1.案例说明
数据来源狗熊会,数据完整,无缺失值,错误值
通过网球运动的技术指标探究运动员的技术水平对世界排名的影响
2.变量修改及探索性分析
读取数据
os.chdir(r'C:\Users\Administrator\Desktop\狗熊会数据\5.5 网球运动员战绩分析')
data_f = pd.read_csv('世界前100名女性网球运动员信息.csv',encoding='GBK')
data_m = pd.read_csv('世界前100名男性网球运动员信息.csv',encoding='GBK')
data_m.head()
男性运动员数据

女性运动员数据
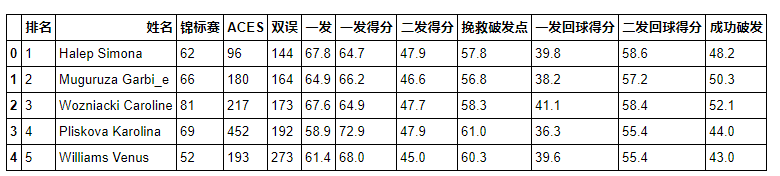
男性运动员费德勒和纳达尔的技术水平指标类比
col_a = ['ACES', '双误']
col_fq = ['一发', '一发得分', '二发得分', '挽救破发点']
col_jq = ['一发回球得分', '二发回球得分', '成功破发']
data_js = data_m[col_fq+col_jq]
data1 = data_js[data_m['姓名']=='Rafael Nadal']
data2 = data_js[data_m['姓名']=='Roger Federer']
c_chema = []
for i in data_js.columns:
dict ={}
dict['name'] = i
dict['max'] = 100
dict['min'] = 0
c_chema.append(dict)
c_chema
from pyecharts import Radar
radar = Radar('各项技术水平比较')
radar.config(c_schema=c_chema)
radar.add('纳达尔',[data1.iloc[0]],is_area_show=True,area_opacity=0.6,area_color='#F25F5C')
radar.add('费德勒',[data2.iloc[0]],is_area_show=True,area_opacity=0.6,area_color='#247BA0')
radar

男性运动员和女性运动技术水平指标类比
datam_js = data_m[col_fq+col_jq]
dataf_js = data_f[col_fq+col_jq]
from pyecharts import Radar
radar = Radar('各项技术水平比较')
radar.config(c_schema=c_chema)
radar.add('男性运动员',[datam_js.mean()],is_area_show=True,area_opacity=0.6,area_color='#F25F5C')
radar.add('女性运动员',[round(dataf_js.mean(),2)],is_area_show=True,area_opacity=0.6,area_color='#247BA0')
radar

ACE,双误变量为统计运动员所有参赛的ACE和双误数,将其转变为参赛数为基准的计数
运动等级排名分类成'TOP25','TOP25-50','TOP50-75','TOP75-100'
data_f['等级']=pd.cut(data_f['排名'],bins=(0,25,50,75,100),labels=['TOP25','TOP25-50','TOP50-75','TOP75-100'])
data_m['等级']=pd.cut(data_m['排名'],bins=(0,25,50,75,100),labels=['TOP25','TOP25-50','TOP50-75','TOP75-100'])
data_f['ACES数'] = data_f['ACES']/data_f['锦标赛']
data_m['ACES数'] = data_m['ACES']/data_m['锦标赛']
data_f['双误数'] = data_f['双误']/data_f['锦标赛']
data_m['双误数'] = data_m['双误']/data_m['锦标赛']
男性选手等级和ACE数,双误数的相关性
fig,ax = plt.subplots(ncols=2,figsize=(10,4))
sns.boxplot(x='等级',y='ACES数',data=data_m,ax=ax[0])
sns.boxplot(x='等级',y='双误数',data=data_m,ax=ax[1])
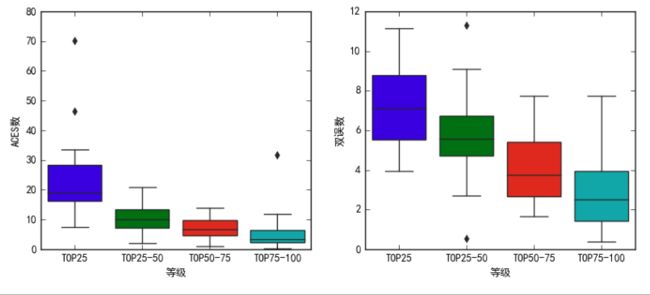
ACE数,双误数与运动员等级有明显相关性
其中某些运动员ACES数达到40以上,了解一下这些运动员

安迪穆雷和德约科维奇都是擅长发球的选手
女性选手等级和ACE数,双误数的相关性
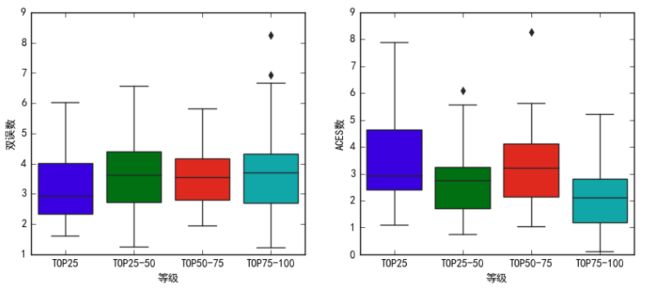
通过方差分析探究一下女性选手等级和ACE数,双误数的相关性
import statsmodels.api as sm
from statsmodels.formula.api import ols
ana1 = ols('双误数~C(等级)',data=data_f).fit()
sm.stats.anova_lm(ana1)
ana2 = ols('ACES数~C(等级)',data=data_f).fit()
sm.stats.anova_lm(ana2)


F值偏小,女性双误数/ACES数与等级相关性都不显著
3.构建模型
对男性运动员构建模型
#定义自标量标签
cols = data_m.columns.tolist()
cols.remove('排名')
cols.remove('锦标赛')
cols.remove('ACES')
cols.remove('双误')
cols.remove('姓名')
cols.remove('等级')
#相关性分析
corr = data_m[cols].corr()
plt.figure(figsize=(10,7))
sns.heatmap(corr,vmax=1,annot=True)
#一发变量与其他变量相关性不高,剔除一发属性
cols.remove('一发')

各变量间相关性较高,一发成功率与其他变量相关性不高,剔除该变量,其他变量做降维处理
由于因子分析具有较好的解释性,选择因子分析法降维
- 对变量进行标准化处理
#z-score 标准化
from sklearn.preprocessing import scale
data_zs = scale(data_m[cols])
- 对变量进行主成分分析法
from sklearn.decomposition import PCA
pca = PCA()
pca.fit(data_zs)
#查看累计贡献度
pca.explained_variance_ratio_.cumsum()
array([ 0.34301552, 0.56753275, 0.65095733, 0.7158034 , 0.77711738,
0.83333131, 0.87353708, 0.91081821, 0.94416561, 0.9682807 ,
0.98886887, 1. ])
累计贡献度显示5个主成分能解释77%的变异数据
可以选取4-6个因子
- 用方差最大化做因子转化,保留五个公共因子
from fa_kit import FactorAnalysis
from fa_kit import plotting as fa_plot
#数据导入和转化
fa = FactorAnalysis.load_data_samples(data_zs,preproc_demean=True,preproc_scale=True)
#抽取主成分
fa.extract_components()
#确认保留因子的数量,使用top_n法
fa.find_comps_to_retain(method='top_n',num_keep=5)
#使用最大方差法进行因子旋转
fa.rotate_components(method='varimax')
#制图
fa_plot.graph_summary(fa)

最大方差法进行因子旋转后各因子界限更加明显
- 查看个因子在各变量上权重,定义各因子
#查看个因子在各变量上权重
fas = pd.DataFrame(fa.comps['rot'],index=cols)
fas

因子0在一发得分,ACES数,双误数权重较大,球员表现较为注重发球得分,定义为发球因子
因子1在一发回球得分,二发回球得分,成功破发权重较大,球员表现较为注重回球得分,定义为回球因子
因子2在二发得分,首盘告负权重较大,球员表现在先失球后赢球,较为抗压,定义为抗压因子
因子3在抢七权重较大,定义为抢七因子
因子4在首盘获胜,决胜盘权重较大,球员表现在顺风局获胜概率大,定义为顺风因子
- 将各球员表现转化为因子得分
#将各球员表现转化为因子得分
score = pd.DataFrame(np.dot(data_zs,fas))
score.columns = ['发球因子','回球因子','抗压因子','抢七因子','顺风因子']
score['等级'] = data_m['等级']
score.head()

费德勒和纳达尔各因子(技术水平)对比
from pyecharts import Radar
c_schema=[]
for i in score.columns[:-1]:
dict = {}
dict['name'] = i
dict['max'] = score[i].max()
dict['min'] = score[i].min()
c_schema.append(dict)
c_schema
radar1 = Radar('费纳技术对比')
radar1.config(c_schema=c_schema)
color = ['#50514F','#F25F5C']
radar1.add('纳达尔',[score.iloc[0,:-1]],is_area_show=True,area_opacity=0.6,area_color='#F25F5C')
radar1.add('费德勒',[score.iloc[1,:-1]],is_area_show=True,area_opacity=0.6,area_color='#247BA0')
radar1
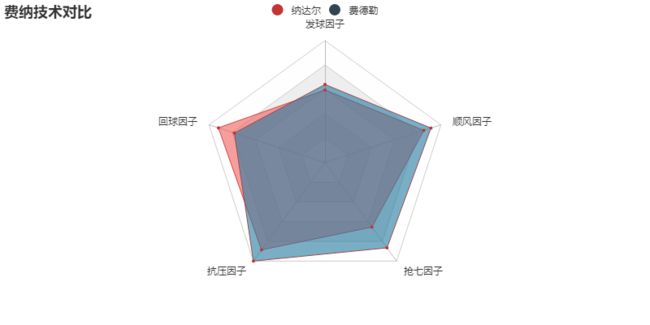
费德勒技术较为全面在抗压方面最为突出,纳达尔在回击球方面较为突出
男性运动员各等级各项因子得分
#各等级各项因子得分
score_top = score.groupby('等级').mean()
radar2 = Radar('男性网球运动各项因子均值')
radar2.config(c_schema=c_schema)
color = ['#D63E34','#304454','#619FA8','#D48465']
for i in range(len(score_top)):
radar2.add(score_top.index[i],[score_top.iloc[i]],is_area_show=True,area_opacity=0.6,area_color=color[i])
radar2

排名靠前的运动员全面领先其他运动
使用决策树选择影响排名的重要因素
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(max_depth=3)
dt.fit(score.iloc[:,:-1],score.iloc[:,-1:])
pd.Series(dt.feature_importances_,index=score.columns[:-1])
发球因子 0.352640
回球因子 0.088491
抗压因子 0.329660
抢七因子 0.164658
顺风因子 0.064551
对排名影响最大的变量分别为发球,抗压和抢七
绘制决策树
from sklearn import tree
from sklearn.externals.six import StringIO
import graphviz
dot_data = StringIO()
tree.export_graphviz(dt, out_file=dot_data,
feature_names=score.columns[:-1],
class_names=['top25','top25-50','top50-75','top75-100'],
filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data.getvalue())
graph
