SparkContext内部执行的时序图

对于这个时序图的具体描述如下:
1.SparkSubmit在main()方法中执行,然后根据提交的类型调用相应的方法,这里是"Submit",调用submit()方法,submit()里面进行一些判断后,
使用反射Class.forName(childMainClass, true, loader),然后调用invoke()方法来调用程序员自己写的类,我们这里是WordCount。
2.在WordCount类中,main()方法里有调用SparkContext,SparkContext构造器使用createSparkEnv()方法,
这个方法使用SparkEnv.createDriverEnv(conf, isLocal, listenerBus)方法创建SparkEnv对象;
在SparkEnv类,调用create()方法来进行创建SparkEnv,在这个方法内部,有一个
AkkaUtils.createActorSystem(actorSystemName, hostname, port, conf, securityManager)的调用过程,
主要用来产生Akka中的ActorSystem以及得到绑定的端口号。
3.在创建SparkEnv对象后,SparkContext构造器使用代码SparkContext.createTaskScheduler(this, master)创建TaskScheduler对象,
这里根据实际的提交模式来进行创建TaskScheduler对象,提交模式有:local、Mesos、Zookeeper、Simr、Spark,
这里模们主要分析Spark集群下的模式;然后还需要创建一个SparkDeploySchedulerBackend对象;
在创建TaskScheduler对象调用initialize()方法,这里选择调度模式,主要有两种模式,FIFO和FAIR,默认的调度模式;
最后调用taskScheduler的start()方法,里面主要调用SparkDeploySchedulerBackend对象的start()方法,
首先调用父类的start()方法产生一个用于和Executor通信的DriverActor对象,然后里面主要创建一个AppClient对象内部有ClientActor类对象,
用于Driver和Master进行RPC通信。
SparkContext源码分析流程
1.SparkSubmit半生对象的源码
1.1SparkSubmit的main()函数在SparkSubmit半生对象的104行左右,这个是程序的主要入口:

接下来主要进入submit()方法,下面是submit()方法
1.2SparkSubmit的submit()方法,代码大约在142行左右, 这个方法的主要作用是根据不同的模式使用runMain()方法:


1.3SparkSubmit的runMain()方法,代码大约在505行左右,这个方法主要的主要作用是通过反射获取自定义类,这里我们主要的是WordCount,然后通过invoke方法调用main 这里是方法的重要代码:

调用WordCount的main()方法后,接下来就要看SparkContext的内部了。
2.SparkContext内部源码分析
很重要:SparkContext是Spark提交任务到集群的入口
我们看一下SparkContext的主构造器
1.调用createSparkEnv方法创建SparkEnv,里面有一个非常重要的对象ActorSystem
2.创建TaskScheduler -> 根据提交任务的URL进行匹配 -> TaskSchedulerImpl -> SparkDeploySchedulerBackend(里面有两个Actor)
3.创建DAGScheduler
2.1创建SparkEnv获取ActorSystem,代码大约在275行左右,这一步的主要的作用是创建ActorSystem对象以后根据这个对象来创建相应的Actor

主要调用SparkEnv类的createDriverEnv()方法获取SparkEnv对象,createDriverEnv()主要调用SparkEnv的create()方法,这里代码大约
在SparkEnv的154行,代码具体如下:

createDriverEnv()内部主要调用create()方法,代码大约在202行,重要的代码如下:
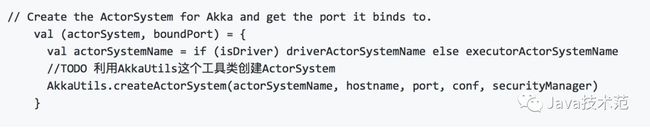
这个方法的主要作用是调用AkkaUtils这个工具类创建ActorSystem。
2.2创建TaskScheduler,代码大约在374行,重要的代码如下:

这里调用createTaskScheduler()方法,这个类主要的作用是根据提交的类型创建相应的TaskScheduler(),这里主要分析Spark集群下,主要的代码如下:

这里进行模式匹配,以上代码大约在SparkContext的2159行,主要的作用是创建TaskSchedulerImpl对象,然后初始化调度器这里,需要看的是initialize(),主要的实现是
TaskSchedulerImpl类,这里我们将会深入TaskSchedulerImpl类的initialize()方法,下面是该方法的实现:

主要用于调度的模式,调度模式主要分为FIFO和FAIR。在进行创建了TaskScheduler对象后,我们再来看一下主要的代码:

上述代码中,这里主要用于创建一个HeartbeatReceiver对象来进行心跳,用于Executors和DriverActor的心跳。
然后创建DAGScheduler对象,这个对象的主要作用是用来划分Stage。
2.3TaskScheduler进行启动,代码大约在395行,重要的代码如下:

由于这里是TaskScheduler的主要的实现类是TaskScheduler是TaskSchedulerImpl类,我们要进入的源码是:

主要调用了SparkDeploySchedulerBackend的start()方法,接下来我们需要看SparkDeploySchedulerBackend内部实现。
以下是SparkDeploySchedulerBackend的构造器函数,这个代码大约在SparkDeploySchedulerBackend的45行重要的代码如下:


从上面的代码可以看出首先调用父类(CoarseGrainedSchedulerBackend)的start()方法,然后对于一些重要的参数进行封装,这里最重要的参数是
CoarseGrainedExecutorBackend类,还有一些driverUrl和WORKER_URL等参数的封装,将CoarseGrainedExecutorBackend
封装成Command,这是一个样例类,不知道样例类请点击这里,将这个参数封装成为一个
ApplicationDescription对象,创建一个AppClient对象,这个对象主要用于Driver和Master之间的通信,以下我们分析start()方法后再分析client.start()。
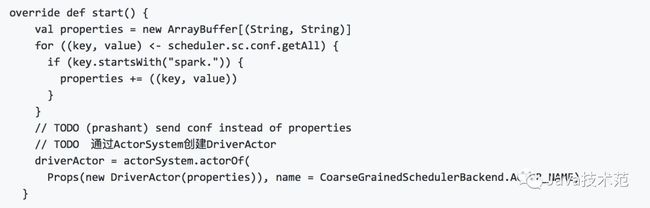
可以从上面的代码看出, 这里主要创建一个DriverActor,这个Actor的主要的作用是Driver进程和Executor进程进行RPC通信
在分析完以上的CoarseGrainedSchedulerBackend的start()方法后,这里主要进行的源码分析是client.start()方法这里创建一个ClientActor,准确来说是这个
ClientActor来和Master通信。
现在,这里就调用ClientActor的生命周期方法,对于Akka通信不了解的,请点击这里进行了解Actor的生命周期方法。
Akka的Actor的生命周期方法主要从preStart()方法开始,这行代码大约在67行左右,主要的内容如下:

在preStart()方法中主要做的事情是向Master注册,registerWithMaster()的主要内容是:

这个方法主要是向活着的Master进行注册,将以前所有的参数封装的appDescription发送给Master,然后启动定时调度器进行和Master的注册,因为有可能进行多次通信。
Master收到通过样例类的模式匹配,对于Driver向Master注册Application,主要的作用是持久化Driver传递的参数和进行资源调度.
主要的代码大约在Master类的315行,主要的代码如下:

这段代码的意义是:持久化信息,告知ClientActor发送注册成功的信息,然后适使用schedule()进行资源的调度。
对于schedule()方法,代码大约在533行,这里的主要作用是进行资源调度,主要的是两种资源调度的方法,一种是尽量打散的分配资源,还有一种是尽量集中。

对于尽量打散的方式:将每个app分配到尽可能多的worker中执行
App调度时会为app分配满足条件的资源-----Worker(State是Alive,其上并没有该Application的executor,可用内存满足要求(spark.executor.memory指定,默认512),
核满足要求(spark.cores.max, 最大可用core数,若未指定,则为全部资源)),然后通知Woker启动Excutor. 及向AppClient发送ExecutorAdded消息。
进行调度时,调度程序会根据配制SpreadOutApps = spark.deploy.spreadOut情况决定资源分配方式。
1 从列表中取下一app,根据CPU情况找出合适的woker,按核从小到大排序
2 如果worker节点存在可以分配的core 则进行预分配处理(轮循一次分一个直至满足app需求),并在分配列表(assigned = ArrayInt)中计数。
3根据assinged列表中的预分配信息,进行分配Executor(真实分配)
4 启动Executor并设置app.state = ApplicationState.RUNNING
尽情集中的方式: 将每个app分配到尽可能少的worker中执行。 1 从可用的worker列表中取下一work. (worker <- workers if worker.coresFree > 0)
2 遍历waitingApps 找到满足app运行条件的app,进行分配
3启动Executor(launchExecutor(w,e))并设置app.state = ApplicationState.RUNNING
其中:launchExcutor(worker, exec) 具体内容如下:
向executor分配给worker
通知worker启动executor
由分配过程可知, 分配的Excutor个数与CPU核心数有关。当指定完Worker节点后,会在Worker节点创建ExecutorRunner,并启动,执行App中的Command
去创建并启动CoarseGrainedExecutorBackend。CoarseGrainedExecutorBackend启动后,会首先通过传入的driverUrl这个参数向
在CoarseGrainedSchedulerBackend::DriverActor(用于与Master通信,及调度任务)发送RegisterExecutor(executorId, hostPort, cores),
DriverActor会创建executorData(executor信息)加入executorDataMap供后续task使用,并回复RegisteredExecutor,
此时CoarseGrainedExecutorBackend会创建一个org.apache.spark.executor.Executor。至此,Executor创建完毕。
Executor是直接用于task执行, 是集群中的直接劳动者。至此,资源分配结束。
百度脑图关于作业提交以及SparkContext的示意图
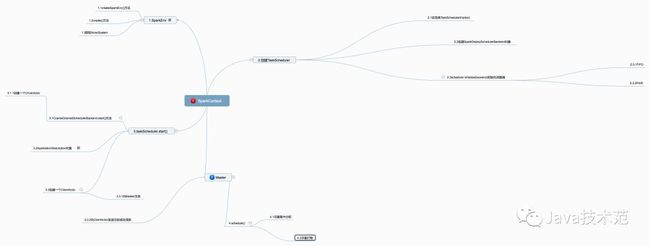
注意:这里的SparkContext和Master是两个独立的类,由于Baidu脑图不能独立划分,所以看起来像父子类关系。
总结
在SparkContext(这里基于Spark的版本是1.3.1)主要做的工作是:
1.创建SparkEnv,里面有一个很重要的对象ActorSystem
2.创建TaskScheduler,这里是根据提交的集群来创建相应的TaskScheduler
3.对于TaskScheduler,主要的任务调度模式有FIFO和FAIR
4.在SparkContext中创建了两个Actor,一个是DriverActor,这里主要用于Driver和Executor之间的通信;还有一个是ClientActor,主要用于Driver和Master之间的通信。
5.创建DAGScheduler,其实这个是用于Stage的划分
6.调用taskScheduler.start()方法启动,进行资源调度,有两种资源分配方法,一种是尽量打散;一种是尽量集中
7.Driver向Master注册,发送了一些信息,其中一个重要的类是CoarseGrainedExecutorBackend,这个类以后用于创建Executor进程。