摘要:教你如何快速爬取一个网页信息;urllib模块中常用的方法介绍;通过修改头信息来伪装成浏览器访问页面;Get请求和Post请求的介绍
*写在前面:为了更好的学习python,博主记录下自己的学习路程。本学习笔记基于廖雪峰的Python教程,如有侵权,请告知删除。欢迎与博主一起学习Pythonヽ( ̄▽ ̄)ノ *
目录
常用内置模块
urllib
简单爬虫
urlopen
urllib的常用方法
模拟浏览器
Get请求(百度搜索关键字)
Post请求(登录新浪微博)
小结
常用内置模块
urllib
Urllib是Python内置的HTTP请求库,或者说,就是用来操作URL的。在爬虫的时候常用到这个库。
简单爬虫
要爬取网页信息,首先我们要引入urllib.request模块,这是一个请求模块。
然后通过urllib.request的urlopen( )方法来打开一个网页。
最后使用read( )方法来获取网页信息。
我们以百度http://www.baidu.com为例
import urllib.request
f = urllib.request.urlopen ('http://www.baidu.com')
data = f.read()
这样我们就获取了该网页的内容,此外,我们还要把它保存下来。
添加一个html文件,然后把data写进去:
import urllib.request
f = urllib.request.urlopen ('http://www.baidu.com')
data = f.read()
with open('./1.html','wb') as fh:
fh.write(date)
此时,我们打开指定目录下的1.html,就能看到我们爬取的网页了。(是不是炒鸡简单(* ̄︶ ̄))
urlopen
我们都知道urlopen()函数是用来打开url的,实际上它参数不止url一个。
urllib.request.urlopen()函数参数介绍:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
常用的参数是前三个:url,data,timeout。
url 是需要打开的网址;
data 是需要传入的数据,一般在get请求方式使用;
timeout 是超时时间,当网络请求过慢,超过timeout设置的时间,就会给出异常,而不是一直等待结果。
urllib的常用方法
下面看一些简单常用的urllib用法。
| 方法 | 作用 |
|---|---|
| info() | 返回网页的当前环境有关信息 |
| getcode() | 返回网页状态码,若为200则正确,若为其他则错误 |
| geturl() | 返回网页的url |
| urllib.request.quote() | 对网址进行编码 |
| urllib.request.unquote() | 对网址进行解码 |
例子:
>>>import urllib.request
>>>f = urllib.request.urlopen ('http://www.baidu.com')
>>>f.info()
Bdpagetype: 1
Bdqid: 0x8915e4020002cb95
...
Transfer-Encoding: chunked
>>>f.getcode()
200
>>>f.geturl()
http://www.baidu.com
>>>urllib.request.quote('http://www.baidu.com')
http%3A//www.baidu.com
>>>urllib.request.unquote('http%3A//www.baidu.com')
http://www.baidu.com
模拟浏览器
有时候,我们爬取网页的时候会出现错误,这是因为这些网页为防止恶意获取信息进行了反爬虫设置。
为避免这种情况,一般而言我们会模拟成浏览器去访问网页。
要模拟成浏览器,就需要添加Headers信息,即头信息。通过设置User-Agent可以让爬虫模拟成浏览器。
如何添加Headers信息呢?这里需要用到urllib模块中的urllib.request.Requset()函数。
调用urllib.request.Requset()函数可以创建一个request对象,调用时传入三个参数,第一个为url即网址信息,第二个为数据,默认为0,第三个为headers,即需要添加的头信息,要以dict类型传入,默认为不传头部。
随后,调用urllib.request.urlopen()打开request对象,就能实现模拟成浏览器访问网页了。
看一下具体的代码:
import urllib.request
url='http://www.baidu.com' # 设置url的值
header={ # 设置header的值
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.98 Safari/537.36'
}
request = urllib.request.Request(url, headers = header) # 调用Request函数
data = urllib.request.urlopen(request).read() # 访问网页
with open('./1.html', 'wb') as fh: # 创建html文件并把数据保存下来
fh.write(data)
还有个问题是怎么得到这个User-Agent的信息呢?
有个简单的方法:使用浏览器打开任意一个网页,按F12,在弹出的界面的上方找到Network,点击后会出现一些文件,点击其中的一个,点击右边的header,在里面就有User-Agent信息。
(参考下图进行操作(`・ω・´))
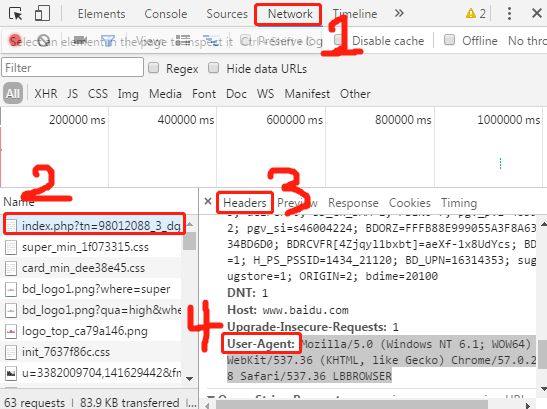
那么User-Agent表示什么呢?
User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
标准格式为: 浏览器标识 (操作系统标识; 加密等级标识; 浏览器语言) 渲染引擎标识 版本信息
——百度百科
Get请求(百度搜索关键字)
如果要进行客户端与服务器端之间的消息传递,我们可以使用HTTP协议请求进行。
在本节内容中介绍两种常用的请求:Get和Post。先来看一下Get请求。
Get请求,通过URL网址传递信息。我们可以把数据直接放在URL中,从而得到想要的信息。
以百度搜索为例子。
当我们用百度搜索Python时,仔细观察url会发现,其中有wd=Python的字段。
事实上,wd字段就是表示搜索的关键字,那么通过Get请求,就可以实现用爬虫自动使用百度搜索了:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import urllib.request
url='http://www.baidu.com/s?wd='
key=urllib.request.quote('三贝的博客') # 由于URL含有中文,需要编码
url_all=url+key
header={ # 头部信息
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.98 Safari/537.36'
}
request = urllib.request.Request(url_all, headers=header)
data = urllib.request.urlopen(request).read()
with open('./search三贝的博客.html', 'wb') as f: # 写入文件中
f.write(data)
打开指定目录下的html文件,显示的就是搜索指定关键字的页面啦( ̄▽ ̄)~*。
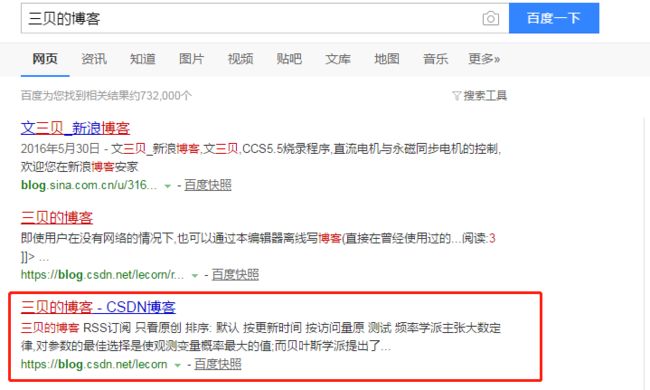
Post请求(登录新浪微博)
Post请求即向服务器发送数据,然后请求执行相应的操作。比如登录用户。
我们只要把需要发送的数据放进data里面,然后传进urlopen的data参数即可。
下面以登录新浪微博为例(以下代码除注释转自廖雪峰官网):
from urllib import request, parse
print('Login to weibo.cn...')
email = input('Email: ') # 用户输入登录的邮箱名
passwd = input('Password: ') # 用户输入登录的密码
login_data = parse.urlencode([ # 登录数据,用dict类型储存,parse.urlencode将dict转为url参数
('username', email),
('password', passwd),
('entry', 'mweibo'),
('client_id', ''),
('savestate', '1'),
('ec', ''),
('pagerefer', 'https://passport.weibo.cn/signin/welcome?entry=mweibo&r=http%3A%2F%2Fm.weibo.cn%2F')
])
req = request.Request('https://passport.weibo.cn/sso/login')
req.add_header('Origin', 'https://passport.weibo.cn')
req.add_header('User-Agent', 'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25')
req.add_header('Referer', 'https://passport.weibo.cn/signin/login?entry=mweibo&res=wel&wm=3349&r=http%3A%2F%2Fm.weibo.cn%2F')
with request.urlopen(req, data=login_data.encode('utf-8')) as f:
print('Status:', f.status, f.reason) # 返回页面执行的状态
for k, v in f.getheaders(): # 得到HTTP相应的头和JSON数据
print('%s: %s' % (k, v))
print('Data:', f.read().decode('utf-8')) # 得到页面信息
如果登录成功( ̄▽ ̄)/,我们获得的响应如下:
Status: 200 OK
Server: nginx/1.6.1
...
Set-Cookie: SSOLoginState=1535461471; path=/; domain=weibo.cn
...
Data: {"retcode":20000000,"msg":"","data":{...,"uid":"2237339025"}}
如果登录失败(T▽T)/,我们获得的响应如下:
...
Data: {"retcode":50011015,"msg":"\u7528\u6237\u540d\u6216\u5bc6\u7801\u9519\u8bef","data":{"username":"[email protected]","errline":665}}
小结
urllib提供的功能就是利用程序去执行各种HTTP请求。
关于Python爬虫的知识点还有很多,本节只是对urllib模块进行简单的介绍,供想Python入门的人儿学习,往后会有更详细的内容介绍ヾ(o・ω・)ノ。
以上就是本节的全部内容,感谢你的阅读。
下一节内容:常用内置模块之 XML
有任何问题与想法,欢迎评论与吐槽。
和博主一起学习Python吧( ̄▽ ̄)~*