些executor运行该应用
SparkContext将Application代码发送给executor(如果是standalone模式就是StandaloneExecutorBackend)
同时SparkContext解析Application代码,构建DAG图,提交给DAGScheduler进行分解成stage,stage被发送到TaskScheduler。
TaskScheduler负责将Task分配到相应的worker上,最后提交给executor执行
executor会建立Executor线程池,开始执行Task,并向SparkContext汇报,直到所有的task执行完成
所有Task完成后,SparkContext向Master注销
3.Job的调度执行流程
应用程序是一系列RDD的操作,Driver解析代码时遇到Action算子,就会触发Job的提交(实际底层实现上,Action算子最后调用rubJob函数提交Job给spark。其他操作都是生成对应RDD的关系链,job提交是隐式完成的,无需用户显示的提交)。
Job的解析、调度执行整个流程可以划分两个阶段:
-
Stage划分与提交
(1)Job按照RDD之间的依赖关系是否为宽依赖,由DAGScheduler从RDD毅力链的末端开始触发,遍历RDD依赖链划分为一个或多个具有依赖关系个Stage;
(2)第一步划分出Stage后,DAGScheduler生成job实例,从末端Stage-FinalStage开始,按照一定规则递归调度Stage,即交给TaskScheduler将每个stage转化为一个TaskSet;
Task调度与执行:由TaskScheduler负责将TaskSet中的Task调度到Worker节点的Executor上执行。
3.1Job到DAGScheduler过程
首先在SparkContext初始化的时候会创建DAGScheduler,这个DAGScheduelr每个应用只有一个。然后DAGScheduler创建的时候,会初始化一个事件捕获对象,并且开启监听。之后我们的任务都会发给这个事件监听器,它会按照任务的类型创建不同的任务。
再从客户端程序方面说,当我们调用action操作的时候,就会触发runjob,它内部其实就是向前面的那个事件监听器提交一个任务。
最后事件监听器调用DAGScheduler的handleJobSubmitted真正的处理
处理的时候,会先创建一个resultStage,每个job只有一个resultstage,其余的都是shufflestage.然后根据rdd的依赖关系,按照广度优先的思想遍历rdd,遇到shufflerdd就创建一个新的stage。
形成DAG图后,遍历等待执行的stage列表,如果这个stage所依赖的父stage执行完了,它就可以执行了;否则还需要继续等待。
-
最终stage会以taskset的形式,提交给TaskScheduler,然后最后提交给excutor。
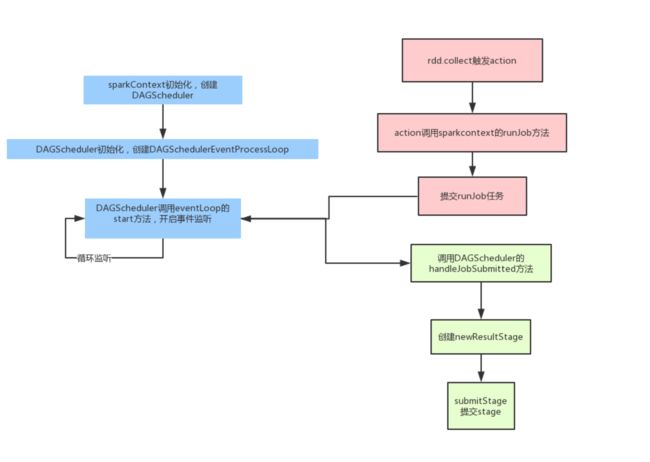 image.png
image.png
3.1.1Job提交
当我们调用action操作的时候,就会触发runjob,它内部其实就是向前面的那个事件监听器提交一个任务,以 RDD#collect()算子介绍:
collect()算子提交任务:
def collect(): Array[T] = withScope {
val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)
Array.concat(results: _*)
}
SparkContext#runJob
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit = {
...
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
...
}
在dagScheduler.runJob-》dagScheduler.submitJob方法中,会向eventProcessLoop发送一个‘JobSubmitted’-任务提交事件;
def runJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): Unit = {
val start = System.nanoTime
// 调用 submitJob 方法
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
}
//
def submitJob[T, U](..){
...
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))
}
事件队列的处理最后会走到 DAGSchedulerEventProcessLoop 的 onReceive 的回调方法里面去。
/**
* The main event loop of the DAG scheduler.
*/
override def onReceive(event: DAGSchedulerEvent): Unit = {
val timerContext = timer.time()
try {
// 调用 doOnReceive 方法
doOnReceive(event)
} finally {
timerContext.stop()
}
}
后面会去调用 doOnReceive 方法,根据 event 进行模式匹配,匹配到 JobSubmitted 的 event 后实际上是去调用 DAGScheduler 的 handleJobSubmitted 这个方法
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
// 模式匹配
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
// 调用 handleJobSubmitted 方法
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
3.1.2Job的划分和调度
handleJobSubmitted主要完成下面的工作:
1.使用 触发 job 的最后一个 rdd来创建 finalStage;注: Stage 是一个抽象类,一共有两个实现,一个是 ResultStage,是用 action 中的函数计算结果的 stage;另一个是 ShuffleMapStage,是为 shuffle 准备数据的 stage。
2.构造一个 Job 对象,将上面创建的 finalStage 封装进去,这个 Job 的最后一个 stage 也就是这个 finalStage;
3.将 Job 的相关信息保存到内存的数据结构中;
4.调用 submitStage 方法提交 finalStage。
构造finalStage和Job实例
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
var finalStage: ResultStage = null
try {
// 使用触发 job 的最后一个 RDD 创建一个 ResultStage
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
// 使用前面创建好的 ResultStage 去创建一个 job
// 这个 job 的最后一个 stage 就是 finalStage
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
clearCacheLocs()
// 将 job 的相关信息存储到内存中
val jobSubmissionTime = clock.getTimeMillis()
jobIdToActiveJob(jobId) = job
activeJobs += job
finalStage.setActiveJob(job)
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
// 提交 finalStage
submitStage(finalStage)
}
3.1.2.1DAG划分,并调度Stage
下面就会走进 submitStage 方法,这个方法是用来提交 stage 的,具体做了这些操作:
1,首先会验证 stage 对应的 job id 进行校验,存在才会继续执行;
2,在提交这个 stage 之前会判断当前 stage 的状态。
如果是 running、waiting、failed 的话就不做任何操作。
如果不是这三个状态则会根据当前 stage 去往前推前面的 stage,如果能找到前面的 stage 则继续递归调用 submitStage 方法,直到当前 stage 找不到前面的 stage 为止,这时候的 stage 就相当于当前 job 的第一个 stage,然后回去调用 submitMissingTasks 方法去分配 task。
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
// 看看当前的 job 是否存在
if (jobId.isDefined) {
logDebug("submitStage(" + stage + ")")
// 判断当前 stage 的状态
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
// 根据当前的 stage 去推倒前面的 stage
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
// 如果前面已经没有 stage 了,那么久将当前 stage 去执行 submitMissingTasks 方法
// 如果前面还有 stage 的话那么递归调用 submitStage
if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
submitMissingTasks(stage, jobId.get)
} else {
for (parent <- missing) {
submitStage(parent)
}
// 将当前 stage 加入等待队列
waitingStages += stage
}
}
} else {
// abortStage 终止提交当前 stage
abortStage(stage, "No active job for stage " + stage.id, None)
}
}
3.1.2.2划分stage
getMissingParentStages 这个划分算法做了哪些操作:
1.创建 missing 和 visited 两个 HashSet,分别用来存储根据当前 stage 向前找到的所有 stage 数据和已经调用过 visit 方法的 RDD;
2.创建一个存放 RDD 的栈,然后将传进来的 stage 中的 rdd 也就是 finalStage 中的那个 job 触发的最后一个 RDD 放入栈中;
3.然后将栈中的 RDD 拿出来调用 visit 方法,这个 visit 方法内部会根据当前 RDD 的依赖链逐个遍历所有 RDD,并且会根据相邻两个 RDD 的依赖关系来决定下面的操作:
如果是宽依赖,即 ShuffleDependency ,那么会调用 getOrCreateShuffleMapStage 创建一个新的 stage,默认每个 job 的最后一个 stage 是 ResultStage,剩余的 job 中的其它 stage 均为 ShuffleMapStage。然后会将创建的这个 stage 加入前面创建的 missing 的 HashSet 中;
如果是窄依赖,即 NarrowDependency,那么会将该 RDD 加入到前面创建的 RDD 栈中,继续遍历调用 visit 方法。
直到所有的 RDD 都遍历结束后返回前面创建的 missing 的集合。
private def getMissingParentStages(stage: Stage): List[Stage] = {
// 存放下面找到的所有 stage
val missing = new HashSet[Stage]
// 存放已经遍历过的 rdd
val visited = new HashSet[RDD[_]]
// We are manually maintaining a stack here to prevent StackOverflowError
// caused by recursively visiting
// 创建一个维护 RDD 的栈
val waitingForVisit = new Stack[RDD[_]]
// visit 方法
def visit(rdd: RDD[_]) {
// 判断当前 rdd 是否 visit 过
if (!visited(rdd)) {
visited += rdd
val rddHasUncachedPartitions = getCacheLocs(rdd).contains(Nil)
if (rddHasUncachedPartitions) {
// 遍历当前 RDD 的依赖链
for (dep <- rdd.dependencies) {
dep match {
// 如果是宽依赖
case shufDep: ShuffleDependency[_, _, _] =>
// 创建 ShuffleMapStage
val mapStage = getOrCreateShuffleMapStage(shufDep, stage.firstJobId)
if (!mapStage.isAvailable) {
// 加入 missing 集合
missing += mapStage
}
// 如果是窄依赖
case narrowDep: NarrowDependency[_] =>
// 加入等待 visit 的集合中,准备下一次遍历
waitingForVisit.push(narrowDep.rdd)
}
}
}
}
}
// 将传入的 stage 中的 rdd 拿出来压入 waitingForVisit 的栈中
waitingForVisit.push(stage.rdd)
// 遍历栈里的所有 RDD
while (waitingForVisit.nonEmpty) {
// 调用 visit 方法
visit(waitingForVisit.pop())
}
// 返回 missing 这个 stage 集合
missing.toList
}
3.1.2.3为创建的task分配最佳位置
submitMissingTasks 方法中做了这些事:
1.拿到 stage 中没有计算的 partition;
2.获取 task 对应的 partition 的最佳位置,使用最佳位置算法;
3.获取 taskBinary,将 stage 的 RDD 和 ShuffleDependency(或 func)广播到 Executor;
4.为 stage 创建 task和taskSet(当tasks长度大于0)
5.提交taskSet给TaskScheduler
submitMissingTasks 主要为task分配最佳位置计算-生成taskId和最佳partition的映射关系;
3.2提交Stage给TaskScheduler完成任务集的调度
前面已经分析到了 DAGScheduler 对 stage 划分,并对 Task 的最佳位置进行计算之后,通过调用 taskScheduler 的 submitTasks 方法,将每个 stage 的 taskSet 进行提交。
在 taskScheduler 的 submitTasks 方法中会为每个 taskSet 创建一个 TaskSetManager,用于管理 taskSet。然后向调度池中添加该 TaskSetManager,最后会调用 backend.reviveOffers() 方法为 task 分配资源。
TaskScheduler维护task和executor对应关系,executor和物理资源对应关系,在排队的task和正在跑的task。
3.2.1包装taskSet,为task分配资源
TaskScheduler唯一实现类-TaskSchedulerImpl的submitTasks逻辑
override def submitTasks(taskSet: TaskSet) {
//获取 taskSet 中的 task
val tasks = taskSet.tasks
logInfo("Adding task set " + taskSet.id + " with " + tasks.length + " tasks")
this.synchronized {
// 为每个 taskSet 创建一个 TaskSetManager
val manager = createTaskSetManager(taskSet, maxTaskFailures)
// 拿到 stage 的 id
val stage = taskSet.stageId
// 创建一个 HashMap ,用来存储 stage 对应的 TaskSetManager
val stageTaskSets =
taskSetsByStageIdAndAttempt.getOrElseUpdate(stage, new HashMap[Int, TaskSetManager])
// 将上面创建的 taskSetManager 存入 map 中
stageTaskSets(taskSet.stageAttemptId) = manager
val conflictingTaskSet = stageTaskSets.exists { case (_, ts) =>
ts.taskSet != taskSet && !ts.isZombie
}
if (conflictingTaskSet) {
throw new IllegalStateException(s"more than one active taskSet for stage $stage:" +
s" ${stageTaskSets.toSeq.map{_._2.taskSet.id}.mkString(",")}")
}
// 向调度池中添加刚才创建的 TaskSetManager
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
// 判断程序是否为 local 模式,并且 TaskSchedulerImpl 没有收到 Task
if (!isLocal && !hasReceivedTask) {
// 创建一个定时器,通过指定时间检查 TaskSchedulerImpl 的饥饿情况
starvationTimer.scheduleAtFixedRate(new TimerTask() {
override def run() {
// 如果 TaskSchedulerImpl 已经安排执行了 Task,则取消定时器
if (!hasLaunchedTask) {
logWarning("Initial job has not accepted any resources; " +
"check your cluster UI to ensure that workers are registered " +
"and have sufficient resources")
} else {
this.cancel()
}
}
}, STARVATION_TIMEOUT_MS, STARVATION_TIMEOUT_MS)
}
// 标记已经接收到 Task
hasReceivedTask = true
}
// 给 Task 分配资源
backend.reviveOffers()
}
下面主要看 backend.reviveOffers() 这个方法,在提交模式是 standalone 模式下,实际上是调用 StandaloneSchedulerBackend 的 reviveOffers 方法,实则调用的是其父类 CoarseGrainedSchedulerBackend 的 reviveOffers 方法,这个方法是向 driverEndpoint 发送一个 ReviveOffers 消息。
代码块
override def reviveOffers() {
// 向 driverEndpoint 发送 ReviveOffers 消息
driverEndpoint.send(ReviveOffers)
}
DriverEndpoint 收到信息后会调用 makeOffers 方法:
case ReviveOffers =>
makeOffers()
makeOffers 方法内部会将 application 所有可用的 executor 封装成一个 workOffers,每个 workOffers 内部封装了每个 executor 的资源数量。
然后调用 taskScheduler 的 resourceOffers 从上面封装的 workOffers 信息为每个 task 分配合适的 executor。
最后调用 launchTasks 启动 task。
private def makeOffers() {
// 过滤出可用的 executor
val activeExecutors = executorDataMap.filterKeys(executorIsAlive)
// 将这些 executor 封装成 workOffers
val workOffers = activeExecutors.map { case (id, executorData) =>
new WorkerOffer(id, executorData.executorHost, executorData.freeCores)
}.toIndexedSeq
// 给每个 task 分配 executor,然后调用 launchTasks 启动这些 task
launchTasks(scheduler.resourceOffers(workOffers))
}
下面看一下 launchTasks 这个方法。
这个方法主要做了这些操作:
1.遍历每个 task,然后将每个 task 信息序列化。
2.判断序列化后的 task 信息,如果大于 rpc 发送消息的最大值,则停止,建议调整 rpc 的 maxRpcMessageSize,如果小于 rpc 发送消息的最大值,则找到 task 对应的 executor,然后更新该 executor 对应的一些内存资源信息。
3.向 executor 发送 LaunchTask 消息。
private def launchTasks(tasks: Seq[Seq[TaskDescription]]) {
// 遍历所有的 task
for (task <- tasks.flatten) {
// 序列化 task 信息
val serializedTask = ser.serialize(task)
// 判断序列化后的 task 信息是否大于 rpc 能够传送的最大信息量
if (serializedTask.limit >= maxRpcMessageSize) {
....
}
else {
// 找到对应的 executor
val executorData = executorDataMap(task.executorId)
// 更新 executor 的资源信息
executorData.freeCores -= scheduler.CPUS_PER_TASK
logDebug(s"Launching task ${task.taskId} on executor id: ${task.executorId} hostname: " +
s"${executorData.executorHost}.")
// 向 executor 发送 LaunchTask 消息
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
}
}
}
3.2.2Executor端执行Task
Executor 收到消息后做了哪些操作?这里 executorData.executorEndpoint 实际上就是在创建 Executor 守护进程时候创建的那个 CoarseGrainedExecutorBackend。
CoarseGrainedExecutorBackend处理接收到 LaunchTask 消息后会判断当前的 executor 是不是为空,如果不为空就会反序列化 task 的信息,然后调用 executor 的 launchTask 方法。
case LaunchTask(data) =>
// 判断当前 executor 是不是空
if (executor == null) {
exitExecutor(1, "Received LaunchTask command but executor was null")
} else {
// 反序列化 task 的信息
val taskDesc = ser.deserialize[TaskDescription](data.value)
logInfo("Got assigned task " + taskDesc.taskId)
// 调用 executor 的 lauchTask 方法
executor.launchTask(this, taskId = taskDesc.taskId, attemptNumber = taskDesc.attemptNumber,
taskDesc.name, taskDesc.serializedTask)
}
executor的 launchTask方法首先会为每个 task 创建一个 TaskRunner,然后会将 task 添加到 runningTasks 的集合中,并标记其为运行状态,最后将 taskRunner 放到一个线程池中执行。
def launchTask(
context: ExecutorBackend,
taskId: Long,
attemptNumber: Int,
taskName: String,
serializedTask: ByteBuffer): Unit = {
// 创建 TaskRunner
val tr = new TaskRunner(context, taskId = taskId, attemptNumber = attemptNumber, taskName,
serializedTask)
runningTasks.put(taskId, tr)
// 将 taskRunner 放到线程池中执行
threadPool.execute(tr)
}
task 运行完成后回向 driver 发送消息,driver 会更新 executor 的一些资源数据,并标记 task 已完成。
TaskScheduler是一个trait接口,任务调度器的实现只有一种就是TaskSchedulerImpl。TaskSchedulerImpl主要处理一些通用的逻辑,例如在多个作业之间决定调度顺序,执行推测执行的逻辑等等。主要逻辑是:
3.3小结
任务在driver中从诞生到最终发送的过程,主要有一下几个步骤:
DAGScheduler对作业计算链按照shuffle依赖划分多个stage,提交一个stage根据个stage的一些信息创建多个Task,包括ShuffleMapTask和ResultTask, 并封装成一个任务集(TaskSet),把这个任务集交给TaskScheduler
TaskSchedulerImpl将接收到的任务集加入调度池中,然后通知调度后端SchedulerBackend
CoarseGrainedSchedulerBackend收到新任务提交的通知后,检查下现在可用 executor有哪些,并把这些可用的executor交给TaskSchedulerImpl
TaskSchedulerImpl根据获取到的计算资源,根据任务本地性级别的要求以及考虑到黑名单因素,按照round-robin的方式对可用的executor进行轮询分配任务,经过多个本地性级别分配,多轮分配后最终得出任务与executor之间的分配关系,并封装成TaskDescription形式返回给SchedulerBackend
SchedulerBackend拿到这些分配关系后,就知道哪些任务该发往哪个executor了,通过调用rpc接口将任务通过网络发送即可。
4.Spark运行架构特点
(1)每个Application获取专属的executor进程,该进程在Application期间一直驻留,并以多线程方式运行tasks。这种Application隔离机制有其优势的,无论是从调度角度看(每个Driver调度它自己的任务),还是从运行角度看(来自不同Application的Task运行在不同的JVM中)。当然,这也意味着Spark Application不能跨应用程序共享数据,除非将数据写入到外部存储系统。
(2)Spark与资源管理器无关,只要能够获取executor进程,并能保持相互通信就可以了。
(3)提交SparkContext的Client应该靠近Worker节点(运行Executor的节点),最好是在同一个Rack里,因为Spark Application运行过程中SparkContext和Executor之间有大量的信息交换;如果想在远程集群中运行,最好使用RPC将SparkContext提交给集群,不要远离Worker运行SparkContext。
(4)Task采用了数据本地性和推测执行的优化机制。
5.参考
https://www.cnblogs.com/xing901022/p/6674966.html
https://www.cnblogs.com/zhuge134/p/10965266.html
https://blog.csdn.net/xianpanjia4616/article/details/84405145
https://juejin.im/post/5d23069a6fb9a07f091bc66e