本文试图让读者对 Redis 有一个整体的认识。如果想深入学习,可以先阅读掘金小册上的 “老钱 Redis”,然后再找一本 Redis 实体书啃啃。
1. 是什么
Redis「Remote Dictionary Service」是基于内存的存储中间件,通常用于数据库、缓存、消息队列。
2. 基础 - 数据结构
Redis 有 5 中数据结构:string、list、hash、set 和 zset(有序集合),分别对应 Java 中的 String、LinkedList、HashMap、Set、SortedSet。
string 字符串
string 是 Redis 中最常见的数据结构,也称 SDS「Simple Dynamic String」,通常作为 key 或 value(最大长度 512 M)。图中粉色部分为 Redis 对象的通用头部,ptr 指向 SDS。string 按长短分以 embstr(len <= 44) 和 raw 的形式存储。


字符串在长度小于 1 M 时采用加倍扩容;大于 1 M 时采用 +1 M 扩容。
list 列表
list 对应的是链表而不是数组,插入删除快而索引慢,可以用于消息队列。list 的底层不是简单的 LinkedList,而是 ziplist(压缩列表)或 quicklist(快速列表)。

压缩列表使用一块连续的内存,元素间紧挨着存储没有空隙。

每个元素中包括前一个元素的长度、当前元素的编码和内容,在编码中标识当前元素的长度。在没有前后指针时,能够快速的前后索引。
struct entry {
int prevlen; // 前一个 entry 的字节长度
int encoding; // 元素类型编码
optional byte[] content; // 元素内容
}
list 在增加元素时会根据内存分配算法和当前内存大小,决定是在原有地址上扩展还是重新分配内存
当某个元素的长度超过 254 个字节时,后面元素的 prevlen 需要从 1 字节改成 5 字节用于表示上一元素的长度。这个操作可能会造成后面的元素雪崩式的更改 prevlen,即 联级更新。因此,list 中存储的元素不应该太多、太大。
hash 字典
hash 是 Redis 中的字典结构,内部实现与 Java 中的 HashMap 一致(数组 + 链表)。字典内部有两个 HashTable,Rehash(扩容或缩容)时用于存储新旧两份数据。
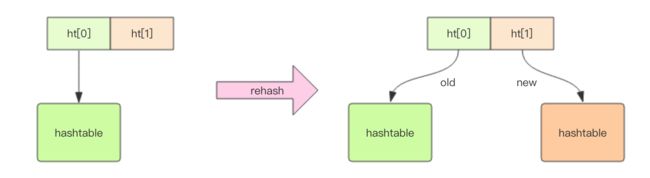
扩容时机:元素个数等于数组长度(bgsave 时 5 倍数组长度时扩容)
扩容方式:2 倍数组长度
缩容时机:元素个数少于数组长度 10%
set 集合
set 是没有排序的字符串集合,不允许出现重复元素,内部结构与 hash 字典一致,只是 value 为 null。
zset 有序集合
zset 是有序集合,内部实现为跳跃链表,用于支持随机地插入和删除。

跳跃链表其实是基于 LinkedList + 多级索引 的实现。链表用于前后索引,多层级索引通过类似 2 分的思路帮助快速定位,复杂度 O(lgn)。跳跃链表相比二叉树实现更加简单,通过随机层数来解决平衡的问题。
节点更新的过程是先删除再添加。
3. 应用
分布式锁
Redis 底层是单线程、事件循环
// 先争抢再设置过期时间,容易死锁
setnx lock_abc true
expire lock_abc 5
// 原子命令
set lock_abc true ex 5 nx
延时队列

// 阻塞读 notify-queue 队列
blpop notify-queue
// 使用 redis zset 来实现延时队列,按 score 获取需要执行的任务
redis.zrangebyscore("delay-queue", 0, time.time(), start=0, num=1)
HypeLogLog
HypeLogLog 是 Redis 的高级数据结构,用于获取唯一元素总数。基于数学概率公式,通过计算某一事件连续发生的最大次数估算实验的次数。Redis 通过对元素进行哈希,记录从某位开始连续出现 0 的最大次数,来估算元素样本的大小。
布隆过滤器
布隆过滤器是一个不精确的 set 结构,用于判断某个元素是否存在过,存在一定误判。内部实现是一个大型的位数组,通过多次哈希进行散落。效果与空间向量类似,同样的元素散落结果一定相同。

GeoHash
在 Redis 中基于 zset 实现,score 是 GeoHash 的值。原理是将经纬度经过哈希算法映射到一条直线上的多个值,哈希值约接近表示两个点约接近。
4. 原理
IO 模型
Redis 是单线程程序。
使用非阻塞 IO:能读时读,能写时写,无线程阻塞。
非阻塞 IO 基于操作系统底层的事件轮询 API,注册监听基于回调。
持久化
Redis 提供两种持久化方式:
- RDB - 一段时间内生成指定时间点生成数据集快照 (snapshot)
- AOF - 增量日志
Redis 提供了 SAVE 和 BGSAVE 两个命令来生成 RDB 文件,前者是阻塞的,后者是后台 fork 子进程。
AOF 持久化实现可以分为命令追加 (append)、文件写入 (write)、文件同步 (fsync) 三个步骤。Append 追加命令到 AOF 缓冲区,Write 将缓冲区的内容写入到程序缓冲区,Fsync 将程序缓冲区的内容写入到文件。
由于 AOF 比 RDB 文件更加完整,Server 启动时优先采用 AOF 文件进行恢复。
主从复制
主从复制是指一个 Server 复制另一个 Server 的数据。
主从复制的对象:mater 和 多 Slaver,和集群的概念区分开。
主从复制的三个阶段:复制初始化(建立连接)、数据同步(同步现有数据)和命令传播(同步增量数据)。
主从复制的策略:从未同步的 Slaver 全量同步,同步过的 Slaver 部分同步
5. 集群
大规模数据存储系统都会面临水平扩展的问题。水平扩展可以通过数据分片来解决,通过一致性哈希来避免大量的 rehash 数据迁移。但是数据分片如何屏蔽业务,在 Redis 3.0 支持集群以前,业界有两种的解决方案。
一是使用中间代理层来屏蔽集群分布,优点是数据迁移和运维方便,缺点是转发有一定的性能损失,代表有 Twitter 的 Twemproxy 和豌豆荚的 Codis。
二是将数据路由和故障转移封装到 client,优点是去中心化、可扩展性高,缺点是运维困难。
Redis 3.0 版本开始官方正式支持分集群,集群通过分片进行数据共享,分片内采用一主多从的形式进行副本复制,并提供复制和故障恢复功能。
哈希槽
Redis Cluster 的数据分片依赖哈希槽(slot)实现,集群预先划分 16384 个 slot,每个分片负责一部分 slot。请求时先通过 key 计算哈希值,然后映射到唯一的 slot,最后直连对应的数据分片。
分片
Redis Cluster 的数据分片通常有多台服务组成,一主多从(master and slavers)。master 负责写(或读),slaver 负责读(或转发写请求)。主从服务使用 Raft 协议完成 Leader 选举(故障转移),使用 Epoch(纪元)的概念来给事件增加版本号。