01
Python是一门很牛逼的编程语言,语法简单,功能强大,它可以用于Web开发,网络爬虫,写脚本,人工智能,机器学习,数据分析,数据可视化等等。说了那么多用途,相信你和我一样,内心早就燃起了对学习Python的热情。这里强烈推荐廖雪峰老师的Python教程,喜欢看书的话,则推荐《PYTHON基础教程》,最新版出到第三版了。
接下来我将会使用Jupyter Notebook来进行代码的编写与运行,它是以网页的形式打开的,可以直接在里面编写代码和运行,非常方便。对于小白来说,推荐安装Anaconda,Anaconda已经自动为我们安装好了Jupyter Notebook以及其他工具等。当然,喜欢钻研的小伙伴也可以到终端输入pip命令安装,具体的就不再赘述了。
首先导入相关的Python模块,并加载好待会儿要操作的数据集。这个数据集是以前练习爬虫的时候抓取下来的豆瓣读书数据。
import numpy as np
import pandas as pd
data = pd.read_excel("doubanTOP250.xlsx")
df = data.head()
df
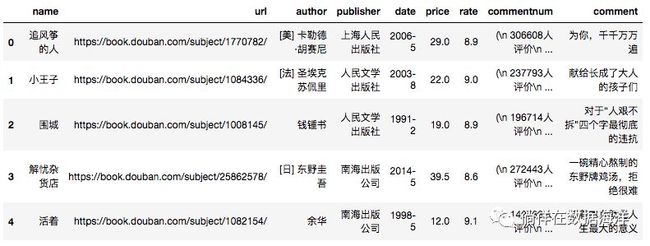
因为该数据集是.xlsx格式,使用pandas.read_excel来加载。其它加载数据的方式还有很多,常见的有:
- 从CSV文件导入数据
pd.read_csv():
- 导入json格式的字符串文件
pd.read_json()
- 从带分隔符的文本文件导入数据
pd.read_table()
- 导入SQL表
pd.read_sql_table()
- 导入xlsx格式的文件
pd.read_excel()
用describe函数可以快速生成各类统计指标,如平均数、标准差、中位数、最大值等,适用于数值型数据。
stats_numeric = pd.DataFrame.describe(df[['price']])
stats_numeric

如果对均值、中位数、峰态系数等的概念不是很清楚,可以点击先看下这篇文章:统计学入门级-描述性统计理论。接下来用Python进行描述性统计,直接上代码。
mode1 = df['rate'].mode()[0]
print('众数:' + str(mode1))
mean1 = df['price'].mean()
print('均值:'+ str(mean1))
median1 = df['price'].median()
print('中位数:' + str(median1))
min1 = df['price'].min()
print('最小值:' + str(min1))
max1 = df['price'].max()
print('最大值:' + str(max1))
quantile1 = df['price'].quantile(q=0.25)
print('第一四分位数:' + str(quantile1))
quantile2 = df['price'].quantile(q=0.50)
print('第二四分位数,即中位数:' + str(quantile2))
quantile3 = df['price'].quantile(q=0.75)
print('第三四分位数:' + str(quantile3))
std1 = df['price'].std()
print('样本标准差:' + str(std1))
var1 = df['price'].var()
print('样本方差:' + str(var1))
skew1 = df['price'].skew()
print('偏态系数:' + str(skew1))
kurt1 = df['price'].kurt()
print('峰态系数:' + str(kurt1))
describe = {'mode':[mode1],
'mean': [mean1],
'median': [median1],
'min': [min1],
'max': [max1],
'quantile1': [quantile1],
'quantile2': [quantile2],
'quantile3': [quantile3],
'standard deviation': [std1],
'variance': [var1],
'skewness coefficient': [skew1],
'kurtosis coefficient': [kurt1]
}
stats = pd.DataFrame(describe,columns= ['mode','mean','median','min','max','quantile1','quantile2',
'quantile3','standard deviation','variance','skewness coefficient',
'kurtosis coefficient'])
stats

02
Series和DataFrame是pandas两个常用的工具数据结构。Series是一种一维的数组型对象,它包含一个值序列和索引,如果索引没有明确指定的话,默认是0到N-1(N为数据的长度)。可以认为Series是一个定长有序的字典,因为它将索引值和数据值按位置配对。
# 创建一个Series,或者使用字典生成一个series
series1 = pd.Series([1,2,-3,9], index = ['a', 'b', 'c', 'd'])
dict = {'tom': 9, 'sam': 79, 'andrew': 90, 'mary':84}
series2 = pd.Series(dict)
series2

- 获取Series对象的值:
series1.values
- 通过索引获取值:
series1['a']
series1[['b','a']]
- 获取Series对象的索引:
series1.index
- 判断Series对象的缺失数据:
series1.isnull()
series1.notnull()
- 对Series对象的值进行排序:
series1.sort_values()
两个Series对象还可以进行相加,在这数学操作中,Series会自动对齐索引。

03
DataFrame表示的是矩阵的数据表,包含已排序的列集合,每一列的值类型可以不同,数值型、字符串、布尔值都可以,它既有行索引也有列索引。
data = {'name': ['tom', 'sam', 'mary', 'jerry'],
'age': [12, 23,15,18],
'score':[67,89,88,90]}
# columns指定了列的顺序,df1将会按照指定顺序排列
df1 = pd.DataFrame(data,columns = ['score', 'name', 'age'])
df1

获取df1的其中一列,可以按字典型标记或属性那样检索为Series。df1[column]对于任意列名均有效,df1.column 只在列名是有效的Python变量名时有效。
df1['age']
df1.age
pandas的其他常用操作如下:
df1.head(n),df1.tail(n)
查看前n行/最后n行,若不指定默认前5行
df.info()
查看索引、数据类型和内存信息
df1.shape
查看行数和列数
df1['age'].value_counts()
查看Series对象的唯一值和计数
df1.values
以数组的形式返回数据
df1.loc[2]
通过位置或特殊属性loc进行选取某一行
df1.columns
获取DataFrame对象的列
df1.index
获取DataFrame对象的索引
df1.isnull(),df1.notnull()
判断DataFrame对象的缺失数据
df1.sort_values()
按照列对DataFrame对象进行排序`
关于Pandas数据处理的知识点还有很多,包括数据合并,过滤,分组,空值的删除替换,数据的选取等等,后续会再补上。