重磅!ICLR 2020 「自然语言处理(NLP)」【Prosus AI】金融情感分析FinBERT模型(含源码)!!
来源:AINLPer微信公众号(点击了解一下吧)
编辑: ShuYini
校稿: ShuYini
时间: 2020-1-15
TILE: FinBERT: Financial Sentiment Analysis with Pre-trained Language Models.
Contributor : Prosus AI
Paper: https://openreview.net/pdf?id=HylznxrYDr
Code: https://github.com/ProsusAI/finBERT
文章摘要
当前许多情感分类解决方案在产品或电影评论数据集中获得了很高的分数,但是在金融领域中,这些方法的性能却大大落后。 出现这种差距的原因是行业专用语言表达,它降低了现有模型的适用性,并且缺乏高质量的标记数据来学习特定领域的积极和消极的新上下文。在没有大量训练数据集的情况下,迁移学习可以成功地适应新领域。本文探讨了NLP迁移学习在金融情感分类中的有效性。本文提出了一个基于BERT的语言模型FinBERT,它将一个金融情绪分类任务在FinancialPhrasebank数据集中的最新性能提高了14个百分点。
文章贡献
1、引入FinBERT,这是一个基于BERT的语言模型,用于金融NLP任务。并在在两个金融情感分析数据集(FiQA、Financial PhraseBank)上得到了比较好的效果。
2、使用另外两个预训练语言模型ULMFit和ELMo进行金融情感分析,并将其与FinBERT进行比较。
3、对模型的几个方面做了进一步的实验研究,包括:进一步的预训练对金融语料库的影响,防止灾难性遗忘的训练策略,以及仅对模型层的一小部分进行微调以减少训练时间,而不会显著降低性能。
文章主要内容
背景介绍
由于每天都要产生数量空前的文本数据,因此分析来自医学或金融等不同领域的大量文本非常重要。然而,在这些专业领域中应用监督的NLP方法(如文本分类)比应用于更一般的语言要困难得多。其两个主要困难因素为: 1)利用复杂神经网络的分类方法需要大量的标记数据,而标记特定领域的文本片段需要昂贵的专业知识。2)在一般语料库上训练的NLP模型不适用于监督任务,因为特定领域的文本有专门的语言和独特的词汇和表达。
NLP迁移学习方法是解决上述问题的有效方法,也是本文研究的重点。**迁移模型背后的核心思想是,首先在非常大的语料库上训练语言模型,然后使用从语言建模任务中学的权重初始化下游模型,其中初始化层的范围可以从单个单词嵌入层到整个模型。**这种方法应该减少所需的标记数据的大小,因为语言模型通过预测下一个单词,以一种无监督的方式在一个非常大的未标记语料库上学习语言语法和语义。通过在特定于域的未标记语料库上进一步对语言模型进行预训练,该模型可以学习目标域文本中的语义关系,该语义关系可能与普通语料库的分布有所不同。
在本文中,主要探索使用微调预训练语言模型BERT的有效性。 并使用Malo等人创建的金融情感分类Financial PhraseBank数据集以及Maia等人的FiQA Task-1情感评分数据集进行验证。
模型介绍
BERT是一种由一组Transfer叠加而成的语言模型。它以一种新颖的方式定义了语言建模。BERT不是根据之前的单词预测下一个单词,而是随机选择所有token的15%作为mask。在最后一个编码器层之上的词汇表上有一个softmax层,可以预测被掩膜的token。BERT训练的第二个任务是“下一个句子预测”。给定两个句子,该模型预测这两个句子是否相有关系。
继先前关于在特定领域上进一步对语言模型进行预训练的有效性的工作(Howard&Ruder,2018)之后,我们尝试了两种方法:第一种是在特定领域下,即在较大金融语料库上对BERT语言模型进行了预训练。第二种方法是只对训练分类数据集中的句子进行预处理。通过在tokens最后一个隐藏状态之后添加一个稠密层来进行情绪分类。这是将BERT用于任何分类任务的推荐实践(Devlin et al.2018) 。然后,在标记的情感数据集上训练分类器网络。主要训练流程图如下图所示: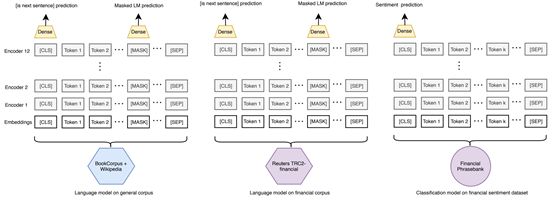 虽然本文的重点是分类,但我们也在具有连续目标的不同数据集上实现了具有几乎相同架构的回归。这里的唯一区别是损失函数采用的是均方误差而不是交叉熵损失。正如Howard & Ruder(2018)所指出的,采用这种微调方法会有灾难性遗忘问题。因为当模型试图适应新任务时,微调过程可能会迅速导致模型“忘记”来自语言建模任务的信息。为了解决这一现象,我们采用了Howard & Ruder(2018)提出的三种技术:倾斜三角形学习率(slanted triangular learning rates)、有区别微调(discriminative fine-tuning)和逐步解冻(gradual unfreezing)。
虽然本文的重点是分类,但我们也在具有连续目标的不同数据集上实现了具有几乎相同架构的回归。这里的唯一区别是损失函数采用的是均方误差而不是交叉熵损失。正如Howard & Ruder(2018)所指出的,采用这种微调方法会有灾难性遗忘问题。因为当模型试图适应新任务时,微调过程可能会迅速导致模型“忘记”来自语言建模任务的信息。为了解决这一现象,我们采用了Howard & Ruder(2018)提出的三种技术:倾斜三角形学习率(slanted triangular learning rates)、有区别微调(discriminative fine-tuning)和逐步解冻(gradual unfreezing)。
实验结果
实验准备
为了进一步优化FinBert,文章使用了一个叫做TRC2-financial的金融语料库(它是路透社TRC21的一个子集,后者由路透社在2008年至2010年间发表的180万篇新闻文章组成)。本文使用的主要情感分析数据集Financial PhraseBank。该数据集由从LexisNexis数据库中随机挑选的4845个英语句子组成,其中这些句子由16名具有金融和商业背景的人进行注释。FiQA Maia数据集等是为WWW ’18会议金融观点挖掘和问题解答Challenge3创建的数据集。我们使用任务1的数据,其中包括1,174个金融新闻标题和推文及其相应的情感评分。
基线方法对比
在对比实验中,我们考虑了三种不同方法的基线:基于GLoVe 的LSTM分类器、基于ELMo 的LSTM分类器和ULMFit分类器。这里使用召回得分来进行评价。在Financial PhraseBank数据集上的对比结果如下: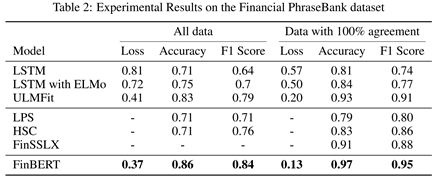 其中LPS、HSC和FinSSLX的结果取自各自的论文。
其中LPS、HSC和FinSSLX的结果取自各自的论文。
FiQA情感数据集的结果如表3所示。本文模型在MSE和R2方面都优于最先进的模型。

预训练对分类器性能的影响
我们比较了三种模型:1)没有进一步的预训练(Vanilla BERT表示),2)在分类训练集上进一步的预训练(FinBERT-task表示),3)在特定领域语料库上进一步的预训练,TRC2-financial (FinBERT-domain表示)。模型通过损失、准确性和测试数据集上的宏观平均F1分数进行评估。结果见表4,但是可以发现,进一步在金融领域语料库上进行预处理的分类器表现最好,但差异不是很大。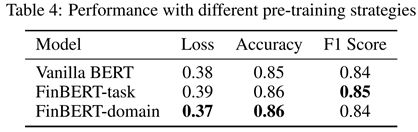
灾难性遗忘性能评估
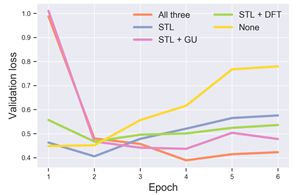
我们尝试了四种不同的设置:无调整(NA)、只使用倾斜三角形学习率(STL)、倾斜三角形学习率和渐进解冻(STL+GU)以及(STL+DFT),并进行了有区别的微调。实验结果发现应用这三种策略可以在测试损失和准确性方面产生最佳性能。实验结果可见下图:
=分割线========
往期回顾
入门基础
「自然语言处理(NLP)」入门系列(一)初识NLP
「自然语言处理(NLP)」入门系列(二)什么才是深度学习?
「自然语言处理(NLP)」入门系列(三)单词表示、损失优化、文本标记化
「自然语言处理(NLP)」入门系列(四)如何训练word2vec !!
论文阅读
「自然语言处理(NLP)」【爱丁堡大学】基于实体模型的数据文本生成!!
「自然语言处理(NLP)」【Borealis AI】跨域文本连贯生成神经网络模型!!
「自然语言处理(NLP)」CTRL:16.3亿个参数的条件转换语言模型
无情!「自然语言处理(NLP)」统一预训练UniLM模型(NLU+NLG)
学术圈
「自然语言处理(NLP)」你必须要知道的八个国际顶级会议!
「重磅!!」深度学习十年技术“进化史”
【圣诞福利】ICLR2020开源代码的paper集合(共计198篇)
收藏!「自然语言处理(NLP)」全球学术界”巨佬“信息大盘点(一)!
Attention
更多自然语言处理相关知识,还请关注 AINLPer公众号 ,极品干货即刻送达。