Linux工具的使用
Linux工具的使用
- 软件包管理器(yum)
-
- 什么是yum,有什么作用?
- Linux编辑器,vim的使用
-
- 安装一个适合程序员的vim代码编辑器
- vim的配置
- vim下的三种模式
-
- 正常模式(Normal mode)下的一些操作
- 末行(底行)模式下的操作
- gcc/g++使用
-
- 什么是gcc/g++?
- 程序编译的四阶段
- Linux下的调试
-
- Linux下的debug版本与release版本
- Linux下的gdb命令(调试命令)
- Linux下makefile文件的书写
-
- 什么是make,什么是makefile
- makefile文件书写
- makefile的使用规则
- makefile文件下的伪命令
- makefile文件的批量化注释
- makefile文件下的所有依赖对象与目标对象写法
- git工具的使用
软件包管理器(yum)
什么是软件包
在Linux下安装软件, 一个通常的办法是下载到程序的源代码, 并进行编译, 得到可执行程序.
但是这样太麻烦了, 于是有些人把一些常用的软件提前编译好, 做成软件包(可以理解成windows上的安装程序)放在一个服务器上, 通过包管理器可以很方便的获取到这个编译好的软件包, 直接进行安装.
软件包和软件包管理器, 就好比 “App” 和 “应用商店” 这样的关系.
yum(Yellow dog Updater, Modified)是Linux下非常常用的一种包管理器. 主要应用在Fedora, RedHat,Centos等发行版上.
什么是yum,有什么作用?
yum是包管理器。yum的作用包括查找、安装、卸载。
yum的查找:

yum list 是获取软件商店中所有的软件 | 管道 grep lrzsz 匹配与关键字相同的软件
软件包名称: 主版本号.次版本号.源程序发行号-软件包的发行号.主机平台.cpu架构.
“x86_64” 后缀表示64位系统的安装包, “i686” 后缀表示32位系统安装包. 选择包时要和系统匹配.
“el7” 表示操作系统发行版的版本. “el7” 表示的是 centos7/redhat7. “el6” 表示 centos6/redhat6.
最后一列, base 表示的是 “软件源” 的名称, 类似于 “小米应用商店”, “华为应用商店” 这样的概念
yum 安装
![]()
因为软件的安装需要使用到root权限,所以此时有两种方式,一个是sudo暂时提升用户权限,一种是su ,先进入root ,直接安装
sudo yum -y install lrzsz.x86_64; 表示待询问的下载。 -y为免交互方式
yum卸载软件
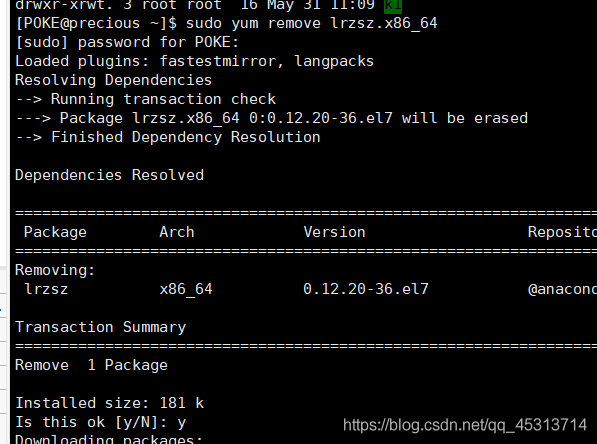
首先介绍一下什么是lrzsz
lrzsz为Linux下的一款程序软件,可以替代ftp的上传与下载。
| 命令 | 含义 |
|---|---|
| rz-E | 打开windows底下的目录,选择文件传入到当前目录下 |
| sz | 将linux下的文件输出到windows下 |
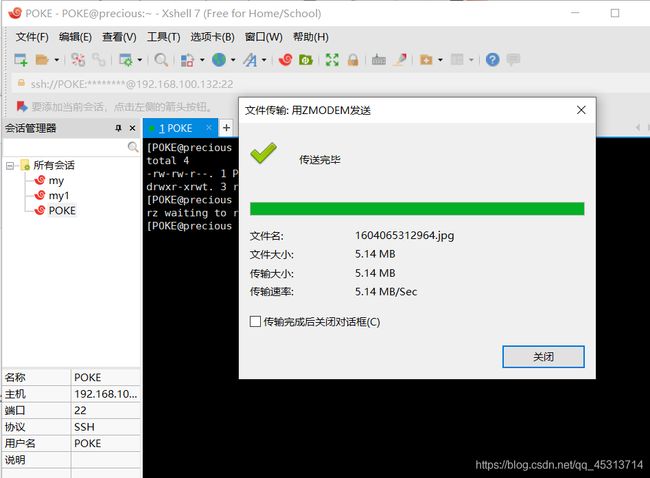
其实可以直接在windows底下将文件拖至xshell,此时会自动调用rz -E。
也可以输入 rz-E命令,此时会打开windows文件夹,自行选择文件输入到Linux中。
sz:命令格式:
sz +文件名
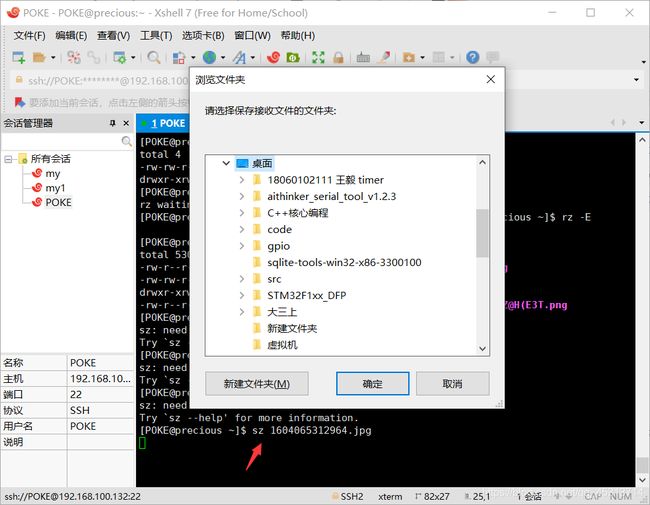

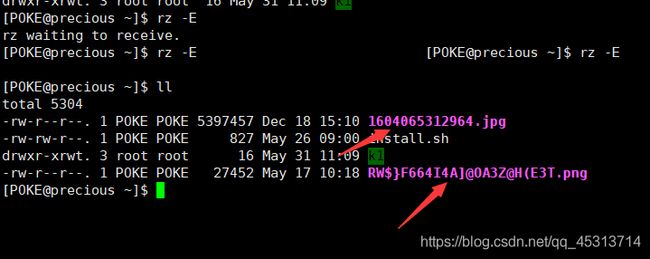
这里我们可以看到文件已经到桌面上了
lrzsz的弊端:只能传输文件,不能传输文件夹,所以我们要传输文件夹的话,就必须先将该文件夹压缩方可传。
也可以使用xftp传,xftp工具
xftp文件 提取码 rygp
Linux编辑器,vim的使用
安装一个适合程序员的vim代码编辑器
curl -sLf https://gitee.com/HGtz2222/VimForCpp/raw/master/install.sh -o ./install.sh && bash ./install.sh 在linux下想让哪个用户用,在哪个用户的工作区输入该命令。
vim的配置
命令:vim ~/.vimrc
vim下的三种模式
| 模式 | 作用 |
|---|---|
| 正常模式(Normal mode) | 控制屏幕光标的移动,字符、字或行的删除,移动复制某区段及进入Insert mode下,或者到 last line mode |
| 插入模式(Insert mode) | 只有在Insert mode下,才可以做文字输入,按「ESC」键可回到命令行模式。该模式是我们后面用的最频繁的编辑模式。 |
| 末行模式(Last line mode) | 文件保存或退出,也可以进行文件替换,找字符串,列出行号等操作。 在命令模式下,shift+: 即可进入该模式。要查看你的所有模式:打开vim,底行模式直接输入 |
正常模式(Normal mode)下的一些操作
移动操作
| 按键 | 作用 |
|---|---|
| h | 光标向左移动 |
| j | 光标向下移动 |
| k | 光标向上移动 |
| l | 光标向右移动 |
快捷键
| 按键 | 作用 |
|---|---|
| gg | 使光标回到第一行的第一个字符 |
| num+G | num为你想要回到的行号,先输入num,再输入G,即可回到该行第一个字符。 |
删除操作
| 按键 | 作用 |
|---|---|
| x | 从光标所指位置开始,往后进行删除,每次删除光标所指位置 |
| X | 光标位置开始,往前删除,但不删除光标所指元素,只删除光标所指的前一个元素 |
| dd | 为剪切作用,每次删除光标所在的一行,(不粘贴即为删除) |
快捷使用
| 快捷键 | 作用 |
|---|---|
| num+x | num为所要删除的元素个数,表示向后删除num个元素 |
| num+X | 表示向前删除删除num个元素 |
| num+dd | 表示从光标行开始,向下删除num行 |
复制与粘贴操作
复制操作
| 按键 | 目的 |
|---|---|
| yy | 复制光标所在的那一行 |
| num+yy | 从光标开始向下复制num行,包括光标所在行 |
粘贴操作
| 按键 | 目的 |
|---|---|
| p | 将复制的内容 从当前行(光标所在行)的下一行开始进行粘贴 |
| P | 将复制的内容从光标所在行的上一行开始复制 |
替换操作
| 按键 | 目的 |
|---|---|
| r+想要替换的字符 | 相对光标所指的元素按下r,同时接着输入想要替换的内容 |
| R | 由正常模式进入替换模式 |
撤销操作
| 按键 | 目的 |
|---|---|
| u | 撤销 |
| ctrl+r | 反撤销操作 |
测试用例:
首先这是初始文件,此时执行 3 dd操作,向下剪切(删除)9,10,11行
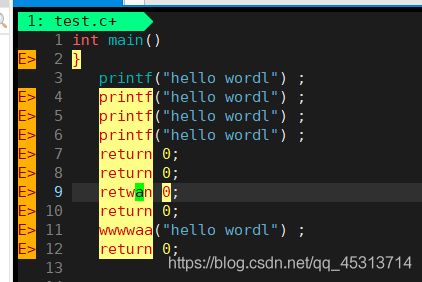
执行后变为这样
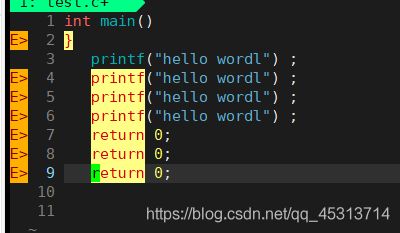
此时按下u他就退回到所给的第一张图片,
按下ctrl+r (一起按的)此时又变为删除后第二张图片所给的那样。
更改操作
| 按键 | 目的 |
|---|---|
| cw | 删除该单词,同时进入插入模式 |
| ctrl+r | 反撤销操作 |
测试用例:
假设我们要更改第9行的return,我们总不能一个一个删吧,此时cw可以直接删除,并进入到插入模式
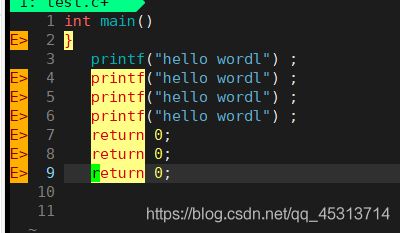
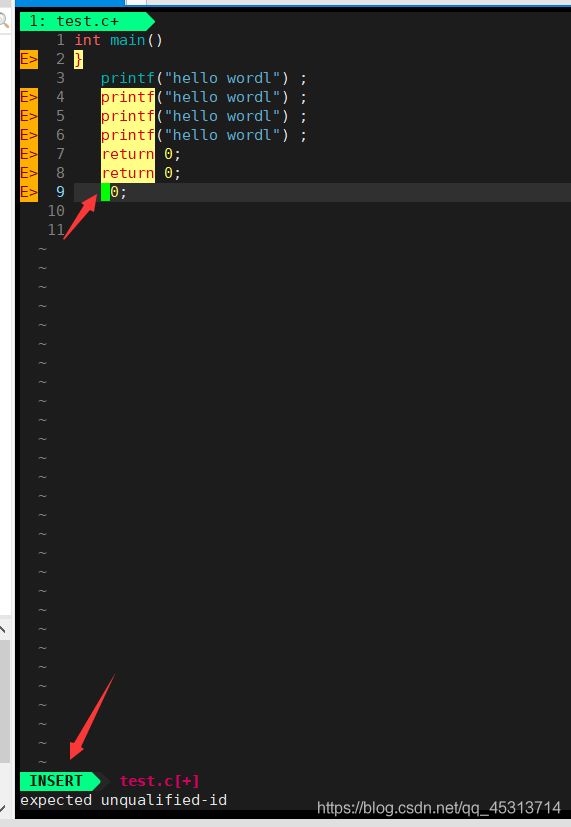
执行cw后效果如上图,此时return已经被删除,并将模式变为插入模式。
整理模式
假设我们此时输入的代码是比较杂乱的,此时便可以输入gg=G,规范化代码,类似与vs底下的shift+k 然后再+f
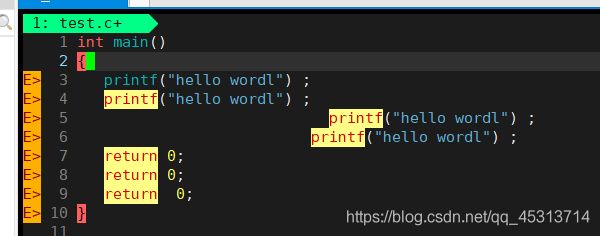
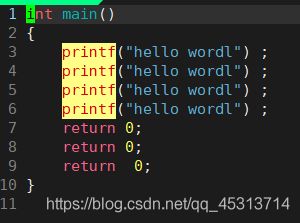
输入gg=G后效果如上图所示。
进入插入模式的常用命令
| 按键 | 作用 |
|---|---|
| o | .首先先进入到插入模式,同时从光标行的下一行开始输入,这里的下一行就类似于在插入模式下走到某一行的末尾,然后回车的效果。这里的下一行是个空行 |
| O | 在上一行进行插入,同时它也是个空行,在normal模式下光标所指的上一行中间加个空行,同时执行插入,类似于给光标行前一行加个语句。 |
| A | 光标指向行的行尾,同时在行尾执行插入操作 |
| I | 光标指向行的行首,在行首进行插入操作。 |
查找某一字符或字符串
此时会进入到底行模式下。
| 输入 | 作用 |
|---|---|
| / | 表示向下查找,在normal模式下先输入一个‘/’再输入想要查找的字符或字符串,按下回车,他会从第1行开始找,按下n的话表示向下再找相同的。 |
| ? | 向上查找,从下往上先找到匹配的,再normal模式下先输入?接着输入想查找的字符或字符串,按下回车,从最后一行依次往上找,找到第一个满足的就停止,此时依然是按‘n’向上接着找。 |
替换操作
命令格式:
%s /[源字符串]/目标的字符串/g
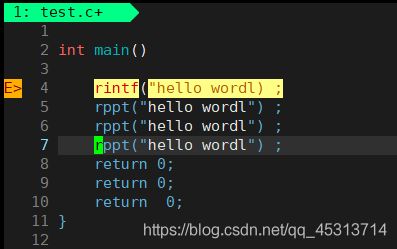
假设我们此时要将rppt替换为printf
首先shift+; 进入到末行模式,然后输入**%s/rppt/printf/g**
%代表的是全文替换,不加的话就是当前行替换
g代表当前行所有目标字符替换,比如此时一行假如说有两个rppt,此时若不加g,则只会替换一个
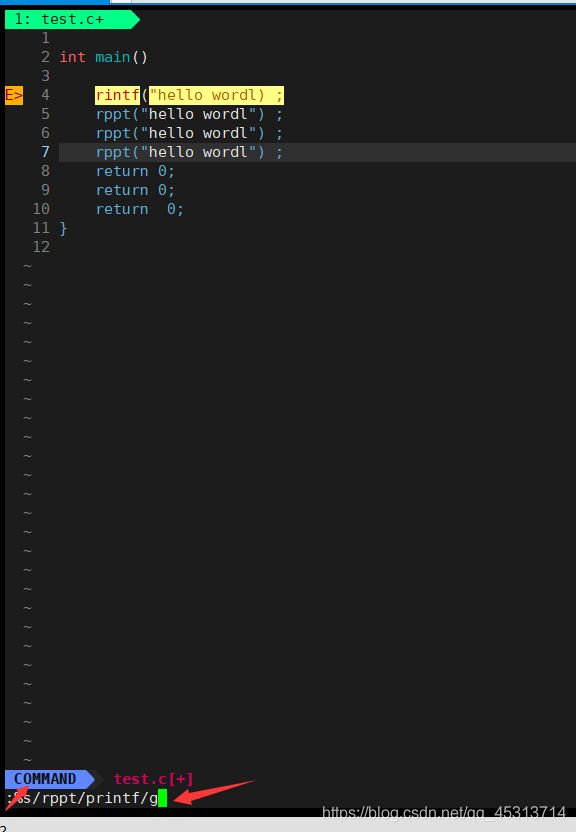
替换后变为
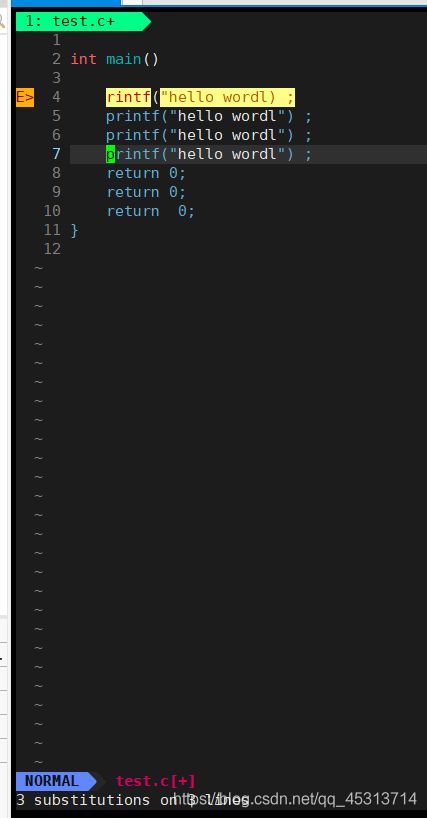
替换成功,并退回到normal模式下。
末行(底行)模式下的操作
当我们执行写入完成后,此时输入shift+;就会进入到底行模式
| 命令 | 意义 |
|---|---|
| q | 不保存退出 |
| wq | 保存并退出 |
| wq! | 保存并强制退出 |
| q! | 强制退出不保存 |
gcc/g++使用
什么是gcc/g++?
gcc是用来编译c语言文件的,g++是用来编译c++文件的。
程序编译的四阶段
| 阶段 | 作用 |
|---|---|
| 预处理 | 1.头文件展开2.替换宏定义 3.替换注释 4.条件编译 生成预处理文件 |
| 编译 | 1.程序的查错2.将代码变为汇编代码,生成汇编文件 |
| 汇编 | 将汇编代码变为机器代码(二进制代码),生成目标文件 |
| 链接 | 将目标文件与库文件链接起来,生成可执行文件 |
阶段1:预处理阶段–生成预处理文件
固定语法:gcc -E 原文件 -o 目标文件.i
目的:对文件进行预处理,同时生成了.i结尾的预处理文件
预处理做了哪些工作?
第一个:头文件展开
第二个:宏替换
第三个:替换注释
第四个:条件编译
这里说明一下条件编译:
利用“#define”定义出的各种宏,我们还可以在预处理阶段实现分支处理,通过判断宏的数值来产生不同的源码,改变源文件的形态,这就是 “条件编译” 。
条件编译还有一个特殊的用法,那就是,使用“#if 1”“#if 0”来显式启用或者禁用大段代码,要比“/* … */”的注释方式安全得多,也清楚得多。
测试用例:
我们此时编辑出一个test,c的文件
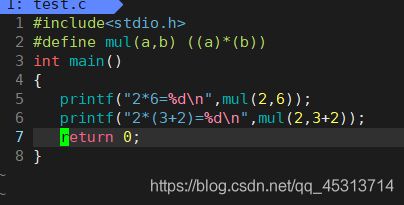
-E为预处理 -o为output的意思
编译出了一个test.i文件。
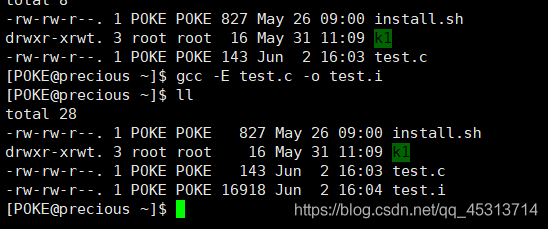
此时我们使用vim打开test.i文件
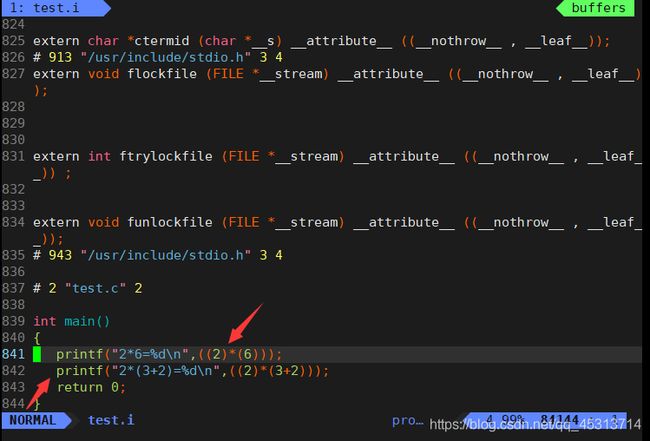
可以看到宏被同义替换了,所以使用宏的时候一定要保证运算的准确性。虽然在test.c中只有不到10行代码,但在预处理时候,却用到了800多行,这是因为对stdio.h头文件进行了展开。
阶段2:编译阶段(整个阶段中最费时间的阶段)
目的:1.对代码的语法进行检查2.将预处理的代码转化为汇编代码
语法: gcc -S 源文件 -o 目标文件.s

请注意,这里既可以使用test.i作为源文件,也可使用 test.c作为源文件
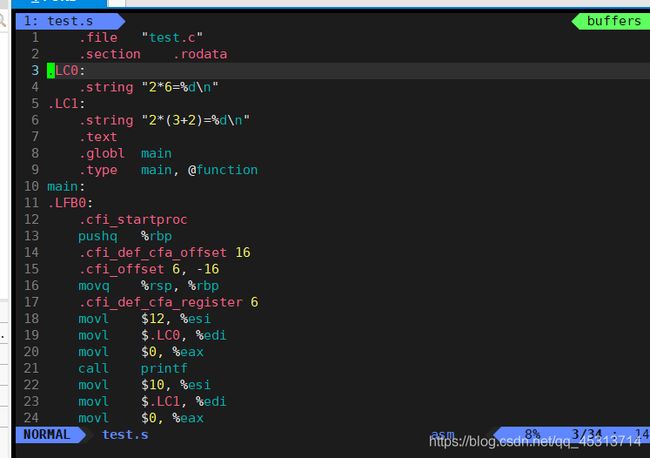
阶段3:汇编 --生成目标文件
目的:将汇编语言转化为机器语言(二进制代码)。
指令格式: gcc -c 源文件 -o 目标文件.o
这里源文件可以是初始文件,也可以是 汇编文件,也可以是预处理文件
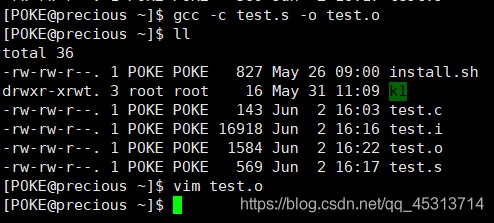
阶段4:链接阶段–生成可执行文件
目的:将汇编阶段生成的目标文件+标准库/自定义库生成可执行代码
命令格式: gcc test.o -o test (test为可执行文件)
同样的这里test.o可以变为任意阶段生成的文件,前提是它存在
测试用例:
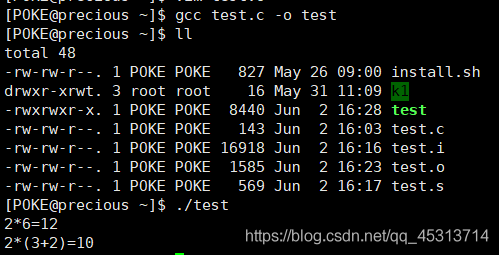
这里我们看到上图我们直接对test.c进行操作,它照样生成了一个可执行文件。
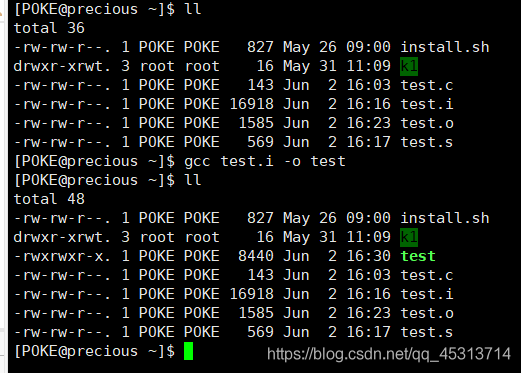
上图我们对.i文件处理,仍然得到一样的效果,那这样是不是想的是我直接对test.c文件进行处理,就不用管中间生成预处理文件、汇编文件、二进制文件那些阶段了?
答案是不是的,作为开发人员,你必须对程序从一个文本文件变为一个可执行文件的阶段非常清楚。
两种不同的链接方式说明:
| 链接方式 | 特点 |
|---|---|
| 动态链接 | 保存符号表,将程序所依赖其他库函数的符号表在链接的时候编译到可执行程序中,下次在别的机器上实现时,直接在别的机器上找,找不到就不可以执行 |
| 静态链接 | 将依赖的函数直接整合到程序中 |
程序默认为动态库
区别:动态库的好处:程序自身比较小一点,不占内存。
缺点:程序的执行依赖于所使用的主机有没有含有所依赖的库函数,没有的话程序无法执行。
静态库的好处:无论主机有没有库函数,都不影响执行。
缺点:因为整合了太多库函数,造成程序臃肿不堪。
测试用例:
首先介绍一下如何生成动态库和静态库
生成静态库:
语法: gcc 源文件 -o 目标文件 -static
没有静态库的可以先执行这样的代码先安装一个静态库
sudo yum install glibc-static
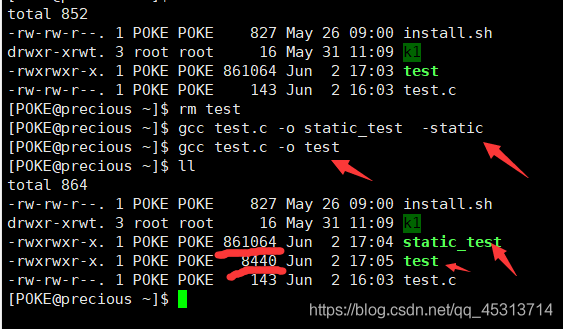
这里我们可以看到 生成的静态库比动态库大了100倍,真的是挺夸张的。
| 库 | 依赖问题 |
|---|---|
| 静态库 | 什么都不依赖,因为所有的库函数都被其整合在一块了 |
| 动态库 | 需要借助运行主机上的库文件,若没有,程序无法执行 |

ldd为查看文件依赖函数的命令
此时采用file命令去查看文件详细信息
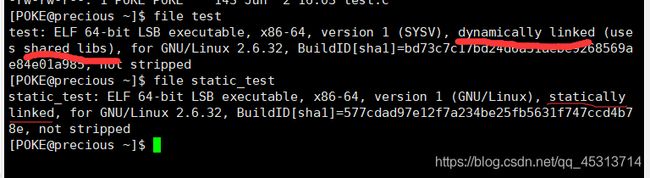
看test文件显示为动态链接的,依赖于共享的库。看static_test文件只给出了它是一个静态链接所生成的。没有给出任何依赖
Linux下的调试
Linux下的debug版本与release版本
| debug版本与release区别 | 区别点 |
|---|---|
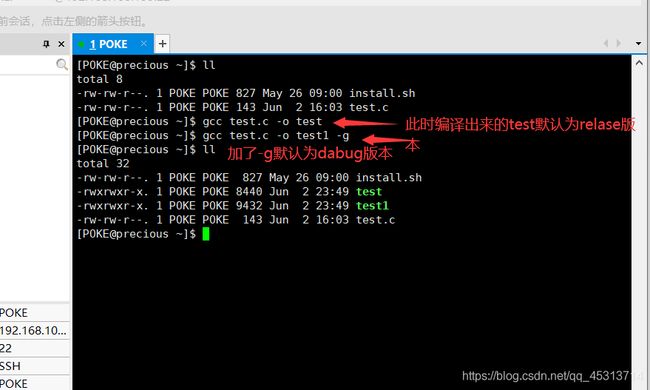
| 在生成方面 | gcc test.c -o test ,此时生成的test是一个可执行程序,默认为release版本。gcc test.c -o test -g 此时生成的便是debug版本 |
| 在大小方面 | debug版本不做优化,所以占用内存比较release版本来说较大 |
| 在调试方面 | debug版本下程序是可以调试的,release版本是不可以进行调试的 |
Linux下的gdb命令(调试命令)
调试命令的前提:文件必须是debug文件
gdb命令格式
gdb +文件名称
| 命令 | 意义 |
|---|---|
| l | 查看文件的内容 |
| r | 让程序运行起来 |
| b+num | 给代码第num行打断点 |
| i b | 查看断点信息 |
| n | 程序逐过程执行 |
| s | 程序逐语句执行 |
| bt/where | 查看调用堆栈 |
| p+变量名 | 查看的是该变量的值 |
gdb下的l命令:可以看到输入该命令后已经可以看到文件内容

gdb下的 r命令:让程序运行起来,一般搭配断点使用
可以看到,这与我们的代码相符,因为此时没有打断点,所以此时会直接输出结果

gdb下的b(break point)断点:让程序执行到断点结束
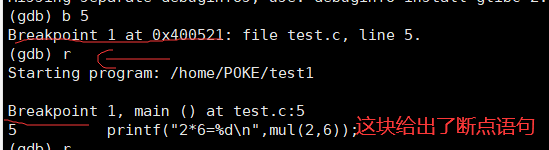
可以看到此时我们再执行r 命令的时候,程序不会走到结束,而会走到断点处结束,同时将断点行所在的语句打印出来,是语句,不是运行结果
gdb下的 i b命令:查看断点信息

此时为了取消该断点,可以执行 这样的操作
此时可以看到程序可以正常运行了,输出了打印结果
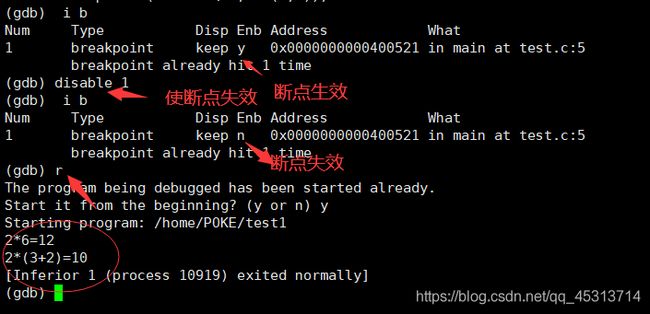
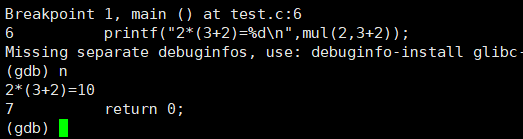
gdb下的n命令:逐过程执行(建立在运行的基础上(r命令))
gdb下的bt/where命令:查看调用堆栈
因为我们要查看调用堆栈,所以先对代码进行修改。
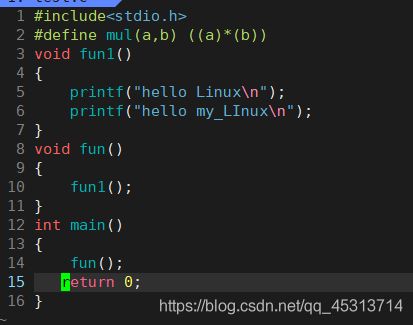
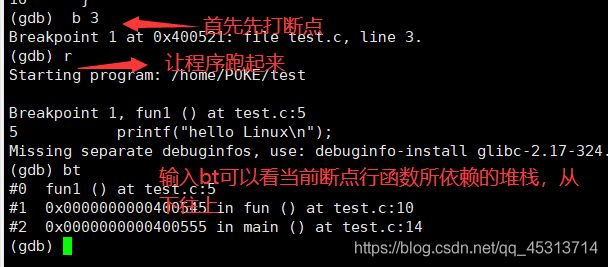
使main()函数先调用的fun(),然后fun()调用的fun1()
Linux下makefile文件的书写
什么是make,什么是makefile
1.make是解释器,解释的是makefile文件,makefile是书写编译规则的文件
2.make对makefile文件进行解释,可以自动化构建项目,自动化生成可执行文件。
3.makefile文件由自己给出
makefile文件书写

这里多了一个test.o是因为依赖文件需要test.o 文件,所以会在makefile或当前目录找test.o文件,若有test.o则不执行makefile中生成test.o文件的操作,否则必须要执行。

makefile的使用规则
| 规则 | 内容 |
|---|---|
| 规则一 | make指令只对makefile/Makefile文件有用 |
| 规则二 | makefile永远只为生成第一个目标对象服务 |
| 规则三 | 若目标对象相对于依赖对象较新,则不生成 |
| 规则四 | makefile生成目标对象时,此时依赖对象也需要生成的话,则先生成依赖对象,最后生成目标对象。 |
规则二:是不是它每次只能生成一个文件,当然不是,看这样的例子:
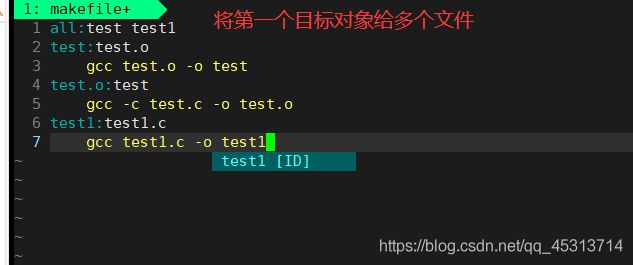
此时生成了test,test1文件
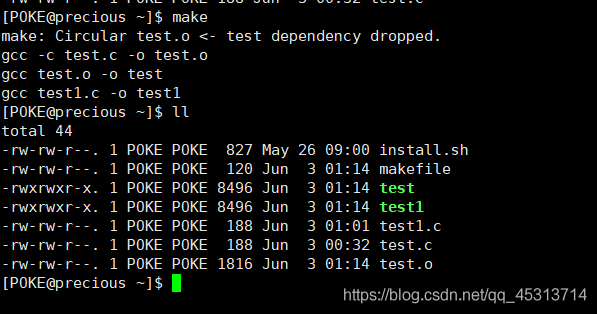
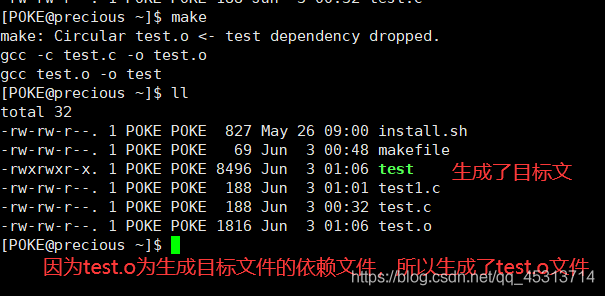
规则四:测试用例

比如此时我们要生成test可执行文件,此时依赖文件为 test.o文件,则先会执行生成test.o的命令,接着再生成,若当前文件夹中有test.o文件的话,则忽略这一步。
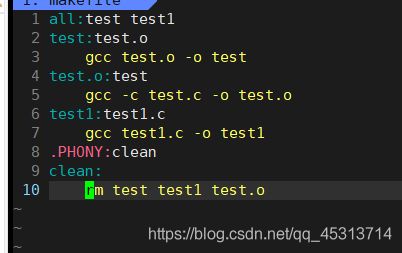
makefile文件下的伪命令
目的:一般用来删除文件用
格式 .PHONY:目标对象
目标对象: 命令

makefile文件的批量化注释

makefile文件下的所有依赖对象与目标对象写法
| 符号 | 含义 |
|---|---|
| $^ | 所有的依赖对象 |
| $@ | 所有的目标对象 |
git工具的使用
| 命令 | 含义 |
|---|---|
| git clone+仓库地址 | 将仓库地址的文件下载到当前目录下 |
| git add*(或者加文件名) | 对文件标记作用,让git工具链去维护 |
| git commit -m"说明" | 将文件上传到本地仓库,同时提交更改日志 |
| git push origin master | 不管是码云还是GitHub,其仓库名称都是orign master,将代码提交上去 |
| git pull | 在仓库目录下执行,将远端仓库下的最新信息拉到本地仓库 |
注意:在推送代码前,必须保证自己目前所处的仓库是最新的,不然可能会造成推送失败,意思是每次push之前,必须先执行 git pull 命令
克隆:
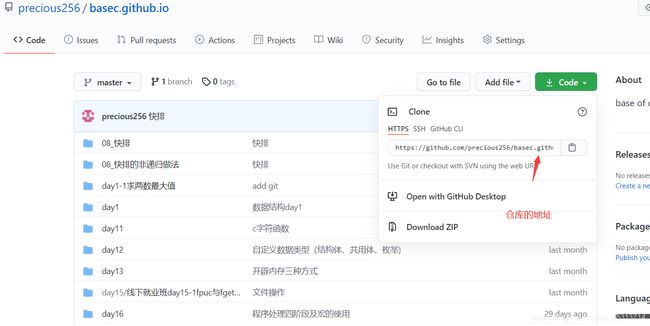
可以看到此时正在克隆

可以看到此时已经克隆到本地了
假设我们此时要上传一个项目的话。
因为笔者这里磁盘满了,所以在windows操作,命令都是一样的
此时标记文件 git add* 或git add test.c
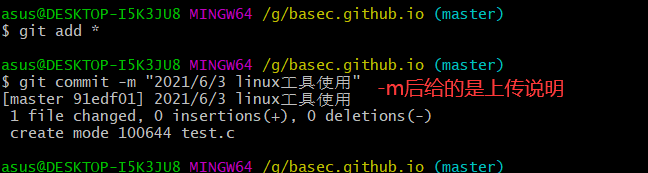
再执行git push origin master命令
将新增文件推送至远端仓库
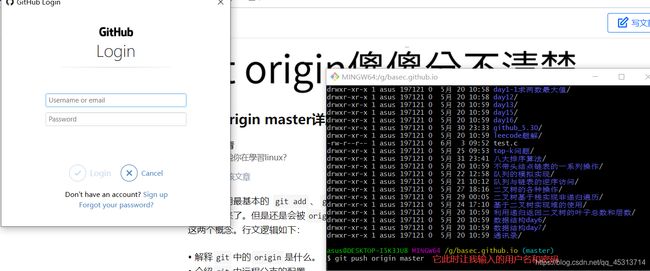
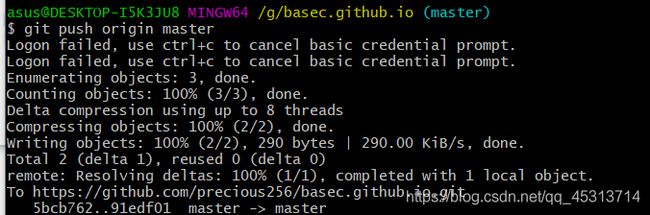
可以看到此时已经上传完成了
![]()
这里看到第一列为我的文件名,后面是我们给的说明,最后一列为时间
git pull 为获取远端仓库的最新信息,在工作中可能有很多的人在管理这个仓库,所以此时你要上传文件的话,但你本地库并不是最新的话,就不可以上传。因为远端仓库默认只接受本地库最新的用户。所以在上传前必须保证自身库就是远端仓库的最新版本。