【Hadoop离线基础总结】完全分布式环境搭建
完全分布式环境搭建
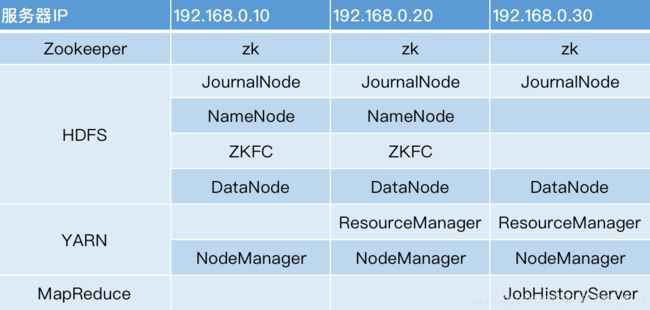
服务规划
适用于工作当中正式环境搭建
安装步骤
- 第一步:安装包解压
停止之前的Hadoop集群的所有服务,并删除所有机器的Hadoop安装包,然后重新解压Hadoop压缩包
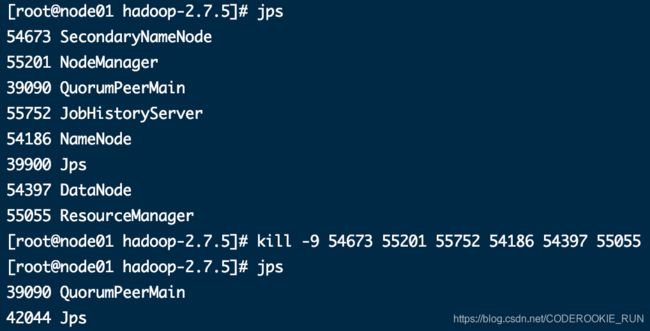
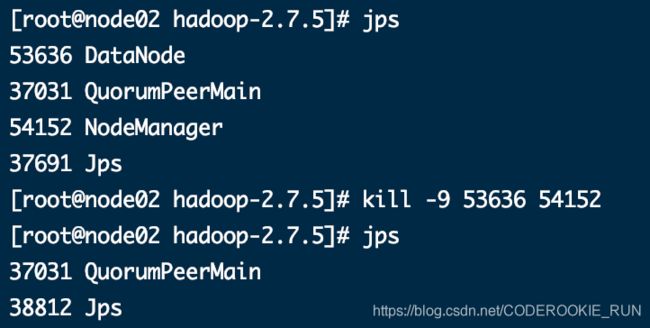

三台机器都执行
rm -rf /export/servers/hadoop-2.7.5/
在第一台机器解压压缩包
cd /export/softwares
tar -zxvf hadoop-2.7.5.tar.gz -C ../servers/
- 第二步:配置文件的修改
进入到一下文件夹,并用notepad++或者finalshell等脚本编辑工具打开一下文件
cd /export/servers/hadoop-2.7.5/etc/hadoop
修改core-site.xml
<configuration>
<property>
<name>ha.zookeeper.quorumname>
<value>node01:2181,node02:2181,node03:2181value>
property>
<property>
<name>fs.defaultFSname>
<value>hdfs://nsvalue>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/export/servers/hadoop-2.7.5/data/tmpvalue>
property>
<property>
<name>fs.trash.intervalname>
<value>10080value>
property>
configuration>
修改hdfs-site.xml
<configuration>
<property>
<name>dfs.nameservicesname>
<value>nsvalue>
property>
<property>
<name>dfs.ha.namenodes.nsname>
<value>nn1,nn2value>
property>
<property>
<name>dfs.namenode.rpc-address.ns.nn1name>
<value>node01:8020value>
property>
<property>
<name>dfs.namenode.rpc-address.ns.nn2name>
<value>node02:8020value>
property>
<property>
<name>dfs.namenode.servicerpc-address.ns.nn1name>
<value>node01:8022value>
property>
<property>
<name>dfs.namenode.servicerpc-address.ns.nn2name>
<value>node02:8022value>
property>
<property>
<name>dfs.namenode.http-address.ns.nn1name>
<value>node01:50070value>
property>
<property>
<name>dfs.namenode.http-address.ns.nn2name>
<value>node02:50070value>
property>
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://node01:8485;node02:8485;node03:8485/ns1value>
property>
<property>
<name>dfs.client.failover.proxy.provider.nsname>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue>
property>
<property>
<name>dfs.ha.fencing.methodsname>
<value>sshfencevalue>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/root/.ssh/id_rsavalue>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/export/servers/hadoop-2.7.5/data/dfs/jnvalue>
property>
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:///export/servers/hadoop-2.7.5/data/dfs/nn/namevalue>
property>
<property>
<name>dfs.namenode.edits.dirname>
<value>file:///export/servers/hadoop-2.7.5/data/dfs/nn/editsvalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:///export/servers/hadoop-2.7.5/data/dfs/dnvalue>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
<property>
<name>dfs.blocksizename>
<value>134217728value>
property>
configuration>
修改hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/export/servers/jdk1.8.0_141
修改mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>node03:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>node03:19888value>
property>
<property>
<name>mapreduce.jobtracker.system.dirname>
<value>/export/servers/hadoop-2.7.5/data/system/jobtrackervalue>
property>
<property>
<name>mapreduce.map.memory.mbname>
<value>1024value>
property>
<property>
<name>mapreduce.reduce.memory.mbname>
<value>1024value>
property>
<property>
<name>mapreduce.task.io.sort.mbname>
<value>100value>
property>
<property>
<name>mapreduce.task.io.sort.factorname>
<value>10value>
property>
<property>
<name>mapreduce.reduce.shuffle.parallelcopiesname>
<value>25value>
property>
<property>
<name>yarn.app.mapreduce.am.command-optsname>
<value>-Xmx1024mvalue>
property>
<property>
<name>yarn.app.mapreduce.am.resource.mbname>
<value>1536value>
property>
<property>
<name>mapreduce.cluster.local.dirname>
<value>/export/servers/hadoop-2.7.5/data/system/localvalue>
property>
configuration>
修改yarn-site.xml
<configuration>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.ha.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.cluster-idname>
<value>myclustervalue>
property>
<property>
<name>yarn.resourcemanager.ha.rm-idsname>
<value>rm1,rm2value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm1name>
<value>node03value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm2name>
<value>node02value>
property>
<property>
<name>yarn.resourcemanager.address.rm1name>
<value>node03:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1name>
<value>node03:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1name>
<value>node03:8031value>
property>
<property>
<name>yarn.resourcemanager.admin.address.rm1name>
<value>node03:8033value>
property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1name>
<value>node03:8088value>
property>
<property>
<name>yarn.resourcemanager.address.rm2name>
<value>node02:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2name>
<value>node02:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2name>
<value>node02:8031value>
property>
<property>
<name>yarn.resourcemanager.admin.address.rm2name>
<value>node02:8033value>
property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2name>
<value>node02:8088value>
property>
<property>
<name>yarn.resourcemanager.recovery.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.ha.idname>
<value>rm1value>
<description>If we want to launch more than one RM in single node, we need this configurationdescription>
property>
<property>
<name>yarn.resourcemanager.store.classname>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStorevalue>
property>
<property>
<name>yarn.resourcemanager.zk-addressname>
<value>node02:2181,node03:2181,node01:2181value>
<description>For multiple zk services, separate them with commadescription>
property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabledname>
<value>truevalue>
<description>Enable automatic failover; By default, it is enabled only when HA is enabled.description>
property>
<property>
<name>yarn.client.failover-proxy-providername>
<value>org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvidervalue>
property>
<property>
<name>yarn.nodemanager.resource.cpu-vcoresname>
<value>4value>
property>
<property>
<name>yarn.nodemanager.resource.memory-mbname>
<value>512value>
property>
<property>
<name>yarn.scheduler.minimum-allocation-mbname>
<value>512value>
property>
<property>
<name>yarn.scheduler.maximum-allocation-mbname>
<value>512value>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>2592000value>
property>
<property>
<name>yarn.nodemanager.log.retain-secondsname>
<value>604800value>
property>
<property>
<name>yarn.nodemanager.log-aggregation.compression-typename>
<value>gzvalue>
property>
<property>
<name>yarn.nodemanager.local-dirsname>
<value>/export/servers/hadoop-2.7.5/yarn/localvalue>
property>
<property>
<name>yarn.resourcemanager.max-completed-applicationsname>
<value>1000value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.connect.retry-interval.msname>
<value>2000value>
property>
configuration>
修改slaves
node01
node02
node03
- 第三步:启动集群
将第一台机器的hadoop安装包分发到第二台、第三台机器上
cd /export/servers
scp -r hadoop-2.7.5/ node02:$PWD
scp -r hadoop-2.7.5/ node03:$PWD
三台机器都创建一下所需的文件夹
mkdir -p /export/servers/hadoop-2.7.5/data/dfs/nn/name
mkdir -p /export/servers/hadoop-2.7.5/data/dfs/nn/edits
mkdir -p /export/servers/hadoop-2.7.5/data/dfs/nn/name
mkdir -p /export/servers/hadoop-2.7.5/data/dfs/nn/edits
更改node的rm2
在第二台机器执行
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim yarn-site.xml
<property>
<name>yarn.resourcemanager.ha.idname>
<value>rm2value>
<description>If we want to launch more than one RM in single node, we need this configurationdescription>
property>
启动HDFS
在第一台机器执行
cd /export/servers/hadoop-2.7.5
bin/hdfs zkfc -formatZK -> 格式化zk
sbin/hadoop-daemons.sh start journalnode -> 启动journalnode
bin/hdfs namenode -format -> 格式化NameNode上面所有的数据
bin/hdfs namenode -initializeSharedEdits -force -> 强制初始化元数据信息
sbin/start-dfs.sh
在第二台机器执行
cd /export/servers/hadoop-2.7.5
bin/hdfs namenode -bootstrapStandby -> 设置NameNode为StandBy状态
sbin/hadoop-daemon.sh start namenode
启动YARN
在第三台机器上执行
cd /export/servers/hadoop-2.7.5
sbin/start-yarn.sh
在第二台机器上执行
cd /export/servers/hadoop-2.7.5
sbin/start-yarn.sh
查看resourceManager状态
在第三台机器上执行
cd /export/servers/hadoop-2.7.5
bin/yarn rmadmin -getServiceState rm1
cd /export/servers/hadoop-2.7.5
bin/yarn rmadmin -getServiceState rm2
在node03启动JobHistory
cd /export/servers/hadoop-2.7.5
sbin/mr-jobhistory-daemon.sh start historyserver
tips
node01机器查看hdfs状态:node01:50070
node02机器查看hdfs状态:node02:50070
yarn集群访问查看:node03:8088
历史任务浏览界面:node03:19888