python 实现中文词云
本文适宜像我一样的新手训练。
使用到的库:
1,wordcloud
2,scipy.misc (用于创建背景图片)
3,matplotlib(数据展示)
4,jieba(中文文本分词)
这是我们要统计的文本数据(可以保存为txt进行练习):
李白 李白 李白 李白 李白 李白 李白 李白 李白 李白 李白 李白
君不见黄河之水天上来,奔流到海不复回。
君不见高堂明镜悲白发,朝如青丝暮成雪。
人生得意须尽欢,莫使金樽空对月。
天生我材必有用,千金散尽还复来。
烹羊宰牛且为乐,会须一饮三百杯。
岑夫子,丹丘生,将进酒,杯莫停。
与君歌一曲,请君为我侧耳听。
钟鼓馔玉不足贵,但愿长醉不复醒。
古来圣贤皆寂寞,惟有饮者留其名。
陈王昔时宴平乐,斗酒十千恣欢谑。
主人何为言少钱,径须沽取对君酌。
五花马,千金裘,
呼儿将出换美酒,与尔同销万古愁。
床前明月光,疑是地上霜。
举头望明月,低头思故乡。
海客谈瀛洲,烟涛微茫信难求。
越人语天姥,云霞明灭或可睹。
天姥连天向天横,势拔五岳掩赤城。
天台四万八千丈,对此欲倒东南倾。
我欲因之梦吴越,一夜飞度镜湖月。
湖月照我影,送我至剡溪。
谢公宿处今尚在,渌水荡漾清猿啼。
脚著谢公屐,身登青云梯。
半壁见海日,空中闻天鸡。
千岩万转路不定,迷花倚石忽已暝。
熊咆龙吟殷岩泉,栗深林兮惊层巅。
云青青兮欲雨,水澹澹兮生烟。
列缺霹雳,丘峦崩摧。洞天石扉,訇然中开。
青冥浩荡不见底,日月照耀金银台。
霓为衣兮风为马,云之君兮纷纷而来下。
虎鼓瑟兮鸾回车,仙之人兮列如麻。
忽魂悸以魄动,恍惊起而长嗟。
惟觉时之枕席,失向来之烟霞。
世间行乐亦如此,古来万事东流水。
别君去兮何时还,且放白鹿青崖间,
须行即骑访名山。安能摧眉折腰事权贵,
使我不得开心颜。
统计的词云效果:
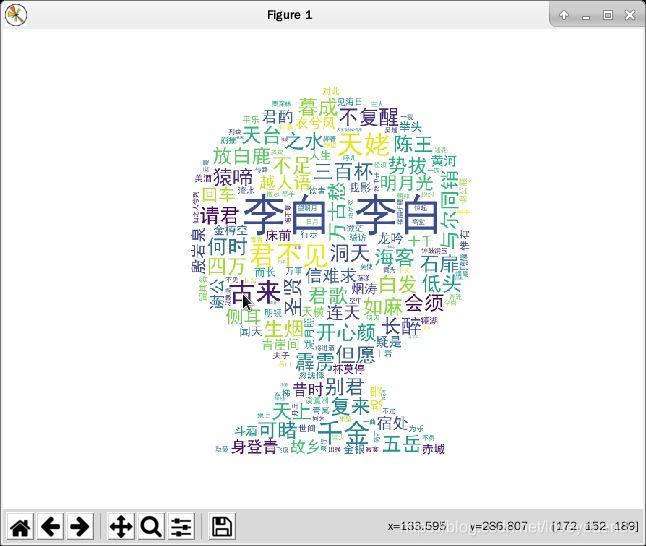
让我们开始吧!
我们把构建词云分为两步:
1,处理文本数据
在生成词云时,wordcloud默认会以空格或标点为分隔符对目标文本进行分词处理。对于中文文本,分词处理需要由用户来完成。一般步骤是先将文本分词处理,然后以空格拼接,再调用wordcloud库函数
2,产生词云图片
wordcloud库的核心是WordColoud类,所有的功能都封装在WordCloud类中。使用时需要实例 化 一 个 Wo r d C o l o u d 类 的 对 象 , 并 调 用 其generate(text)方法将text文本转化为词云
所以我们采用函数式编程方式编写代码。
一、处理文本数据
jieba支持三种分词模式:
- 精确模式lcut(),试图将句子最精确地切开,适合文本分析,单词无冗余;
- 全模式lcut(s, cut_all=True) ,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义,存在冗余;
- 搜索引擎模式cut_for_search(s),在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
from wordcloud import WordCloud
from scipy.misc import imread
import matplotlib.pyplot as plt
import jieba
def read_deal_text():
with open("ciyun.txt","r") as f: #读取我们的待处理本文
txt=f.read()
re_move=[",","。",'\n','\xa0'] #无效数据
#去除无效数据
for i in re_move:
txt=txt.replace(i," ")
word=jieba.lcut(txt) #使用精确分词模式进行分词后保存为word列表
处理符号后的效果:
['李白', '李白', '李白', '李白', '李白', '李白', '李白', '李白', '李白', '李白', '李白', '李白', '君不见', '黄河', '之水', '天上', '来', '奔流', '到', '海不复', '回', '君不见', '高堂', '明镜', '悲', '白发', '朝如', '青丝', '暮成', '雪', '人生', '得意', '须尽欢', '莫使', '金樽空', '对', '月', '天生我材必有用', '千金', '散尽', '还', '复来', '烹羊', '宰牛', '且', '为乐', '会须', '一饮', '三百杯', '岑', '夫子', '丹丘', '生', '将进酒', '杯莫停', '与', '君歌', '一曲', '请君', '为', '我', '侧耳', '听', '钟鼓馔玉', '不足', '贵', '但愿', '长醉', '不复醒', '古来', '圣贤', '皆', '寂寞', '惟有', '饮者', '留其名', '陈王', '昔时', '宴', '平乐', '斗酒', '十千', '恣欢', '谑', '主人', '何为', '言少', '钱', '径须', '沽', '取', '对', '君酌', '五花马', '千金', '裘', '呼儿', '将', '出换', '美酒', '与尔同销', '万古愁', '床前', '明月光', '疑是', '地上', '霜', '举头', '望明月', '低头', '思', '故乡', '海客', '谈瀛洲', '烟涛', '微茫', '信难求', '越人语', '天姥', '云霞', '明灭', '或', '可睹', '天姥', '连天', '向', '天横', '势拔', '五岳', '掩', '赤城', '天台', '四万', '八', '千丈', '对此', '欲', '倒', '东南', '倾', '我', '欲', '因之梦', '吴越', '一夜', '飞度', '镜湖', '月', '湖月照', '我影', '送', '我', '至', '剡溪', '谢公', '宿处', '今尚', '在', '渌', '水', '荡漾', '清', '猿啼', '脚著', '谢公屐', '身登青', '云梯', '半壁', '见海日', '空中', '闻天', '鸡', '千岩', '万', '转路', '不定', '迷花', '倚石', '忽', '已', '暝', '熊', '咆', '龙吟', '殷岩泉', '栗深林', '兮', '惊层', '巅', '云', '青青', '兮', '欲', '雨', '水', '澹', '澹', '兮', '生烟', '列缺', '霹雳', '丘峦', '崩摧', '洞天', '石扉', '訇', '然中开', '青冥', '浩荡', '不见', '底', '日月', '照耀', '金银', '台', '霓为', '衣兮风', '为', '马', '云之君', '兮', '纷纷', '而来', '下', '虎', '鼓瑟', '兮', '鸾', '回车', '仙之人兮列', '如麻', '忽魂悸', '以魄动', '恍', '惊起', '而长', '嗟', '惟觉', '时', '之', '枕席', '失', '向来', '之', '烟霞', '世间', '行乐', '亦', '如此', '古来', '万事', '东', '流水', '别君', '去', '兮', '何时', '还', '且', '放白鹿', '青崖间', '须行', '即', '骑访', '名山', '安', '能', '摧眉折腰', '事', '权贵', '使', '我', '不得', '开心颜']
with open("txt_save.txt",'w') as file:
for i in word:
file.write(str(i)+' ')
print("文本处理完成")
接着将word列表用空格连接保存到txt_save.txt文件中用于下一步产生词云图片
二、产生词云图片
WordCloud类的常用方法
generate(text) 由text文本生成词云
to_file(filename) 将词云图保存为名为filename的文件
def img_grearte():
mask=imread("boy.png")
with open("txt_save.txt","r") as file:
txt=file.read()
word=WordCloud(background_color="white",\
width=800,\
height=800,
font_path='simhei.ttf',
mask=mask,
).generate(txt)
word.to_file('test.png')
print("词云图片已保存")
plt.imshow(word) #使用plt库显示图片
plt.axis("off")
plt.show()
mask=imread("boy.png") #用于图片背景,可自行下载png背景透明图片,imread库函数隶属于scipy库,pip在安装wordcloud库时会自动安装依赖库。
font_path='simhei.ttf' #这里我们用到了中文字体simhei.ttf ,wordcloud默认字体是不支持中文
注意:在此boy.png和simhei.ttf都是放在和程序同一目录。
我们创建一个wordcloud的实例对象word,并设置其属性,包括背景颜色、图片尺寸、字体、图片背景,最后生成词云图片并保存,可到程序目录下常看。
后面使用plt库显示图片
三、完整如下:
from wordcloud import WordCloud
from scipy.misc import imread
import matplotlib.pyplot as plt
import jieba
def read_deal_text():
with open("ciyun.txt","r") as f:
txt=f.read()
re_move=[",","。"," ",'\n','\xa0']
#去除无效数据
for i in re_move:
txt=txt.replace(i," ")
word=jieba.lcut(txt) #使用精确分词模式
with open("txt_save.txt",'w') as file:
for i in word:
file.write(str(i)+' ')
print("文本处理完成")
def img_grearte():
mask=imread("boy.png")
with open("txt_save.txt","r") as file:
txt=file.read()
word=WordCloud(background_color="white",\
width=800,\
height=800,
font_path='simhei.ttf',
mask=mask,
).generate(txt)
word.to_file('test.png')
print("词云图片已保存")
plt.imshow(word) #使用plt库显示图片
plt.axis("off")
plt.show()
read_deal_text()
img_grearte()