这是AI+教育的入门科普文系列第一篇,敬请不要期待第2/3/4篇。
作为一个物理老师,一个PM或者说一个硬件工程师,我学过约40小时的AI知识,总计10本书+10多个网站+2个不同背景的人闲聊,在AI+教育领域尚在入门阶段,欢迎各路大神来揪其中的不靠谱,一起UP。
AI是个啥?
是个啥呀是个啥?曾经有个老师说是机器学习,攻城狮老公说是概率,两种说法都叫我将信将疑,囫囵整合下,我理解的AI,或者说人工智能是:
在给力的计算芯片上,算法通过“学习”数据,完成自我进化,形成模型,通过模型让相关联的东东达成一定概率的匹配,最终达到模拟、延伸或扩展人的智能的目的。
比如说,在一次远程公开课上,王老师不仅仅需要给台下的30个小学生讲课,还要通过智慧屏远程连接山村里的50个孩子,他是第一次给村里的孩子上课,却能够叫出每个孩子的名字,因为通过学习海量有批注的数据,算法完成了自我进化,构建出一个模型,通过该模型,它将视频中的人像和数据库中的数据做对比,实现了视频中孩子和姓名的匹配,王老师可以在教室里的大屏上看到孩子和他们的姓名。
提到人工智能,我们常常绕不开如下关键词:
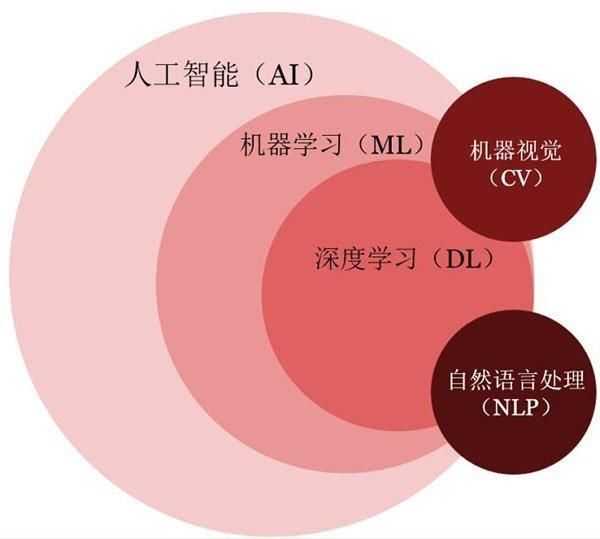
其中机器学习是人工智能的一种途径或子集,也是人工智能的核心,它从数据出发,通过复杂的算法和运算能力,寻找一切数据背后的规律,它强调的是数据的学习。简单的机器学习算法的性能,很大程度上依赖于人为给定数据的特征,比如说猫,它的特征有长着毛茸茸的毛、顶着一对三角形的的耳朵等,特征的选取决定了机器学习的效果。
而深度学习算法可以自己提取数据特征。
总之,人工智能是技术,是工具,也是新的产品设计思维逻辑。它有三个要点:算力、算法和算据。
1 算力
也就是说计算能力,这种能力用于支持机器学习的训练和推算环节,其中推算环节根据芯片的位置,又可以分为云端推断和设备端推断。
根据定制化程度,人工智能芯片又被分为通用芯片、半定制化芯片和全定制化芯片三种。
①通用型:CPU、GPU、TPU等模块阵列,它们可以处理几乎所有类型任务,价格相对较高且运算速度相对较低。
②半定制化:FPGA(Field Programmable Gate Array)可编程门阵列,是一种集成大量门电路和存储器的芯片,可以通过配置文件来定义门电路及存储器间的走线,从而实现特定功能。其本质是用硬件实现软件算法。针对小计算量、大批次的计算,性能优于GPU,另外它有低延迟的特点,适合在推断环节支撑海量的用户实时计算并发请求。
③全定制化:ASIC(Application Specific Integrated Circuits)应用专用集成电路,是为专门目的而设计的集成电路,设计成本高,周期长,但运算效率高,功耗小,量产时,单个芯片的造价低。
结合FPGA和ASIC的特点,在实际应用时,我们可以先将芯片原型以FPGA形式做出来,在市场中进行充分的测试和调整,然后再进行ASIC生产。
2 算法
算法是指解决方案的准确而完整的描述,是一系列解决问题的清晰指令,它代表着用系统的方法描述解决问题的策略机制。
有一个与之容易混淆的名词叫“模型”,它是指通过数据对算法进行训练后生成的“中间件”,当有新的数据输入时,有相应的结果输出,它和算法的关系如下:

①根据模型训练方式不同,算法可以分为如下几类:
监督学习可以用于识别图片中的动物是猫还是狗,训练集中的图片要包括明确的猫或狗的标签;而无监督学习的训练数据没有标签,比如说在搜索引擎中,借助无监督学习将来自不同类型网站的相似的网页聚类在一起;半监督学习是是在无监督学习中混入一些有标签的数据,其本质上更接近人类的日常学习,可以获得更好的模型质量。
强化学习是让计算机通过不断尝试,从反馈中学习如何在特定的情景下,选择可以得到最大回报的行动。应用案例如AlphaGo,通过让计算机不断下围棋的过程中进行打分,不断更新行为准则,最终掌握下围棋的技能并得到高分。
深度学习本质上是让计算机用层次化的概念体系来理解和学习,每个概念通过相对简单的概念之间的关系定义,进而实现通过简单概念学习复杂概念。它借鉴了脑神经科学的实现手段,但与人脑差距很大:人可以从少量样本中总结规律,而深度学习对数据的量、数据的特征维度和特征在空间中的分布情况等条件都有较高的要求。
通过深度学习可以替代手工获取特征。典型的应用如电商平台的商品推荐引擎,社交网络平台向用户推荐他关心的新闻、电影、可能需要的专家建议等。
迁移学习是把已经训练好的模型参数,迁移到新的模型上帮助新模型训练的学习方法。
②根据要解决的任务算法又可以分为:
二分类,也就是说二选一任务;
多分类,如视觉识别、手写识别;
回归,用于预测具体的数值,如预测明天的温度、湿度、PM2.5指数等;
聚类,如社交软件根据用户的兴趣爱好以及在线行为数据对人群进行划分;
异常检测,对数据中存在的不正常或非典型的个体进行检测和标记。
选择算法时,我们需要在选择算法之前分析一些因素,减少算法选择的范围,需要考虑:
(1)数据量的大小、数据质量和数据本身的特征。
(2)具体业务场景中要解决的问题本质是什么?
(3)可以接受的计算时间是什么?
(4)算法的精度要求。
3 算据
随着计算资源、开放训练平台的使用门槛越来越低,算力将成为如水电煤一般的基础设施,而算据对行业的纵深度要求极高。未来,数据无疑将成为人工智能领域的竞争壁垒。
而提到数据,不得不关联到热词“大数据”,第2篇的主题是“教育大数据”:
大数据的“4V”是什么?
教育数据从哪里来?
又该如何收集处理它们?
...
敬请不要期待。